引言:在现代应用程序开发中,通常会将数据存储在 MySQL 中,用于事务性处理和数据持久化。而 Elasticsearch(ES)则是一种专门用于全文搜索和分析的强大工具。将这两者结合使用的一个常见需求是实时将 MySQL 中的数据同步到 Elasticsearch 中,以实现高效的数据检索和分析功能。本文将探讨几种常见的实现方案和技术选型。
题目
MySQL 如何实现将数据实时同步到 ES ?
推荐解析
引言
在日常的开发中,我们一般会使用 MySQL 来作为数据的存储,然后 ES 来实现全文的数据检索以及特殊查询,那么这个时候就会有一个问题,我们 MySQL 如何实时将数据同步到 ES 中呢?我们接下来来盘点一下。
解决方案
1. 数据双写
这个方案应该是比较常用的,即在写入数据的时候,先将数据写入 MySQL 然后在将数据写入 ES,这种方案实现起来比较简单,但是如果你在写入 MySQL 之后,服务发生了宕机,这个时候就可能产生不一致的情况,这个时候就可能需要重新进行写入。
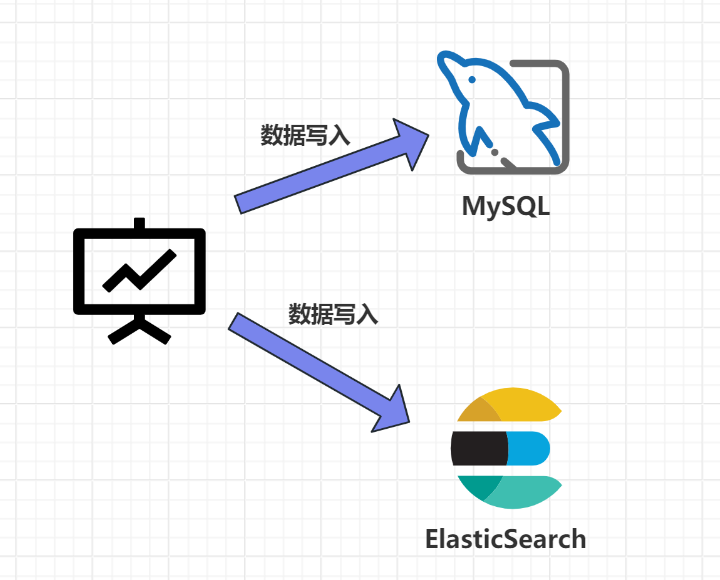
伪代码如下:
/**
* 新增商品
*/
@Transactional(rollbackFor = Exception.class)
public void addGoods(GoodsDto goodsDto) {
//1、保存Mysql
Goods goods = new Goods();
BeanUtils.copyProperties(goodsDto,goods);
GoodsMapper.insert();
//2、保存ES
IndexRequest indexRequest = new IndexRequest("goods_index","_doc");
indexRequest.source(JSON.toJSONString(goods), XContentType.JSON);
indexRequest.setRefreshPolicy(WriteRequest.RefreshPolicy.IMMEDIATE);
highLevelClient.index(indexRequest);
}
这个方案的优缺点如下:
-
优点:
-
- 实现起来逻辑简单,而且实时性较高
-
缺点:
-
- 硬编码问题严重,并且业务耦合程度高
- 如果服务或者 Elasticsearch 发生宕机情况,就有数据丢失的风险
2. MQ 异步同步
