作者简介:刘志诚,乐信集团信息安全中心总监、OWASP广东区域负责人、网安加社区特聘专家。专注于企业数字化过程中网络空间安全风险治理,对大数据、人工智能、区块链等新技术在金融风险治理领域的应用,以及新技术带来的技术风险治理方面拥有丰富的理论和相关经验。

奥特曼去年年底被伊利亚逼宫的起因就在于奥特曼与伊利亚在开发强大的人工智能以及在安全的基础上开发强大人工智能之间的分歧,据VOX报道,伊利亚虽然并未在逼宫失败后离职,但已经不去公司,仅远程领导超级对齐团队。而最近这次的导火索就在于4月份OpenAI以泄密为由解雇了超级对齐团队的两名员工,然后伊利亚辞职,超级团队的联合领导人雷克也在2天后辞职。伊利亚保持了体面,但雷克表达了在超级对齐项目资源使用上与公司领导人发生了巨大的分歧。根据OpenAI与离职员工以股票保留为前提的保密协议,OpenAI内部几乎没有针对这件事情的相关信息。
前几天我在朋友圈简单评述了这件事:
“这是去年11月OpenAI宫斗事件的延续,安全也意外的暴露在前沿科技的聚光灯下,从倒置的原因来看这本身是对风险认知和风险治理的理念之争。
首先是风险认知,什么叫做风险?是已知安全事故溯因的威胁与脆弱性还是对未来安全事故的威胁和脆弱性预测?个人倾向于前者,毕竟未知的预测存在不确定性和误判,但如果不做这个努力,我们能不能接受悲观预测的结果?
AI如果超越人类(不是个体而是整体),可能导致人类的毁灭,这是马斯克的悲观预测也是与奥特曼的分歧所在。这次伊利亚只不过是认为已经到达或越过了平衡点,显然,奥特曼认为还没达到。
20%算力用于对齐人类利益的风险预测与治理,符合张亚勤院士10-30%的认知,但对于了解OpenAI的伊利亚和奥特曼而言,这个分歧不可调和。
整体上而言,虽然我也做安全,从我对风险认知的观点来看,目前我站奥特曼,基于预测和假设的安全仍未达到超越AI发展优先级的平衡点,发展AI能力仍是优先事项。”
想写篇文章,想着不能信口开河,就去找了下OpenAI关于安全的相关资料,看了下Preparedness的框架和超级对齐团队的论文,顺便分享下,再做观点输出。

OpenAI安全的目标是安全部署模型,实现模型行为一致性,保障基础模型的安全与道德推理机能,提供端到端的安全基础设施,通过人类与人工智能的协作开发符合人类价值观的策略。
OpenAI的人工智能安全(Safety)分成三个团队,安全系统团队负责AI模型部署的安全性,稳健型和可靠性,针对现在的模型;安全实战(Preparedness)团队负责前沿模型的安全评估。针对前沿模型;超级对齐(Superalignment)团队负责超级人工智能安全风险进行监管对齐人类目标的研究,针对未来的模型。
1、安全系统团队
安全系统团队面对的问题包括,确保模型提供有价值,值得信赖的答案,避免给出不安全,不适当的答案;检测未知的有害答案,操作和用法;安全的保护用户隐私;构建人工智能与用户的协作并代表用户安全的行动;通过红队模型的合作发现失败案例;利用人类专业知识指导人工智能安全;分享经验与解决方案提高行业的安全性。
安全系统的团队以人工智能来解决上述挑战,构建通用解决方案,实现安全与实用性之间的平衡,防止对人类请求的过度拒绝。要求团队具备扎实的工程能力和强大的基础设施建设运营能力,在持续研究的基础上对安全风险缓解措施持续迭代,设计和构建以模型功能为中心的安全服务,自动化的调查,分析,决策,实现数据飞轮驱动的反馈人工智能模型。
安全系统团队包括四个小组,安全工程小组实施系统级的风险缓解措施,构建安全,隐私的集中式安全服务基础设施,以机器学习为中心的工具进行大规模的部署;模型安全研究小组,关注模型行为一致性,创建更安全,行为符合价值观,可控可靠的模型;安全推理研究小组,关注检测与理解已知和未知的风险,指导默认安全行为和设计缓解措施;人机交互小组将模型行为与人类价值观对齐,与模型一起设计政策,并根据人类专家反馈,保障人工智能的行为与人类期望一致。
2、安全实战准备团队
该团队在2023年12月18日发表了准备框架,阐述了其主要工作。框架的5个核心要素包括评估跟踪风险水平;寻找未知的未知风险;确定安全基线,实地开展工作;创建跨职能的安全咨询团队。
OpenAI的首要责任是对人类的维护,承诺通用人工智能安全所需的研究,本框架给出安全协调的总体方法,目标是减少模型的偏见,幻觉,误用,通过安全承诺和保障措施实现对人工智能的信任,鼓励行业以类似的方法努力保障人工智能安全。
考虑模型微调类型不同风险发生的概率不同,为了实现针对不同风险采用不同缓解措施,OpenAI把风险分成四类: 网络安全(Cyber Security)风险;化学、生物、核、辐射(CBRN)风险;劝导风险;模型自主风险。
针对不同类型的风险,给出不同的风险评级。
网络安全风险,对网络攻击来看,无法执行有效的行动是低级,有效的提升人的效率至两倍是中级,自动化的验证漏洞是高级,基于目标自动化执行攻击是关键风险。
CBRN,给出信息是低级,提出改进是中级,可以协助本科生水平制造是高级,可以协助任何人制造是关键风险。
劝导,说服人类改变信仰或采取行动。提供文档是低级,达到人工文档水平是中级,达到变革推动者的水平是高级,让所有人违背自己的自然意愿行动是关键风险。
模型自主,是适应环境,自我渗透,自我改善,规模化扩展,利用资源自主实现目标。可以执行不连贯行动为低级,执行连贯行动获取资源为中级,执行生产性ML,开发新型任务是高级,执行自我智能研究是关键风险。
小组以缓解前的风险评级,缓解措施,缓解后的风险评级,形成风险计分卡,并以此确定安全基线。策略要求仅对补救后的中等风险,缓解后为高的模型才允许开发。任何高风险以上模型需要进行安全调整,防止模型外泄。
实地工作小组输出报告,定期补充证据,给出变更建议,协调安全团队整理缓解措施,纳入报告,与第三方可信人工智能团队协调进行第三方审计。
成立安全咨询小组(SAG)帮助领导层和董事会做好安全决策准备,包括监督风险评估,应急处理紧急情况的快速通道。
3、超级人工智能对齐团队
2023年7月5日成立,由伊利亚和雷克领导,预测超级人工智能10年内可以实现,解决比人类智能高级的超级人类智能遵循人类意图,认为目前人类监督RLHF难以满足需求,需要科学性突破。计划的方法是采用人工智能的方法监管人工智能,核心在于弱人工智能对强人工智能的泛化。计划在未来四年以20%的计算量解决超级对齐问题。
该团队在2023年12月14日发表了论文《WEAK-TO-STRONG GENERALIZATION: ELICITING STRONG CAPABILITIES WITH WEAK SUPERVISION》阐述了研究的初期成果。

