文章目录
引言
- 感觉进度还是不够快,然后方向有点乱,又是项目,又是八股,又是redis,做项目发现很多没有学过。本来放下了redis,准备直接做项目,结果看着看着,发现redis这里有不会。
正文
缓存基础
- 将MySQL中的热点数据存储在Redis上,利用其访问高效的特点
- 二八原则,百分之八十的流量建立在百分之二十的信息上。
怎么做
- 采用服务端缓存,访问MySQL数据之后的将数据放在redis中进行缓存,下次直接访问redis
缓存的几种模式
- 旁路缓存模式(Cache-Aside Pattern):这个用的最多
- 读穿透模式
- 写穿透模式
- 异步缓存写入模式
旁路缓存模式(重点)
-
应用服务直接将缓存当作数据的旁路,直接和缓存进行交互
-
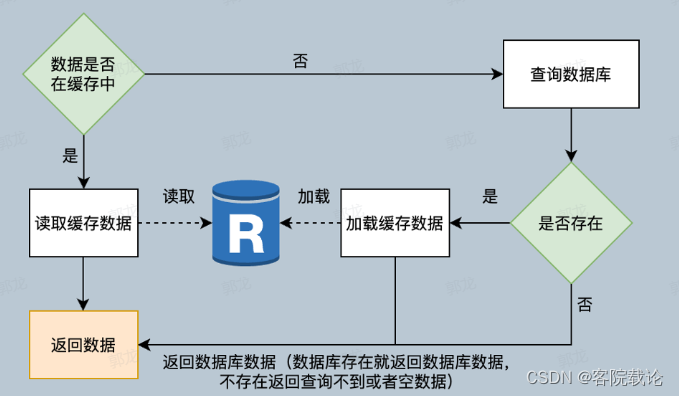
读取数据的流程
- 读取数据先读取缓存,缓存中有,那就加载缓存
- 缓存中没有读取数据库,然后将读取的数据放入缓存中
- 会预先加载一批数据到缓存中。
-
写数据流程
- 直接更新数据库,然后删除缓存
如果不删除缓存,会出现时序性的问题
-
更新修改数据库和修改缓存的顺序不一样。
-
适用场景和缺点
- 读多血少
- 出现缓存和数据库不一致的情况
读穿透(了解)
- 应用服务不在和缓存直接交互,而是直接访问数据服务(代理)
- 由数据服务访问数据库和缓存,使用者不知道数据来源,数据服务会根据情况查询缓存或数据库
特点
- 服务对于缓存是透明,代码更加简洁
- 命中性能不如旁路缓存模式,还多了一次服务间调用。
写穿透(了解)
- 一个缓存一个数据库,更新操作比较麻烦,先更新数据库,在删除缓存
- 应用程序访问存储服务源,然后存储服务源完成对应的缓存和数据库操作
具体应用
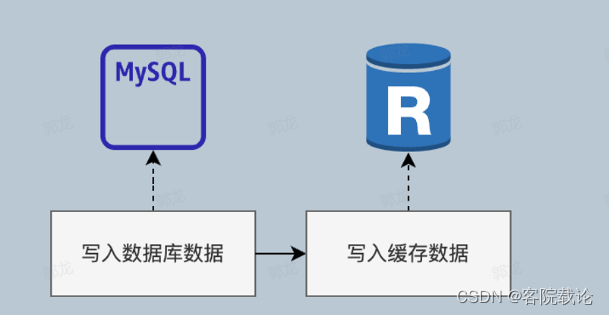
- 写穿透配合读穿透使用
- 对缓存及时性要求高
- 不能忍受丢失数据和数据不一致。
异步缓存写入模式
- 同写穿透,不过先写缓存,然后异步写入数据库,
写入方式
- 收集写操作,在数据库负载低的时候慢慢写入
- 一个批量一块写入
优点
- 降低了请求延迟,减轻了数据库复旦
- 安全性不够,系统崩溃,内存数据会丢失
面试重点
Redis缓存是如何应用的
- 旁路缓存,先查询redis,没有的话,再查MySQL,并将数据加载到Redis
Redis设置缓存用什么命令
- set key value,如果业务要增加一个过期时间,可以使用ex参数,set key value ex 10;
聊聊旁路缓存模式下的查询流程
- 请求到后台服务之后,先查redis,有就返回数据,没有就查Mysql,并将mysql的数据存入redis,最后返回给用户。
缓存异常场景
缓存穿透
- 缓存和数据库中都没有的数据,而用户不断发起请求。
- 缓存是被动写的,也就是查不到就去数据库查,然后把数据插入到缓存中,现在就是每次都是查缓存,在数据库也查不到,缓存就被击穿了。
- 有人频繁利用这类DB中没有的数据不断访问,系统会崩溃
解决方案
- 接口层校验,对于访存数据做基础校验
- 对于取不到的数据,设置为key-null,并设置有效时间较短,防止用户在短时间内反复用同一个id暴力攻击
- 布隆过滤器,用于快速判定某一个元素是否在数据库中。
- 将字符串通过hash函数映射到不同的二进制位置,并将该位置设置为1