这个思路应该是大家比较容易想到的,就是在执行完 MySQL 的写入操作之后,将操作交给 MQ,然后通过 MQ 告诉 ES 需要进行数据的同步。
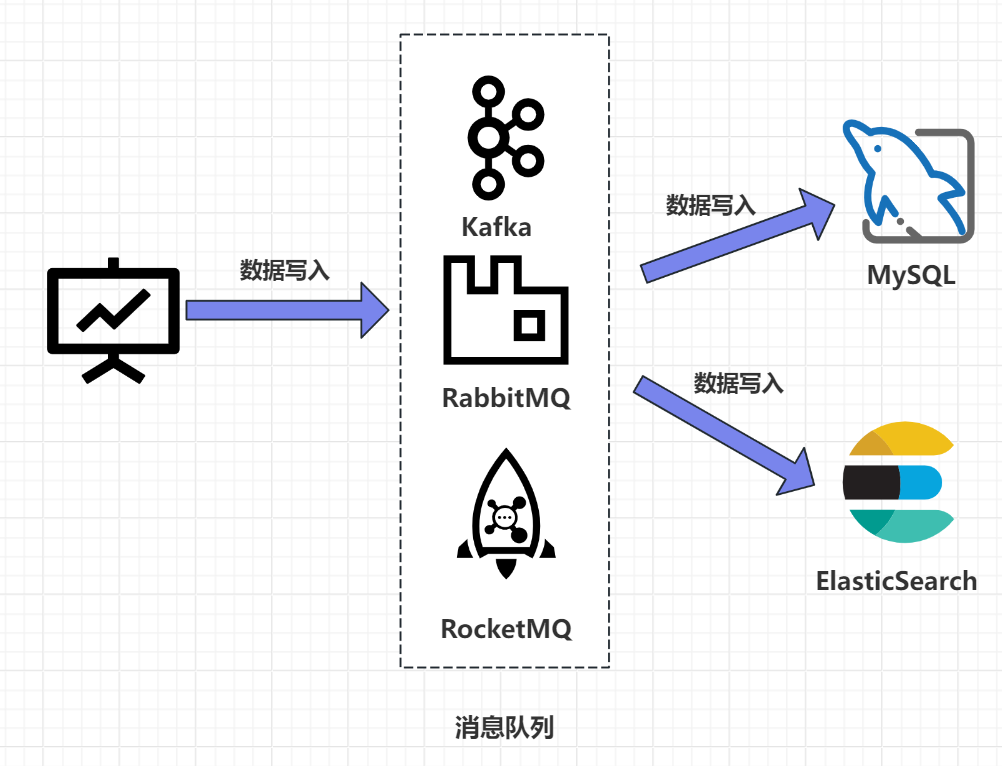
这个方案优缺点如下:
-
优点:
-
- 这个方案最直接的点就是性能高,并且实现了业务的解耦合,并且可以利用 MQ 的重试机制,在写入失败的时候进行重试,降低了数据丢失的风险。
- 这样还支持多个数据源的写入,提高了扩展性,不会出现由于单个数据源写入异常从而导致其他数据源写入受到影响的问题。
-
缺点:
-
- 硬编码问题,在接入新的数据源的时候需要实现新的消费者代码,代码侵入性较强
- 引入了消息队列,提高了运维的成本,增加了系统的复杂程度
- 可能出现延时问题,因为消息队列是异步消费模型,用户写入的数据不一定可以马上看到结果,有一定的延迟。
3. 基于 Binlog 实现数据同步
上面的这两个方案总结下来就两个问题,第一个问题就是硬编码并且代码侵入性较强,另外一个点就是没有办法实现数据的实时同步,那么有没有其他方案,答案肯定是有的,那就是利用 MySQL 的 Binlog 日志来实现数据同步,如下图所示:
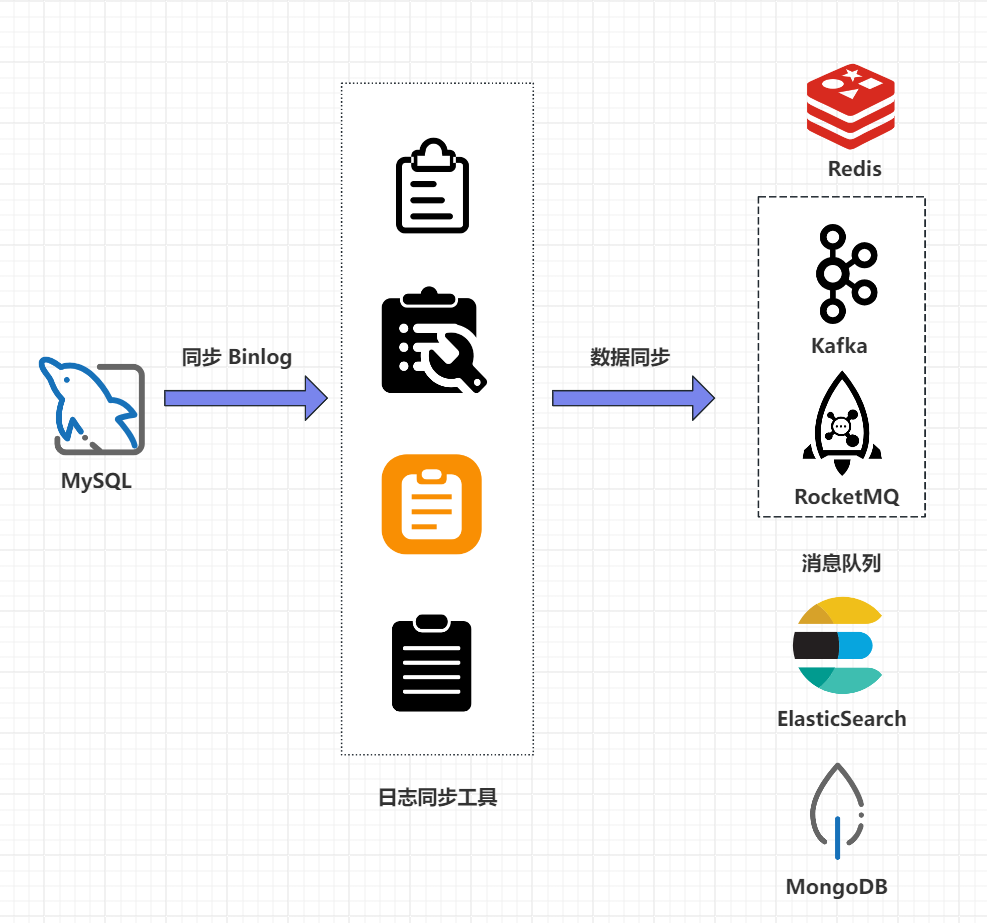
具体步骤如下:
-
优点:
-
- 没有代码侵入,没有硬编码
- 原有的系统没有任何变化,可以实现无感知,性能较高
- 业务解耦合,这个和消息队列是差不多实现思路的,不过这个不需要关注原来系统的业务实现
-
缺点:
-
- 如果采用 MQ 消费解析 Binlog 日志的话,又会回到方案二引入消息队列产生的问题
针对以上方案,我们可以使用一种新的解决方案,就是阿里巴巴开源的 Canal 中间件。
Canal 方案
什么是 Canal ?
Canal:译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。

说白了就是,根据 MySQL 的 BinLog 日志进行增量同步数据。要理解 Canal 的原理,就要先了解 MySQL 的主从复制原理,如下:
- MySQL 所有的增删改操作都会进入MySQL 主从复杂的主节点,即 Master 节点。
- Master 节点会生成 Binlog 日志文件,每次操作 MySQL 数据库就会记录到 Binlog 日志文件中。
- Slave 节点会订阅 Master 节点的 Binlog 日志,以增量备份的形式同步数据到 Slave 数据。
Canal 同步流程
