
个人主页:欢迎来到 Papicatch的博客
课设专栏 :学生成绩管理系统
专业知识专栏: 专业知识

文章目录
引言
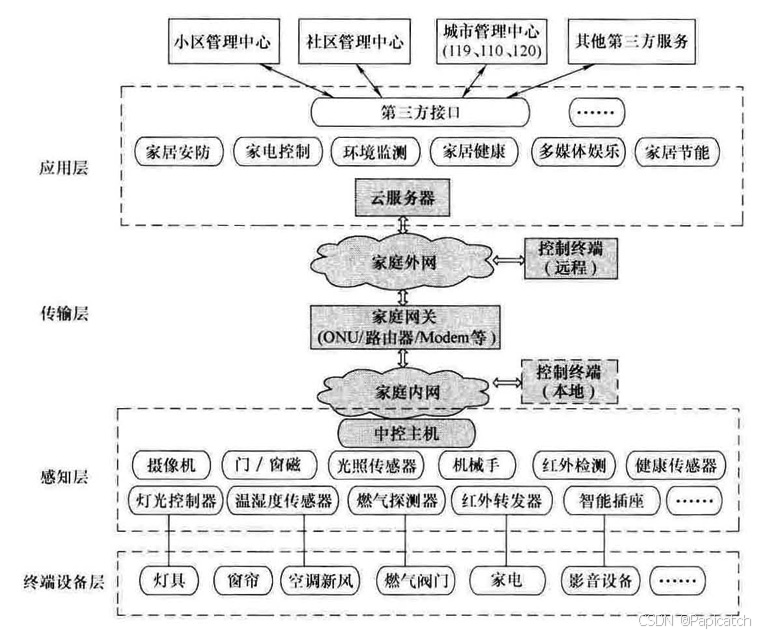
在当今科技飞速发展的时代,人工智能与智能家居的结合正逐渐改变着我们的生活方式。
人工智能使得智能家居具备了更强的学习和适应能力。例如,智能恒温器可以通过学习用户的日常温度偏好和行为模式,自动调整室内温度,以达到节能和舒适的最佳平衡。
基于深度卷积神经网络的表情识别
深度卷积神经网络(DCNN)在表情识别这一复杂任务中展现出了卓越的性能,而 OpenCV 作为一个功能强大且广泛应用的计算机视觉库,为实现基于 DCNN 的表情识别系统提供了坚实的基础和便利的工具。
在开始构建表情识别系统之前,至关重要的一步是精心准备丰富且具有代表性的数据集。这些数据集通常包含了数量众多、涵盖各种不同场景和个体的人脸图像,并且每一张图像都被准确地标注了其所对应的表情类别,常见的表情类别如高兴、悲伤、愤怒、恐惧、惊讶、厌恶以及中性等。
在数据预处理阶段,OpenCV 发挥了关键作用。可以运用 cv2.imread() 函数方便地读取图像文件。为了使输入模型的图像尺寸统一,便于模型处理,会使用 cv2.resize() 函数对图像进行缩放操作。同时,为了消除不同图像之间由于光照、对比度等因素造成的差异,通过 cv2.normalize() 函数对像素值进行归一化处理,将其范围限定在特定的区间内,以提高模型的训练效率和准确性。
构建深度卷积神经网络模型是表情识别的核心部分。可以选择一些知名且性能出色的预训练模型,例如 VGG、ResNet 等。这些预训练模型在大规模图像数据集上进行过训练,已经学习到了通用的图像特征。也可以根据具体需求,自定义设计适合表情识别任务的网络结构。
在训练过程中,为了进一步丰富数据,增加模型的泛化能力,利用 OpenCV 进行数据增强操作。例如,使用 cv2.flip() 函数实现图像的随机水平或垂直翻转,使用 cv2.rotate() 函数进行随机旋转,或者使用 cv2.addNoise() 函数为图像添加适量的噪声。
深度学习框架(如 TensorFlow、PyTorch 等)与 OpenCV 的结合是实现高效训练的关键。在训练过程中,将经过 OpenCV 预处理和增强后的数据集输入到模型中,通过反向传播算法不断调整模型的参数,以最小化预测结果与真实标签之间的误差。
当模型训练完成后,进入测试阶段。再次利用 OpenCV 读取待识别的人脸图像,经过与训练时相同的预处理步骤后,将其输入到训练好的模型中进行预测。模型会输出一个概率分布,表示该图像属于各个表情类别的可能性。
假设我们训练了一个基于 ResNet 的表情识别模型,当使用 OpenCV 读取一张新的人脸图像并进行预处理后,输入到模型中。模型输出的概率分布为 [0.05, 0.85, 0.03, 0.02, 0.03, 0.02] ,分别对应悲伤、高兴、愤怒、恐惧、惊讶和厌恶。由于高兴对应的概率值 0.85 最高,所以可以判断这张图像的表情为高兴。
然而,在实际应用中,还需要面对诸多挑战和需要优化的方面。例如,模型的复杂度可能导致计算资源需求过高,影响实时性,需要进行模型压缩和优化。不同的光照条件、拍摄角度、面部遮挡等因素可能影响识别效果,需要增强模型在这些情况下的鲁棒性。此外,还需要考虑如何将表情识别系统与实际的应用场景进行无缝集成,以实现更有价值的应用。
流程图
模型设计
在设计基于深度卷积神经网络的表情识别模型时,需要综合考虑多个因素以实现准确且高效的表情分类
网络架构选择
可以采用经典的卷积神经网络架构,如 VGGNet、ResNet 或 Inception 系列。以 ResNet 为例,其通过引入残差连接解决了深度网络中的梯度消失问题,使得能够构建更深的网络以学习更复杂的特征。
卷积层设计
卷积层用于提取图像的局部特征。通常,在初始层使用较小的卷积核(如 3x3)来捕捉基本的纹理和形状信息。随着网络深度增加,可以逐渐增加卷积核的大小或数量,以获取更全局和抽象的特征。
池化层
池化层用于减少特征图的空间维度,降低计算量并引入一定的平移不变性。常见的池化方式有最大池化和平均池化。
激活函数
ReLU(Rectified Linear Unit)是常用的激活函数,因其计算简单且能有效避免梯度消失问题。但在某些情况下,如为了处理梯度消失或提高模型的表达能力,也会使用 Leaky ReLU 或 Parametric ReLU 等变体。
全连接层
在网络的末端,通常会连接几个全连接层来将学到的特征映射到表情类别空间。全连接层的神经元数量根据表情类别的数量进行调整。
