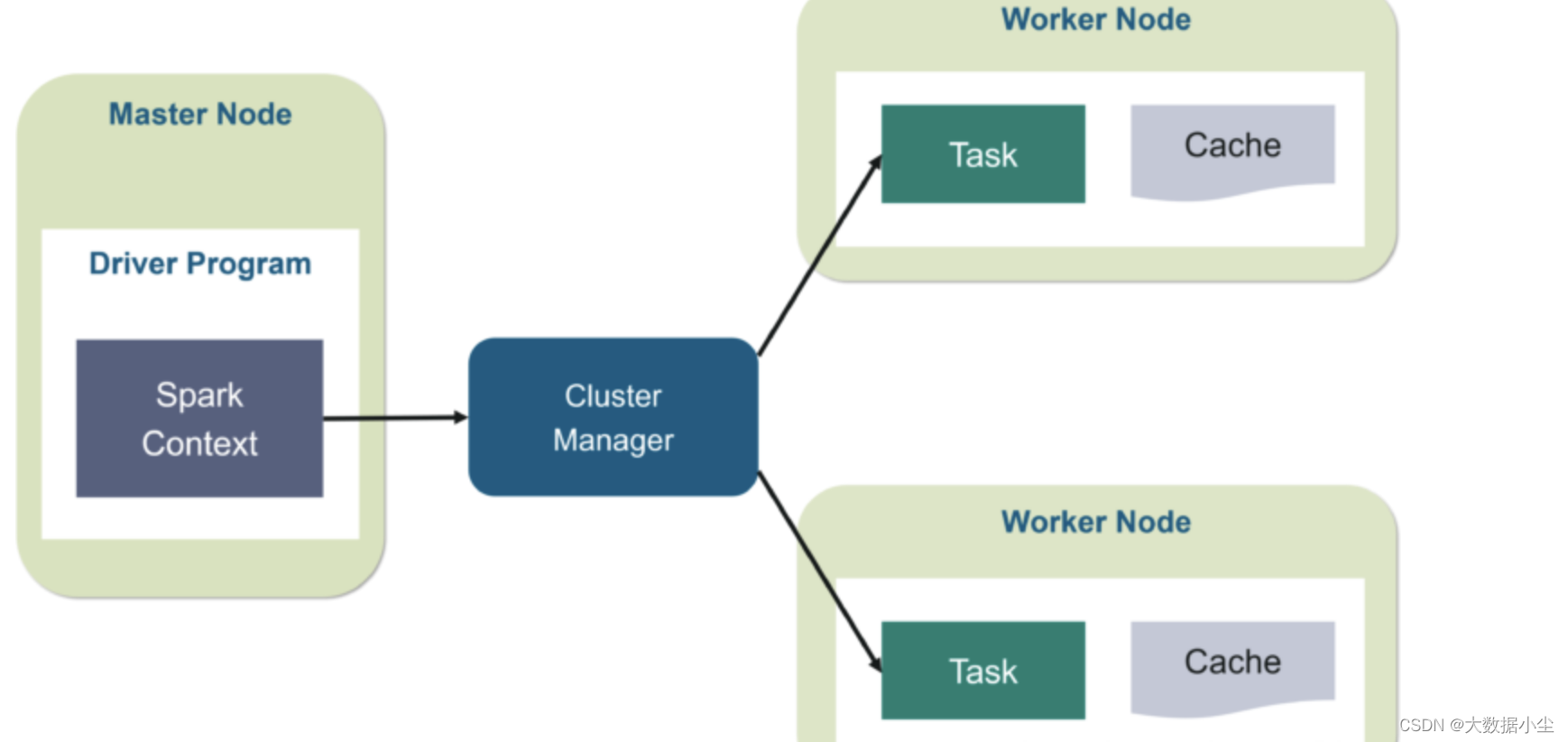
1: Spark 整体架构
Spark 是新一代的大数据处理引擎,支持批处理和流处理,也还支持各种机器学习和图计算,它就是一个Master-worker 架构,所以整个的架构就如下所示:
2: Spark 任务提交命令
一般我们使用shell 命令提交,命令如下:
./bin/spark-submit \
--master yarn \
--deploy-mode cluster \
--driver-cores 2 \
--driver-memory 1g \
--executor-cores 4 \
--num-executors 10 \
--executor-memory 8g \
--class PackageName.ClassName XXXX.jar \
--name "Spark Job Name" \
driver 和executor 就是对应的spark的 driver 和executor 的配置,然后再指定个部署模式master 就可以了。
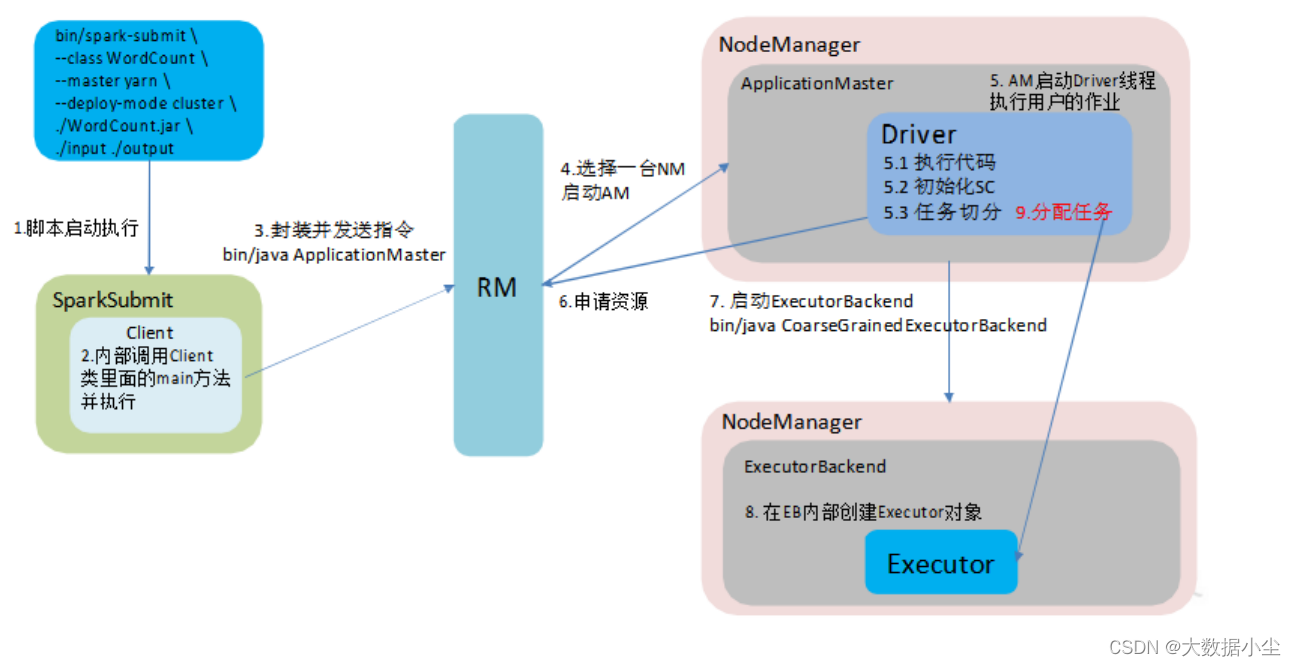
3: spark提交任务的流程
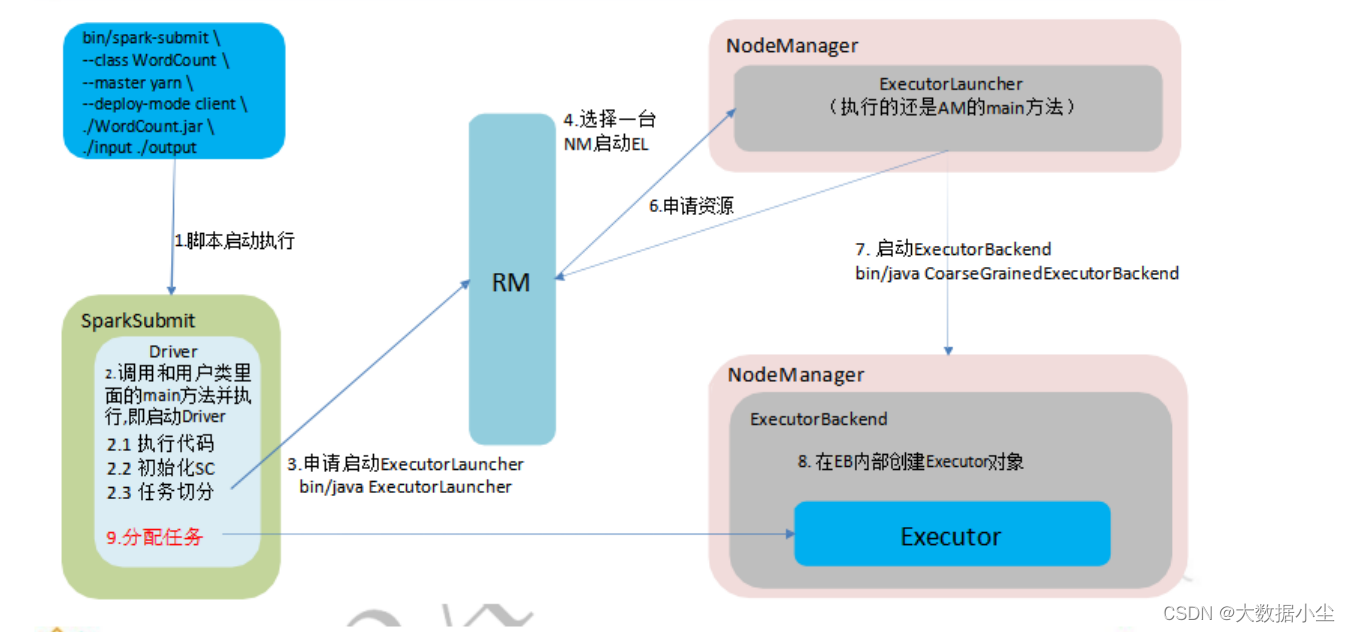
如上所示,我们在提交spark 任务的时候,有个参数可供选择模式,就是deploy-mode 的参数,它的值有client 和cluster 之分;client 说白了就是driver 在客户端,任务的分配和调度都在客户端,这种只适合用于测试;毕竟一旦流量大了的话客户端是顶不住的啊;而cluster 模式是spark对应的driver 和executor 都是在yarn集群上,相对来说稳定,我们这里只着重说yarn-cluster 的提交流程
3.1: 首先如上面的第二点所示,我们先提交启动命令