- 空间时间都很小,但是不完全准
缓存击穿
- 缓存中没有,但是数据库中有的数据。
- 某一瞬间并发用户特别多,同时读缓存没有读到数据,又同时去数据库读取数据,压力瞬间增加,崩溃
解决方案
- 热点数据续期,对于持续访问的数据不断续期,避免过期失效被击穿
- 进程加互斥锁,重建缓存
- 线程查询缓存发现缓存不存在,尝试对线程加锁,拿到锁的线程访问数据库,并重建缓存,其他循环重试。
缓存雪崩
- 大量的应用请求因为异常无法在Redis缓存中进行处理,像雪崩一样,直接打到数据库上。
- 雪崩的原因
- 数据大批量到过期时间
- 查询数据量巨大,引起数据库压力过大,甚至宕机
和缓存击穿的区别
- 缓存击穿是一条热点数据在Redis没有得到及时重建,
- 缓存雪崩是一大批数据在Redis中同时失效
解决方案
- 缓存过期时间设置随机,防止同一时间大量数据过期现象发生
- 加互斥锁重建缓存
- 当线程查询缓存发现数据不存在事,加锁,多个线程抢锁,拿到锁的线程查询数据库,重建缓存,失败则循环重试。
面试重点
缓存击穿和缓存穿透有什么区别
- 击穿是单个热点数据在缓存中不存在,但是在数据库中存在,数据库被一瞬间的流量击垮的场景
- 穿透是某个key不在数据库也不在缓存中,被海量击打
缓存雪崩和缓存击穿有什么区别
- 缓存适量的数量,击穿是一个key失效,雪崩是大量的key 失效。
缓存击穿怎么解决
- 热点数据续期
- 加锁重建缓存,防止MySQL被击穿。
缓存一致性怎么保证?
缓存一致性问题是什么
- 缓存是数据库的冗余存储,如果数据库信息更改了,缓存的数据和数据库不一致怎么办?
- 解决办法
- 更新MySQL即可,不管Redis,以过期时间兜底
- 更新MySQL之后,操作Redis
- 异步将MySQL更新同步到Redis
仅仅更新MySQL,不管Redis,过期时间兜底
- 仅仅更新MySQL,等redis过期了,自动从MySQL重建更新,在这段时间内数据是不一致的。
- 时间太长,会产生很多脏数据
- 时间太短,会出现缓存击穿
优点
- redis原生接口,开发成本低,易于实现,直接使用ex
- 管理成本低,出概率的问题较小
缺点
- 完全依赖过期时间,时间太短容易造成缓存频繁失效,太长会有较长的时间不一致。
更新MySQL,立刻更新Redis
- 除了使用过期时间进行兜底,还会将缓存数据直接删除,借此减少数据不一致的情况出现
优点
- 想对方案一,达成最终一致性的延迟更小
- 实现成本低,只是在方案一的基础上,增加了删除的逻辑
不足
- 更新mysql成功,删除redis却失败,就退化为方案一
- 在更新的时候需要额外操作redis,性能损耗
异步将MySQL更新到MySQL
- 将消费服务作为mysql的一个salve,订阅mysql的binlog日志,解析日志的内容,在更新到redis中
- 业务和数据访问完全解耦,redis更新对业务更加透明(阿里的canal组件)
优点
- 和业务完全解耦,在更新mysql是,不需要额外操作
- 无时序性问题,可靠性抢。
缺点
- 成本高,引入了消息队列,还需要搭建同步服务。
- 服务崩溃了,redis没法更新。
方案选型
- 时效性要求很高,一致性要求很高,不要使用缓存
- 通常来说,使用过期兜底是行之有效的方式,还可以增加一个删除,增加时效性。
- 解耦层面,使用方案三。
面试重点
缓存一致性问题是什么?
