python爬虫篇(项目案列讲解-爬取小说)
大家谨记爬虫只是用来方便大家从互联网上检索信息,获取免费资源,不得以危害或者窃取对方资源使用为目的进行违法犯罪。牢记网络安全法。
1.爬取笔趣阁小说。
学习一下思路:
1.我们进入需要爬取到的小说界面,右键开发者工具 ,选中元素显示,然后找到需要爬取的小说章节模块在代码中的位置。
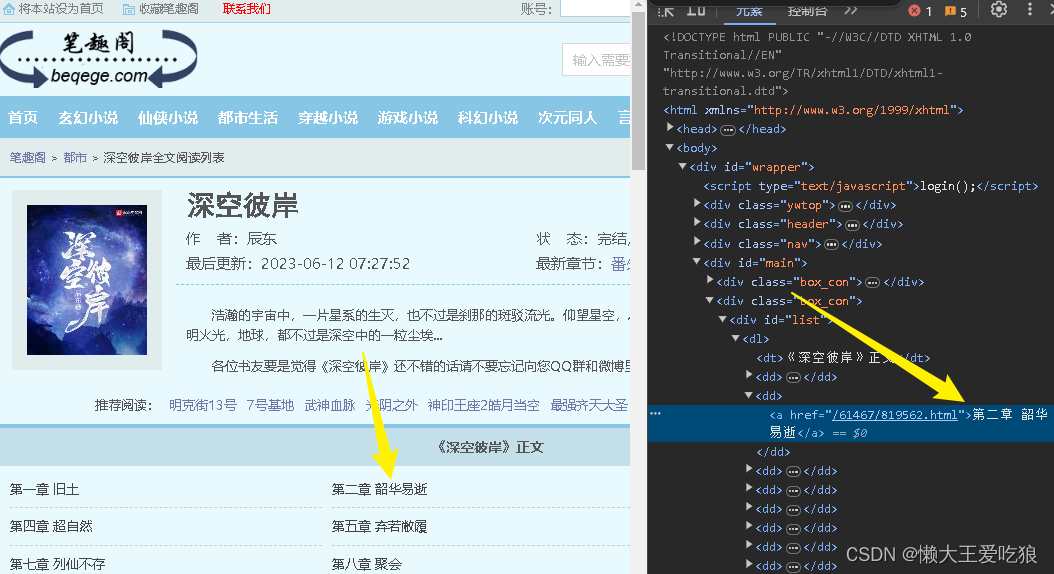
将a标签中的文本内容复制,然后ctrl+u打开源代码 ctrl+f将刚刚的文本内容复制查找是否有这个模块。(比较爽的是,刚好这里有,可以不需要去查看网络请求和script代码了)
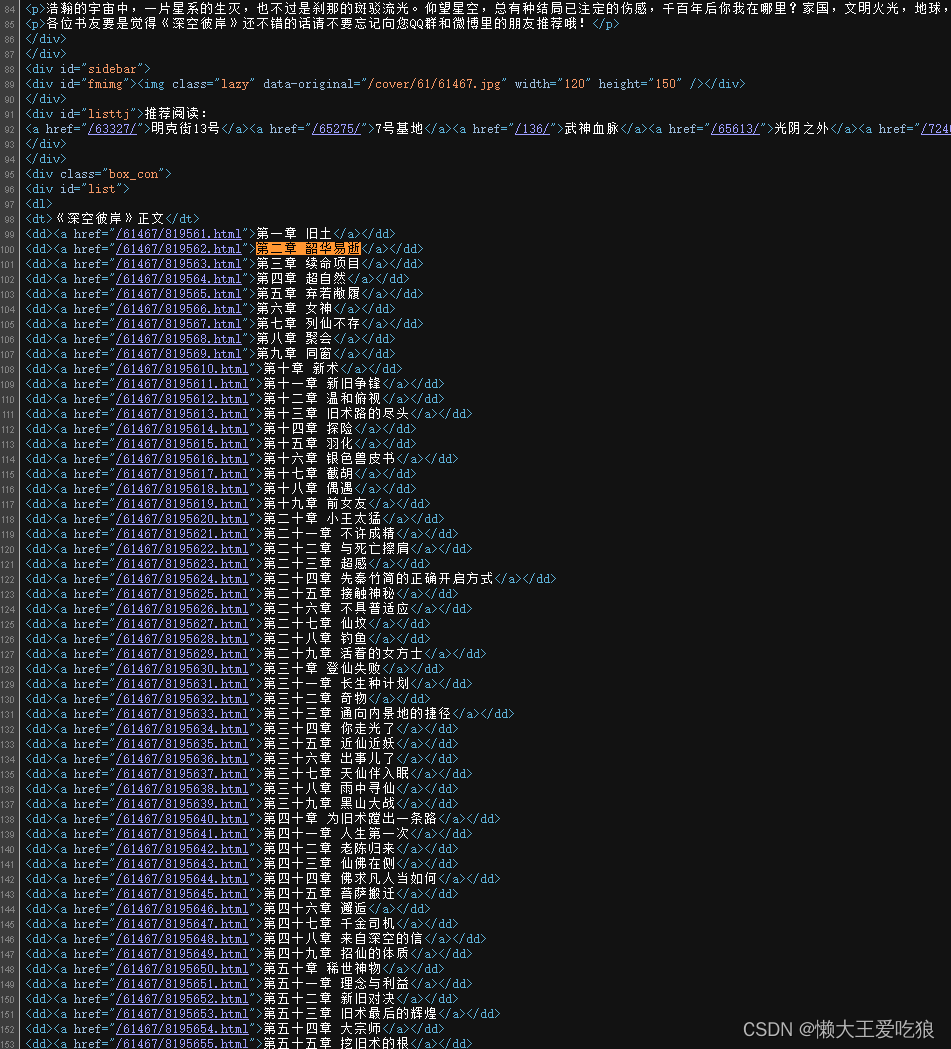
那么我们现在可以可以来获取源代码了
import requests
from lxml import etree
# 网页网址(指向小说章节的那部分)
url = "https://www.bige3.cc/book/3319/"
#UA伪装
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"
}
#获取源代码请求 注意参数的书写
response = requests.get(url,headers=headers)
#源代码的具体编码格式建议先看一下网页中的meta设置的编码格式 meta中的charset
response.encoding = 'utf-8'
#赋值
webCode = response.text
编码格式的查看方式。
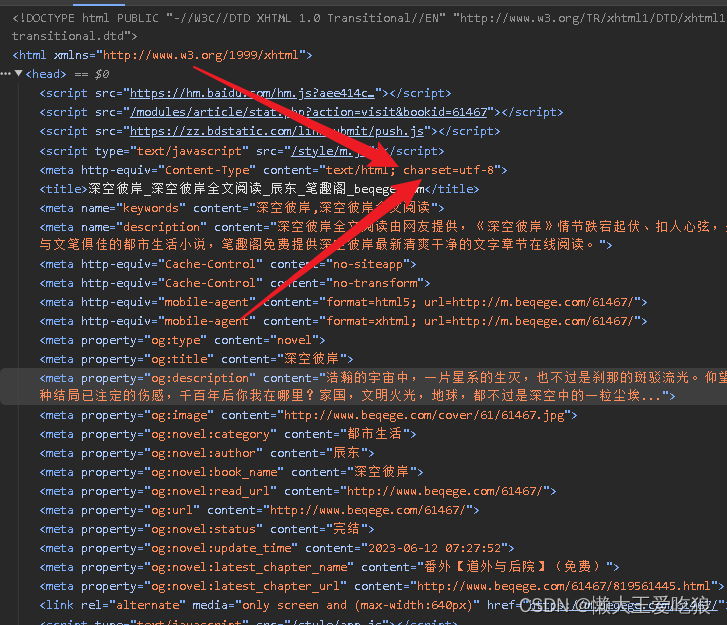
获取源代码之后,我们现在需要去解析一下这串源代码
