论文复现跳转链接如下
点击跳转 ⭐️

(一)技术学习任务
Ⅰ、机器学习之聚类
1、基本介绍概念
- 监督学习是利用标记数据进行训练,可以用于分类、回归等任务。
- 无监督学习则是利用未标记数据进行训练,可以用于聚类、异常检测等任务(没有对与错,寻找数据的共同特点)。
- 半监督学习则是介于监督学习和无监督学习之间的一种学习方式,利用一小部分已标记数据和大量未标记数据进行训练。
- 强化学习则是利用智能体与环境的交互进行学习,可以用于处理与环境交互的问题。
-
无监督学习 是机器学习的一种重要类型,它专注于从未标记或未分类的数据中发现隐藏的模式和结构。与监督学习不同,无监督学习的数据没有显式的标签或已知的结果变量,其核心目的是探索数据的内在结构和关系。
-
机器学习的二种方法,没有给定事先标记过的训练示例,自动对输入的数据进行分类或分群,
优点:- ①算法不受监督信息(偏见)的约束,可能考虑到新的信息
- ②不需要标签数据,极大程度扩大数据样本
主要应用:聚类分析、关联规则、维度缩减、聚类分析
无监督学习主要包括以下几种任务:
- 聚类:将数据划分为多个群组或簇,使得同一簇内的数据点彼此相似,而不同簇的数据点相异。常见的聚类算法包括K-均值(K-means)、层次聚类(Hierarchical clustering)等。
- 降维:减少数据中的变量数量,提取重要特征,同时保留数据的大部分重要信息。降维有助于提高计算效率、降噪和改进数据可视化。常见的降维算法包括主成分分析(PCA)、t-SNE等。
- 关联规则学习:在大型数据集中发现变量之间的有意义的关系。这有助于市场篮子分析、交叉销售等应用。
- 异常检测:识别数据集中的异常、奇异或不符合预期的数据点。这在欺诈检测、网络安全等领域有重要应用。
- 生成模型:学习数据的分布,以生成新的、与训练数据类似的数据。这有助于数据增强、艺术创作等。
2、聚类分析基本介绍
KMeans聚类:
①根据数据与中心点距离划分类别
②基于类别数据更新中心点
③重复过程直到收敛
特点:
1、实现简单,收敛快
2、需要指定类别数量
均值漂移聚类(Meanshift):
①在中心点一定区域裣索薮据点
②更新中心
③重夏流程到中心点稳定
特点:
1、自动发现类别数量,不需要人工选择
2、需要选择区域半径
DBSCAN算法(基于密度的空间聚类算法)
①基于区域点密度筛选有效数据
②基于有效数据向周边扩张,直到没有新点加入
特点:
1、过滤噪音数据
2、不需要人为选择类别数量
3、数据密度不同时影响结果
3、K均值聚类
- K-均值算法:以空间K个点为中心进行聚类,对最靠近他们的对象归类,是聚类算法中最为基础但也最为重要的算法。
算法流程:
1、选择聚类的个数k
2、确定聚类中心
3、根据点到聚类中心聚类确定各个点所属类别
4、根据各个类别数据更新聚类中心
5、重复以上步骤直到收敛(中心点不再变化)

优点:
1、原理简单,实现容易,收敛速度快
2、参数少,方便使用
缺点:
1、必须设置簇的数量
2、随机选择初始聚类中心,结果可能缺乏一致性
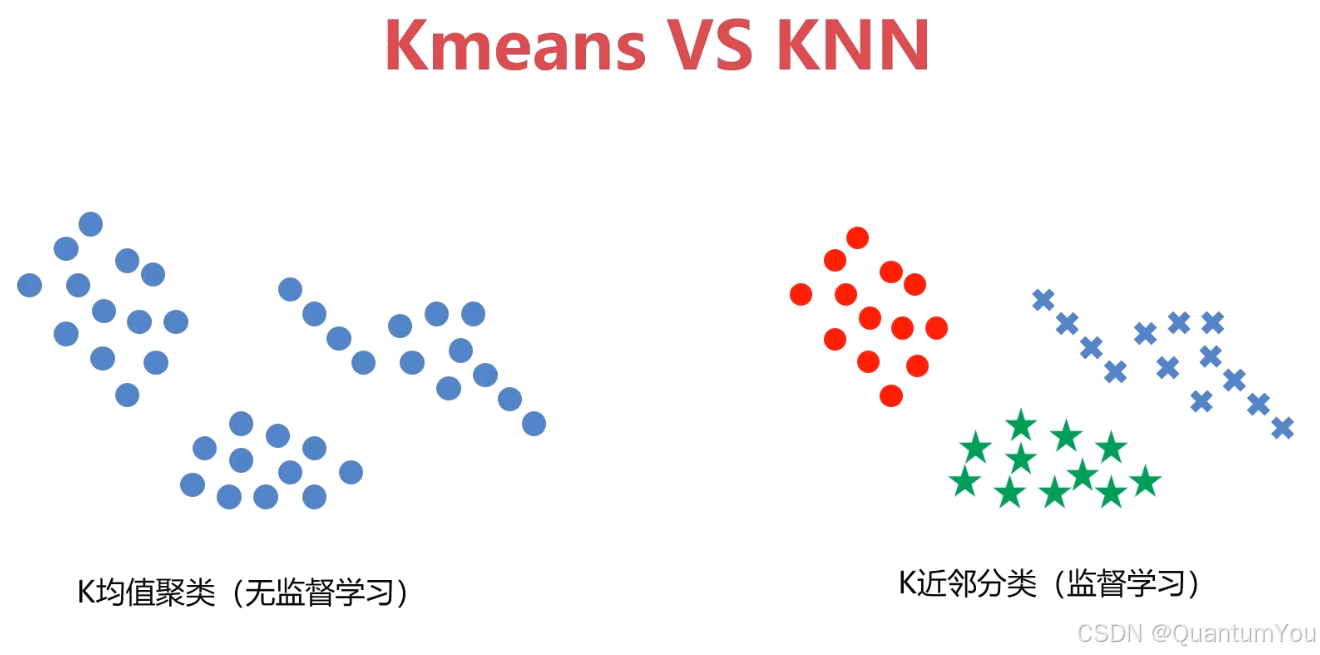
4、K近邻分类模型(KNN)
- 给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该输入实例分类到这个类中。

5、均值漂移聚类
- 均值漂移算法:一种基于密度梯度上升的聚类算法(沿着密度上升方向寻找聚类中心点)
算法流程:
1、随机选择未分类点作为中心点
2、找出离中心点距离在带宽之丙的点,记做集合S
3、计算从中心点到集合S中每个元素的偏移向量M
4、中心点以向量M移动
5、重复步骤2-4,直到收敛
6、重复1-5直到所有的点都被归类
7、分类:根据每个类,对每个点的访问频率,取访问频率最大的那个类,作为当前点集的所属类

