B题 洪水灾害的数据分析与预测
亚太中文赛事本次报名队伍约3000队,竞赛规模体量大致相当于2024年认证杯,1/3个妈杯,1/10个国赛。赛题难度大致相当于0.6个国赛,0.8个妈杯。该比例仅供大家参考。
本次竞赛赛题难度A:B:C=3:1:4,选题人数估计A:B:C=1:9:2。基于于本次比赛B题选题人数可能会占据很大的比例的现状,我们将提供两个版本论文,思路完全不同的B题资料【一篇论文+两套代码+售后群不禁言】。下面给大家带来详细的解题思路。
对于数据类型的题目,第一步一定是先进行数据处理,而非直接进行问题一的求解。
数据预处理
缺失值处理:
- 检查数据中的缺失值情况。
- 根据数据分布情况选择合适的填补方法,如均值填补、中位数填补或插值法。
异常值处理:
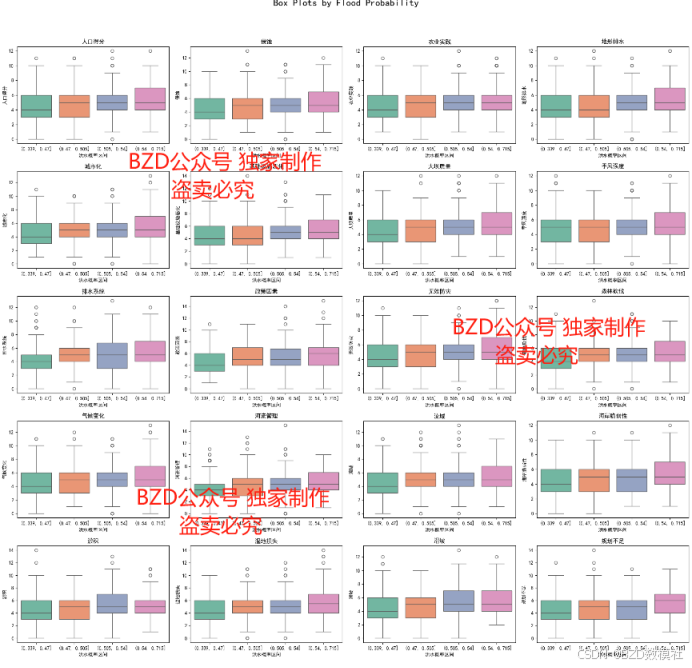
- 绘制箱线图,识别和处理异常值。
- 根据数据的实际意义和分布情况决定是否去除或调整异常值。
数据标准化:
- 对所有数值型数据进行标准化处理,以消除量纲差异对分析结果的影响。
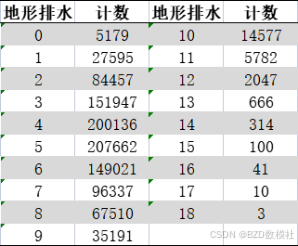
下面进行部分异常值展示,对于数据中提供的各项指标得分中取值区间均为0-17,其中“地形排水”,存在得分为18,该值可以认定为异常值。进行后续的相关处理即可。对于异常值处理的结果,我们可以采用克里斯插值、三次样条等相关处理进行插值即可
问题 1. 请分析附件 train.csv 中的数据,分析并可视化上述 20 个指标中,哪些指标与洪水的发生有着密切的关联?哪些指标与洪水发生的相关性不大?并分析可能的原因,然后针对洪水的提前预防,提出你们合理的建议和措施。
步骤 1: 相关性分析
1. 计算相关系数:
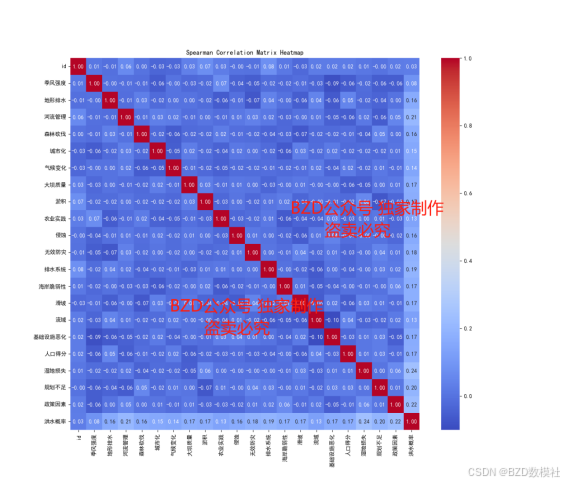
- 使用皮尔逊相关系数计算各指标与洪水发生概率之间的相关性。
- 可以选择使用Spearman或Kendall相关系数进行补充分析。
2. 可视化相关性:
- 使用Seaborn绘制相关性矩阵热力图,直观展示各指标之间的相关性。
- 分析哪些指标与洪水发生概率的相关性较强,哪些指标相关性较弱。
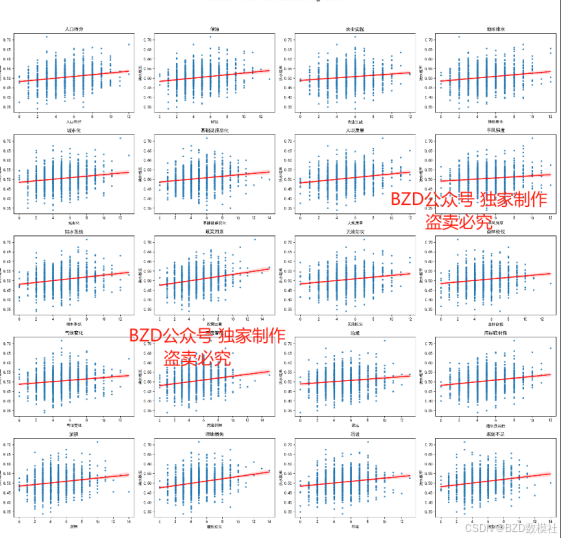
