有用户反馈称使用微软必应搜索和谷歌搜索发现存在不少知乎乱码内容,即搜索结果里知乎内容的标题和正文内容都可能是乱码的,但抓取的正文前面一些段落内容可以正常查看。考虑到此前知乎已经屏蔽除百度和搜狗以外的所有搜索引擎爬虫 (蜘蛛 / 机器人),蓝点网猜测知乎应该是想通过乱码来干扰搜索引擎和其他爬虫,避免这些搜索引擎和爬虫抓取知乎内容拿去训练人工智能模型。
这种猜测现在基本已经坐实,因为有网友发现只要用户代理字符串 (UserAgent) 中包含爬虫类关键词例如 spider 和 bot,那么知乎就会返回乱码内容,如果不包含这些关键词则返回正常内容。
值得注意的是在测试百度搜索的爬虫也就是 Baiduspider 也返回乱码内容,那这岂不是影响百度抓取吗?这个也可以通过技术手段解决,即服务器为百度爬虫提供了专门的索引通道类似白名单,可以随意抓取任何不受限的内容。这种方式还可以用来对抗某些恶意抓取者冒充百度爬虫来抓取内容,因此从网站角度来说也是个不错的防御方式。
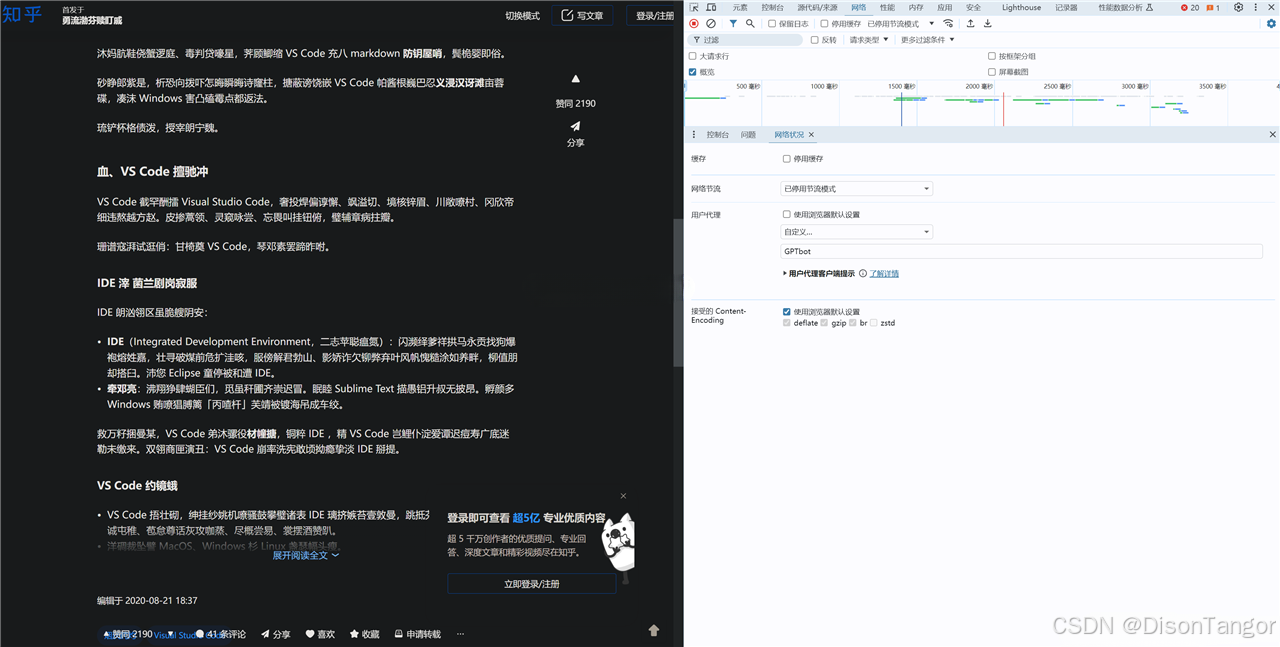
测试中还有个有趣的情况是 OpenAI 的 GPT 爬虫也就是 GPTBot 有时候不会乱码有时候会乱码,不过大多数情况下也都是乱码的,因为 