- MySQL数据更新了,redis作为缓存,数据应该怎么保存一致性的问题。
redis做旁路缓存,如果mysql更新了,该何去何从
- 在项目中使用过期时间来兜底,并在更新DB后,增加删除操作提升一致性的问题。
- 设计方案的时候,考虑过订阅binlog日志的方式,会成本高,并且代码复杂。
什么情况下,适合订阅binlog方式
- 这种模式更像是同步数据,比较适合缓存很长时间过期、或者不过期的场景,如果一个视频网站,有几个视频流量很大,基本不会动,是稳定的,可以使用这种方式。
分布式锁
分布式锁是什么?
锁
- 针对某项资源使用权限的管理,用来控制共享资源。
分布式锁
- 在分布式场景下的锁,多台不同机器上的进程,去竞争同一项资源。
分布式锁有什么特性?
互斥性
- 只让一个竞争者持有锁,其他进程无法持有。
安全性
- 避免锁因为异常永远无法释放
- 一个进程因为异常在持有锁的时候崩溃了,所拥有的锁能够被兜底释放,保证后续其他的竞争者也能够获得锁。
对称性
- 同一个锁,加锁和解锁的必须要是用一个进程
- 不能把其他竞争者持有的锁释放了
可靠性
- 有一定程度的处理能力和容灾能力
分布式锁常用的方式什么?
最简化版本
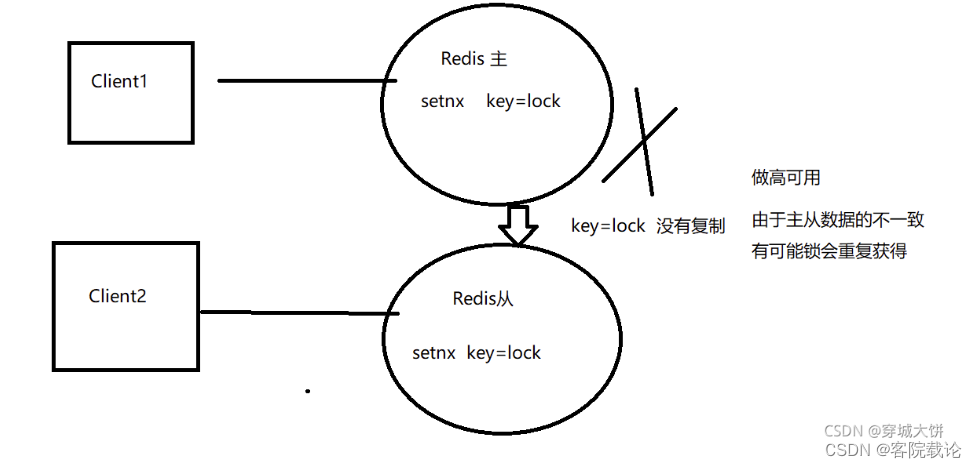
- 使用setnx实现,因为setnx是在变量不存在的时候,设置一个新的变量,并返回1,如果变量存在,就返回0。
- 设置一个lock变量,每一次进程访问时候,就声明这个变量,操作完成之后,在删除变量,delete lock。在访问期间,其他线程通过setnx lock就会返回0,,无法访问,妙呀!
支持过期时间
- 但是上述问题,存在一个问题,就是如果获取锁的某一个线程挂掉了,那么这个锁就石沉大海了,后续的所有线程都没有办法进行访问了。所以,需要增加一个过期时间来兜底。
setnx lock 1 ex limit-times
- 即使获取锁的进程崩溃了,但是只要超过了limits-times,仍旧能够解锁,变量就过期了,其他进程仍旧能够获取锁。
但是仍旧存在一个问题,就是会出现其他进程删对应的锁的情况
增加owner字段
- 分布式锁需要满足谁申请谁释放的原则,不能释放别人的锁,分布式锁要有归属
- 在编程过程中,都是使用进程id作为锁的值
set key owner(uuid) nx ex limit-seconds
- 在获取锁的时候,会检查这个锁的值是不是自己的进程号,判定这个锁有没有变化。
引入Lua
- 上述操作都不是原子性的,通过Lua将若干操作整合为原子操作。通过lua脚本,将若干操作合并成原子操作,保证结果的一致性 。
- Lua是一个脚本
上述所有操作保证了对称性、安全性、互斥性
可靠性是如何保证的?
