目录
2.2.日志式文件系统(Journaling filesystem)
1.文件的读取
我们知道在Linux系统下,每个文件(不管是一般文件还是目录文件)都会占用一个inode,且可依据文件内容的大小来分配多个区块给该文件使用。
目录的内容在记录文件名,一般文件才是实际记录数据内容的地方。
我们现在已经了解了Linux的文件系统,那么Linux是如何对文件进行读取的呢?
1.1.目录
当我们在Linux下的文件系统建立一个目录时,文件系统会分配一个inode与至少一块区块给该目录。
其中,inode记录该目录的相关权限与属性,并可记录分配到的那块区块号码,而区块则是记录在这个目录下的文件名与该文件名占用的inode号码数据,也就是说目录所使用的区块记录如下的信息:

如果想要实际观察root 根目录内的文件所占用的inode号码时,可以使用Is-i这个选项来处理:
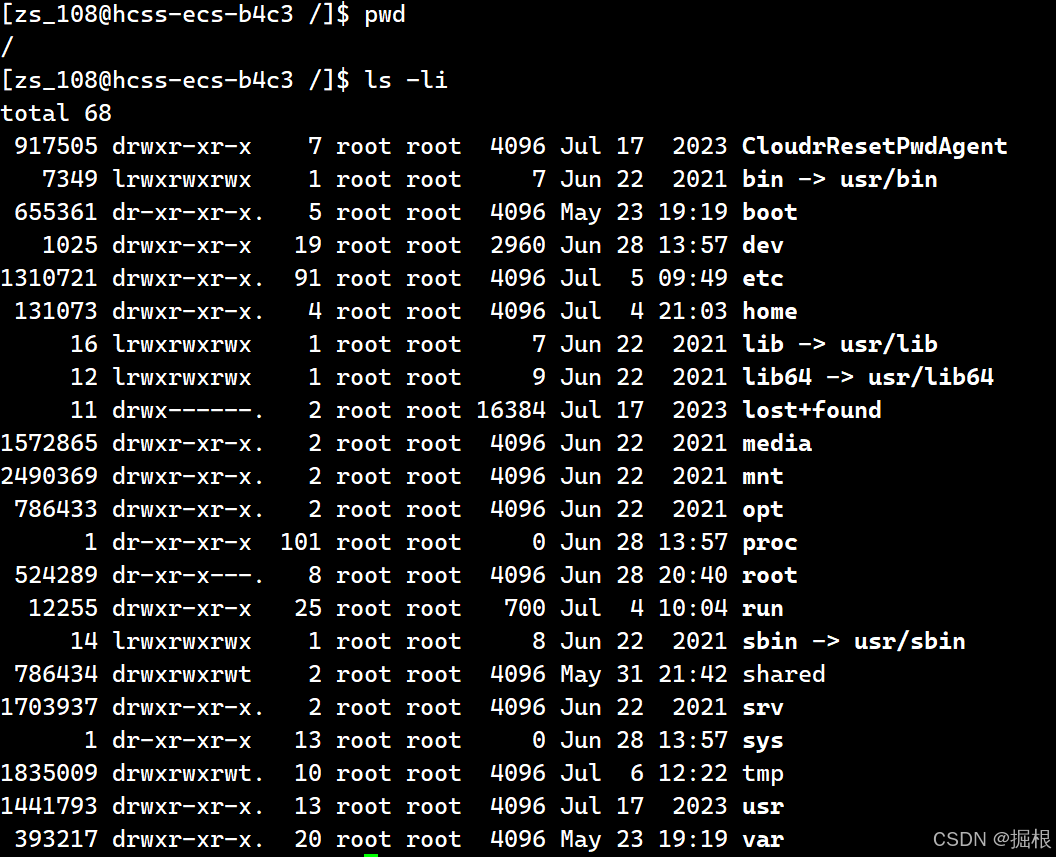
由于每个人所使用的计算机并不相同,系统安装时选择的项目与磁盘分区都不一样,因此你的环境不可能与我的inode号码一模一样,上表的左边所列出的inode仅是我的系统所显示的结果而已。
而由这个目录的区块结果我们现在就能够知道,当你使用【|| /】时,出现的目录几乎都是1024的倍数,为什么?因为每个区块的数量都是1K、2K、4K,看一下我的环境:

由于我的根目录使用的区块大小为4K,因此每个目录几乎都是4K的倍数,其中由于/usr/sbin的内容比较复杂因此占用了3个区块。
至于奇怪的/proc我们在讲过该目录不占磁盘容量所以当然使用的区块就是0。
由上面的结果我们知道目录并不只会占用一个区块而已,也就是说:在目录下面的文件数如果太多而导致一个区块无法记录得下所有的文件名与inode对照表时,Linux会多给该目录一个区块来继续记录相关的数据。
1.2.文件
当我们在Linux下的ext2建立一个一般文件时,ex2会分配一个inode与相对于该文件大小的区块数量给该文件。
例如:假设我的一个区块为4KB,而我要建立一个100KB的文件,那么Linux将分配一个inode与25个区块来存储该文件。但同时请注意,由于inode仅有12个直接指向,因此还要需要一个区块来记录区块号码。
1.3.目录树读取
好了,经过上面的说明你也应该要很清楚地知道inode本身并不记录文件名,文件名的记录是在目录的区块当中。
那么因为文件名是记录在目录的区块当中,因此当我们要读取某个文件时,就务必会经过目录的inode与区块,然后才能够找到那个待读取文件的inode号码,最终才会读取到该文件的区块中的数据。