论文提出,强模型是否会根据弱监督者的潜在意图进行泛化——即使在弱监督者只能提供不完整或有缺陷的训练标签的困难问题上,也能利用其全部能力来解决任务?认为天真的人类监督——例如来自人类反馈的强化学习(RLHF)——如果不进行进一步的工作,可能很难扩展到超人类模型,但是大幅提高从弱到强的泛化能力是可行的。
通过辅助置信损失鼓励强模型进行置信预测,使用中间模型引导监督,使用无监督微调改进模型表征,可以提高模型的性能,例如GPT-2监督GPT-4进行NLP任务时,可以弥补弱模型和强模型之间80%的性能差距。不过研究也发现,并不是所有场景都有效,其中RM场景更差。因此,本论文仅相当于是概念证明,并不是可部署的实际解决方案。
同时论文也指出,未来的人工智能理解并模仿人类,输出人类水平的知识,而不是超级人工智能能力的知识,因此,概念验证的泛化能力未必可以适应弱人工智能对超级人工智能的监管。因此,目前的经验与面对的问题的并不完全一致,未来可能存在泛化的困难。
论文给出的进一步研究方向包括:未来修复设置的不相似之处,使设置更具类比性,验证是否存在严重的不对等性,放宽所做的简化,测试弱强分类其在优化压力下的鲁棒性;开发更好的扩展方法,强人工智能可以直观理解任务,有任务的显著表征,需要的泛化可以满足一些特征在不接触事实的情况下测量特征,如弱监督因错误产生分歧时,可以通过辅助信心损失捕捉到特征,同时,由于概括应该是自然的和突出的,在逻辑上和多提示之间的概括和推理应该是一致的;逐渐提升弱到强泛化的科学理解,对结果差异的原因,弱到强规范差异的程度测量,弱监督的错误的影响等方面进行研究。