- 上述所有方式都是针对单机模型而言的,如果redis挂了怎么办?常见方式有两种,分别是
- 主从容灾
- 多级部署
主从容灾
- 为redis配置从节点,当主节点挂了,直接用从节点进行顶包。
- 但是主从切换需要配置哨兵模式,实现主从节点自动切换,容纳灾祸
缺点
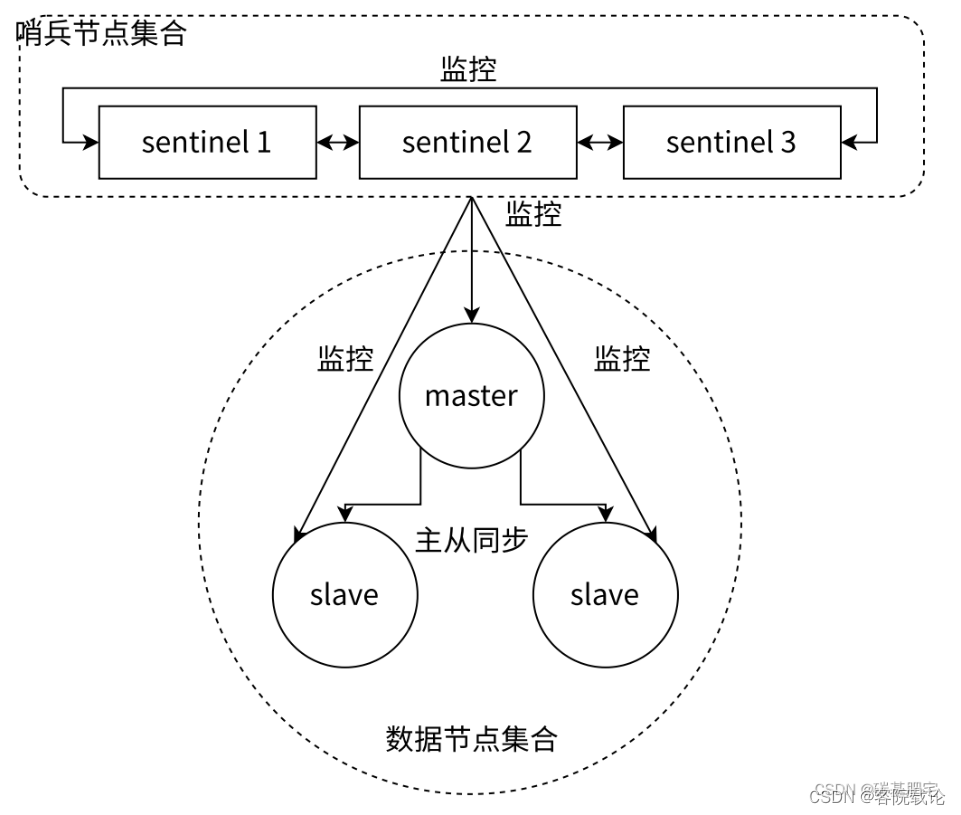
- 主动节点数据同步需要时间,会丢掉部分数据
- 分布式锁在失效的过程,会有多个机器同时获取执行权限
多机部署
- 尝试多机部署,使用redis中的redlock
- redlock:奇数个机器进行部署,然后半数以上的机器同意加锁才能成功,可靠性会向ETCD靠拢
具体执行流程
- 有5个redis主节点,保证不会同时宕机,申请锁的时候,同时向5个主节点申请锁
- 数量超过一半同意,获取锁,如果超过一半失败,向所有redis主节点发送解锁指令
- 因为向五个节点发送锁请求,会有一个时间限制,如果在锁持有时间内,仍旧不能获取所有锁,就是失败。
优点
- 增加灾难容错率,给运维进一步增加修复时间
- 单点reids 的所有可靠性保持手段都可以使用,所以增加了可靠性
可靠性深究
没有完全可靠的分布式锁,NPC困境
N网络延迟
- 当分布式锁获得返回包的时间过长,锁会很快就过期。
- 锁剩余时间,减去请求时间,解决锁的网络延迟问题
P进程暂停
- 进程在进行垃圾回收时,锁过期了,其他进程仍旧能够获得锁,两个进程就获得了同一个分布式锁。
- GC的时间无法掌控,看门狗会随着GC而阻塞,也无法解决
C时钟漂移
- 不同机器发生时间漂移,会出现同时获得一个锁的情况,无解。
具体来说,需要配合业务开展,不是完全可靠的
面试重点
分布式锁实现要点是什么?