3.2: 然后客户端这边先运行提交的jar包里面的main方法
3.3: 接着和RM 通信,告诉RM 启动ApplicationMaster,./bin/ApplicatioMaster
3.4: RM 随机选择一台NM 准备启动AM
3.5: 在AM 里面启动driver,然后让driver 进行SparkContext 的初始化以及进行任务的切分
3.6:AM 再向RM 申请资源
3.7: 申请资源后AM 就启动ExecutionBackend,
3.8: ExecutionBackend 启动 Executors
3.9:Driver 把任务分配给Executors
cluster 流程图如下所示:
client 流程图如下所示:
4: Spark 中的RDD
4.1: RDD 概念
还是老样子,先理解一个东西之前我们看看它的学名是什么,Resilient Distribute DataSet ,就是弹性分布式数据集;说白了,它的本质还是数据的集合,MR 和Flink的输入是一条条数据,这Spark 说我乖点了,输入我就先把它们整成一个个数据集;哈哈哈,符合预先聚合的思想。说白了,RDD 就是三个层次的抽象,Dataset, partition, 以及record;对应到生活中的例子,就是班级,组以及单个同学;
4.2:RDD 的特点是啥?从学名可以窥见一二,弹性,分布式
我们先说弹性,说白了就是灵活,可以容错,它是怎么容错的呢?就是RDD之间互相有依赖关系,如果某个RDD的分区没有了,可以从原始数据和依赖关系得来,不用让其他分区重算;
那么分布式呢,就是一个RDD的分区数据可以分发到不同的节点上进行计算;靠近数据的计算嘛;
一个RDD的分区数可以自定义;如果没有自定义,则和hdfs的block数一样,或者和cpu的核数成比例关系,一核心大概可以处理2-4个分区。
4.3: RDD 之间的血缘关系