虽然OpenAI这里谈的安全(Safety)和我们所关注的安全(Security)不同,Securtiy只是其准备完成框架中四类风险的一种网络安全(Cyber Security),但确实是在谈风险的问题。与我评论的核心论断保持一致,我们对未知的风险应该持一种什么样的态度。
Robert Hanna的一篇论文《OpenAI, The Superalignment Problem, and Human Values》持更加激进的态度,对OpenAI超级团队“我们不需要先解决人类价值观和价值聚合的难题,就能很好的对齐超级人工智能,使其避免令人震惊的灾难性后果”的结论从哲学的角度进行了质疑。引用了从谷歌离职的机器学习之父辛顿的观点,认为对待人工智能我们需要向反思曼哈顿计划一样,以令人尊敬的新技术卢德主义者那样持坚决的反对态度。
虽然出发点可能与奥特曼截然不同,但Hanna的观点对超级对齐团队的工作的影响可能相同,奥特曼只是觉得优先级没那么高,Hanna则觉得这方法既不可行也没有效。
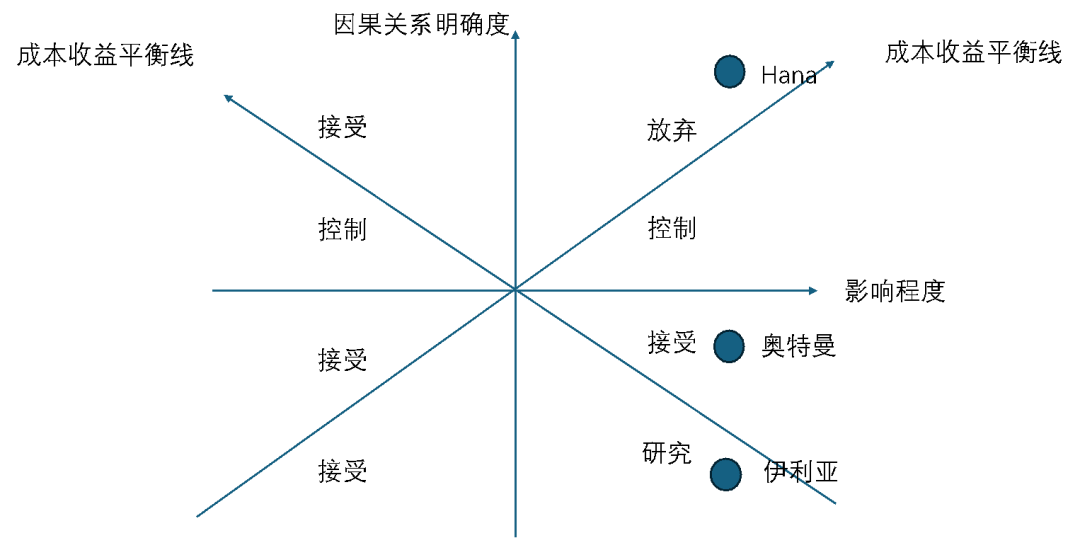
风险一般以概率和影响程度进行等级划分,结合成本效益的风险接受度作为风险控制措施决策的依据,这个理论相对于已知风险而言是个理想的模型。但相对于未知风险,由于并没有明确的风险控制措施,且概率亦不可知,这个理论的风险模型就面临挑战。
我以因果关系明确度替代风险发生的概率,对未知风险缓解措施的方案进行评估。影响程度低,因果关系明确,成本低于收益可以控制,其它状态均接受相关风险。对于影响程度高,因果关系明确,成本低于收益控制,成本高于收益放弃项目。因果关系不明确,成本低于收益需要研究因果关系,实验控制措施;成本高于收益,暂时接受风险,通过控制成本降低到收益下继续研究,或者待因果关系明确后控制风险或放弃项目,因此这个不是一个稳态,只是暂时的状态。
针对超级人工智能对人类的威胁,属于一个未知风险,既没有概率,也没有控制措施,针对这样的风险,在已知影响程度高,破坏性强的前提下,如果成本收益可控,继续研究是个理想决策,如果收益不可知,成本较大,暂时接受相关风险等待因果关系明确是个可行的选择。因此,伊利亚和奥特曼的分歧是认为超级对齐团队工作处在什么样状态的认知。当然,从Hanna的认知角度来看,这是一个因果关系明确的无解问题,投入多少资源都难以控制风险,就应该放弃。
所以,我的结论仍然保持不变。其实,我们的安全(Security)也一样,要清楚控制措施与风险之间的因果关系是否明确,要不然就要看你的解决方案处在因果关系不明确第四象限的什么位置,才好做决策。
参考文献:
1、https://openai.com/safety-systems/
2、https://openai.com/preparedness/
3、Reimagining secure infrastructure for advanced AI(2024)
https://openai.com/index/reimagining-secure-infrastructure-for-advanced-ai/
4、(Collin Burns,2023) Collin Burns. WEAK-TO-STRONG GENERALIZATION: ELICITING STRONG CAPABILITIES WITH WEAK SUPERVISION
https://arxiv.org/pdf/2312.09390
5、(Robert Hanna,2023). Robert Hanna. OpenAI, The Superalignment Problem, and Human Values.
https://againstprofphil.org/wp-content/uploads/hanna_OpenAI_the_superalignment_problem_and_human_values_jan24.pdf
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 网安加·百家讲坛 | 刘志诚:从安全(Safety)团队看OpenAI之争的本质

发表评论 取消回复