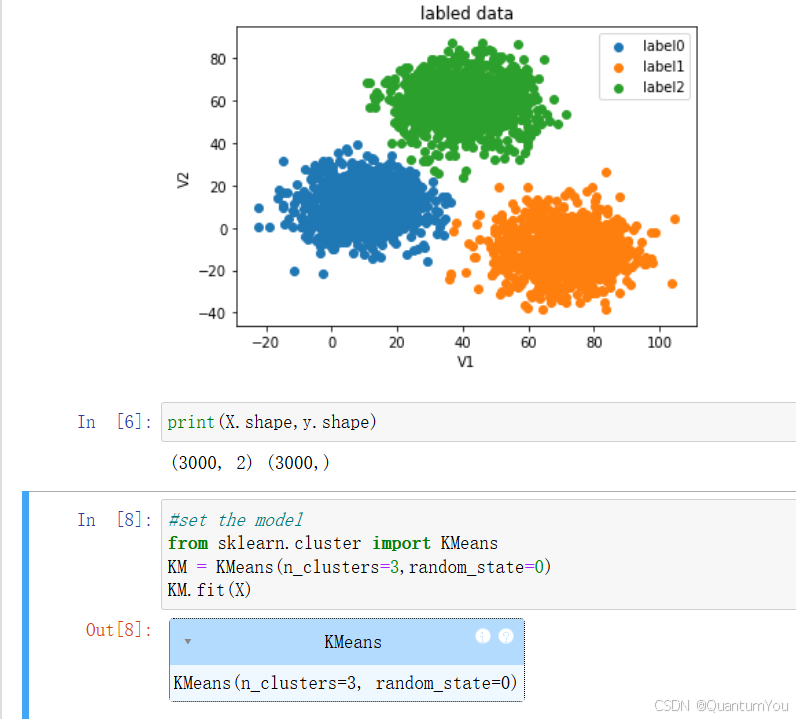
6、代码实现
- KMeans算法实现聚类
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# KMeans算法实现聚类
from sklearn.cluster import KMeans
from sklearn.metrics import accuracy_score
data = pd.read_csv('data.csv')
x = data.drop(['labels'], axis=1)
y = data.loc[:, 'labels']
# print(pd.value_counts(y)) # 查看各个类别的个数
# 数据可视化
plt.figure(figsize=(10, 10))
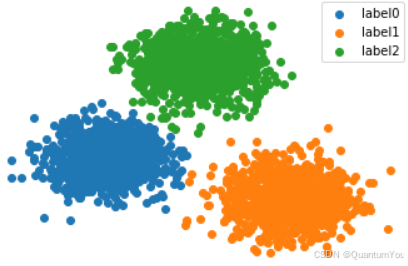
label0 = plt.scatter(x.loc[:, 'V1'][y == 0], x.loc[:, 'V2'][y == 0])
label1 = plt.scatter(x.loc[:, 'V1'][y == 1], x.loc[:, 'V2'][y == 1])
label2 = plt.scatter(x.loc[:, 'V1'][y == 2], x.loc[:, 'V2'][y == 2])
plt.title('title')
plt.xlabel('v1')
plt.ylabel('v2')
plt.legend((label0, label1, label2), ('label0', 'label1', 'label2'))
# plt.show()
km_model = KMeans(n_clusters=3, random_state=0)
km_model.fit(x)
center = km_model.cluster_centers_
# print("中心点", center)
# print(center[:,0],center[:,1])
plt.scatter(center[:, 0], center[:, 1], color='black')
plt.show()
# 计算准确率
y_predict = km_model.predict(x)
print(accuracy_score(y, y_predict))
# 可视化结果索引
plt.figure(figsize=(10, 10))
label0 = plt.scatter(x.loc[:, 'V1'][y_predict == 0], x.loc[:, 'V2'][y_predict == 0])
label1 = plt.scatter(x.loc[:, 'V1'][y_predict == 1], x.loc[:, 'V2'][y_predict == 1])
label2 = plt.scatter(x.loc[:, 'V1'][y_predict == 2], x.loc[:, 'V2'][y_predict == 2])
plt.title('title')
plt.xlabel('v1')
plt.ylabel('v2')
plt.legend((label0, label1, label2), ('label0', 'label1', 'label2'))
plt.show()
# 矫正数据
y_corrected = []
for i in y_predict:
if i == 0:
y_corrected.append(1)
elif i == 1:
y_corrected.append(2)
else:
y_corrected.append(0)
print(accuracy_score(y,y_corrected))
