1.方程
求e^x-派(3.14)的解
用二分法来求解,先简单算出解所在的区间,然后用迭代法求逼近解,一般不能得到精准的解,所以设置一个能满足自己进度的标准来判断解是否满足
这里打印出解x0是因为在递归过程中没有变量去接收返回值,所以返回x0,再打印x0得到的是None,再用numpy自带的log(pi)就查看解的相似度
import numpy as np
def f(x):
return np.e**x-np.pi
resolution=0.00000001
global x
x=0
def search_x(x1,x2):
x0=(x1+x2)/2
if np.abs(f(x0)-0)<=resolution:
print(x0)
elif f(x1)*f(x0)<0:
search_x(x0,x1)
elif f(x2)*f(x0)<0:
search_x(x0,x2)
search_x(0,10)
print("方程的解",np.log(np.pi))
2.拟合曲线
有俩组数据,通过这俩组数据可以得到一个图像
import matplotlib.pyplot as plt
import numpy as np
from numpy import polyfit
from matplotlib.pylab import mpl
mpl.rcParams['font.sans-serif']=['SimHei']#仅有这俩行 可以显示中文 但是减号为定义
mpl.rcParams['axes.unicode_minus']=False
time=[0.25, 0.5, 0.75, 1 ,1.5 , 2 ,2.5 ,3 ,3.5 ,4 ,4.5 ,5,6,7,8,9,10,11,12,13,14,15,16]
alcohol=[30,68,75,82,82,77,68,68,58,51,50,41,38,35,28,25,18,15,12,10,7,7,4]
# print(len(time),len(alcohol))
plt.scatter(time,alcohol)
plt.title("project")
plt.xlabel("x")
plt.ylabel("y")
plt.show()
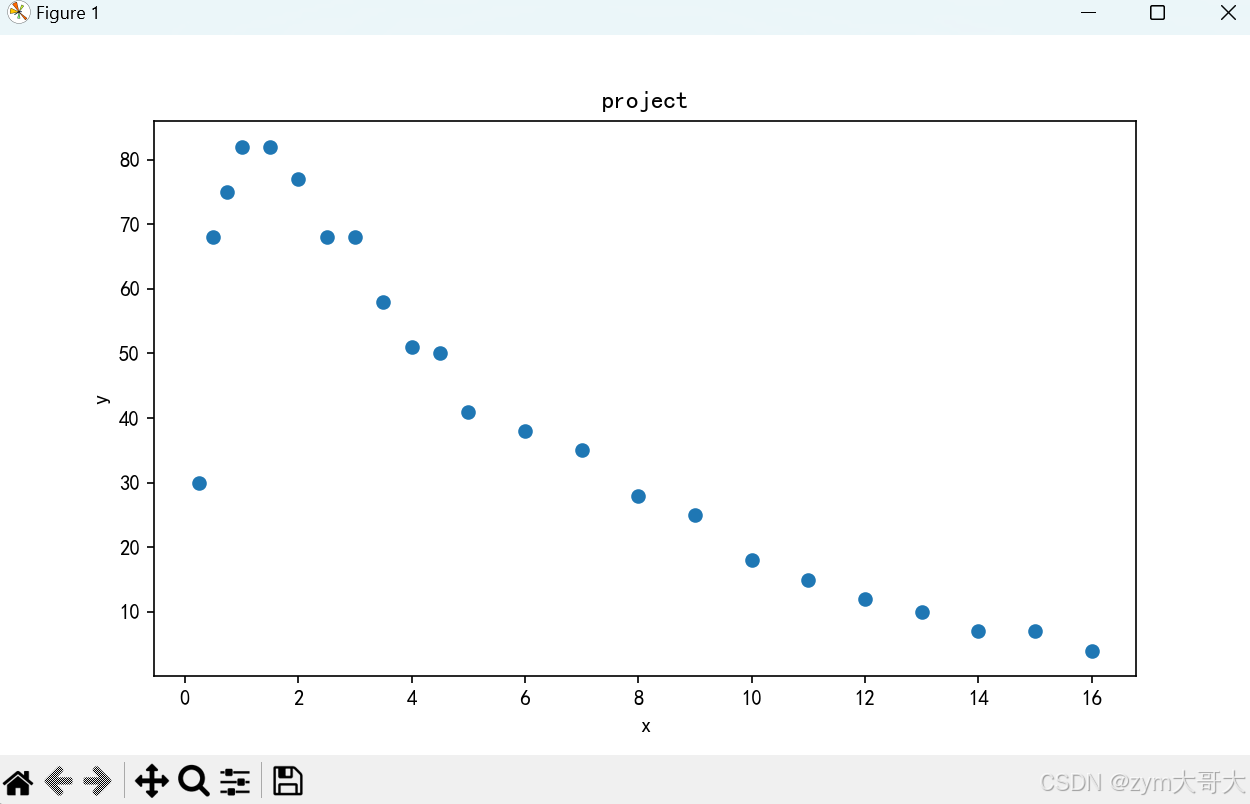
接下来就是对数据进行操作,是线性关系明显