由于目录树是由根目录开始读起,因此系统通过挂载的信息可以找到挂载点的inode号码,此时就能够得到根目录的inode内容,并依据该inode 读取根目录的区块内的文件名数据,再一层一层的往下读到正确的文件名。
举例来说,如果我想要读取/etc/passwd这个文件时,系统是如何读取的呢?
在我系统上面与/etc/passwd有关的目录与文件数据如上表所示,该文件的读取流程为(假
设读取者身份为dmtsai 这个一般身份用户):
- 1. /的inode:
通过挂载点的信息找到inode号码为2的根目录inode,且 inode 规范的权限让我们可以读取
该区块的内容(有r与x);
- 2./ 的区块:
经过上个步骤取得区块的号码,并找到该内容有etc/目录的inode 号码(1310721);
- 3. etc/ 的inode:
读取1310721号inode 得知zs_108具有r与x的权限,因此可以读取etc/的区块内容;
- 4. etc/的区块:
经过上个步骤取得区块号码,并找到该内容有passwd 文件的inode 号码(1311648);
- 5. passwd 的 inode:
读取1311648号inode 得知zs_108具有r的权限,因此可以读取passwd的区块内容;
- 6. passwd的区块:
最后将该区块内容的数据读出来;

1.4.文件系统大小与磁盘读取性能
另外,关于文件系统的使用效率,当你的一个文件系统规划得很大时,例如100GB这么大时,由于磁盘上面的数据总是来来去去的,所以,整个文件系统上面的文件通常无法连续写在一起(区块号码不会连续的意思),而是填入式地将数据写入没有被使用的区块当中。
如果文件写入的区块真的很分散,此时就会有所谓的文件数据离散的问题发生了。
如前所述,虽然我们的ext2在inode处已经将该文件所记录的区块号码都记上了,所以数据可以一次性读取,但是如果文件真的太过离散,确实还是会发生读取效率下降的问题,因为磁头还是得要在整个文件系统中来来去去地频繁读取。
果真如此,那么可以将整个文件系统内的数据全部复制出来,将该文件系统重新格式化,再将数据给它复制回去即可解决这个问题。
此外,如果文件系统真的太大,那么当一个文件分别记录在这个文件系统的最前面与最后面的区块号码中,此时会造成磁盘的机械手臂移动幅度过大,也会造成数据读取性能的下降。
而且磁头在查找整个文件系统时,也会花费比较多的时间去查找。
因此,磁盘分区的规划并不是越大越好,而是要针对您的主机用途来进行规划才行。
2.增添文件
上一小节谈到的仅是读取而已,那么如果是新建一个文件或目录时,我们的文件系统是如何处理的呢?