# 可视化结果索引
y_corrected = np.array(y_corrected)
plt.figure(figsize=(10, 10))
label0 = plt.scatter(x.loc[:, 'V1'][y_corrected == 0], x.loc[:, 'V2'][y_corrected == 0])
label1 = plt.scatter(x.loc[:, 'V1'][y_corrected == 1], x.loc[:, 'V2'][y_corrected == 1])
label2 = plt.scatter(x.loc[:, 'V1'][y_corrected == 2], x.loc[:, 'V2'][y_corrected == 2])
plt.title('title')
plt.xlabel('v1')
plt.ylabel('v2')
plt.legend((label0, label1, label2), ('label0', 'label1', 'label2'))
plt.show()
x = data.drop(['labels'], axis=1)
y = data.loc[:, 'labels']
-
第一行代码
x = data.drop(['labels'], axis=1)的作用是从data中删除(或者说“丢弃”)名为labels的列,并将结果赋值给x。这里axis=1指定了操作是沿着列(columns)方向进行的,即删除列而不是行。因此,x将包含data中除了labels列之外的所有列。 -
第二行代码
y = data.loc[:, 'labels']的作用是从data中选取名为labels的列,并将结果赋值给y。这里.loc[]是一个基于标签的索引器,用于通过行标签和列标签来选取数据。在这个例子中,:表示选取所有的行,'labels'表示选取名为labels的列。因此,y将只包含data中的labels列。
plt.figure(figsize=(10, 10))
label0 = plt.scatter(x.loc[:, 'V1'][y == 0], x.loc[:, 'V2'][y == 0])
label1 = plt.scatter(x.loc[:, 'V1'][y == 1], x.loc[:, 'V2'][y == 1])
label2 = plt.scatter(x.loc[:, 'V1'][y == 2], x.loc[:, 'V2'][y == 2])
plt.title('title')
plt.xlabel('v1')
plt.ylabel('v2')
plt.legend((label0, label1, label2), ('label0', 'label1', 'label2'))
-
plt.figure(figsize=(10, 10)): 创建了一个新的图形,其大小为10x10英寸。figsize参数用于设置图形的宽度和高度 。 -
接下来的三行代码分别使用
plt.scatter()函数根据y中的标签(0, 1, 2)将x中的点绘制成三种不同的颜色或标记。这里,x.loc[:, 'V1'][y == 0]表示选取x中所有行、'V1’列,并且这些行的标签(y的值)等于0的点的’V1’值。同理,'V2'和其他标签(1, 2)也是类似的逻辑。 -
plt.legend((label0, label1, label2), ('label0', 'label1', 'label2')):添加图例。label0、label1、label2是之前通过plt.scatter()返回的散点图对象,它们分别代表三个不同标签的点的集合。
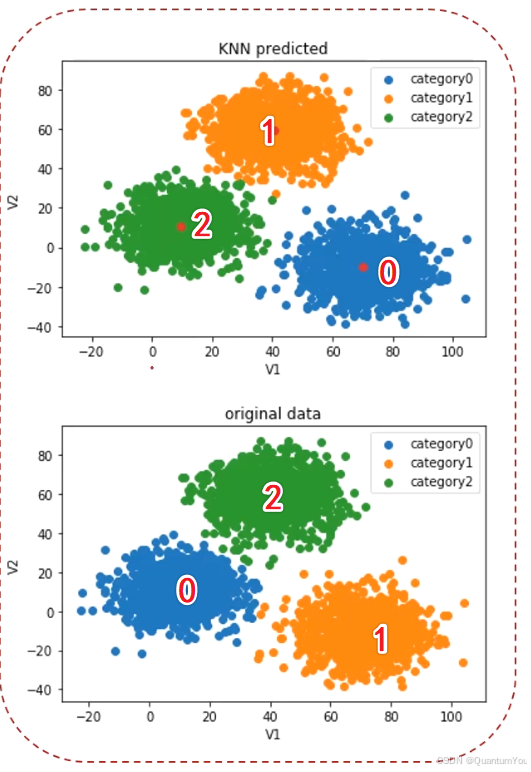
- Meanshift实现聚类
