还是话不多说,很久没写爬虫了,来个bs4康复训练爬虫,正好我最近在看《神魂至尊》,爬个txt文件下来看看
直接上代码
"""
神魂至尊网址-https://www.bqgui.cc/book/1519/
"""
import requests
from bs4 import BeautifulSoup
import os
A=[]#存储章节标题
B=[]#存储章节链接
url='https://www.bqgui.cc/book/1519/'
header={
'Referer':'https://www.bqgui.cc/s?q=%E7%A5%9E%E9%AD%82%E8%87%B3%E5%B0%8A',
'Cookie':'Hm_lvt_52624d0257fe48ed9dea61ff01fa3417=1720163550; HMACCOUNT=79B595C42B32BA19; hm=9a7ca0f0fe759c15c8c93eed6eb59f86; Hm_lpvt_52624d0257fe48ed9dea61ff01fa3417=1720163795',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0'
}
reponse = requests.get(url,headers=header)
#print(reponse.text)
html = BeautifulSoup(reponse.text,'lxml')
htmls = html.select('div.listmain dl dd a')
for a in htmls:
# 检查a的文本内容中是否包含特定字符串
if '<<---展开全部章节--->>' not in a.text:
# 如果不包含,则添加到列表A和B中
A.append(a.text)
B.append('https://www.bqgui.cc/' + a['href'])
for j in B:
urls =j
headers={
'Cookie':'Hm_lvt_52624d0257fe48ed9dea61ff01fa3417=1720163550; HMACCOUNT=79B595C42B32BA19; hm=9a7ca0f0fe759c15c8c93eed6eb59f86; Hm_lpvt_52624d0257fe48ed9dea61ff01fa3417=1720164854',
'Referer':'https://www.bqgui.cc/book/1519/',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0'
}
reponses = requests.get(urls,headers=headers)
lxml = BeautifulSoup(reponses.text,'lxml')
lxmls = lxml.select('div.Readarea.ReadAjax_content')
for k in lxmls:
#print(k.text)
for l in A:
directory = '神魂至尊'
if not os.path.exists(directory):
os.makedirs(directory)
with open(f'{'神魂至尊'}/{l}','a')as f:
f.write(k.text + '\n')
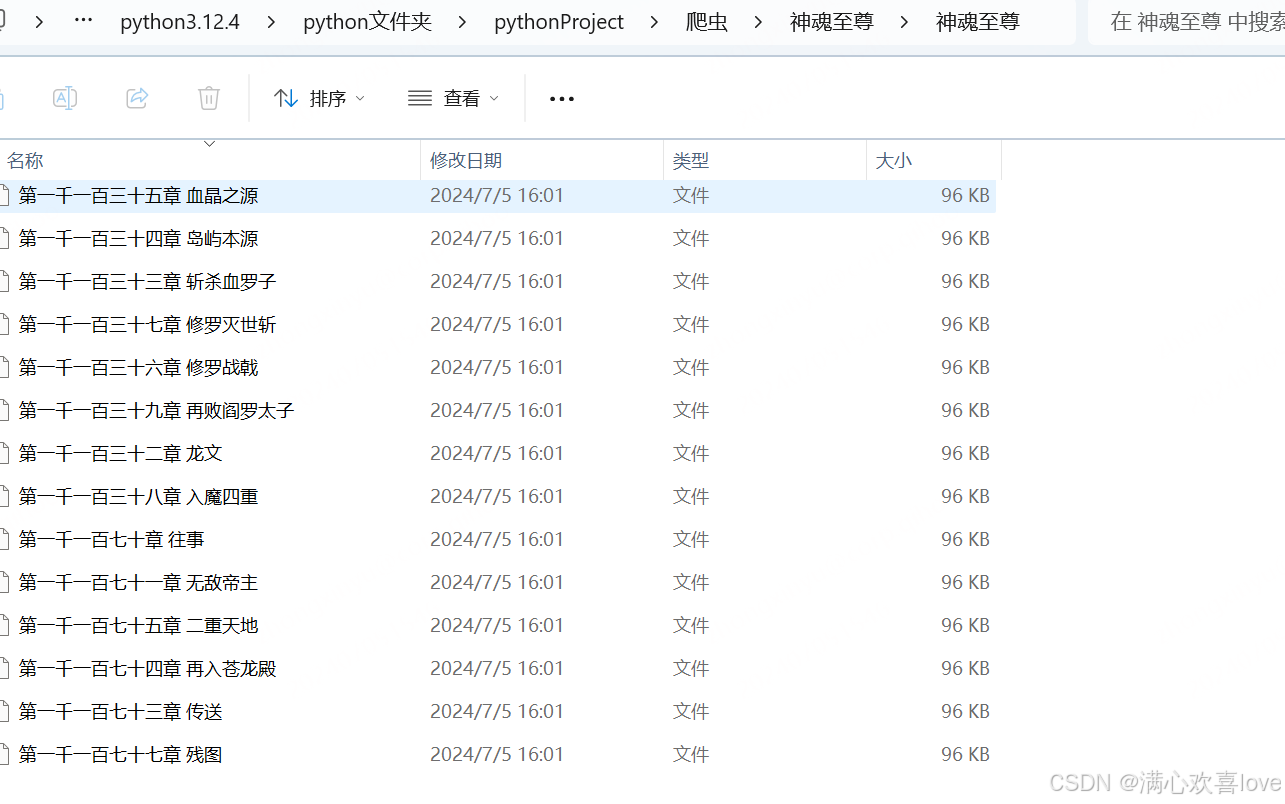
效果图
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Python爬虫康复训练——笔趣阁《神魂至尊》

发表评论 取消回复