ACL 2024
- 人类通常在不损害旧技能的情况下获得新技能
- 然而,对于大型语言模型(LLMs),例如从LLaMA到CodeLLaMA,情况正好相反。
- 深度学习笔记:灾难性遗忘-CSDN博客
- ——>论文提出了一种用于LLMs的新的预训练后方法
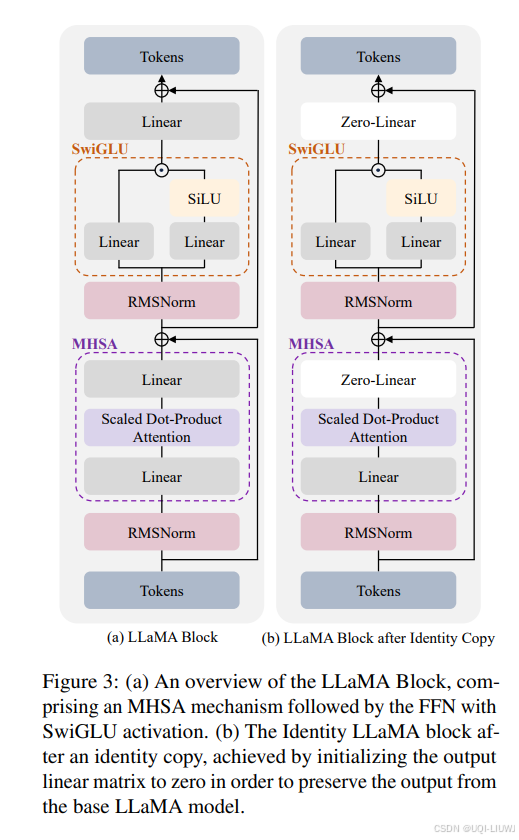
- 包括Transformer块的扩展
- 仅使用新语料库调整扩展块,以高效而有效地提升模型的知识,而不引发灾难性的遗忘
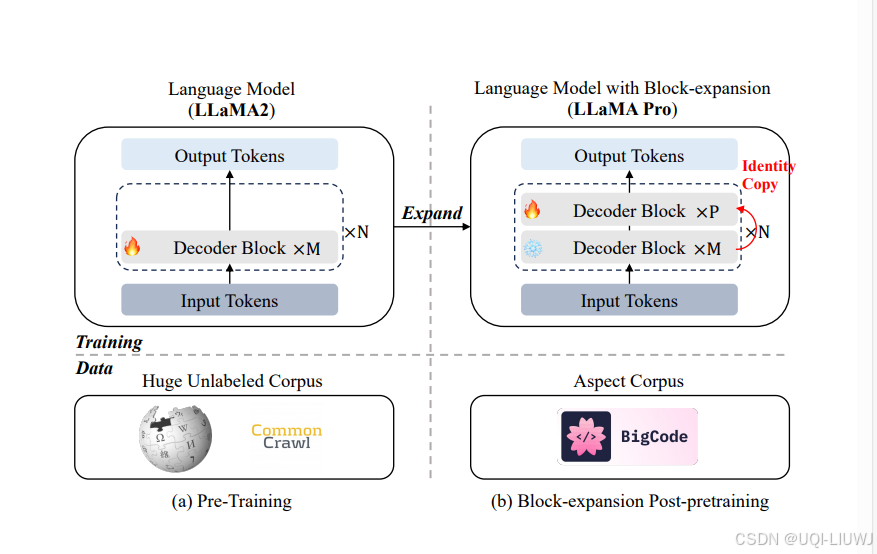
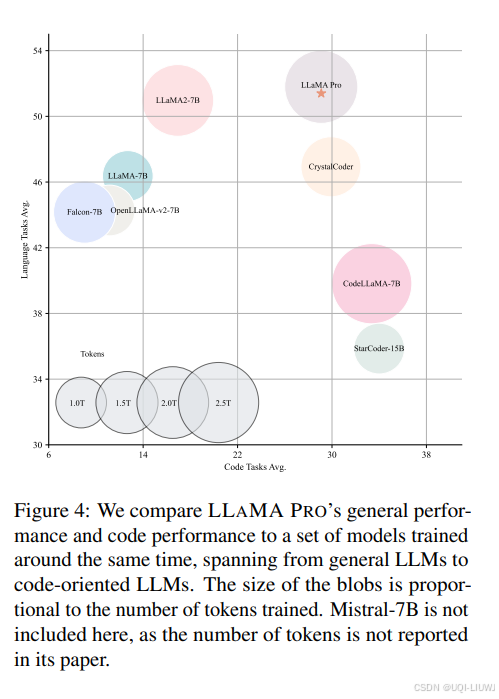
- 在代码和数学语料库上进行实验,得到了LLAMA PRO-8.3B
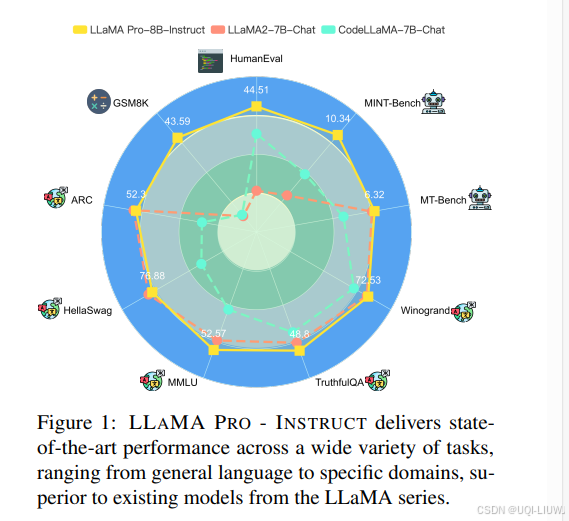
- 初始化自LLaMA2-7B,在一般任务、编程和数学方面表现出色
- LLAMA PRO及其遵循指令的对应模型(LLAMA PRO - INSTRUCT)在各种基准测试中取得了先进的性能
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 论文略读: LLaMA Pro: Progressive LLaMA with Block Expansion

发表评论 取消回复