这个时候就得要区块对照表及inode 对照表的帮忙了。
假设我们想要新增一个文件,此时文件系统的操作是:
- 1.先确定用户对于欲新增文件的目录是否具有w与x的权限,若有的话才能新增;
- 2.根据inode 对照表找到没有使用的inode号码,并将新文件的权限/属性写入;
- 3.根据区块对照表找到没有使用中的区块号码,并将实际的数据写入区块中,且更新inode的区块指向数据;
- 4.将刚刚写入的inode与区块数据同步更新inode对照表与区块对照表,并更新超级区块的内容。
一般来说,
- 我们将inode 对照表与数据区块称为数据存放区域,
- 至于其他例如超级区块、区块对照表与inode 对照表等区段就被称为元数据(metadata)
因为超级区块、inode对照表及区块对照表的数据是经常变动的,每次新增、删除、编辑时都可能会影响到这三个部分的数据,因此才被称为元数据。
2.1.数据的不一致(Inconsistent)状态
在一般正常的情况下,上述的新增操作当然可以顺利的完成。
但是如果有个万一怎么办?
例如你的文件在写入文件系统时,因为某些原因导致系统中断(例如突然的停电、系统内核发生错误等的怪事发生时),所以写入的数据仅有inode对照表及数据区块而已,最后一个同步更新元数据的步骤并没有完成,此时就会发生元数据的内容与实际数据存放区产生不一致(Inconsistent)的情况。
既然有不一致当然就得要解决。
在早期的ext2文件系统中,如果发生这个问题,那么系统在重新启动的时候,就会借由超级区块当中记录的有效位(是否有挂载)与文件系统状态(正确卸载与否)等状态来判断是否强制进行数据一致性的检查,若有需要检查时则以e2fsck这个程序来进行。
不过,这样的检查真的是很费时,因为要针对元数据区域与实际数据存放区来进行比对,呵呵,得要查找整个文件系统,如果你的文件系统有100GB以上,而且里面的文件数量又多时,哇,系统真忙碌,而且在对提供网络服务的服务器主机上面,这样的检查真的会造成主机恢复时间的拉长,真是麻烦,这也就造成后来所谓日志式文件系统的兴起。
2.2.日志式文件系统(Journaling filesystem)
为了避免上述提到的文件系统不一致的情况发生,我们的前辈们想到一个方式,如果在我们的文件系统当中规划出一个区块,该区块专门记录写入或修改文件时的步骤,那不就可以简化一致性检查的步骤了?
也就是说:
- 1.预备:当系统要写入一个文件时,会先在日志记录区块中记录某个文件准备要写入的信息;
- 2.实际写入:开始写入文件的权限与数据;开始更新metadata的数据;
- 3.结束:完成数据与metadata的更新后,在日志记录区块当中完成该文件的记录;
在这样的程序当中,万一数据的记录过程当中发生了问题,那么我们的系统只要去检查日志记录区块,就可以知道哪个文件发生了问题,针对该问题来做一致性的检查即可,而不必针对整个文件系统进行检查,这样就可以达到快速修复文件系统的目的,这就是日志式文件最基础的功能。
那么我们的ext2可实现这样的功能吗?
当然可以,使用ext3与ext4即可。ext3与ext4是ex的升级版本,并且可向下兼容ext2版本。所以,目前我们才建议大家,可以直接使用ext4这个文件系统,如果你还记得dumpe2fs 输出的信息,可以发现超级区块里面含有下面这样的信息:
看到了吧!通过inode 8号记录日志区块的区块指向,而且该日志区块具有32MB的容量来记录
日志信息。这样对于所谓的日志式文件系统有没有一点概念呢?