Canal 的原理就是伪装成 MySQL主从复制的从节点(Slave 节点),从而订阅 MySQL主节点的 Binlog日志,主要流程如下:
- Canal 服务端向 MySQL 的 Master 节点传输 Dump 协议
- MySQL 的 Master 节点接收到 Dump 请求后推送 Binlog日志给 Canal 服务端,解析 Binlog 日志对象(原始为字节流对象),然后转换成 JSON 数据格式
- Canal 客户端通过 TCP 协议或 MQ 形式监听 Canal 服务端,然后将同步数据到ES,到此,同步过程就完成了。
总结
1)数据双写是最简单的实现方式,可以最大程度的保证数据的同步写入,不过问题很明显,就是代码侵入性太强了,而且容易因为中间件故障导致写入失败。
2)**MQ 异步同步,**这个方案引入了消息队列,实现了业务的解耦合,而且性能较高,吞吐量也比较大,并且支持多数据源的数据同步,不过由于 MQ 是异步消费模型,所以可能出现数据同步延迟的情况,所以实时性要求比较高的场景可能没办法实现。
3)**基于 Binlog 日志实现,**主要原理就是通过监听 MySQL 的 Binlog 日志数据实现增量数据同步,这个方案其基本不会产生代码侵入,而且数据同步的实时性也有一定的保障,不过弊端也比较明显,就是 Binlog 系统的实现可能较为复杂,所以可以考虑使用第三方日志同步组件,最典型的实现就是 Canal 实现。
其他补充
鱼聪明 AI 的回答:
鱼聪明 AI 地址:https://www.yucongming.com/
使用 Canal 进行 MySQL 到 Elasticsearch 数据同步具有多方面的好处,同时也可能面临一些潜在的问题。让我们详细来看一下。
好处
- 实时性高: Canal 可以实时监听 MySQL 的 Binlog 日志变更,将变更数据迅速同步到 Elasticsearch。这种实时性能够满足许多对数据更新要求较高的场景,如搜索引擎、实时分析等。
- 无代码侵入: 使用 Canal 进行数据同步,不需要在应用程序中添加额外的写入逻辑或代码。它作为一个独立的服务监听 Binlog,对原有系统没有侵入性,不会修改原有的业务逻辑。
- 减少系统负担: 相比于直接在应用程序中实现数据双写或通过消息队列进行异步同步,Canal 可以减少数据库的负担。它直接监听 Binlog,而不需要额外的数据库读取操作,因此对数据库性能的影响较小。
- 支持增量同步: Canal 的核心功能是基于 MySQL 的增量日志(Binlog)进行数据同步。这意味着可以精确捕获每一次数据变更,避免了全量同步的性能瓶颈和数据一致性问题。