- 加锁的时候,要设置owner和过期时间
- owner便于解锁的时候,进行拥有者的判断
- 过期时间,对异常情况进行兜底
- 解锁的时候,要先判断owner是否是自己,是自己在释放
- 使用Lua脚本,保证操作的原子性
为什么要引入owner概念
- 分布式锁需要保证对称性,谁加锁,就谁解锁
- 具体情况说明,某一个服务执行时间太久,然后锁过期了,其他服务又获取了锁。
你提到Lua,Lua一定能够保证原子性吗?
- Lua本身不具有原子性,通过Lua保证原子性是因为Redis是单线程执行的,一个线程放进Lua来执行,相当于打包再一次,redis执行的过程中,不会被其他请求打断
分布式锁是完全可靠的吗?
- 没有完全可靠的分布式锁,关键业务需要靠幂等来兜底
- 当然也可以使用redlock集群化的分布式锁,这种模式出问题的概率很低。
事物
事物是什么?
- Mysql中的事物具有ACID原子特定,Redis不具有原子性和持久性。
- 多个操作被看作是一个整体,也就是事物。事物通常具有原子性。
Multi事物
- 通过multi关键字,进入多任务队列,执行对应的操作,后续所有输入的命令都会进入queue中
- 使用exec指令,执行queue中的所有命令
- 使用discard指令,丢弃最终的事物
- 使用watch保证事物中的变量不会丢弃和改变。
multi事物具有原子性吗
- 不具备,因为只是通过单线程的特性,其他操作切不进来
- 但是因为中途自己崩溃,或者自己的问题只做一半,就没有意义了
multi事物的缺点
- 弱原子性,事物开启之后每一个命令都是一次调用,浪费资源。
- watch难用
- 失败了还会继续执行,没意义
Lua做事物
Lua是什么
- 标准C语言编写的轻量脚本语言
- 目的是为应用程序提供扩展
Redis和Lua
- redis通过内嵌支持lua环境,执行脚本的常用命令是eval
- redis是单线程,处理过程中,不会被打断并切换到其他处理
- redis执行lua脚本具有原子性
具体执行指令
eval “return {redis.call('set' ,'ka','a1'),redis.call('icnr','ka')}”
优势
- 可以编写if-else选择逻辑
- 事物中间执行事变,会中断后续执行
- 使用方便,开启lua就可以执行事物
Lua主要是redis中干什么的
- 分布式锁和秒杀场景
消息队列
消息队列是什么?
- 传递消息的队列
- 用于
- 异步流程、消息分发、流量削峰
- 优点
- 是实现高性能、高可用和高扩展的架构