3.Linux文件系统的运行
我们现在知道了目录树与文件系统的关系,但我们也知道,所有的数据要加载到内存后CPU才能够进行处理。
想一想,如果你常常编辑一个好大的文件,在编辑的过程中又频繁地要系统来写入到磁盘中,由于磁盘写入的速度要比内存慢很多,因此你会常常耗在等待磁盘的读写上真没效率。
为了解决这个效率的问题,Linux使用一个称为异步处理(asynchronously)的方式。所谓的异步处理是这样的:
当系统加载一个文件到内存后,如果该文件没有被修改过,则在内存区段的文件数据会被设置为【干净(clean)】。但如果内存中的文件数据被更改过了(例如你用nano去编辑过这个文件),此时该内存中的数据会被设置为【脏的(Dirty)】,此时所有的操作都还在内存中执行,并没有写入到磁盘中。系统会不定时的将内存中设置为【Dirty】的数据写回磁盘,以保持磁盘与内存数据的一致性。你也可以利用sync命令来手动强制写入磁盘。
我们知道内存的速度要比磁盘快得多,因此如果能够将常用的文件放置到内存当中,这不就会提高系统性能了吗?
没错,是有这样的想法。
因此我们Linux系统上面的文件系统与内存有非常大的关系:
- 系统会将常用的文件数据放置到内存的缓冲区,以加速文件系统的读写操作;
- 因此 Linux的物理内存最后都会被用光,这是正常的情况,可加速系统性能;你可以手动使用sync来强制内存中设置为Dirty的文件回写到磁盘中;
- 若正常关机时,关机命令会主动调用sync来将内存的数据回写入磁盘内;
- 但若不正常关机(如断电、宕机或其他不明原因),由于数据尚未回写到磁盘内,因此重新启动后可能会花很多时间在进行磁盘校验,甚至可能导致文件系统的损坏(非磁盘损坏)
4、文件的删除
文件创建后,如何删除?
删除并不是真删除,而是将 inode 对照表 和 Block对照表 中位图信息进行修改即可(只要访问不到,就是删除)
- 根据文件名找到 inode 编号
- 再根据 inode 属性中的映射关系,设置 Block 对照表对应的比特位,设置为 0 (删内容)
- 最后根据 inode 编号设置 inode对照表中对应的比特位为 0 (删属性)
将位图信息置为 0 后,创建新文件时,系统可以直接使用
至于文件的查找与修改,通过 inode 修改其内部属性即可
注意: inode 和 Data blcok 可能存在失衡的情况
- 一直创建空文件,导致 inode 满载,而 Data block 空余很多
- 不断往同一个文件中写入数据,导致 Data block 被占用,后续创建文件时,inode 无法再分配到 Data block
4.1. 删除文件
删除文件的步骤
- 首先根据文件名找到
inode编号 - 再将该文件对应的
inode,在inode位图当中置为无效(置0) - 最后将该文件申请的数据块,在块位图当中置为无效(置0)
此删除操作并不会真正将文件对应的信息删除,而只是将其inode号和数据块号置为了无效,起到了访问不到就等于删除的效果
当我们删除文件后短时间内是可以恢复的
为什么说是短时间内呢,
因为该文件对应的inode号和数据块号已经被置为了无效,因此后续创建其他文件或是对其他文件进行写入操作申请inode号和数据块号时,可能会将该置为无效了的inode号和数据块号分配出去,此时删除文件的数据就会被覆盖,也就无法恢复文件了。
4.2.为什么拷贝文件的时候很慢,而删除文件的时候很快?