data = pd.read_csv('data.csv')
x = data.drop(['labels'], axis=1)
y = data.loc[:, 'labels']
r = estimate_bandwidth(x, n_samples=50000)
# print(r)
ms_model = MeanShift(bandwidth=r)
ms_model.fit(x)
y_pred = ms_model.predict(x)
print(pd.value_counts(y_pred))
print(pd.value_counts(y))
# 数据矫正(0->2,1->1,2->0)
y_corrected = []
for i in y_pred:
if i == 0:
y_corrected.append(2)
elif i == 1:
y_corrected.append(1)
else:
y_corrected.append(0)
print(accuracy_score(y, y_corrected))
-
首先使用了
estimate_bandwidth函数来估计数据集x的带宽r,这个带宽随后被用作MeanShift聚类算法的参数。然后,使用估计得到的带宽r来初始化MeanShift模型,并对数据集x进行拟合,最后对同一数据集x进行预测以获取聚类标签y_pred -
KNN实现分类
knn_model = KNeighborsClassifier(n_neighbors=3)
knn_model.fit(x, y)
y_pred = knn_model.predict(x)
- 首先使用
fit方法对训练数据集x和对应的标签y进行训练。然后,使用predict方法尝试对相同的数据集x进行预测。
7、上述三种算法总结
-
KNN:是监督学习方法的一种,用于分类和回归。它依赖于已知标签的数据集来对新数据进行分类或预测。
-
Kmeans:是无监督学习方法的一种,主要用于聚类分析。它不需要数据集的标签信息,而是根据数据之间的相似度将数据分为若干个簇。
-
Meanshift:同样属于无监督学习方法,也是用于聚类分析。它通过迭代过程寻找数据的聚类中心,与Kmeans类似,但具有更强的自适应性和对噪声的鲁棒性。
- 算法原理
-
KNN:通过计算待分类样本与训练集中各样本之间的距离,找出距离该样本最近的k个邻居,并根据这k个邻居的类别信息,采用多数投票或加权平均等方法来确定待分类样本的类别。
-
Kmeans:随机选择k个数据点作为初始簇中心,然后根据数据点到簇中心的距离将数据点分配到最近的簇中,之后更新簇中心为簇内所有点的均值,重复此过程直到簇中心不再发生变化或达到预设的迭代次数。
-
Meanshift:从一组数据点中随机选择一个点作为初始中心点,然后根据一定的带宽(或称为窗口大小)计算该中心点周围的数据点的密度,并更新中心点位置为密度加权的平均值,重复此过程直到中心点收敛或达到预设的迭代次数。
- 应用场景
- KNN:适用于分类和回归问题,特别是当数据集较大且类别分布较为均匀时。由于其简单直观,KNN也常用于初步的数据分析和探索性学习中。
- Kmeans:广泛应用于聚类分析领域,如市场细分、图像处理、文本聚类等。Kmeans能够快速地将数据分为若干个簇,帮助人们理解数据的内在结构和分布规律。
- Meanshift:由于其自适应性和对噪声的鲁棒性,Meanshift算法在复杂数据集的聚类分析中表现出色。特别是在处理具有不规则形状或重叠簇的数据集时,Meanshift算法往往能够取得比Kmeans更好的聚类效果。
- 优缺点
- KNN:优点包括简单易用、模型训练时间快、预测效果好等;缺点则包括对内存要求较高、预测阶段可能较慢、对不相关的功能和数据规模敏感等。