血缘血缘,套到数据集这边就知道是上下游RDD的关系了,这里的血缘指的就是子RDD和父RDD 之间是分区之间一对一还是多对一;说白了如果一个父RDD的一个分区的数据给到了子RDD的多个分区,这明摆着宽广嘛,就是宽依赖;否则就是摘依赖,一对一的关系;如下所示
4.4: RDD 之间的stage 划分
这里就有个问题了,为什么要进行stage的划分呢? 大家可以想想,这个spark的RDD 也是基于内存的计算,如果一个任务一直这样计算下去,比如算到90%的时候,机器突然宕机了,任务全部失败了,是不是又得重新计算,所以我们就要进行个中间数据的备份嘛,比如算完了一个stage的数据,先把它存储到外部系统,这样就不怕任务突然中断了;
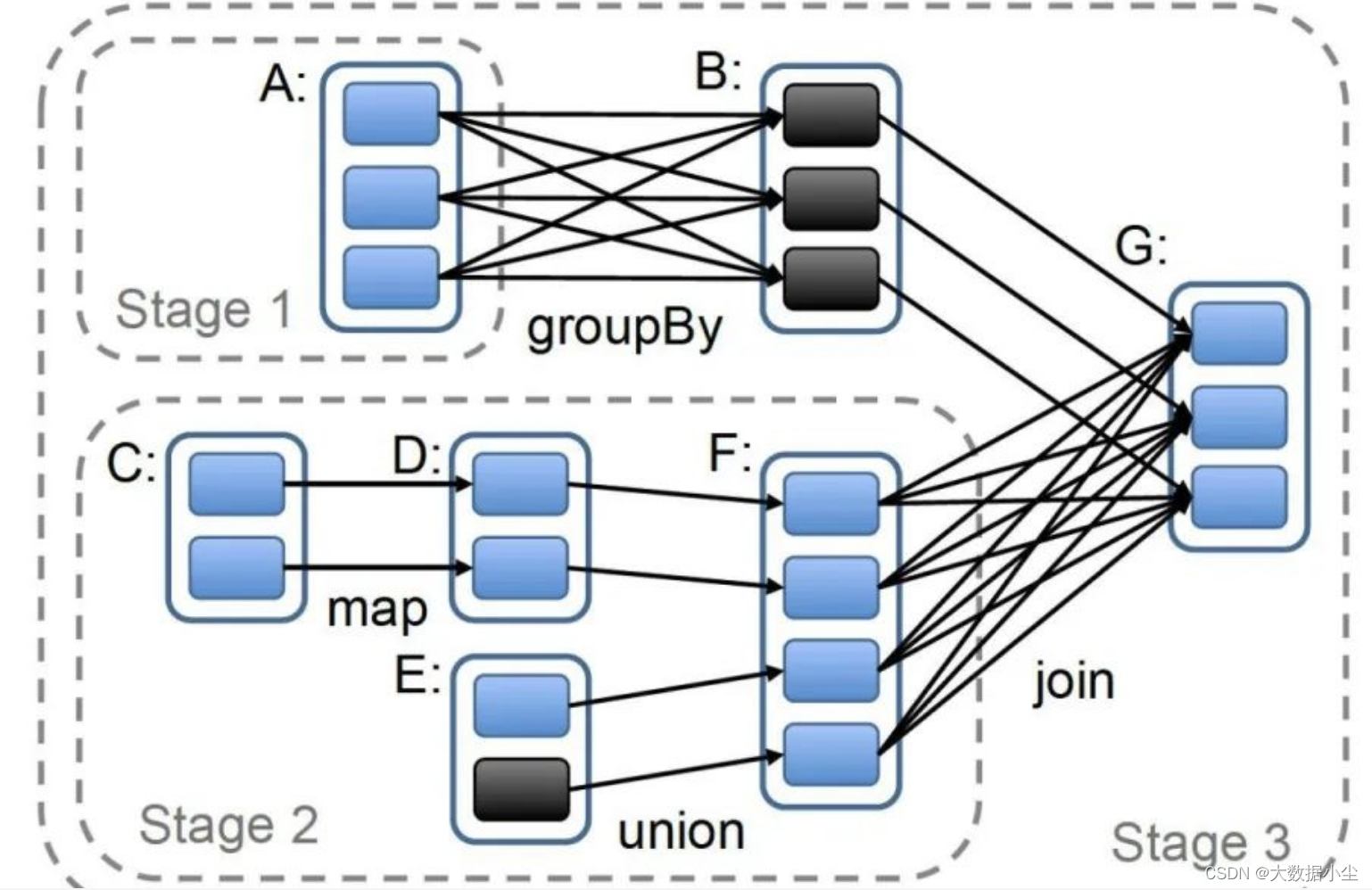
所以大家是不是结合上面的宽窄依赖就想到了,如果出现了宽依赖我们就截断,划分一个stage;毕竟可以先保存一份数据嘛,可能一个子RDD有多个父RDD,每个父RDD就自己先把数据保存起来,做个备份嘛;
所以我们stage 划分就是根据宽窄依赖去划分的,碰到宽依赖就划分一个stage,stage 里面的算子和数据自成一个天地。
4.5: spark的编程思想之RDD
所以兄弟们可以看到,说白了,我们进行spark的编程的时候,就是基于RDD的,然后和算子一起,把RDD当作点,这些算子当成边,不就构建成了我们的这个有向无环图(DAG) 嘛;没有相互依赖的RDD 进行一个并行计算,有相互依赖的窄依赖的类型也可以进行并行计算,当碰到宽依赖的时候,就要进行数据打散了,不就是shuffle嘛,最后算好的数据落盘就行了。
5: Spark中groupByKey,reduceByKey,, combineByKey, aggregrateByKey的区别