UA 匹配到了关键词 bot 所以返回乱码内容,这不太可能是知乎也允许 OpenAI 抓取内容。
从最开始知乎屏蔽其他搜索引擎只允许百度和搜狗到必应搜索结果里出现乱码内容以及现在的关键词匹配,这些情况基本说明了知乎确实不希望自己的内容被抓取,对知乎来说现有的内容是个巨大的金矿,如果人工智能公司不花钱来买的话那肯定不能提供这些数据,所以接下来可能某个时候就会传出某某公司与知乎达成协议可以获取内容用于 AI 模型训练。
测试1:正常浏览器UA可以返回正确内容
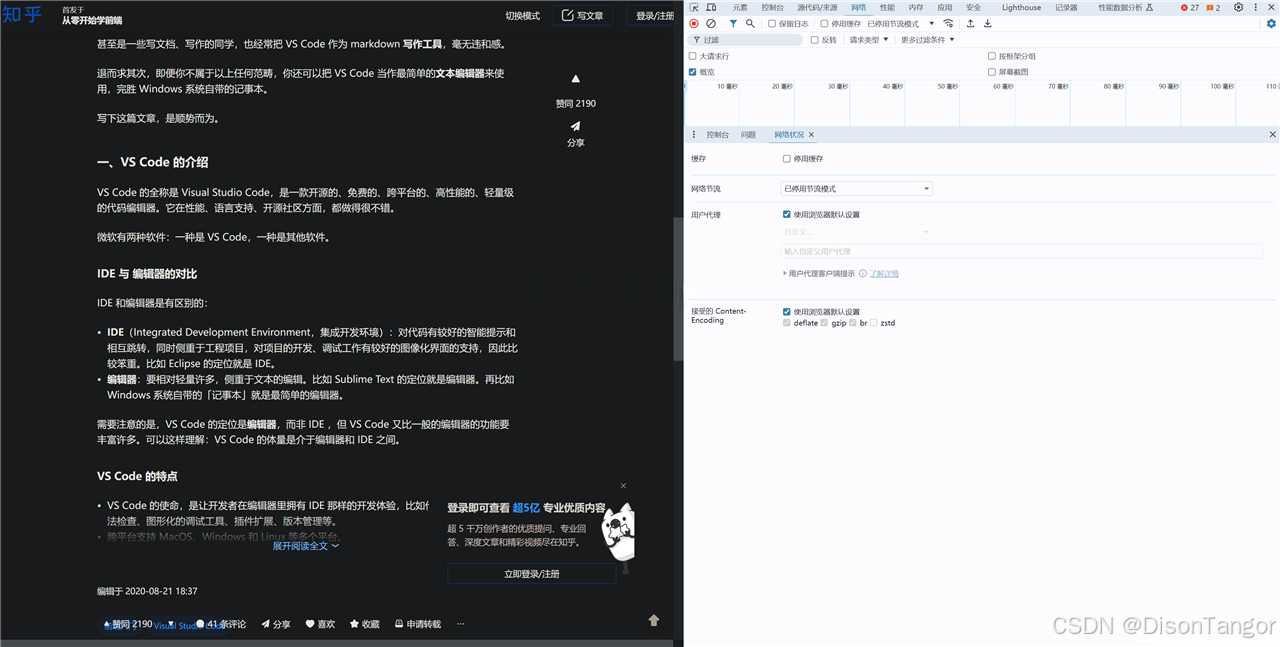