- Kmeans:优点在于实现简单、聚类效果好、计算复杂度低;缺点则包括需要事先指定簇的个数k、对初始簇中心的选择敏感、可能陷入局部最优解等。
- Meanshift:优点在于自适应性强、对噪声鲁棒性强、能够处理复杂形状和重叠簇的数据集;缺点则包括计算复杂度较高、对带宽的选择敏感等。
Ⅱ、机器学习其他常用技术
1、决策树基本知识
- 决策树 是一种常用的监督学习算法,用于分类和回归任务。它主要通过树状图的形式来表现数据分类的过程,每个内部节点表示一个属性上的判断,每个分支代表一个判断结果的输出,而每个叶节点代表一种分类结果。决策树模型易于理解和解释,同时能够处理具有不相关特征的数据。
构建决策树的过程通常包括以下几个步骤:
-
特征选择:从给定的特征集中选择一个最优特征来分割数据集,使得分割后的数据集更加“纯净”或“一致”(即同一类别的数据尽可能在同一个子集中)。
-
决策树生成:按照选择的特征,将数据集分割成若干个子集,并为每个子集递归地选择最优特征进行分割,直到满足停止条件(如子集纯度足够高、所有特征都已使用、子集中的样本数小于预设阈值等)。
-
决策树剪枝:由于决策树容易过拟合,即模型在训练数据上表现很好,但在新数据上表现不佳,因此需要通过剪枝来简化决策树,提高模型的泛化能力。剪枝分为预剪枝和后剪枝,前者在决策树生成过程中进行,后者在决策树生成后进行。
决策树的优点
- 能够处理不相关特征:通过特征选择,决策树可以自动忽略不相关特征。
- 可以处理非线性关系:决策树模型能够捕获变量之间的非线性关系。
- 适合高维数据:决策树不需要对特征进行缩放或中心化处理,适用于高维数据。
决策树的缺点
- 容易过拟合:如果决策树过于复杂,可能会导致过拟合。
- 不稳定性:数据的小变化可能会导致生成的决策树结构发生显著变化。
- 不适合处理连续变量:虽然可以通过离散化连续变量来处理,但这会增加模型的复杂度。
首先引入常用分类方法
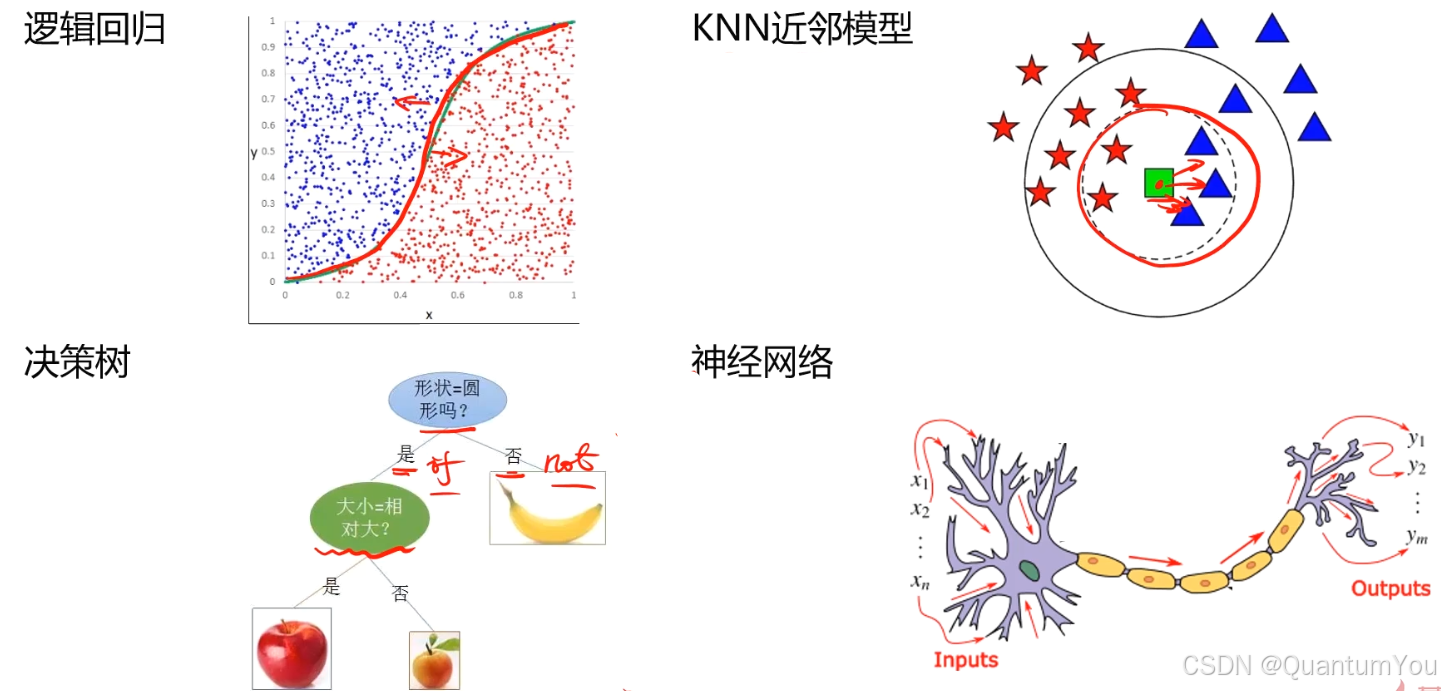
- 一种对实例进行分类的树形结构,通过多层判断区分目标所属类别
- 本质:通过多层判断,从训练数据集中归纳出一组分类规则
优点:
- 计算量小,运算速度快,易于理解,可清晰查看各属性的重要性
缺点:
- 忽略属性间的相关性,样本类别分布不时,容易影响模型表现
决策树 求解

Ent(D)的值越小,变量的不确定性越小。


目标:划分后样本分布不确定性尽可能小,即划分后信息熵小,信息增益大
2、异常检测概念
- 在基于高斯分布(也称为正态分布)的异常检测中,通常使用数据的均值( μ \mu μ)和标准差( σ \sigma σ)来评估数据点的正常性或异常性。一个常用的方法是计算数据点到其分布均值的距离,并将其与标准差进行比较,以此来判断该数据点是否异常。
高斯分布的概率密度函数
f ( x ∣ μ , σ 2 ) = 1 2 π σ 2 e − ( x − μ ) 2 2 σ 2 n i n i f(x | \mu, \sigma^2) = \frac{1}{\sqrt{2\pi\sigma^2}} e^{-\frac{(x-\mu)^2}{2\sigma^2}}nini f(x∣μ,σ2)=2πσ21e−2σ2(x−μ)2nini
其中, x x x 是随机变量, μ \mu μ 是均值, σ 2 \sigma^2 σ2 是方差,而 σ \sigma σ 是标准差。
- 在异常检测中,我们可能会定义一个阈值(比如,基于标准差的数量),超过这个阈值的数据点被认为是异常的。例如,一个常用的方法是使用 3 σ 3\sigma 3σ规则,即认为距离均值超过 3 σ 3\sigma 3σ的数据点是异常的。这可以表达为:
∣ x − μ ∣ > 3 σ |x - \mu| > 3\sigma ∣x−μ∣>3σ
如果 x x x满足上述不等式,则 x x x被视为异常值。

3、主成分分析
数据降维
一、定义