time=[0.25, 0.5, 0.75, 1 ,1.5 , 2 ,2.5 ,3 ,3.5 ,4 ,4.5 ,5,6,7,8,9,10,11,12,13,14,15,16]
alcohol=[30,68,75,82,82,77,68,68,58,51,50,41,38,35,28,25,18,15,12,10,7,7,4]
y=[np.log(a) for a in alcohol]#把alcohol里面的数据取对数 根据原数据对象做出操作
# print(len(time),len(alcohol))
plt.scatter(time,y)
plt.title("project")
plt.xlabel("x")
plt.ylabel("y")
plt.show()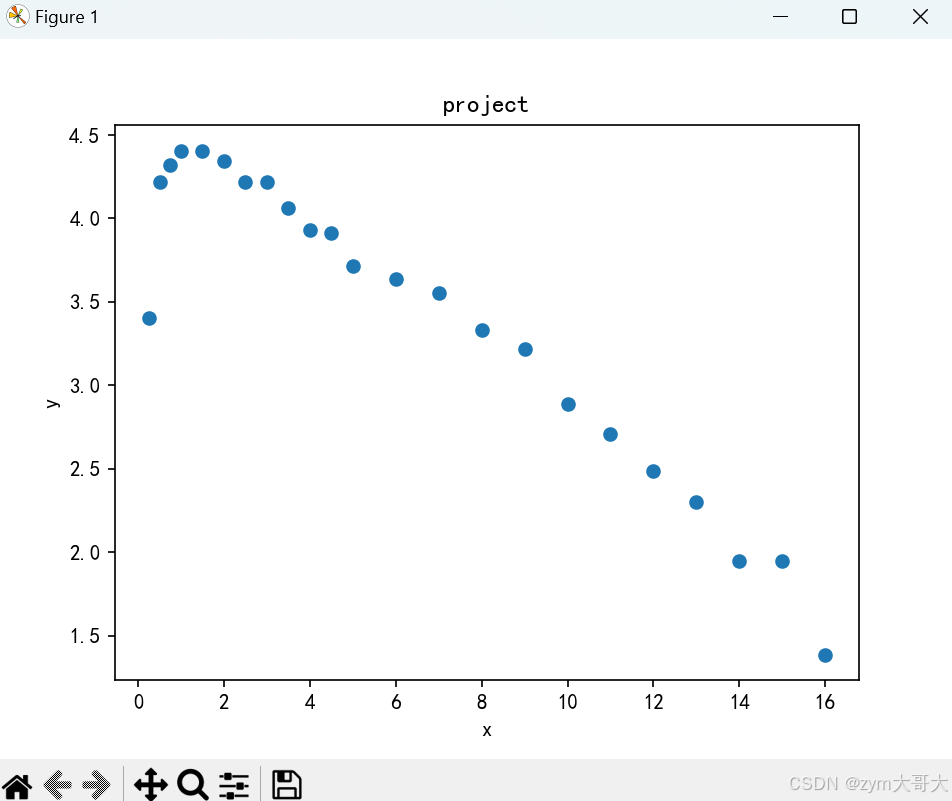
这个代码执行的是把alcohol的每个数据取出来在取对数,最后赋给y
y=[np.log(a) for a in alcohol]图像可以知道存在峰值,而峰值后的数据关系联系强,而峰值前的数据也同样,所以可以分段函数的办法来表现图像关系
.index 可以得到里面数据的索引
.max 可以得到数据中最大值
[alcohol.index(max(alcohol)):] 表示从最大值开始到最后一个数据
alcohol_tup=alcohol[alcohol.index(max(alcohol)):]polyfit(x,y,z) x与y是俩个数据集 z表示是几次的函数 这里是y=kx+b 为一次,所以z=1
这里会返回俩个值,一个是k,一个是b
from numpy import polyfit
k,b=polyfit(time_tup,y_tup,1)#1表示次数为1次 2为2次
把数据都进行分段
time=[0.25, 0.5, 0.75, 1 ,1.5 , 2 ,2.5 ,3 ,3.5 ,4 ,4.5 ,5,6,7,8,9,10,11,12,13,14,15,16]
alcohol=[30,68,75,82,82,77,68,68,58,51,50,41,38,35,28,25,18,15,12,10,7,7,4]
y=[np.log(a) for a in alcohol]#把alcohol里面的数据取对数 根据原数据对象做出操作
alcohol_tup=alcohol[alcohol.index(max(alcohol)):]#找到alcohol的最大数并返回索引 把最大值以及从最大值后面的数据索引 重新改造数据
