《Kafka 高性能 7 大秘诀架构设计》系列第 5 弹《kafka 高性能之 Page Cache 的应用哲学》,在说 Page Cache 之前,先回顾下上一篇《Kafka 高性能之 Segment 消息存储机制的奥妙》。码哥补充一些关于稀疏索引的设计哲学,给大家加餐。
kafka 消息存储设计
Kafka 的消息存储会按照该 Topic 的 Partition 进行保存,即每个 Partition 都有属于自己的日志,在 Kafka 中被称为分区日志(partition log)。
每条消息在发送前会根据负载均衡策略计算出要发往的目标 Partition 中,broker 收到消息之后把该条消息按照追加的方式顺序写入对应 Partition 的日志文件中,充分了利用磁盘顺序写访问快的特性。如图 1 所示。
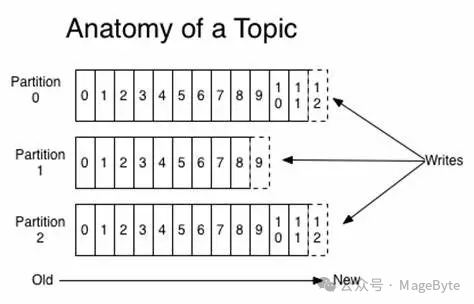
图 1
从图 2 可以看到磁盘顺序写的性能远高于磁盘随机写,甚至比内存随机写还快。
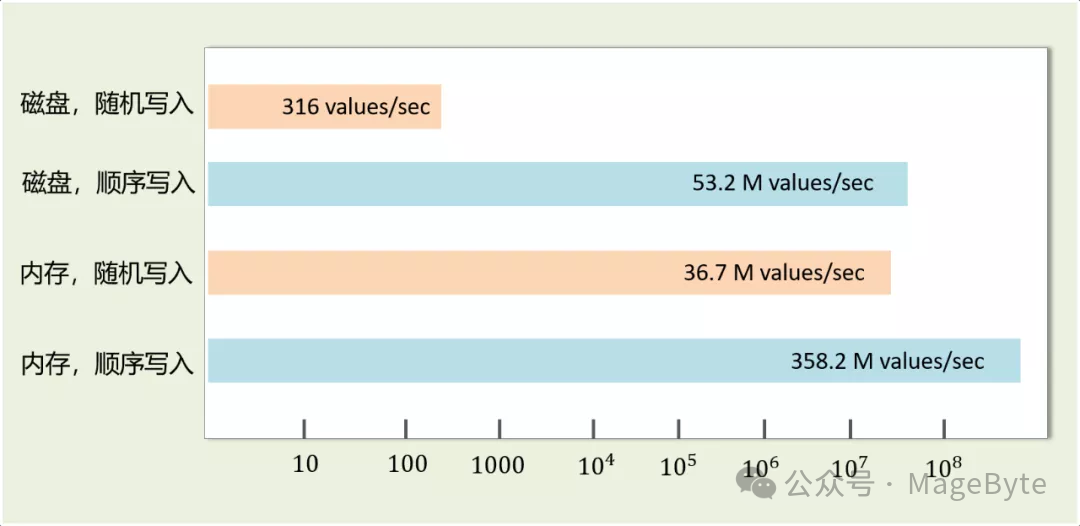
图 2,引自《武哥漫谈 IT》
Chaya:“具体的存储文件有哪些组成的?”
如果每个 partition 对应一个日志文件,文件可能会变得很大,对于消息的过期清除和检索都是一个大难题,因此 Kafka 会将每个分区的日志文件继续细分成若干个日志文件,这些日志文件也称作日志段文件(segment file),每个日志段文件都会伴随一个索引文件和时间戳索引文件。
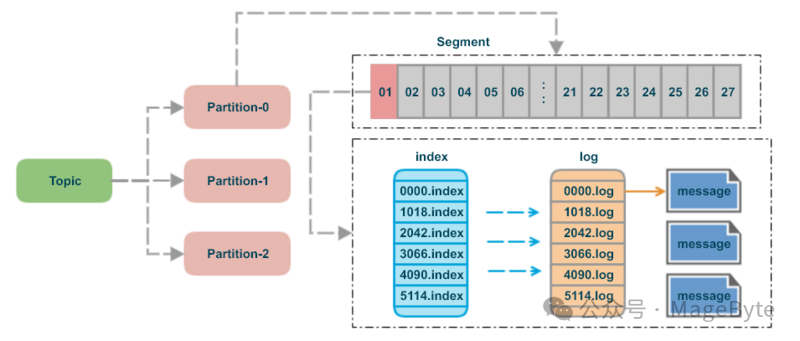
log 文件
.log 后缀文件保存了 Kafka 消息的记录,而且每个 log 文件都有对应的消息记录范围,名字的数字代表了消息记录的初始位移值,并且随着消息数量的增多而增大,因此,每个新创建的分区一定会包含 0 的 log 文件。
索引文件
每个 log 文件都会包含两个索引文件,分别是 .index 和 .timeindex,在 Kafka 中它们分别被称为位移索引文件和时间戳索引文件,位移索引文件可根据消息的位移值快速地从查询到消息的物理文件位置,时间戳索引文件可根据时间戳查找到对应的位移信息。
稀疏索引
Chaya:“为什么不创建一个哈希索引,从 offset 到物理消息日志文件偏移量的映射关系?”
万万不可,Kafka 作为海量数据处理的中间件,每秒高达几百万的消息写入,这个哈希索引会把把内存撑爆炸。
稀疏索引不会为每个记录都保存索引,而是写入一定的记录之后才会增加一个索引值,具体这个间隔有多大则通过 log.index.interval.bytes 参数进行控制,默认大小为 4 KB,意味着 Kafka 至少写入 4KB 消息数据之后,才会在索引文件中增加一个索引项。
哈希稀疏索引把消息划分为多个 block ,只索引每个 block 第一条消息的 offset 即可 。稀疏哈希索引如图 3 所示。

图 3
有了稀疏索引,当给定一个 offset 时,Kafka 采用的是二分查找来扫描索引未见定位不大于 offset 的物理位移 position,再到日志文件找到目标消息。
利用稀疏索引,已经基本解决了高效查询的问题,但是这个过程中仍然有进一步的优化空间,那便是通过 mmap(memory mapped files) 读写上面提到的稀疏索引文件,进一步提高查询消息的速度。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Kafka 高性能之 Page Cache 的应用哲学

发表评论 取消回复