- 数据降维是通过保留数据的主要信息和结构,将高维数据转换为低维表示的过程。它旨在消除冗余和噪声,提炼出数据的最重要的方面,从而简化数据分析和可视化的任务。
二、目的
- 减少计算复杂性:高维数据可能导致计算资源的浪费,数据降维可以减少计算的时间和空间复杂性,提高模型的训练和预测效率。
- 消除冗余信息:高维数据中可能存在冗余特征,这些特征对模型的训练并没有太大的帮助,甚至可能引起过拟合。数据降维可以消除这些冗余信息,提高模型的泛化能力。
- 可视化和解释性:降维后的数据可以更容易地进行可视化和解释,帮助我们更好地理解数据和模型的特征。
三、方法
数据降维的方法主要分为两类:特征选择和主成分分析(PCA)。
-
特征选择
- 定义:在所有特征中选择部分特征作为训练集特征,选择后特征的值不改变,但是选择后的特征维数会降低。
-
主成分分析(PCA)
- 定义:PCA是一种分析、简化数据集的技术,其核心在于数据维度压缩,尽可能降低原数据的维度,同时损失少量信息。
- 原理:通过线性变换将原始数据映射到一个新的低维空间中,这个新空间是由原始数据的主成分(即方差最大的方向)构成的。
- 步骤:
- 标准化数据:将原始数据进行标准化处理,使其满足正态分布。
- 计算协方差矩阵:计算数据矩阵的协方差矩阵。
- 计算特征值和特征向量:将协方差矩阵的特征值和特征向量进行排序,选择Top-k个特征值和对应的特征向量。
- 构建降维矩阵:将Top-k个特征向量构建成降维矩阵。
- 进行降维:将原始数据矩阵与降维矩阵进行乘积运算,得到降维后的数据矩阵。
如何保留主要信息:投影后的不同特征数据尽可能分得开(即不相关)
计算过程:
- 原始数据预处理(标准化:u=0 σ=1)
- 计算协方差矩阵特征向量、及数据在各特征向量投影后的方差
- 根据需求(任务指定或方差比例)确定降维维度k
- 选取k维特征向量,计算数据在其形成空间的投影
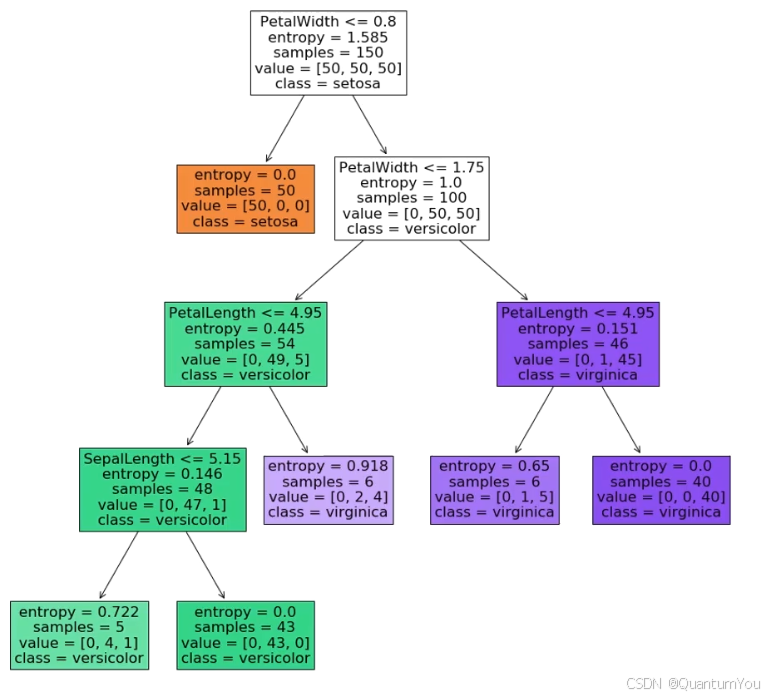
4、决策树代码实现
- 决策树官方文档
https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html#sklearn.tree.DecisionTreeClassifier
# 决策树模型
from sklearn import tree
from sklearn.metrics import accuracy_score
from matplotlib import pyplot as plt
# 加载数据
data = pd.read_csv('iris_data.csv')
x = data.drop(['target', 'label'], axis=1)
y = data.loc[:, 'label']
# print(x.shape, y.shape)
# 训练模型
dc_tree = tree.DecisionTreeClassifier(criterion='entropy', min_samples_leaf=1)
dc_tree.fit(x, y)
y_pred = dc_tree.predict(x)
print(accuracy_score(y, y_pred))
# 画图
plt.figure(figsize=(30, 30))
tree.plot_tree(dc_tree, filled=True,
feature_names=['sepal length', 'sepal width', 'petal length', 'petal width']
, class_names=['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'])
# plt.show()
# 下载图片
plt.savefig('iris_tree2.png')