- 因为拷贝文件需要先创建文件,然后再对该文件进行写入操作,该过程需要先申请inode号并填入文件的属性信息,之后还需要再申请数据块号,最后才能进行文件内容的数据拷贝,
- 而删除文件只需将对应文件的inode号和数据块号置为无效即可,无需真正的删除文件,因此拷贝文件是很慢的,而删除文件是很快的。
4.3.、文件误删后的解决方案
磁盘中的数据被删除后,还可以再恢复吗?
答案是可以的,但不能完全恢复,并且越早断电、送修越好
前面说过,删除并不是真删除,访问不到就行了,所以只要在删除后,根据 inode 找到 Data block,其中的内容没有被覆盖,数据就可以找回来
应急方案:
- 不要轻举妄动,避免 Data block 被覆盖
- 通过 inode 将 inode 位图 中的位图置 1,使文件复活,再根据属性进行数据恢复
- 如果自己不知道 inode,那就尽早断电,送给厂家恢复(专业)
如何避免误删文件?
- 学习 Windows 中的回收站,删除不是真删除,而是先将文件移入回收站(目录)中,留给用户反悔的时间
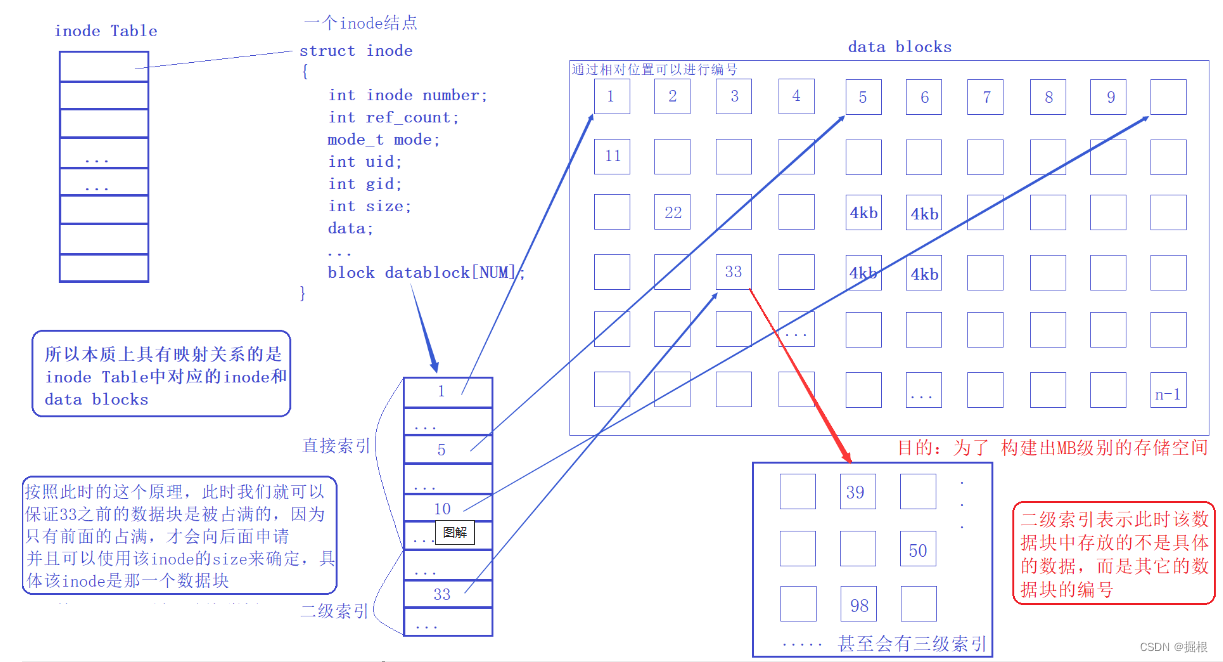
5、大文件存储
单个数据块大小有限(4 kb),如何做到一个数据块存储大量数据?
答案是 套娃,Data block 中存储其他 Data block 信息,此时称为多级索引,可以做到一个数据块中存储大量数据
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【Linux进阶】文件系统6——理解文件操作

发表评论 取消回复