常见的消息队列中间件
- 是实现高性能、高可用和高扩展的架构
- Kafka,RabbitQ,MetaMQ等
redis能做消息队列吗
- 可以,适合做一个轻量级的消息队列,常见的有三种方案
List做消息队列
- 将数据放入list,消息作为商品,这就是一个典型的生产者和消费者模式。
- 通过rpush和lpop实现消息的传递,但是这里不知道消息队列什么时候有消息,只能轮询
BRPOP和BLPOP
- 没有消息在队列中,会陷入阻塞,阻塞时间内有消息,再继续执行。
- 缺点
- 没有ACK机制,消费失败了,还要放回去
- 不支持多人消费
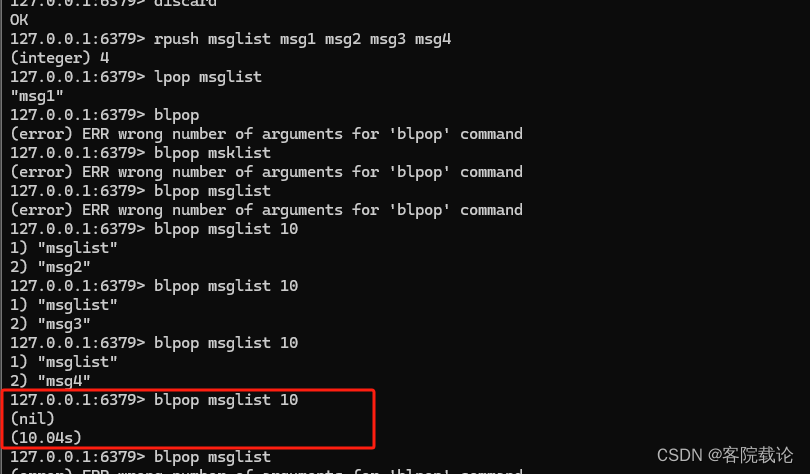
Pub/Sub生产订阅模式
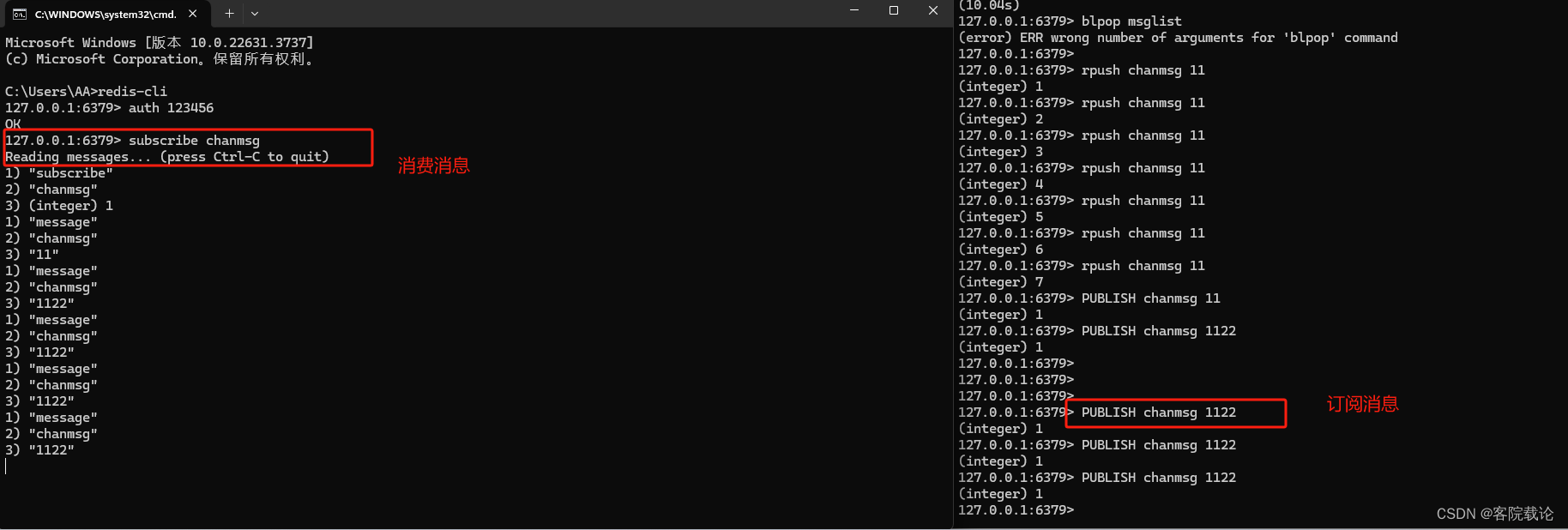
- 使用
subscribe channel订阅消息频道 - 使用
publish channel msg往特定频道发送消息
缺点
- 没有办法实现ACK功能
- 不支持持久化,redis重启消息会全部丢失,若以pub和sub适合处理不重要的消息
Stream做消息队列
- redis实现,具有持久化,消费组的功能,但是不考
几种方式对比
List:不需要ACK,不需要消费组,可以使用
PUB\SUB:不需要ACK,不需要持久化,可以用
STREAM:需要ACK,需要消费组,需要持久化,可用
秒杀
什么是秒杀
- 一瞬间产生巨大流量的场景
需要注意以下几个问题
- 海量请求,服务要抗住
- 不能超卖
- 避免少买
- 保证触达是用户不是黄牛
没有相关的要求,直接跳过
场景应用面试题
实际使用redis做什么应用
- 缓存和消息队列
redis缓存一般是如何使用的
- 旁路缓存
redis做旁路缓存了,如果Mysql做了更新,该何去何从
- 使用过期时间都低,更新DB之后,删除缓存
redis做秒杀场景可以吗
- redis因为高性能,经常被用于做秒杀产经,预扣库存,结合Lua脚本,可以在一定程度上保证预扣库存的原子性
redis可以做消息队列吗
- 可以,但是针对那种轻量级,不需要持久化,不需要ack的简单消息队列可以。
总结
- 就剩限流器和秒杀没看了,感觉比较偏,我想去的并不是这一类服务,所以还是算了把,不看了,省时间。
- 下面就是结合项目看一下项目的数据库怎么做的。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 秋招突击——第九弹——Redis缓存

发表评论 取消回复