一、什么是Beautiful Soup库
1、Beautiful Soup库是用来做HTML解析的库
Beautiful Soup把看起来复杂的HTML内容,解析成树状结构,让搜索和修改HTML结构变得更容易
2、第三方库,先安装
终端输入pip install bs4
from bs4 import BeautifulSoup(引入)
3、beautifulsoup和bs4是什么关系
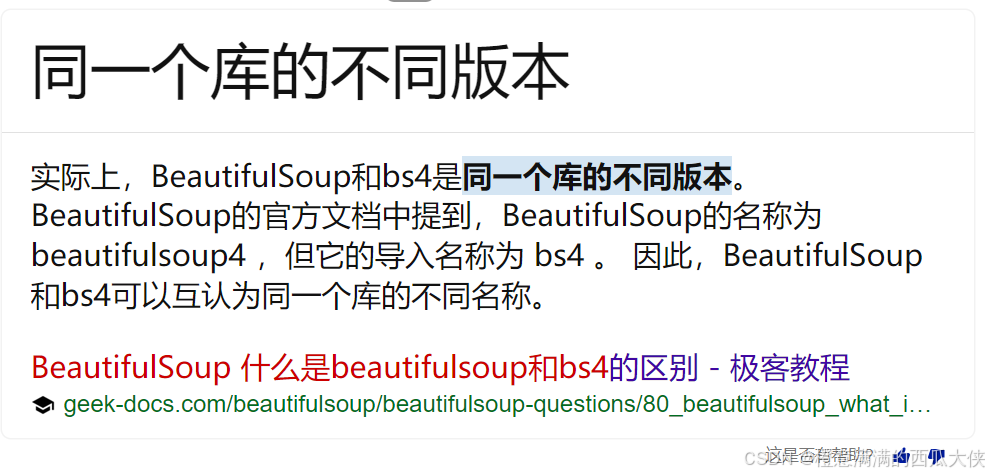
二、储备知识:
from bs4 import BeautifulSoup
import requests
header={"User_Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36"}#注意是字典类型
content=requests.get("http://books.toscrape.com/",headers=header).text#注意是headers,注意网址别写错,可以直接复制粘贴
#把content传入BeautifulSoup的构造函数里
soup=BeautifulSoup(content,"html.parser") #第二个参数指定解析器,即可以解析什么类型的内容
#print(soup.p) #都是打印第一个出现的元素
#print(soup.img)
#浏览器的检查功能
#运用某种方法,找出所有class属性值为“price_color”的p标签
all_prices=soup.findAll("p",attrs={"class":"price_color"})#注意是findAll
#findAll能根据标签、属性等找出所有符合要求的元素,attrs是可选参数(字典类型)
#findAll返回可迭代对象,可以用for循环遍历各个对象
for price in all_prices:
print(price)
#如果不想打印乱七八糟的HTML标签信息,可以选择打印对象的string属性(把标签包围的文字返回给我们)
for price in all_prices:
print(price.string[2:])
#如果只想要纯净的数字,不要前面的货币符号,用一些字符串操作方法也可以实现,比如切片操作
#切片操作: 获得索引值大于等于2的所有剩下字符串
#找书名: 共性->所有书名都是h3元素的子元素->找所有h3元素下的a元素
#1、找到所有h3元素
all_titles=soup.findAll("h3")
#2、找到每个h3元素下的所有a元素
for title in all_titles:
all_links=soup.findAll("a")
#3、提取a元素里的文字
for link in all_links:
print(link.string)
#由于h3里只有一个a元素,可以直接找第一个
for title in all_titles:
link=title.find("a")
print(link.string)三、小试牛刀:
import requests
from bs4 import BeautifulSoup
head={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36"}
#一页只有25部电影,每一页的链接不一样
for start_num in range(0,250,25): #0,25,50...225
response=requests.get(f"https://movie.douban.com/top250?start={start_num}",headers=head)
content=response.text
soup=BeautifulSoup(content,"html.parser")
all_titles=soup.findAll("span",attrs={"class":"title"})
for title in all_titles:
# 原版标题前面有一个斜杠,用if判断
title_string=title.string
if "/" not in title_string:
print(title_string)
注意:
1、在 requests.get 的 URL 中,start=start_num 是一个字符串而不是变量。应该使用字符串格式化方法将 start_num 的值插入 URL 中
2、遇到过的一个bug(因为head写成了字符串,漏了“User-Agent”,应该写字典形式才对):
-
错误信息:
AttributeError: 'str' object has no attribute 'items'这行错误信息告诉我们代码试图调用
.items()方法(返回字典的键值对),而这个方法在字符串对象上是不可用的。由此可以推断,传递给requests.get的headers参数是一个字符串而不是字典。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » python爬虫入门(四)之Beautiful Soup库

发表评论 取消回复