正则化
为了防止过拟合,可以采用 L1 和 L2 正则化、Dropout 等技术。Dropout 会在训练过程中随机将神经元的输出设置为 0,强制网络学习更具鲁棒性的特征。
模型融合
还可以考虑将多个不同架构或在不同数据集上训练的模型进行融合,以综合它们的优势,提高识别性能。
例如,设计一个简单的表情识别模型,可能包含以下结构:
- 输入层:接收预处理后的人脸图像,例如尺寸为 224x224 的彩色图像。
- 卷积层 1:使用 32 个 3x3 的卷积核,步长为 1,ReLU 激活函数,输出 224x224x32 的特征图。
- 池化层 1:2x2 的最大池化,步长为 2,输出 112x112x32 的特征图。
- 卷积层 2:64 个 3x3 的卷积核,步长为 1,ReLU 激活函数,输出 112x112x64 的特征图。
- 池化层 2:2x2 的最大池化,步长为 2,输出 56x56x64 的特征图。
- .....
- 全连接层 1:512 个神经元,ReLU 激活函数。
- 全连接层 2:输出为表情类别数量(假设 7 种表情),Softmax 激活函数用于最终的分类。
模型设计实现
以下是一个使用 Python 和深度学习框架(如 TensorFlow 或 PyTorch)来实现基于深度卷积神经网络的表情识别模型的基本步骤:
数据准备
- 收集大量带有表情标签的人脸图像数据集。
- 将数据集划分为训练集、验证集和测试集。
导入所需的库
import tensorflow as tf
import numpy as np
import cv2定义模型结构
def create_model():
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(224, 224, 3)),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(128, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(7, activation='softmax') # 假设 7 种表情类别
])
return model数据预处理
def preprocess_image(image_path):
image = cv2.imread(image_path)
image = cv2.resize(image, (224, 224))
image = image / 255.0 # 归一化
return image编译模型
model = create_model()
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['accuracy'])加载数据并进行训练
train_images = []
train_labels = []
for image_path, label in training_data:
image = preprocess_image(image_path)
train_images.append(image)
train_labels.append(label)
train_images = np.array(train_images)
train_labels = np.array(train_labels)
model.fit(train_images, train_labels, epochs=10, batch_size=32, validation_split=0.1)在测试集上进行评估
test_images = []
test_labels = []
for image_path, label in test_data:
image = preprocess_image(image_path)
test_images.append(image)
test_labels.append(label)
test_images = np.array(test_images)
test_labels = np.array(test_labels)
loss, accuracy = model.evaluate(test_images, test_labels)进行表情预测
new_image_path = 'new_image.jpg'
new_image = preprocess_image(new_image_path)
prediction = model.predict(np.expand_dims(new_image, axis=0))