5、基于高斯分布的异常检测代码
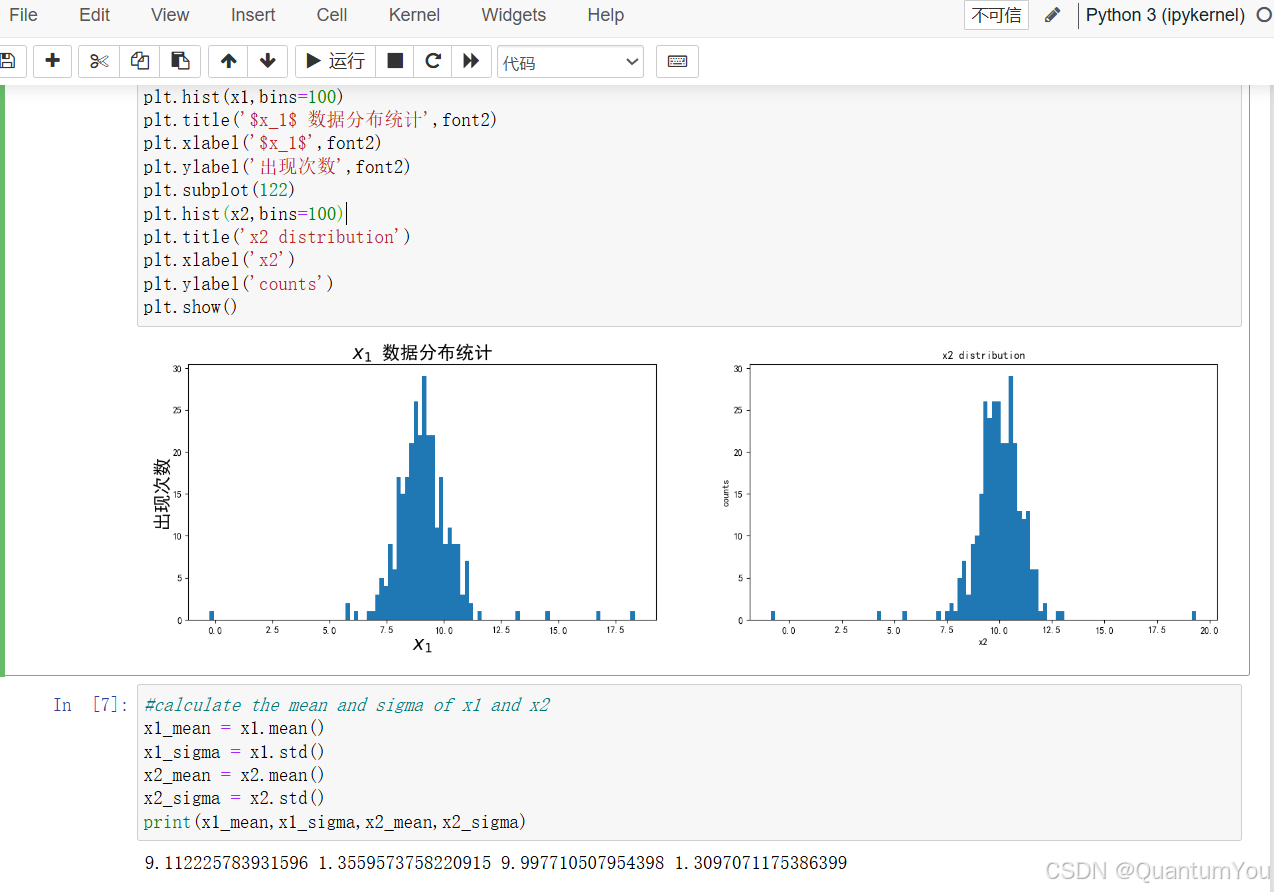
from scipy.stats import norm
x1_range = np.linspace(0,20,300)
x1_normal = norm.pdf(x1_range,x1_mean,x1_sigma)
x2_range = np.linspace(0,20,300)
x2_normal = norm.pdf(x2_range,x2_mean,x2_sigma)
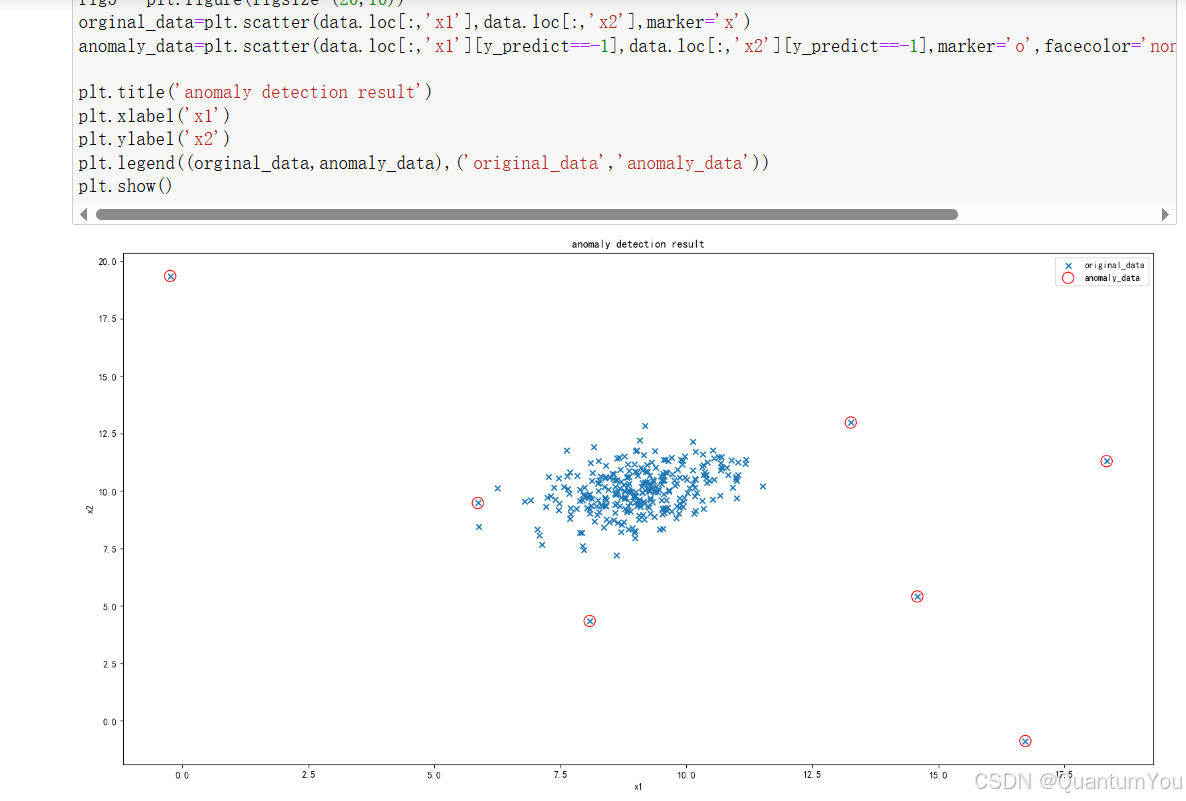
- 1、通过计算数据各维度对应的高斯分布概率密度函数,可用于寻找到数据中的异常点;
- 2、通过修改概率密度阈值
contamination,可调整异常点检测的灵敏度;
6、主成分分析代码实现
实现步骤
- 1、基于
iris_data.csv数据,建立KNN模型实现数据分类(n_neighbors=3) - 2、对数据进行标准化处理,选取一个维度可视化处理后的效果
- 3、进行与原数据等维度PCA,查看各主成分的方差比例
- 4、保留合适的主成分,可视化降维后的数据
- 5、基于降维后数据建立KNN模型,与原数据表现进行对比
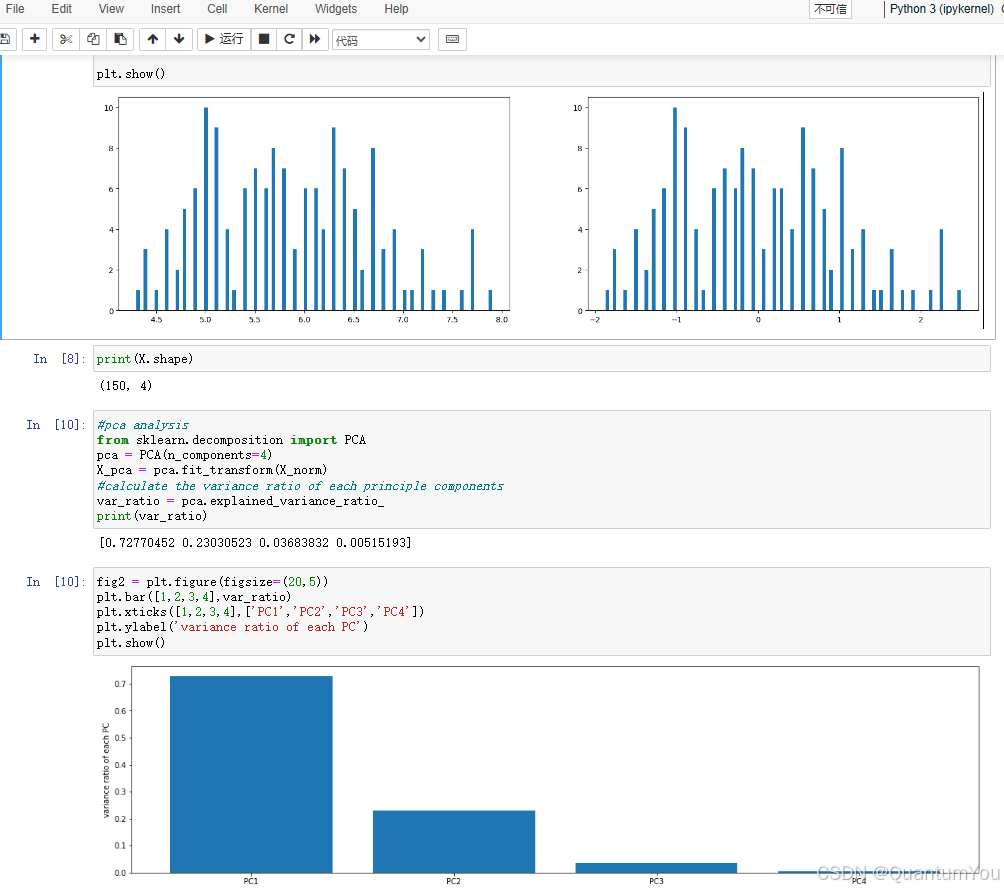
# 建立KNN模型
KNN_MODE = KNeighborsClassifier(n_neighbors=3)
KNN_MODE.fit(X, Y)
y_pred = KNN_MODE.predict(X)
print(accuracy_score(Y, y_pred))
# 标准化处理
x_norm = StandardScaler().fit_transform(X)
# 计算处理后的数据的均值和标准差
x_mean = x_norm.mean()
x_std = x_norm.std()
# 打印均值和标准差
print(X.loc[:, 'sepal length'].mean(), x_mean)
print(X.loc[:, 'sepal length'].std(), x_std)
# 可视化处理
plt.figure(figsize=(10, 10))
plt.subplot(121)
plt.hist(X.loc[:, 'sepal length'], bins=100)
plt.title('sepal length')
plt.subplot(122)
plt.hist(x_norm[:, 0], bins=100)
plt.title('sepal length')
plt.show()
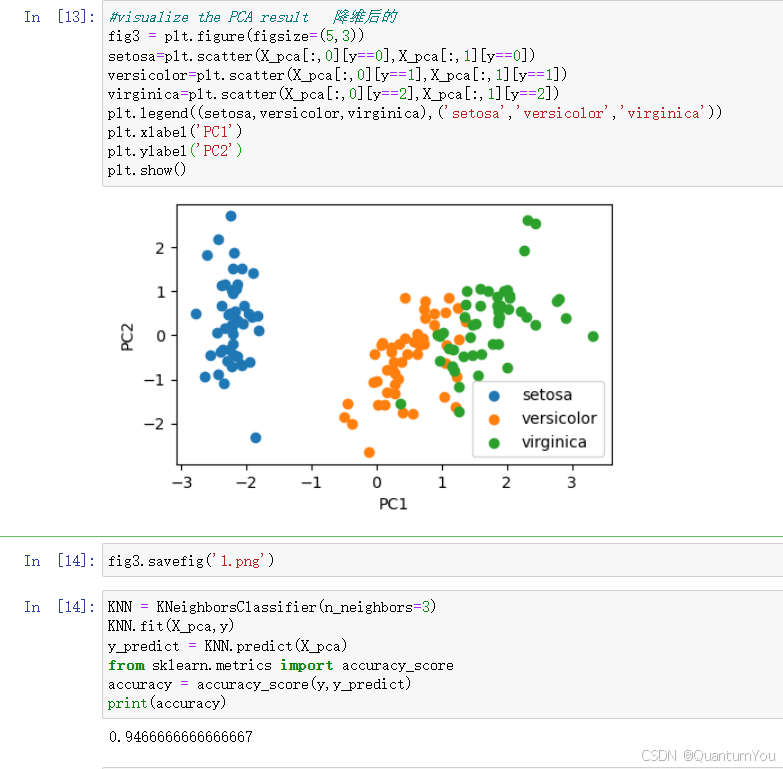
# PCA
pca = PCA(n_components=4)
x_pca = pca.fit_transform(x_norm)
# 打印方差
print(pca.explained_variance_ratio_)
# 可视化操作
plt.figure(figsize=(20, 10))
plt.bar([1, 2, 3, 4], pca.explained_variance_ratio_)
plt.xticks([1, 2, 3, 4], ['pca1', 'pca2', 'pca3', 'pca4'])
plt.show()
# 只保留2个维度
pca = PCA(n_components=2)
x_pca = pca.fit_transform(x_norm)
# print(x_pca.shape)

(二)论文复现工作
Ⅰ、项目准备运行工作
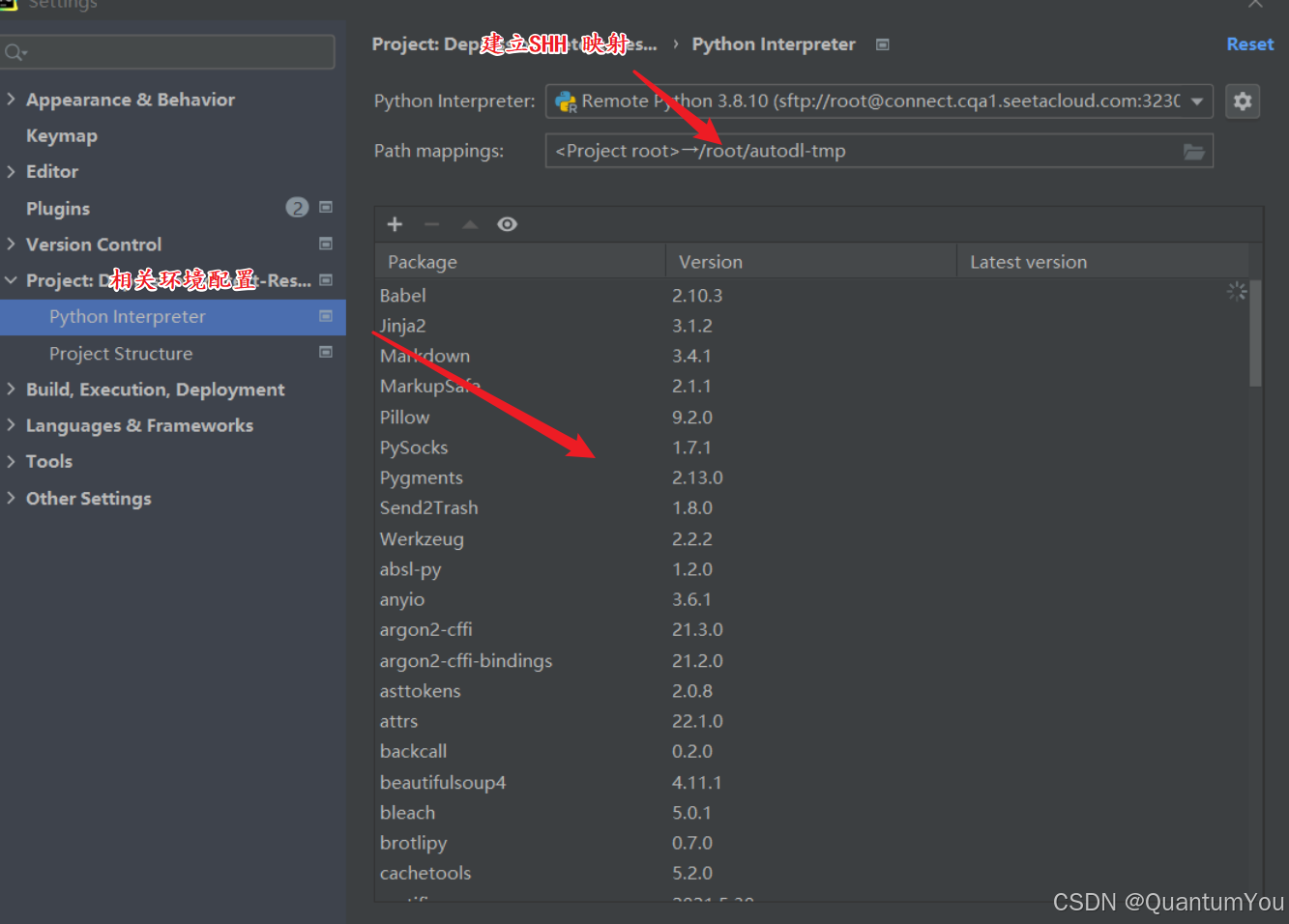
1、配置项目环境