time_tup=time[alcohol.index(max(alcohol)):]
y_tup=y[alcohol.index(max(alcohol)):]
k,b=polyfit(time_tup,y_tup,1)#1表示次数为1次 2为2次
#1次 是y=kx+b
print(k,b)建立一个model函数来进行拟合
predy是在拟合函数中得到的y值
time=[0.25, 0.5, 0.75, 1 ,1.5 , 2 ,2.5 ,3 ,3.5 ,4 ,4.5 ,5,6,7,8,9,10,11,12,13,14,15,16]
alcohol=[30,68,75,82,82,77,68,68,58,51,50,41,38,35,28,25,18,15,12,10,7,7,4]
y=[np.log(a) for a in alcohol]#把alcohol里面的数据取对数 根据原数据对象做出操作
alcohol_tup=alcohol[alcohol.index(max(alcohol)):]#找到alcohol的最大数并返回索引 把最大值以及从最大值后面的数据索引 重新改造数据
time_tup=time[alcohol.index(max(alcohol)):]
y_tup=y[alcohol.index(max(alcohol)):]
k,b=polyfit(time_tup,y_tup,1)#1表示次数为1次 2为2次
#1次 是y=kx+b
print(k,b)
def model(t):
a=np.e**(k*t+b)
return a
time0=np.linspace(time_tup[0],16,1000)
predy=model(time0)
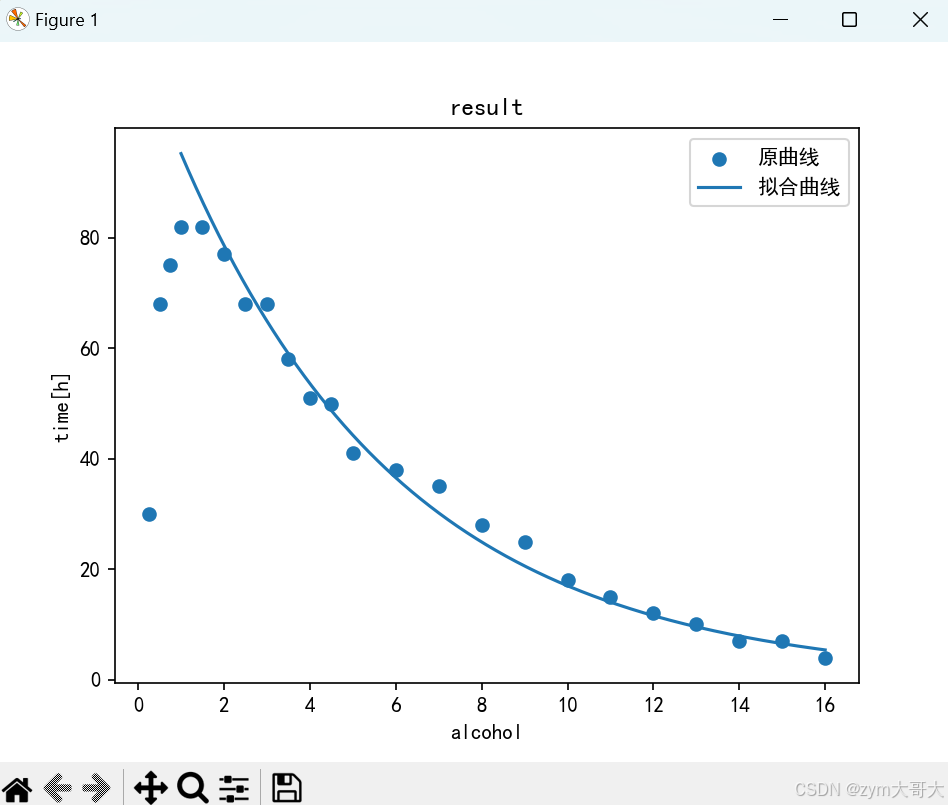
plt.scatter(time,alcohol,label="原曲线")
plt.plot(time0,predy,label="拟合曲线")
plt.title("result")
plt.xlabel("alcohol")
plt.ylabel("time[h]")
plt.legend()
plt.show()
可以看到峰值后的拟合曲线基本贴合原数据
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Python实战训练(方程与拟合曲线)

发表评论 取消回复