怎么说呢,其实这些算子都是针对数据做聚合的操作,groupByKey 和reduceByKey 没有定义初始值的结构,groupByKey 默认用的hash 分区,而reduceByKey 可以自定义分区,也会提前进行combine;这两个算子分区内的逻辑和分区间的逻辑都是一致的;
而aggregrateByKey 和 combineByKey 和 则在reduceByKey的基础上做了些变化,aggregrateByKey 是自定义分区内和分区间的逻辑;而combineByKey 是在上述的基础上也增加一个初始值自定义。
6: spark中的hashShuffle,sortShuffle, 以及优化后的这两个变种
6.1: 普通的hashShuffle ,说白了就是在shuffle的过程中使用hash对key 进行分组,假如上游有100个类似的mapTask,下游有100个reduce task,每个mapTask 会针对下游生成100个文件,总共就是10000个小文件了,这个对于集群来说负担就太大了,如下所示:
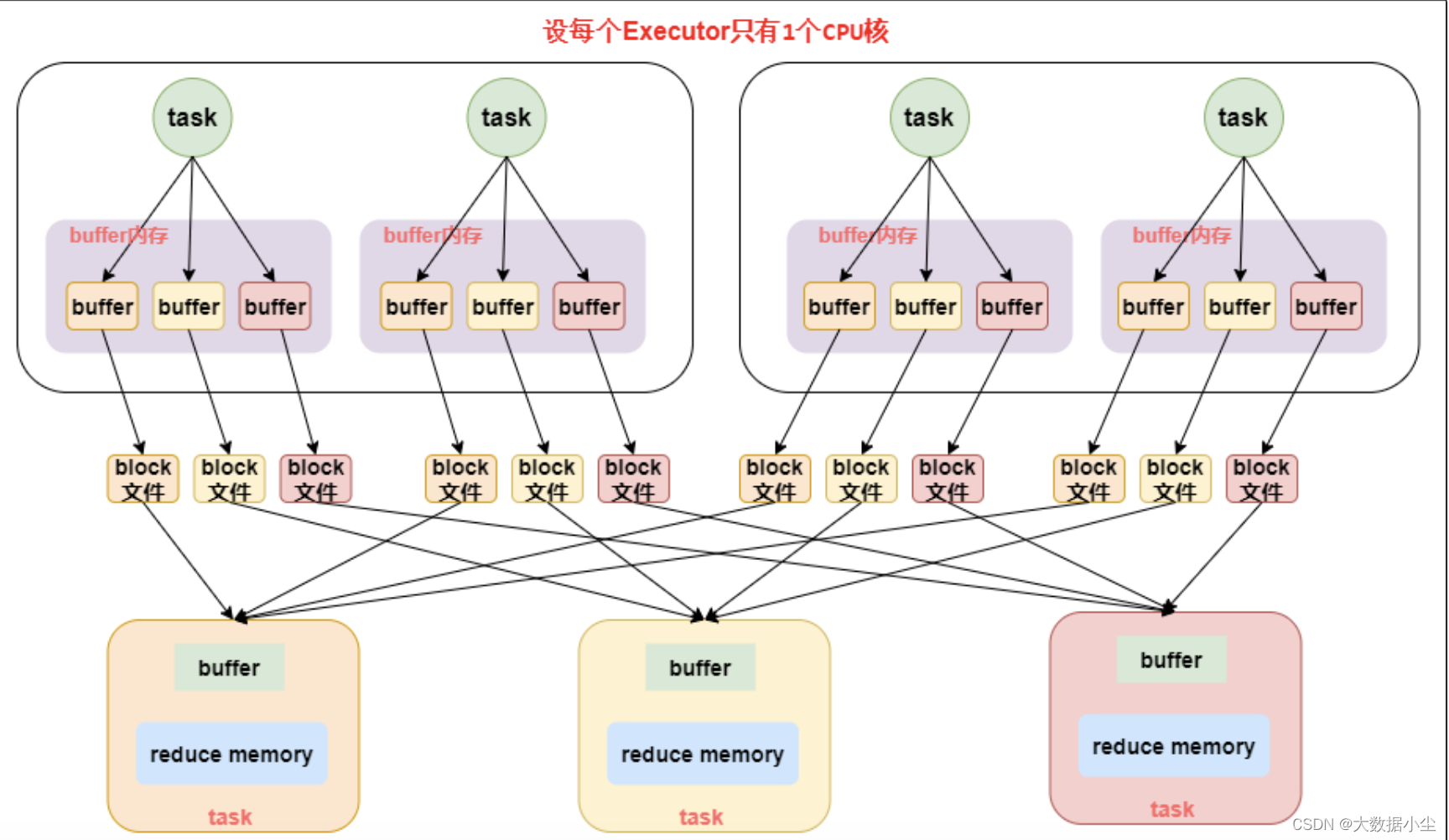
6.2: 优化后的HashShuffle
上述的普通版产生的小文件个数太多了,所以我们需要优化下,优化的重点思路就是复用,既然每个上游的task都要生成这么多文件,可不可以一个Executor 里面的缓冲区复用呢?答案是可以的,spark 官方就根据cpu core 的数量 * 下一个stage的task个数来确定缓冲区数量以及文件个数,相对来说少了挺多的,原先要10000个,现在可能只要5*100个就可以了。哈哈哈,不过这个优化机制要通过spark.shuffle.consolidateFiles=true 开启;
6.3: sortShuffle
sortShuffle 是什么呢?说白了就是在shuffle 之前先进行排序,然后也会有溢写到磁盘,可能会生成多个文件,但是最终每个task会对所有的文件进行合并,最终只生成一个文件和文件对应的索引,让下游的task 根据索引文件去找数据,拉取数据。如下所示:
这个对应的文件更少了,对下游的压力也更小了。
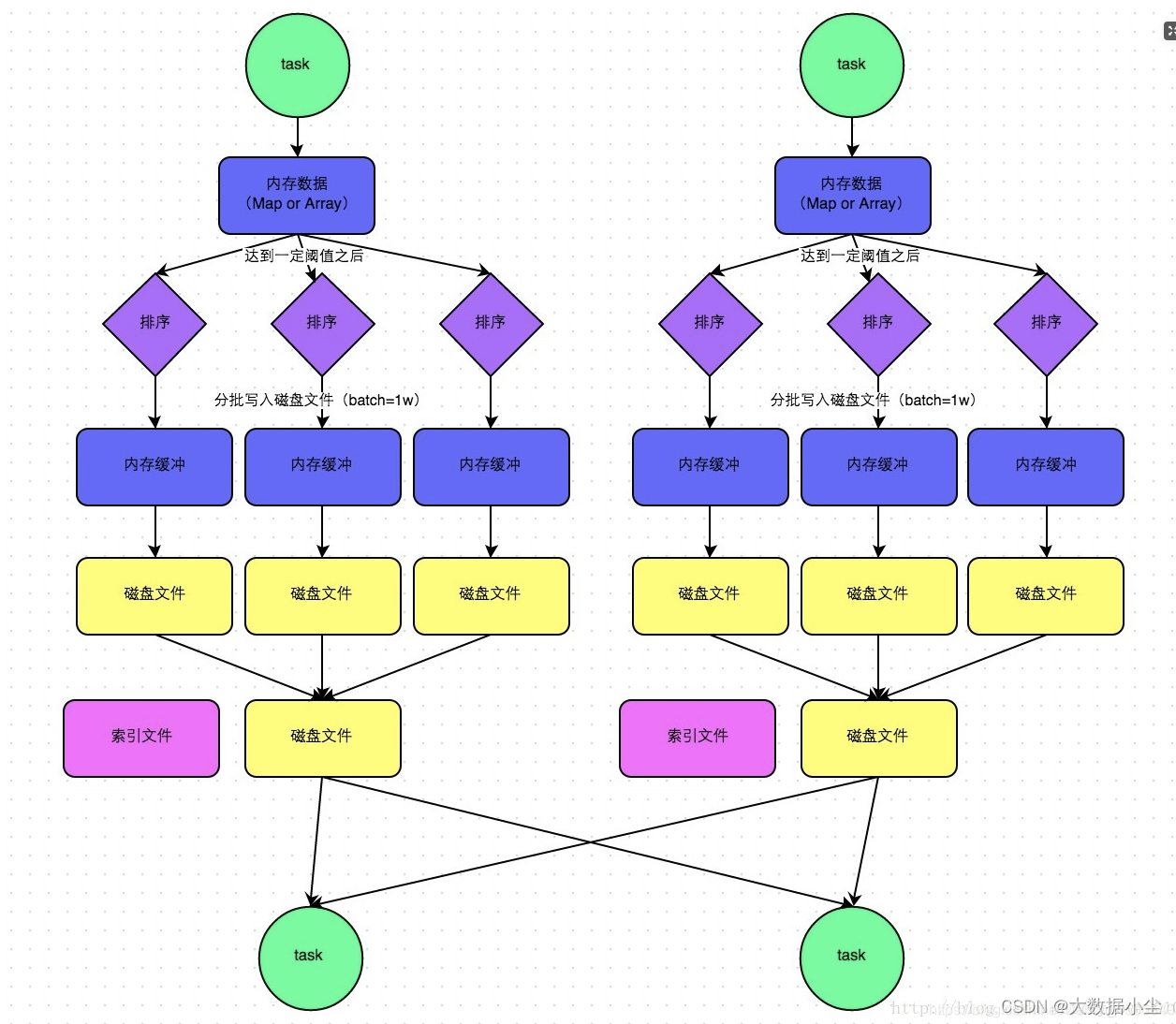
6.4: byPassSortShuffle
这个和上面的sortShuffle 如出一辙,唯一的区别就是在写文件的时候不会进行排序,省去了这部分的开销;不过这个需要触发的点有两个,
6.4.1: shuffle map task 数量小于spark.shuffle.sort.bypassMergeThreshold=200参数的值。
6.4.2: 不是聚合类的 shuffle 算子
兄弟们最终是不是还想问问,现阶段该怎么启用sortShuffle,spark2.x 已经把所有的shuffle都默认成了sortShuffle了。
7: spark中的cache,persist 和checkpoint 的区别
三者都是把数据持久化的,前面两个是把数据缓存到内存,而checkpoint 是吧数据存到hdfs 或者本地文件;前者不会截断血缘关系,后者会截断,毕竟hdfs副本可以容错;cache 实际上就是调用的persist
8: RDD , DataFrame, 以及DataSet 的区别
8.1: RDD 就是我们刚刚说的弹性分布式数据集嘛,是面向对象的,是需要序列化和反序列化的,在网络IO中性能消耗大,是不支持Spark Sql的;但是它是编译类型安全的;
8.2: DataFrame 怎么说呢?就是相当于一个表,类似于python 和R,它只知道表头,只知道下面的Name,age,Height;不知道具体每个字段对应的数据类型,它就相当于表里的v如下所示:
所以它是编译时类型不安全的;不过它有个优点,它的存储是放在java的堆外内存,不用进行GC了,也不用进行序列化和反序列化带来的开销了