- 从以往的本地环境迁移至服务器环境,注意包的版本号
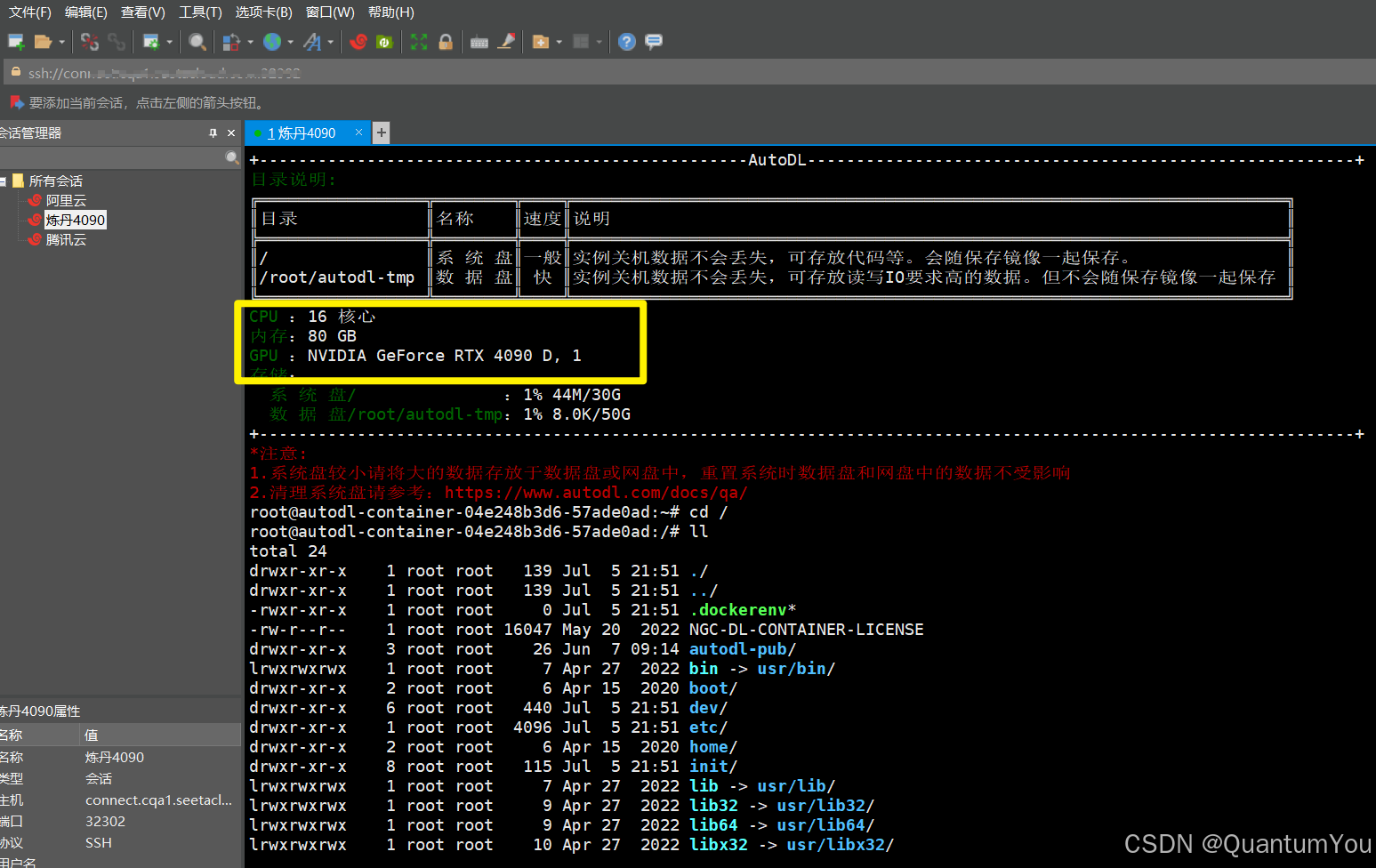
2、连接4090运行项目
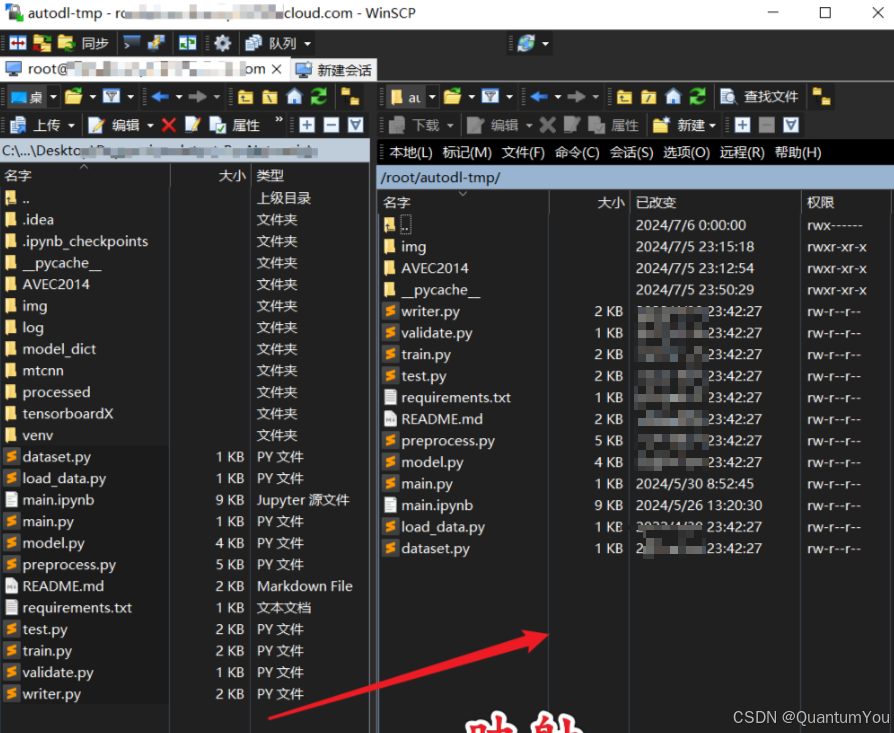
3、进行映射至服务器
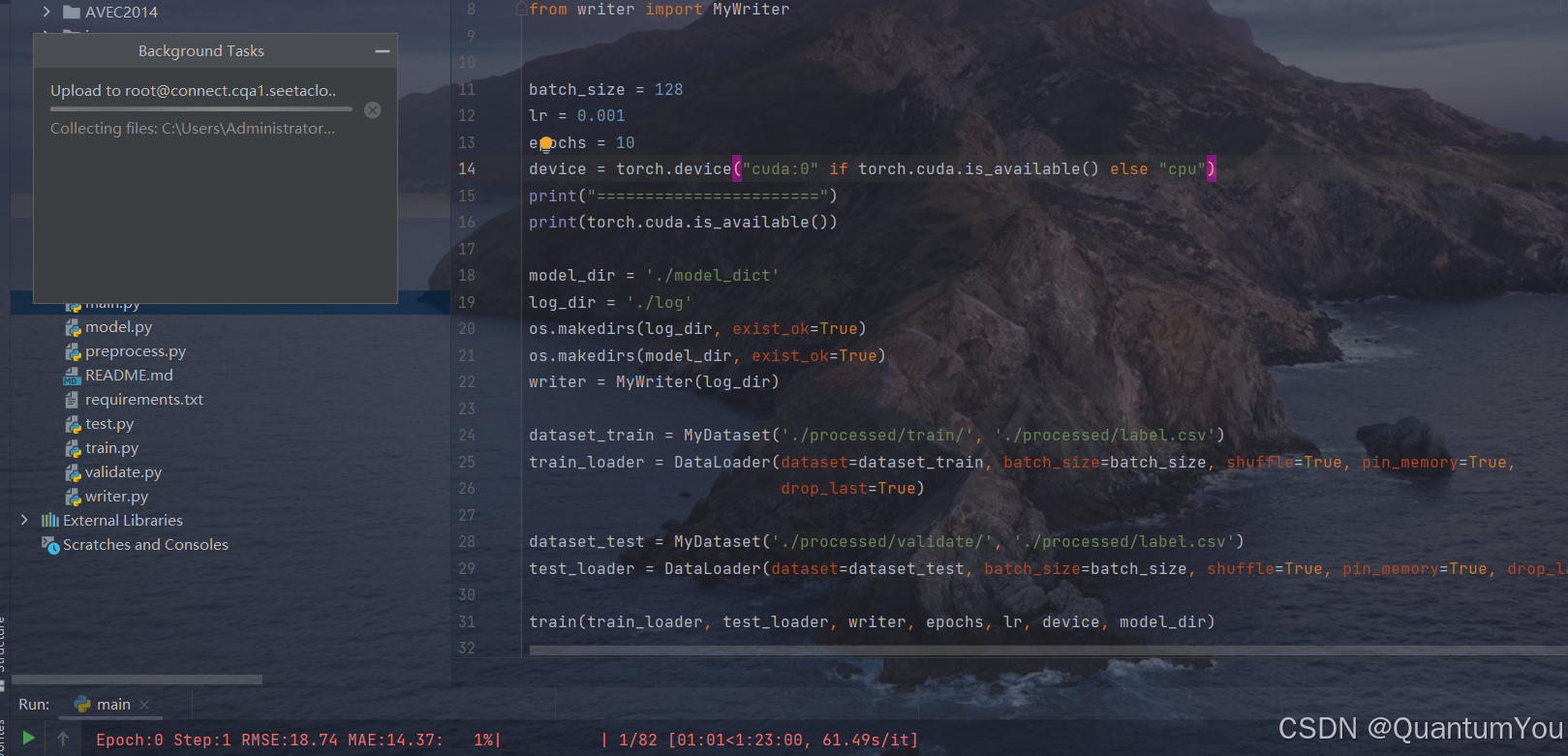
Ⅱ、复现过程中问题及其解决方案
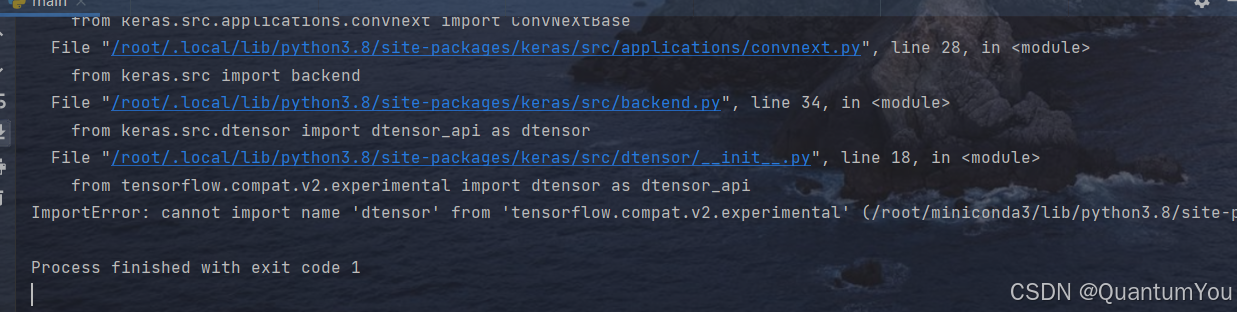
1、dtensor问题及其解决方案
解决方案:
pip install keras==2.6
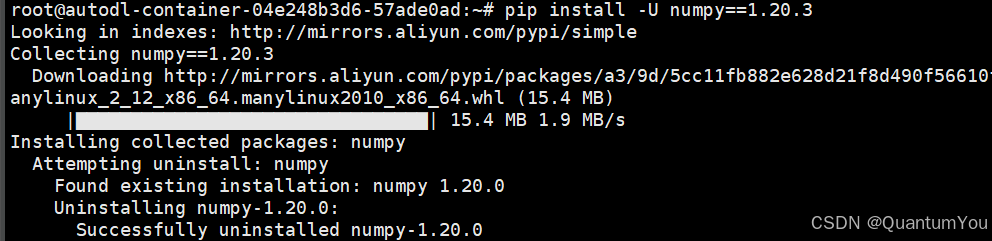
2、np.object问题及其解决方案
解决方案:
AttributeError: module numpy has no attribute object . np.object
pip install -U numpy==1.20.3
3、protocol问题及其解决方案
解决方案:
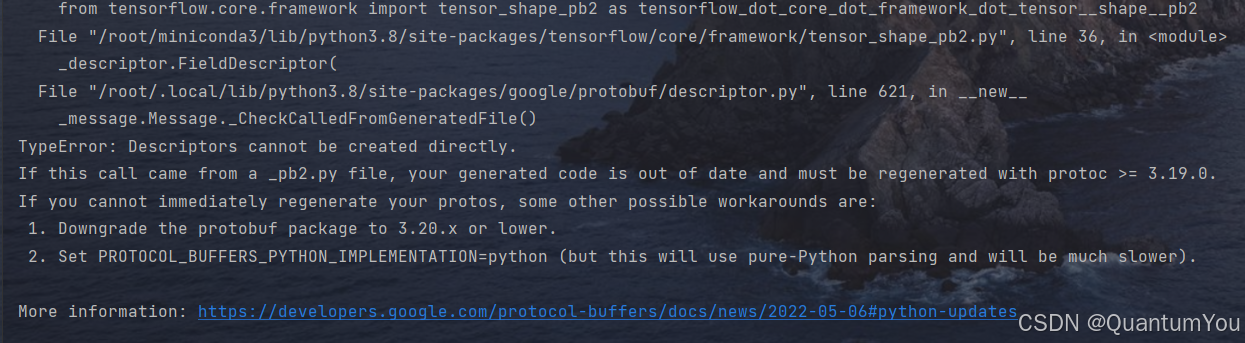
pip install protocol==3.19.0
或更新torchvision
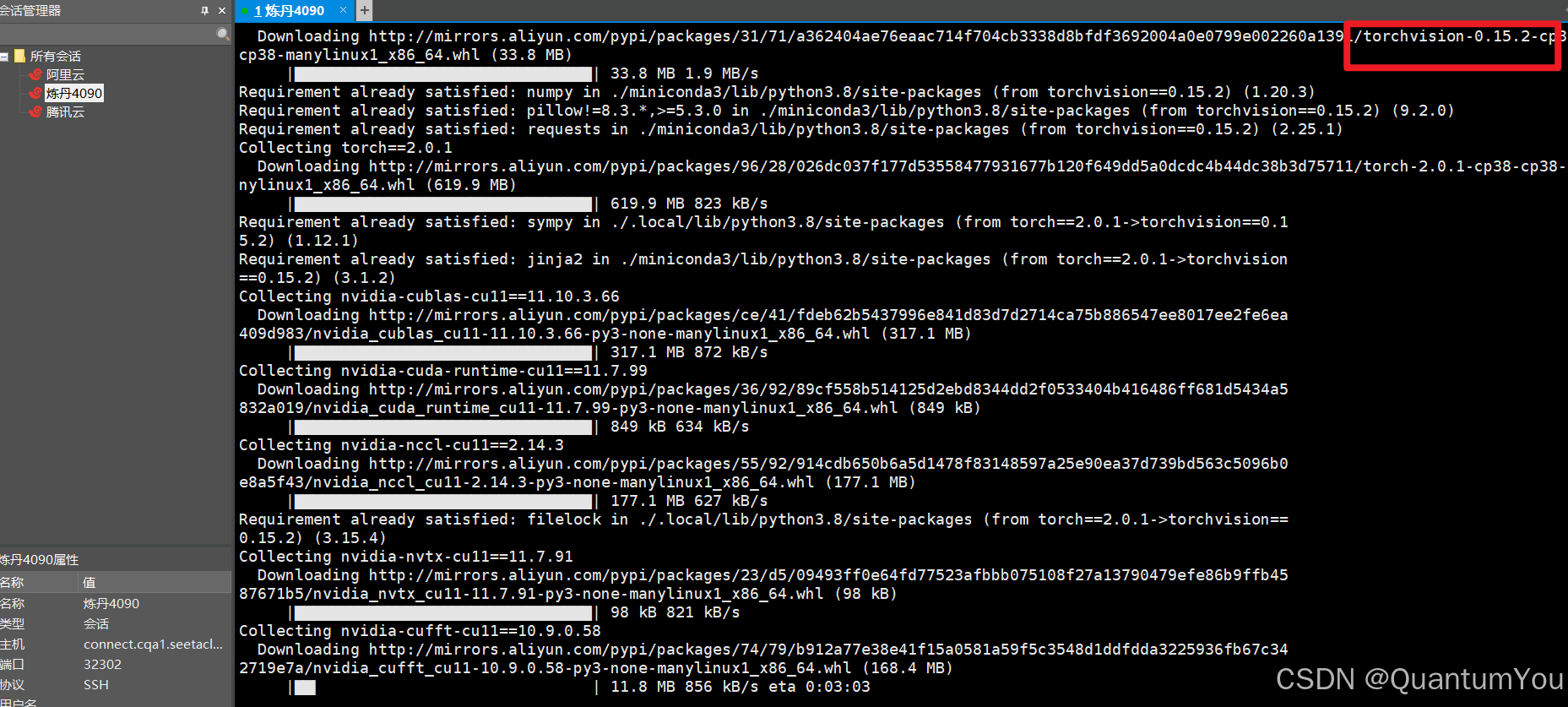
这个更新好久哇
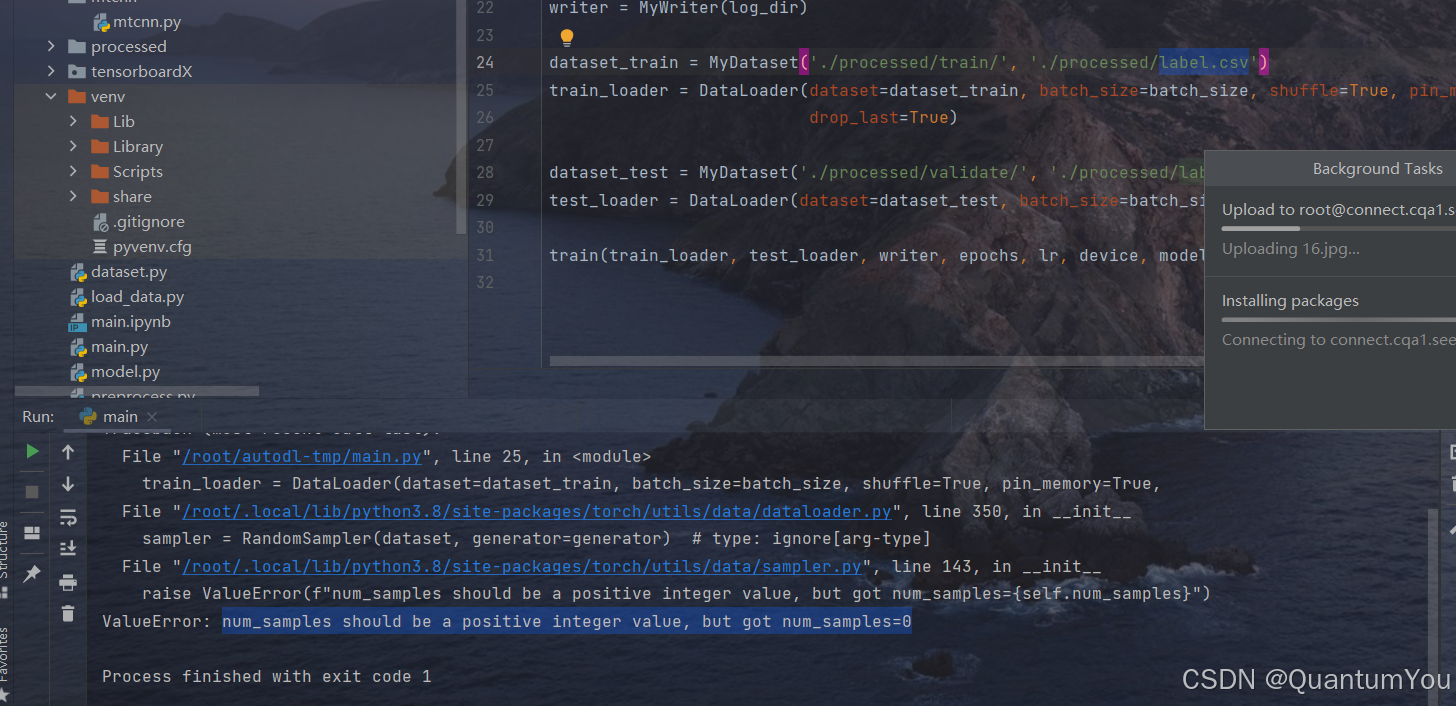
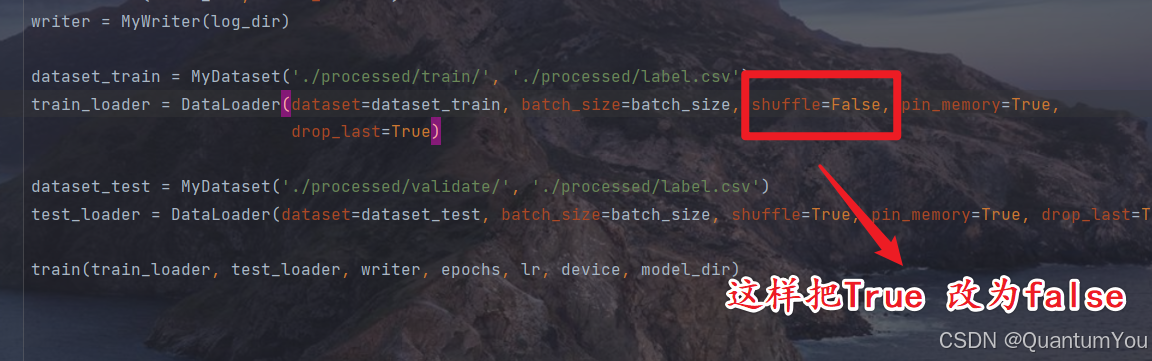
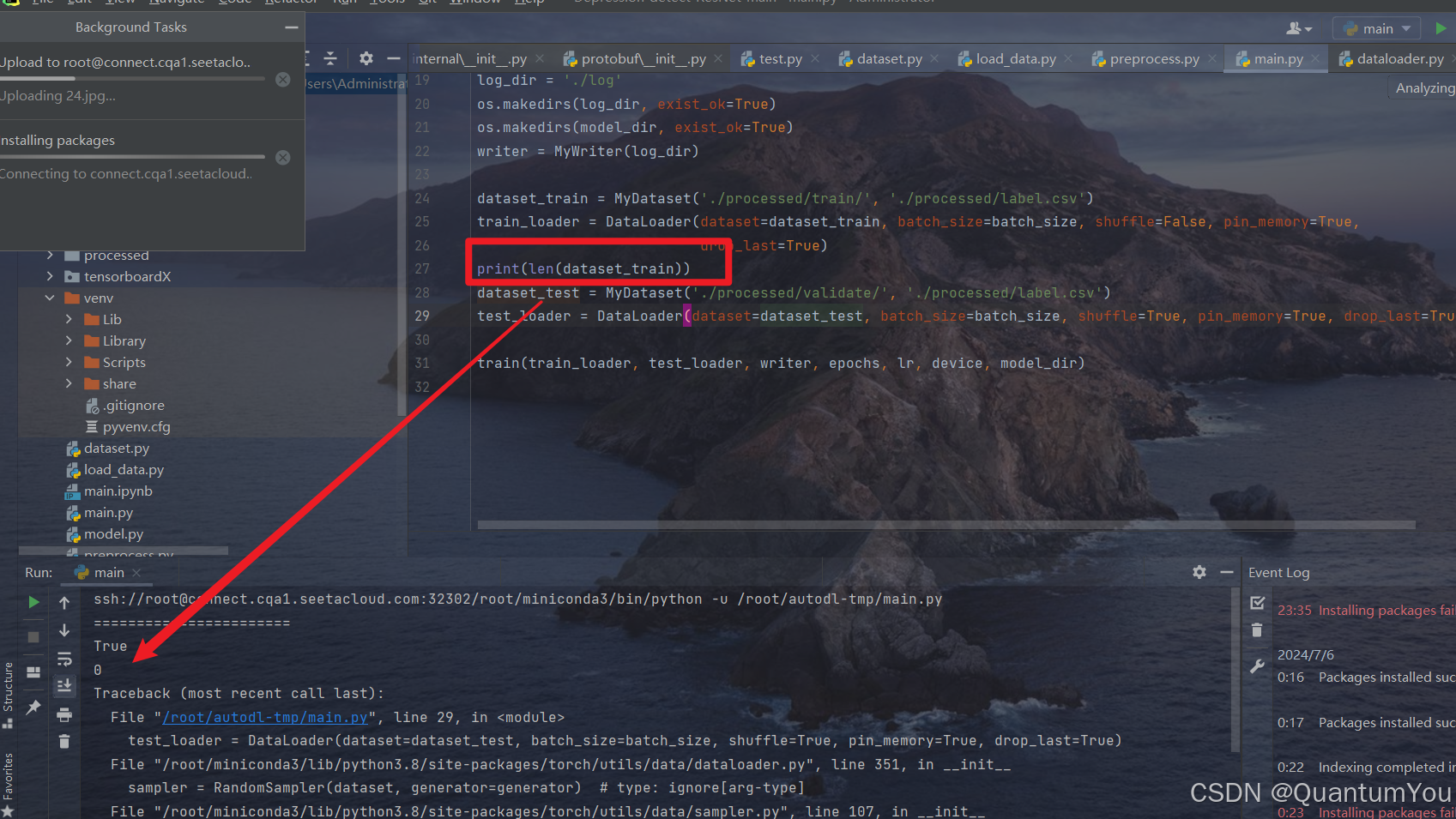
4、num_samples 问题及其解决方案
- 本质是路径问题,找不到文件当然没有num_samples
通过层层发现 实际是路径的问题
开始上传路径缺失的文件 - 关于文件大上传服务器技巧: 可以进行压缩上传 突然想到
unzip test.zip

5、torch.cuda.FloatTensor问题及其解决方案
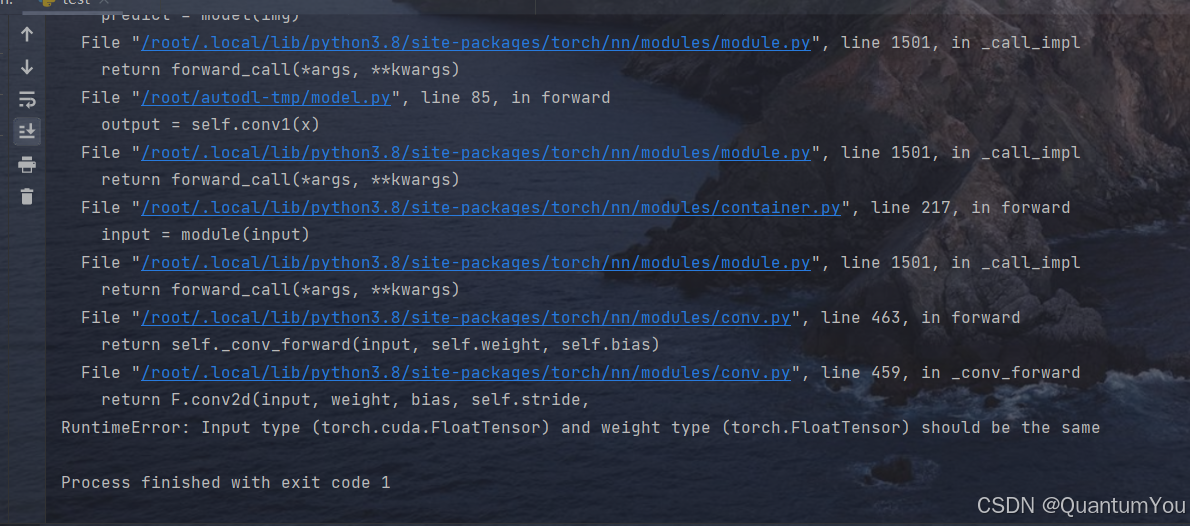
- 输入的数据类型为
torch.cuda.FloatTensor,说明输入数据在GPU中模型参数的数据类型为torch.FloatTensor,说明模型还在CPU
问题原因搞清楚了,模型没加载到CPU,在代码中加一行语句就可以了
model = model.cuda()
model = model.to('cuda')
model.cuda()
model.to('cuda')
上面四行任选一,还有其他未列出的表述方法,都可以将模型加载到GPU。
- 反之
Input type (torch.FloatTensor) and weight type (torch.cuda.FloatTensor) should be the问题来源是输入数据没有加载到GPU,解决方法为任选其一
tensor = tensor.cuda()
tensor = tensor.to('cuda')
Ⅲ、折腾了好久终于开始炼丹
1、训练过程
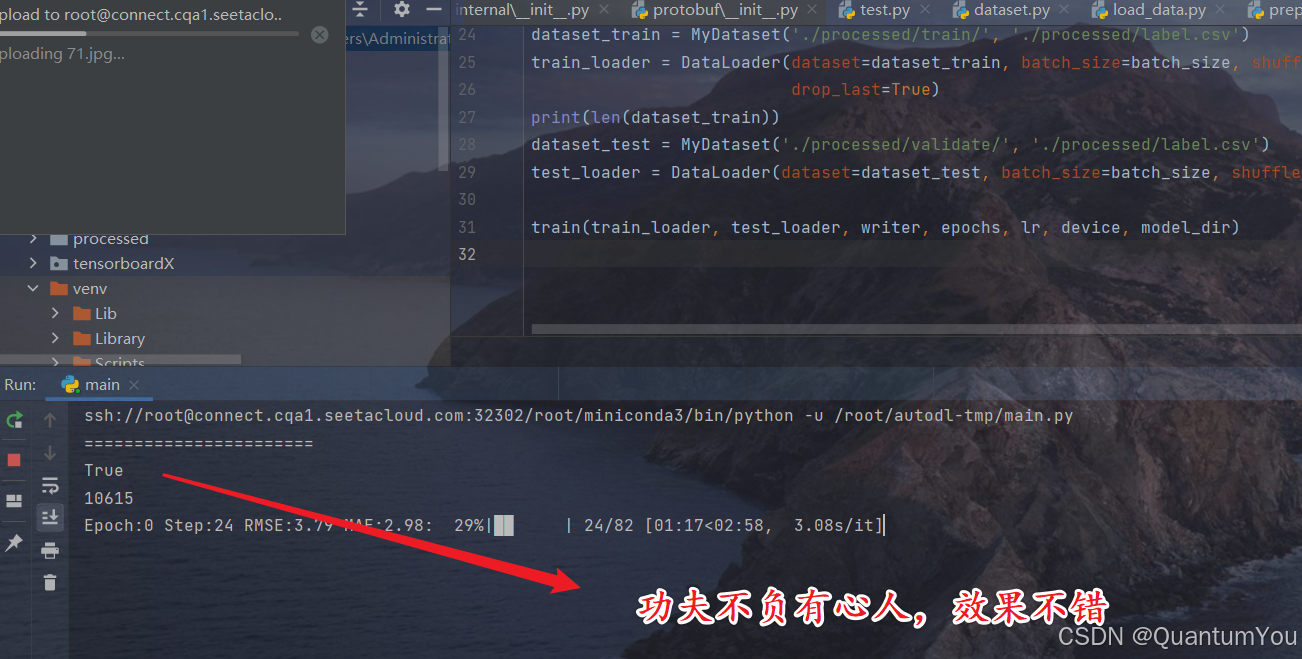
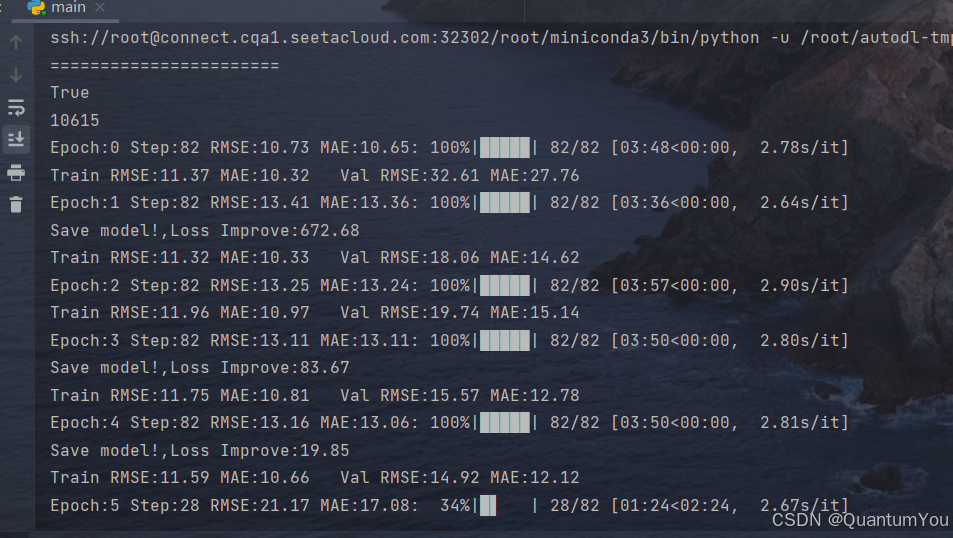
- 性能确实不错,我自己电脑本地运行一两天都不一定训练完成,4090一两小时就训练好了
2、预测过程
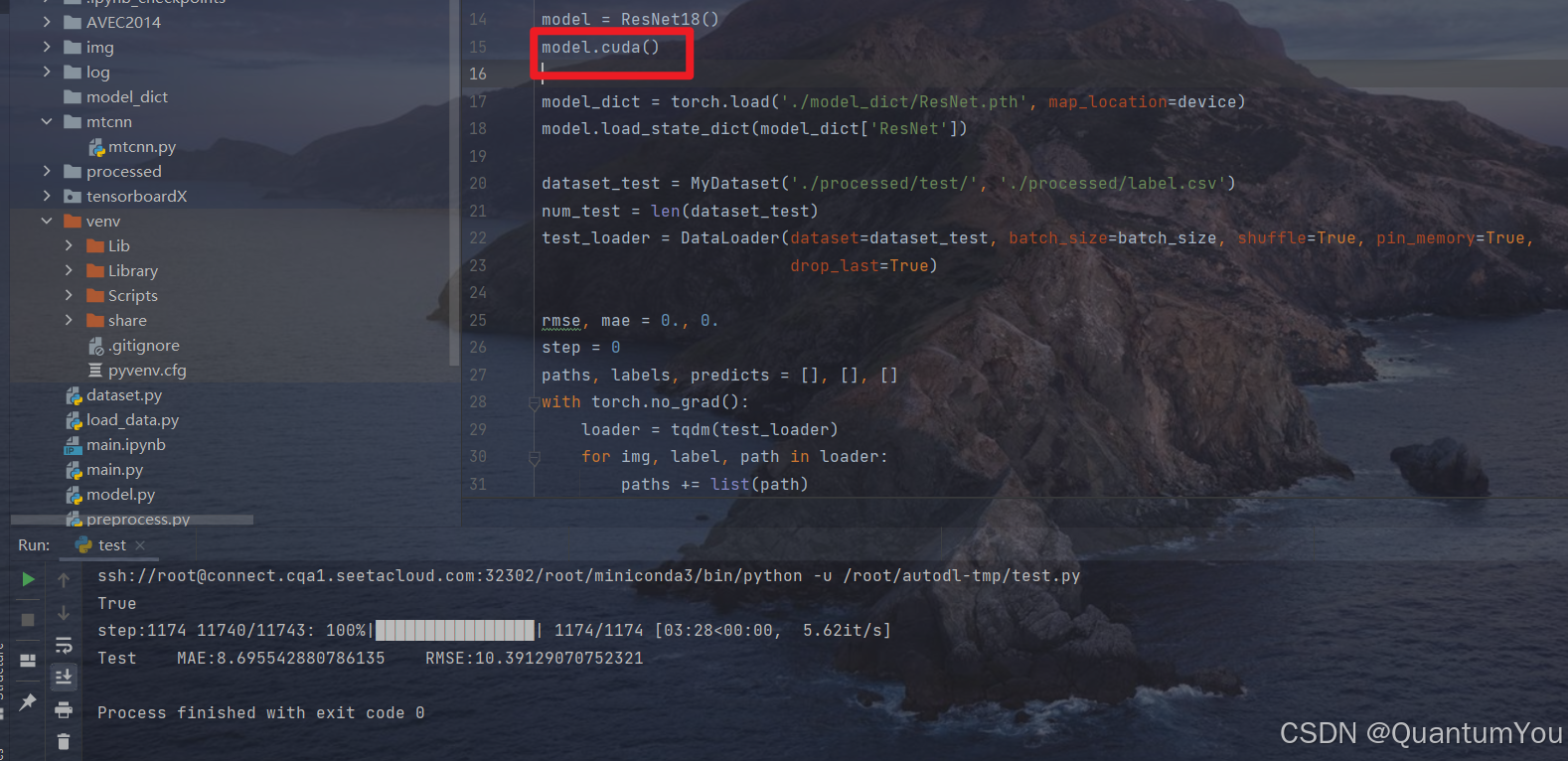
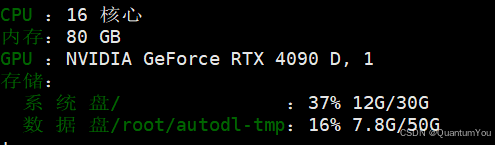
- 看一下运行完成后所占的空间
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 人工智能项目论文复现

发表评论 取消回复