- 灵活性和可扩展性: Canal 支持多种数据源的同步,并且可以配置多个消费端,从而提高了系统的扩展性和灵活性。可以根据具体需求灵活配置同步的规则和目标。
- 开源社区支持: Canal 是阿里巴巴开源的项目,在社区中有较为活跃的维护和支持,可以从社区中获取到丰富的文档、问题解答和更新。
可能产生的问题
尽管使用 Canal 可以带来诸多好处,但也有一些可能的问题需要注意:
- 性能消耗: Canal 需要实时监听 MySQL 的 Binlog,并且将数据转发到目标系统(如 Elasticsearch)。在高并发或大数据量的情况下,可能会对服务器资源(CPU、内存、网络带宽)造成一定压力。
- 部署和维护复杂性: Canal 作为一个独立的服务需要单独部署和维护,这增加了系统的复杂性和运维成本。特别是在需要监控、调优和升级时,可能需要专门的运维人员或团队来管理。
- 数据一致性: 尽管 Canal 本身是为了实现数据同步而设计的,但在实际应用中,仍然需要注意数据一致性的问题。特别是在网络传输或数据处理过程中可能出现的中断、延迟或错误,都有可能导致数据同步的不一致。
- 版本兼容性: Canal 的版本更新可能会引入新的功能或修复问题,但同时也可能带来与现有环境不兼容的风险。在升级 Canal 版本时需要谨慎测试和规划,以确保不影响现有业务的稳定性。
- 安全性: Canal 需要连接到 MySQL 数据库获取 Binlog 日志,因此在安全设置方面需要注意,确保 Canal 的访问权限受到正确的限制和保护,避免因权限问题导致的安全风险。
综上所述,使用 Canal 进行 MySQL 到 Elasticsearch 的数据同步是一种高效、实时的解决方案,但需要在性能、部署复杂性、数据一致性和安全性等方面进行综合考量和管理。
欢迎交流
本文主要介绍 MySQL 同步数据到 ES,一些主流的解决方案,以及如何利用开源中间件去提高性能,在文末还有三个问题关于数据同步,欢迎小伙伴在评论区进行留言!近期面试鸭小程序已全面上线,想要刷题的小伙伴可以积极参与!

1)数据一致性问题是否会影响你的应用?
2)你的系统是否能够处理高吞吐量的数据同步?
3)你如何管理和调优数据同步解决方案的部署复杂性?
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » MySQL 如何实现将数据实时同步到 ES ?

发表评论 取消回复