步骤 2: 数据可视化
1. 散点图与回归分析:
- 绘制每个指标与洪水发生概率的散点图,观察数据分布和趋势。
- 使用线性回归或其他回归方法拟合数据,分析指标与洪水发生概率的关系。
2. 箱线图与分布图:
- 使用箱线图展示不同指标在不同洪水发生概率区间内的分布情况。
- 使用直方图和密度图分析各指标的分布特征。
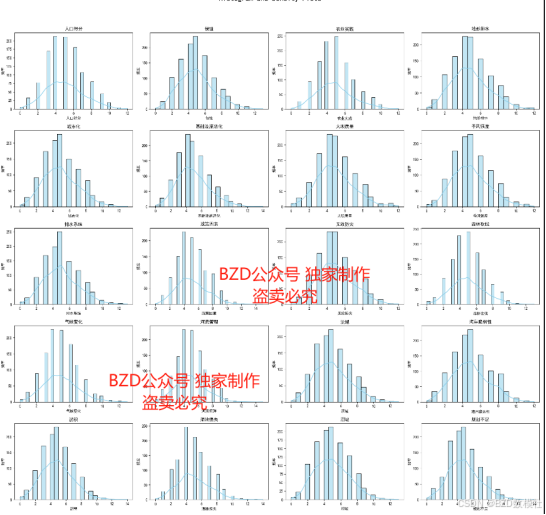
步骤 3: 文字描述
1. 指标分析:
- 根据相关性分析和可视化结果,讨论各指标对洪水发生的潜在影响机制。
- 分析可能的人为因素和自然因素对洪水发生的影响。
2. 提出建议:
- 针对高相关性指标,提出相应的洪水提前预防措施,如加强河流管理、改善排水系统、控制森林砍伐等。
问题 2. 将附件 train.csv 中洪水发生的概率聚类成不同类别,分析具有高、中、低风险的洪水事件的指标特征。然后,选取合适的指标,计算不同指标的权重,建立发生洪水不同风险的预警评价模型,最后进行模型的灵敏度分析。
步骤1: 聚类分析
1. K-means聚类:
- 使用K-means算法将洪水发生概率分为高、中、低三个风险类别。
- 对数据进行聚类前的标准化处理,以提高聚类效果。
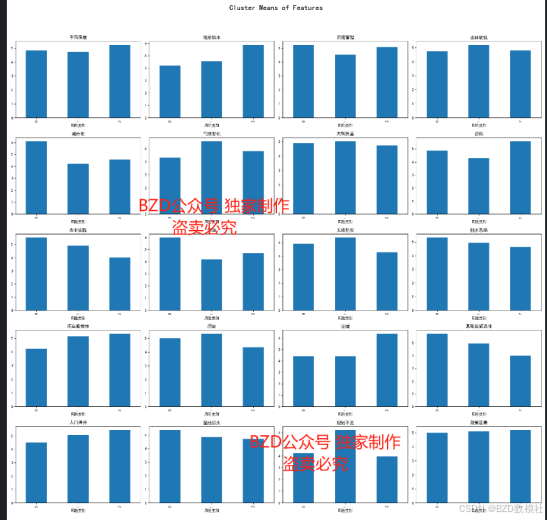
2. 聚类结果分析:
- 分析不同类别的指标特征,找出各类别之间的显著差异。
- 使用可视化方法展示聚类结果,如雷达图、箱线图等。
步骤 2: 权重计算与模型建立
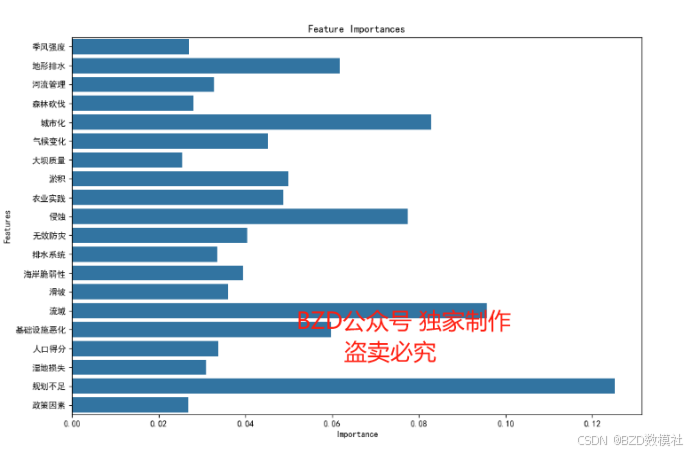
1. 特征选择与权重计算:
- 使用信息增益、Gini系数等特征选择方法,计算不同指标的权重。
- 选取重要指标,建立加权和的洪水风险评估模型。
2. 模型灵敏度分析:
- 通过改变模型参数或去除某些指标,分析模型预测结果的变化。
- 评估模型的鲁棒性和敏感性,确保模型在不同条件下的稳定性。
特征重要性柱状图
问题 3. 基于问题 1 中指标分析的结果,请建立洪水发生概率的预测模型,从 20 个指标中选取合适指标,预测洪水发生的概率,并验证你们预测模型的准确性。如果仅用 5 个关键指标,如何调整改进你们的洪水发生概率的预测模型?