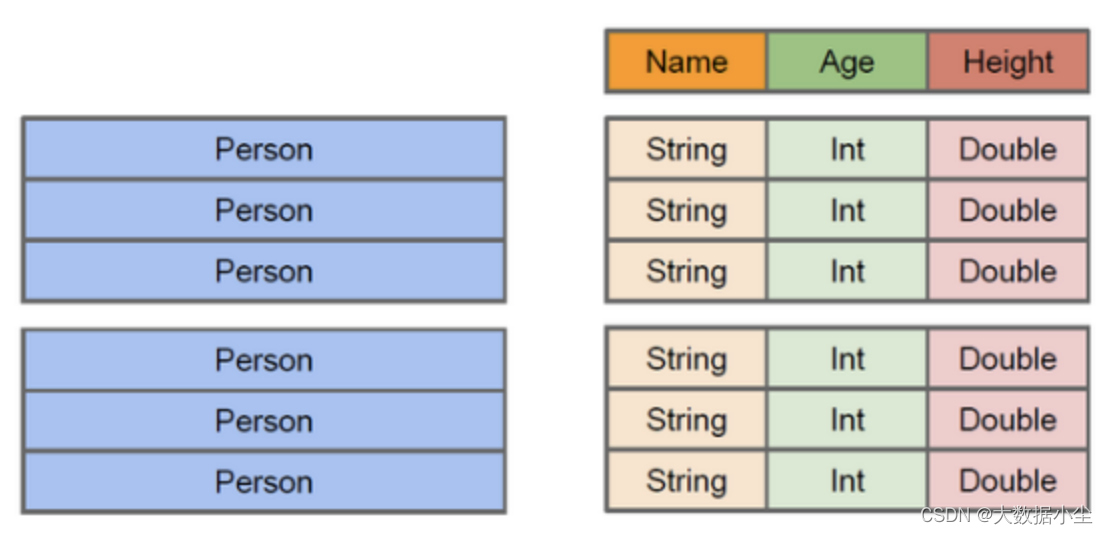
8.3: 这就是天生为sql 创建的数据集了,它就相当于sql里面的表,既知道表的字段头,也知道每个表的字段的数据类型;而且它还支持序列化的时候轻量的序列化,它结合了DF 和 RDD的优点,编译时也是类型安全的,并且带来了一个全新的概念,Encode,它可以保证按需序列化数据了。
9: SparkShuffle 的优化:
上一步我们讲了spark上游MapTask生成小文件的优化,那么接下来我们也可以看看sparkReduce的这个Reduce 端的优化。
9.1: 既然要优化reducer端,首先能不能让每次buffer存储的数据量多点,就节省了reduce 拉取的个数,这个值通过spark.shuffle.file.buffer 来控制,一般32k,可以是64k;
9.2: 既然要拉取的数据量少点,是不是可以提高每批次拉取的数据量呢?那就是spark.reducer.maxSizeInFlight 的值控制的,一般是48M,可以到96M;
10. sparkStreaming 和kafka的连接方式
说白了,这个问题就是问的sparkStreaming 如何从kafka 拉取数据的,
10.1:Receiver 方式,这个是Spark 1.5 之前的版本,说白了就是Executor 里面有个receiver的组件,它负责和kafka创建连接,并且使用kafka的高阶api 去和kafka 通信,从kafka 消费过来的数据基本上是先放在内存中,然后供spark的executor 去做其他处理,所以数据量激增的时候有可能导致内存炸掉; 毕竟数据放在内存中很有可能丢失,是吧?所以它做了一个checkPoint,会对每个批次的数据做个备份,学名叫做WAL(Write ahead log) 机制,就是会把数据备份到分布式文件系统比如hdfs上面;