选中这个章节,你现在需要做的是右键->复制->复制xPath 然后回到python代码中按照格式填写即可
实例图
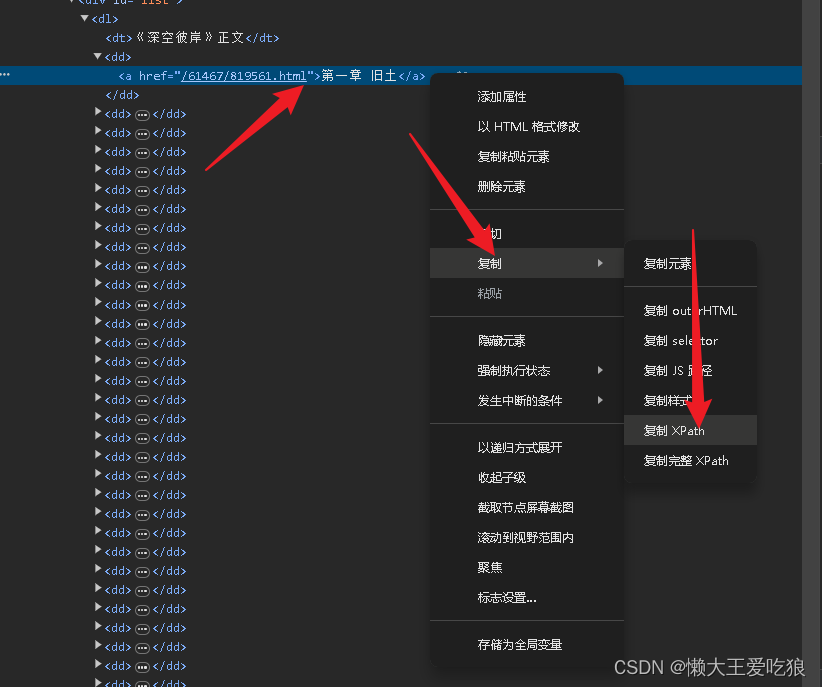
复制粘贴基本成功
import requests
from lxml import etree
# 网页网址(指向小说章节的那部分)
url = "https://www.bige3.cc/book/3319/"
#UA伪装
header = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"
}
#获取源代码请求 注意参数的书写
response = requests.get(url,headers=header)
#源代码的具体编码格式建议先看一下网页中的meta设置的编码格式 meta中的charset
response.encoding = 'utf-8'
#赋值
webCode = response.text
#创建一个etree对象
en = etree.HTML(webCode)
li = en.xpath('//div[@class = "listmain"]/dl/dd[1]/a//@href')
#创建新的url请求
print(li)
newUrl = "https://www.bige3.cc"+li[0]
print(newUrl)
note = requests.get(newUrl)
print(note.text)
打印后我们可以获取到这个章节对应的网页信息。
我们需要的小说,所以现在我们需要解析note,通过下面的信息,我们可以发现需要的文字在一个div中的文字形式,所以直接解析获取文本即可。重复上面步骤,按照相同的代码结构进行书写。