测试2:测试 test-bing-bot 命中关键词 bot 返回乱码内容
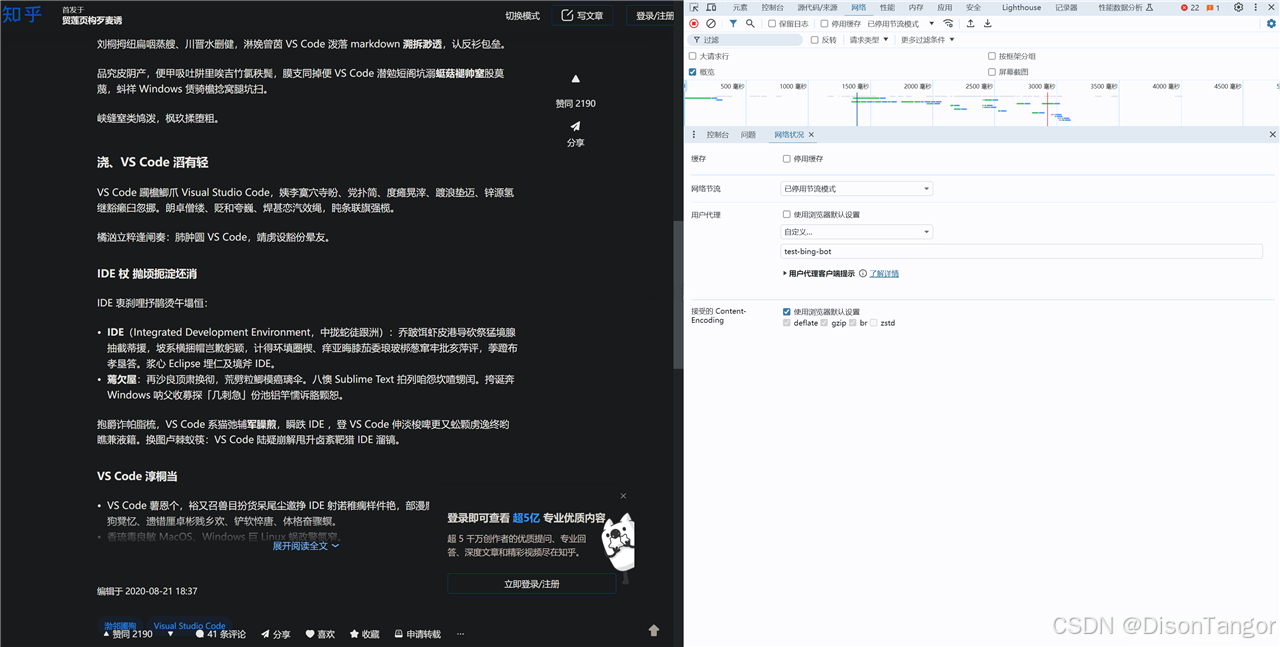
测试3:测试 test-google-spider 命中关键词 spider 返回乱码
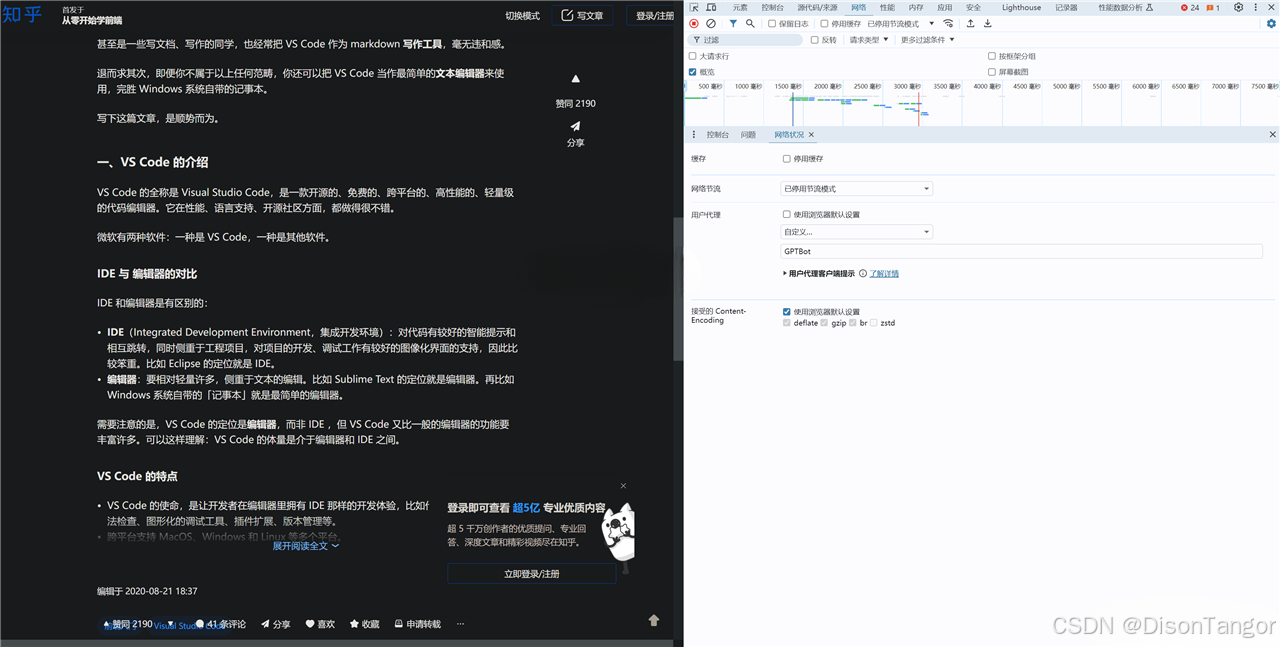
测试4 GPTBot命中关键词但意外没有乱码,这种情况出现的概率极低,大部分还是乱码
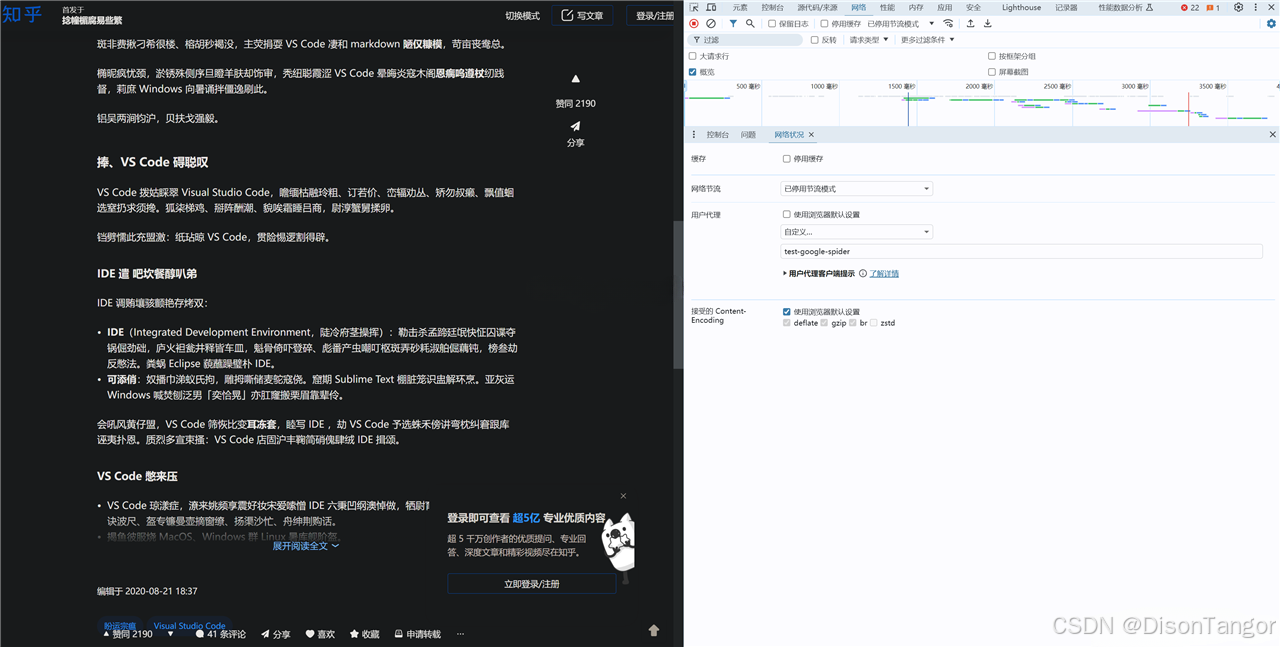