10.2:Direct 方式,直接每次轮询kafka的partition的数据,有几个partition 这边也就轮询几次,使用kafka的低阶的api,自己保存每个partition的offset,自己维护,保证了可以和kafka的同步;可以做到数据精确消费一次;
生产环境一般都用DIrect 方式,毕竟不用checkpoint,不用降低数据处理速率,而且可以精准消费一次;不存在重复消费的可能。
说白了,就是Receiver 是被动的,可能会被kafka的数据给干爆;Direct 是主动的,自己掌握offset ,去主动消费
11:sparkStreaming 窗口函数的原理
因为sparkStreaming 本质上是微批数据当作实时数据(如下所示)
val ssc = new StreamingContext(sc,Seconds(5))//5表示5秒中对数据进行切分形成一个RDD
``
所以窗口数据也是微批的合集,窗口一定要是微批的整数倍,这样才能算是可以统计出来的有效窗口
12: spark 常见算子解释
12.1: mapToPair, 说白了就是把原来的数据转换成关系对的形式,不管之前的数据怎么样,转换之后的数据就是pair对的形式,比如 tuple<String,Long>
12.2: transform, tranformToPair, 都是基于sparkStreaming 的流式数据结构上的算子,transform可能就是返回一个流式的数据Dstream, 里面的数据单位是Object; 而tranformToPair 返回的是带有pair 对的流是数据。
12.3: spark 编程,最关键的是你要知道你的输入是什么,你要输出什么,是tuple呢,还是String呢,还是其他数据呢,RDD里面装载的基础数据结构要知道;
12.3:
