门控循环单元(Gated Recurrent Unit, GRU)是一种用于处理序列数据的递归神经网络(Recurrent Neural Network, RNN)变体,它通过引入门控机制来解决传统RNN在处理长序列时的梯度消失问题。GRU与长短期记忆网络(LSTM)相似,但结构更为简化。以下是GRU的详细介绍:
1. GRU的结构
GRU由以下几个主要部分组成:
- 重置门(reset gate):控制当前时间步的输入如何与之前的记忆结合,用于决定要丢弃多少过去的信息。
- 更新门(update gate):控制上一时间步的记忆如何流入当前时间步的记忆,用于决定要保留多少过去的信息。
具体来说,GRU的计算过程如下:
2. 公式表示
假设xt是当前时间步的输入,ht−1是上一时间步的隐状态,则GRU的更新过程可以用以下公式表示:
- 重置门(reset gate):
- 更新门(update gate):
- 候选隐状态(candidate hidden state):
- 当前隐状态(current hidden state):
其中:
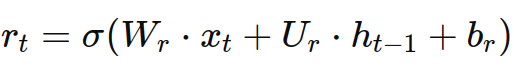
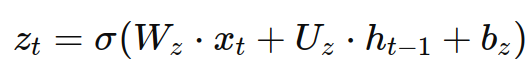
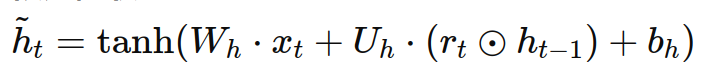
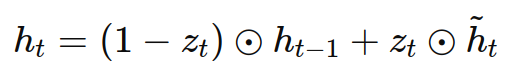
- σ 是sigmoid激活函数。
- tanh 是tanh激活函数。
- W和U 是权重矩阵,b是偏置项。
- ⊙ 表示元素乘法(Hadamard积)。
3. GRU的工作原理
- 重置门rt:决定了多少过去的记忆需要被重置或忽略。重置门的值接近0时,意味着更多的过去信息被丢弃;值接近1时,意味着保留更多的过去信息。
- 更新门zt:决定了当前时间步的记忆如何与之前的记忆进行权衡。更新门的值接近0时,更多的过去记忆被保留;值接近1时,更多的当前信息被引入。
4. GRU与LSTM的比较
- 结构:GRU比LSTM结构更简单,LSTM有三个门(输入门、遗忘门和输出门),而GRU只有两个门(重置门和更新门)。
- 参数:由于结构较为简化,GRU的参数量比LSTM少,因此在某些任务中计算效率更高。
- 性能:在许多任务上,GRU与LSTM的表现相当,有时GRU甚至表现得更好,特别是在数据量较少的情况下。
5. 应用场景
GRU广泛应用于自然语言处理(NLP)、语音识别、时间序列预测等领域,尤其适合需要处理长序列数据的任务。
6. 实现示例
在TensorFlow中,可以使用tf.keras.layers.GRU来实现一个GRU层:
import tensorflow as tf
import numpy as np
# 生成示例数据
# 输入序列(样本数量,时间步长,特征维度)
input_seq = np.random.randn(3, 5, 10).astype(np.float32)
# 定义GRU模型
model = tf.keras.Sequential([
tf.keras.layers.GRU(20, return_sequences=True, input_shape=(5, 10)), # 隐状态维度为20
tf.keras.layers.GRU(20) # 第二个GRU层
])
# 编译模型
model.compile(optimizer='adam', loss='mse')
# 打印模型摘要
model.summary()
# 生成示例标签(样本数量,输出维度)
output_seq = np.random.randn(3, 20).astype(np.float32)
# 训练模型
model.fit(input_seq, output_seq, epochs=10)
# 预测
predictions = model.predict(input_seq)
print(predictions)
代码解释
-
数据生成:
input_seq = np.random.randn(3, 5, 10).astype(np.float32)这里生成了一个随机的输入序列,假设有3个样本,每个样本有5个时间步,每个时间步有10个特征。
-
定义GRU模型:
model = tf.keras.Sequential([ tf.keras.layers.GRU(20, return_sequences=True, input_shape=(5, 10)), tf.keras.layers.GRU(20) ])使用
tf.keras.Sequential定义了一个简单的GRU模型。第一个GRU层的隐状态维度为20,并且返回所有时间步的输出。第二个GRU层的隐状态维度也为20,但只返回最后一个时间步的输出。 -
编译模型:
model.compile(optimizer='adam', loss='mse')使用Adam优化器和均方误差损失函数来编译模型。
-
打印模型摘要:
model.summary()打印模型的摘要信息,以查看模型的结构和参数数量。
-
生成示例标签并训练模型:
output_seq = np.random.randn(3, 20).astype(np.float32) model.fit(input_seq, output_seq, epochs=10)生成与输入序列匹配的随机标签,并使用这些标签来训练模型。
-
预测:
predictions = model.predict(input_seq) print(predictions)使用训练好的模型进行预测,并打印预测结果。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » [深度学习] 门控循环单元GRU

发表评论 取消回复