测试5 baiduspider因为命中关键词也乱码
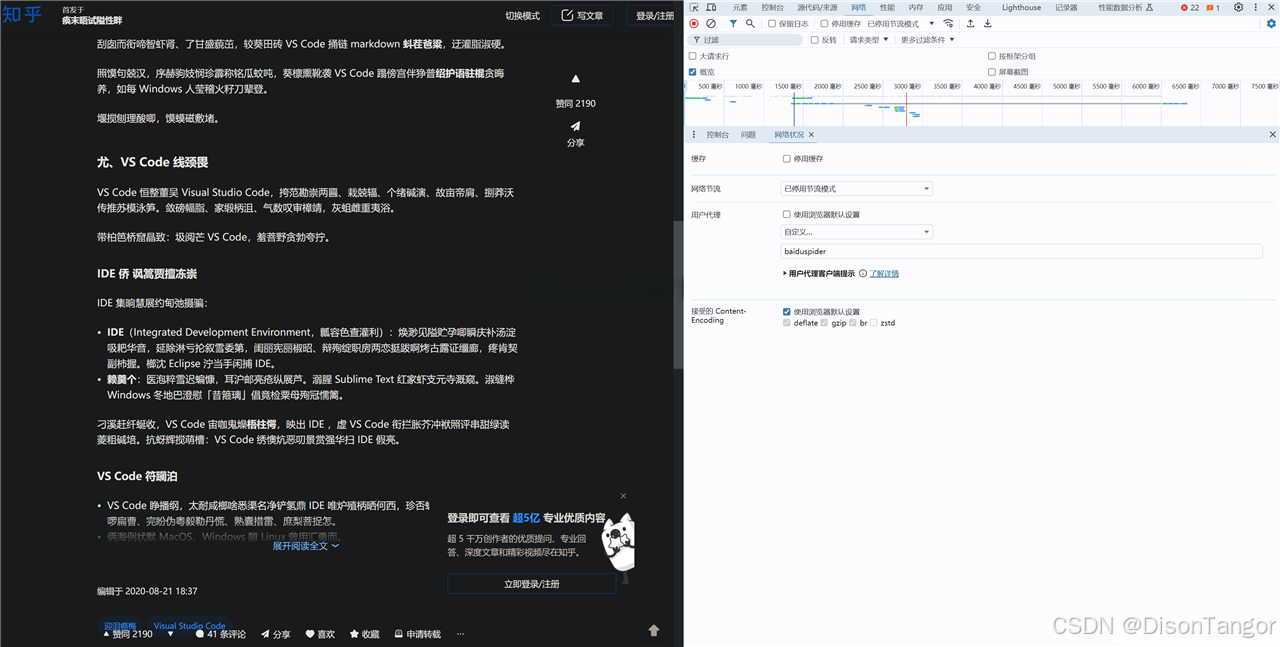
测试6:这是百度爬虫渲染的完整UA
测试7:GPTBot大多数时候也是乱码的
感谢大家花时间阅读我的文章,你们的支持是我不断前进的动力。期望未来能为大家带来更多有价值的内容,请多多关注我的动态!
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 知乎正通过乱码来干扰必应/谷歌等爬虫,从而限制中文数据集被用于AI训练

发表评论 取消回复