自定义排序类就是要实现Ordered 以及 Serialziable 接口,定义好大于,小于,compreTo的逻辑;
自定义的accumulator 说白了就是一个累加器,继承实现AccumulatorParam的方法,最关键的是要知道这个累加器的逻辑是什么,对哪个值累加,在addAccumulator 中实现这个累加的逻辑;
自定义的聚合函数,也就是udaf的function , 是要继承UserDefinedAggregateFunction的类,最重要的是要做三件事,初始化传进来的值,在update方法里面对每个分区的值做业务判断处理;
在merge 方法里面对所有分区的值做个融合判断处理,最终在buffer中更新
13:spark电商项目的核心
13.1: 首先从业务方面可以分为session访问指标计算,页面转换率计算;广告相关的指标计算,订单指标的相关统计计算;产品相关的指标计算;核心点是和产品经理核对好各个指标的计算方法;
13.2: 大数据大数据,最重要的关注点就是我们要关注性能,因为好的性能和差的性能跑任务的时间可以相差到几个甚至十几个小时,所以我们在编写代码的时候就要尽可能考虑到这些点;从系统可用资源方面,代码层面,数据倾斜和组成方面进行考虑,尽量达到最大的性能;尽量考虑稳定性。
13.3: spark调优
13.3.1: 算子调优
13.3.2: shuffle 调优
13.3.3: 资源调优
13.3.4: jvm 调优,降低cache 内存的比例
14: Spark 内存管理机制
14.1: 静态内存变为动态内存,统一内存管理了,分成了Storage Memory 和Execution Memory ,分别是1:1 的关系,存储数据,存储shuffle过程中的数据
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 大数据Spark 面经

发表评论 取消回复