步骤1: 特征选择与模型建立
1. 特征选择:
- 根据问题1的分析结果,选取与洪水发生概率关系密切的指标。
- 尝试多种机器学习模型,如线性回归、决策树、随机森林、XGBoost等,建立洪水发生概率的预测模型。
2. 模型训练与优化:
- 使用交叉验证和网格搜索优化模型参数,选择最优模型。
- 评估模型的预测精度,确保模型的泛化能力。
步骤2: 模型验证与改进
1. 模型验证:
- 使用 `train.csv` 中的部分数据进行训练,其余数据进行验证,评估模型的预测精度。
- 分析预测误差,优化模型结构和参数。
2. 关键指标模型:
- 如果仅使用5个关键指标,调整模型结构,重新训练和验证模型。
- 比较不同模型的预测效果,选择最佳方案。
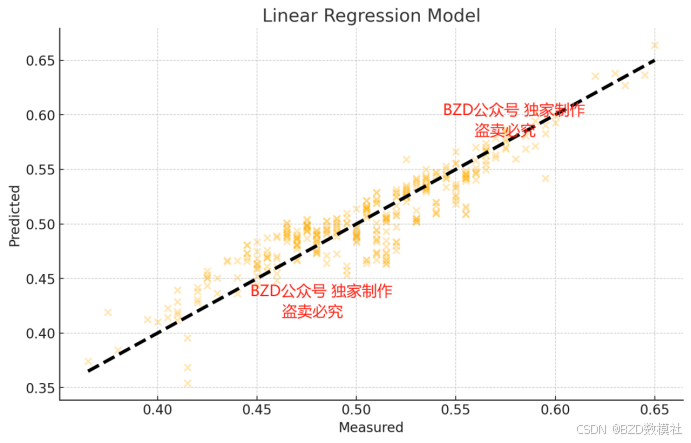
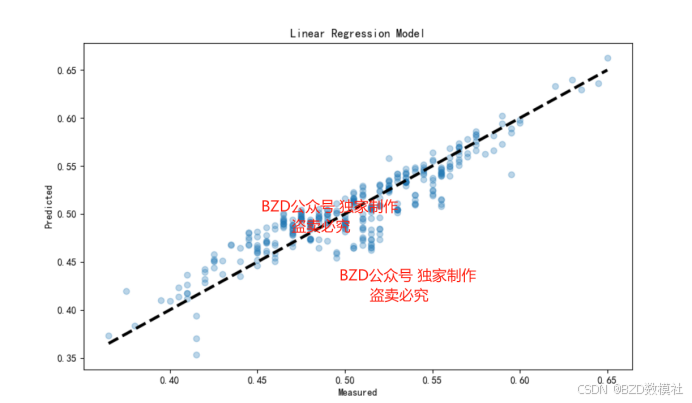
问题 4. 基于问题 2 中建立的洪水发生概率的预测模型,预测附件 test.csv 中
所有事件发生洪水的概率,并将预测结果填入附件 submit.csv 中。然后绘制这 74
多万件发生洪水的概率的直方图和折线图,分析此结果的分布是否服从正态分布。
步骤1: 预测与提交结果
1. 模型预测:
- 使用问题3中选定的最佳模型,预测 `test.csv` 中每个事件的洪水发生概率。
- 将预测结果填入 `submit.csv` 文件中。
步骤2: 分布分析
1. 直方图与折线图:
- 绘制74万件洪水事件的概率直方图和折线图,分析洪水发生概率的分布情况。
- 使用正态性检验方法(如Shapiro-Wilk检验),判断预测结果是否符合正态分布。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 2024 年第十四届 APMCM 亚太地区大学生数学建模竞赛B题超详细解题思路+数据预处理问题一代码分享

发表评论 取消回复