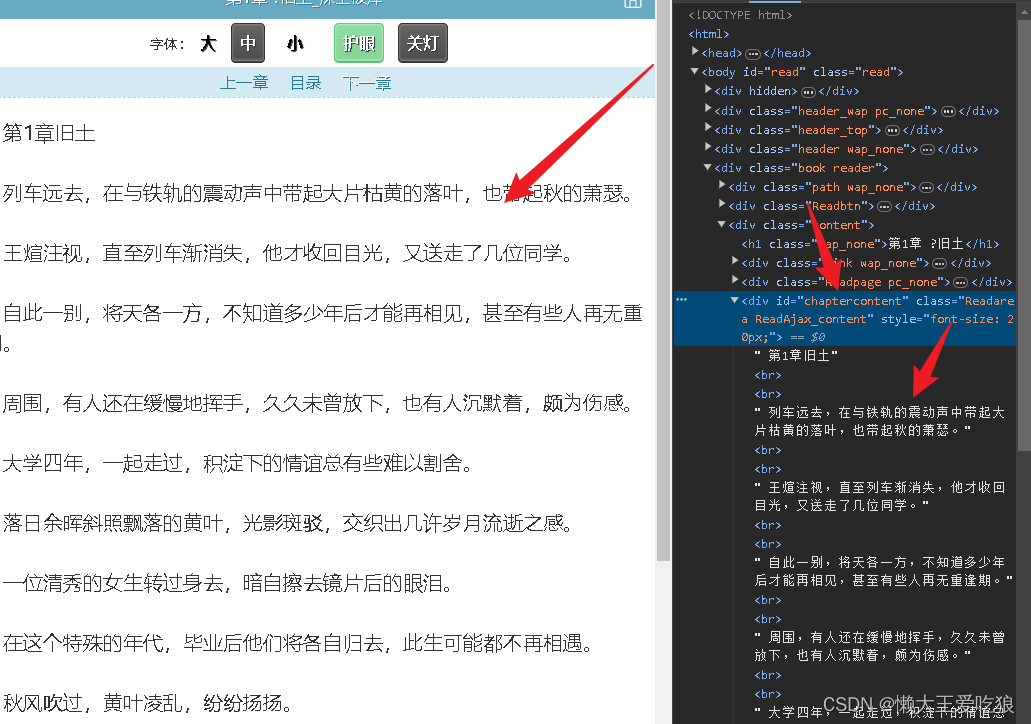
完整代码
import requests
from lxml import etree
# 网页网址(指向小说章节的那部分)
url = "https://www.bige3.cc/book/3319/"
#UA伪装
header = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"
}
#获取源代码请求 注意参数的书写
response = requests.get(url,headers=header)
#源代码的具体编码格式建议先看一下网页中的meta设置的编码格式 meta中的charset
response.encoding = 'utf-8'
#赋值
webCode = response.text
#创建一个etree对象
en = etree.HTML(webCode)
li = en.xpath('//div[@class = "listmain"]/dl/dd[1]/a//@href')
#创建新的url请求
newUrl = "https://www.bige3.cc"+li[0]
note = requests.get(newUrl)
note.encoding = 'utf-8'
noteText = etree.HTML(note.text).xpath('//div[@id="chaptercontent"]/text()')
for t in noteText:
with open("小说.txt",'a',encoding='utf-8') as file:
file.write(t)
file.write('\n')
print("成功下载")
效果展示:

那么如果我需要爬取一整书籍呢?
我们再来看一下目录的结构。每一章节对应的链接所在的结构都是一样的,全部存在于dl->dt->dd->a->href 所以我只需要获取全部的dd标签,然后一个for循环遍历所有的dd标签,然后内部再写一个for循环,即可获取正本书籍
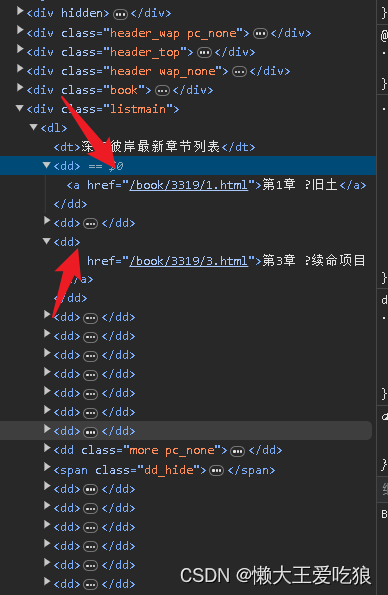
获取整本书的代码:
import requests
from lxml import etree
# 网页网址(指向小说章节的那部分)
url = "https://www.bige3.cc/book/3319/"
#UA伪装
header = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"
}
#获取源代码请求 注意参数的书写
response = requests.get(url,headers=header)
#源代码的具体编码格式建议先看一下网页中的meta设置的编码格式 meta中的charset
response.encoding = 'utf-8'
#赋值
webCode = response.text
#创建一个etree对象
en = etree.HTML(webCode)
#获取全部的dd标签
li = en.xpath('//div[@class = "listmain"]//dl//dd')
index = 0
bookLen = len(li)
for i in li:
#创建新的url请求
try:
# 解析dd 这里为什么不需要书写etreed对象获取呢?
# 因为li数组本身就是一个解析后的etree元素列表,
# 所以i本身就是一个etree元素,可以直接使用xpath
#这里注意使用[0] xpath解析获取到的都是数组形式
bookWeb = i.xpath("./a/@href")[0]
newUrl = "https://www.bige3.cc"+ bookWeb
note = requests.get(newUrl)
note.encoding = 'utf-8'
noteText = etree.HTML(note.text).xpath('//div[@id="chaptercontent"]/text()')
for t in noteText:
with open("小说.txt",'a',encoding='utf-8') as file:
file.write(t)
file.write('\n')
print(f"书本下载({index}/{bookLen})")
index+=1
except:
print("章节下载失败")
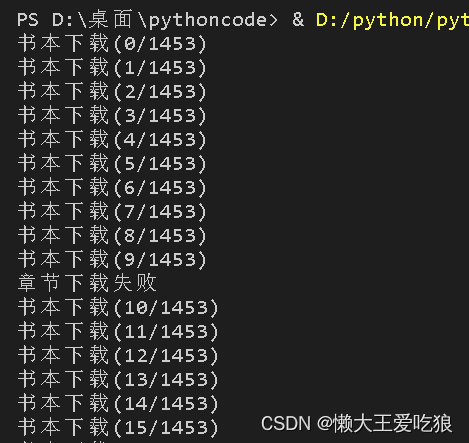

提高效率(对对方服务器危害较大,线程数量尽量使用小一点的)
我们会发现当将写入小说的部分注释掉,将url打印时我们会发现,几乎2-3s就可以全部打印,写文件是最耗费时间的,所以一个线程肯定是不够的,这里需要用到多线程提高效率,不会的可以去学一下线程池的使用。 我们发现这个文章是乱序的,这是由于并发引起的,可以加入互斥锁进行爬取。
import requests
from lxml import etree
from concurrent.futures import ThreadPoolExecutor
def download_chapter(chapter_url):
try:
response = requests.get(chapter_url, headers=header)
response.encoding = 'utf-8'
noteText = etree.HTML(response.text).xpath('//div[@id="chaptercontent"]/text()')
with open("小说.txt", 'a', encoding='utf-8') as file:
for t in noteText:
file.write(t + '\n')
print(f"章节 {chapter_url} 下载完成")
except Exception as e:
print(f"章节 {chapter_url} 下载失败:{e}")
if __name__ == "__main__":
url = "https://www.bige3.cc/book/3319/"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"
}
response = requests.get(url, headers=header)
response.encoding = 'utf-8'
webCode = response.text
en = etree.HTML(webCode)
li = en.xpath('//div[@class = "listmain"]//dl//dd')
chapter_urls = ["https://www.bige3.cc" + item.xpath("./a/@href")[0] for item in li]
with ThreadPoolExecutor(max_workers=5) as executor: #根据需求加入线程大小
executor.map(download_chapter, chapter_urls)
完整代码↓↓↓可取

如有侵权,请联系删除。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » python爬虫篇(项目案列讲解-爬取小说)

发表评论 取消回复