predicted_label = np.argmax(prediction)模型推理
模型推理是将训练好的表情识别模型应用于新的未知数据以进行表情预测的过程。
首先,需要确保已经完成了模型的训练,并保存了训练好的模型参数。在实际推理时,加载这些保存的模型参数。
对于输入的新图像,同样需要进行与训练数据相同的预处理步骤。这可能包括图像的读取、裁剪、调整大小、归一化等操作,以确保输入数据的格式和范围与训练时一致。
将预处理后的图像数据输入到加载的模型中。模型会根据其学习到的特征和模式,计算出每个表情类别的概率分布。
例如,假设我们的模型预测结果是一个包含 7 个元素的概率数组 [0.1, 0.2, 0.05, 0.3, 0.15, 0.1, 0.1] ,分别对应 7 种表情类别(高兴、悲伤、愤怒、恐惧、惊讶、厌恶、中性)。
为了确定最终的表情预测类别,通常会选择概率最大的类别作为输出结果。在上述例子中,概率最大的是第四个元素 0.3 ,对应的表情类别可能是恐惧,那么就预测该图像的表情为恐惧。
为了提高推理的效率和准确性,还可以采用一些优化技术,如模型量化、剪枝等,以减少模型的计算量和参数数量,同时不显著降低性能。
此外,在实际应用中,可能需要对连续的图像帧进行推理,以获取更准确和稳定的表情识别结果。可以通过对多个帧的预测结果进行平滑处理或采用基于时间序列的分析方法来实现。
例如,在视频流的表情识别中,可以设置一个时间窗口,对窗口内的帧进行综合分析,而不是仅仅依赖于单个帧的预测结果。
氛围灯控制
照明技术
- 发光二极管(LED):是氛围灯最常用的光源。其具有高效、节能、寿命长、颜色多样等优点。不同类型的 LED 如 RGB LED 或 RGBW LED 能够提供更丰富的色彩组合。
- 光学设计:包括透镜、反射器等的设计,用于控制灯光的发散角度、均匀度和亮度分布,以达到理想的照明效果。
通信技术
- 蓝牙:常用于短距离无线控制,例如通过手机与氛围灯进行连接和控制。
- Wi-Fi:提供更稳定和高速的数据传输,适用于大规模的氛围灯系统或需要与其他智能设备集成的场景。
- Zigbee:一种低功耗、短距离的无线通信技术,适合构建大规模的传感器和控制网络。
传感器技术
- 环境光传感器:用于检测周围环境的光线强度,从而自动调整氛围灯的亮度,以保持舒适的视觉效果。
- 人体传感器:可以感知人的存在和活动,实现当有人进入房间时自动开启氛围灯,或者根据人的位置调整灯光的照射方向。
控制算法
- 颜色混合算法:对于 RGB 类型的氛围灯,需要精确的颜色混合算法来实现准确的色彩输出。
- 亮度调节算法:确保在调节亮度时,灯光的颜色和均匀度不受影响。
- 场景模式算法:根据不同的预设场景(如阅读、聚会、睡眠等),自动配置灯光的颜色、亮度和变化模式。
智能控制技术
- 语音控制:通过语音识别技术,用户可以通过语音指令来控制氛围灯的开关、颜色和模式等。
- 自动化控制:结合时间、天气、室内温度等因素,实现氛围灯的自动控制。例如,在夜晚自动开启柔和的灯光,在寒冷的天气中使用暖色调灯光。
电源管理技术
- 高效的电源转换:确保将输入电源有效地转换为适合 LED 工作的电压和电流,提高能源利用效率。
- 电源稳定性:提供稳定的电源输出,防止电压波动对灯光效果产生影响。
软件和用户界面
- 移动应用程序:提供直观、友好的用户界面,方便用户进行各种控制操作和场景设置。
- 云服务:支持远程控制、数据存储和设备管理,实现多设备的统一控制和个性化配置。
例如,在一个智能家居的氛围灯系统中,通过 Wi-Fi 连接到家庭网络,利用环境光传感器自动根据室内光线调整亮度,用户可以通过手机应用选择不同的颜色和场景模式,同时系统还支持语音控制,如“打开阅读模式的灯光”。电源管理模块保证了灯光的稳定工作和节能效果。
开发流程图
人脸表情识别模型推理功能插件构建
构建人脸表情识别模型推理功能插件需要以下关键步骤:
模型选择与训练
- 选择适合的深度卷积神经网络架构,如 ResNet、VGG 等,并在大规模的人脸表情数据集上进行训练。
- 确保模型能够准确地识别多种常见的表情类别。
模型转换与优化
- 将训练好的模型转换为适合在插件中使用的格式,例如 TensorFlow Lite 格式,以减少模型大小和提高推理速度。
- 进行模型量化、剪枝等优化操作,降低计算量和内存占用。
接口设计
- 定义清晰的输入和输出接口。输入通常是预处理后的人脸图像数据,输出是表情类别的预测结果。
- 设计友好的 API,以便其他应用程序能够方便地调用插件。
数据预处理
- 在插件中实现图像的读取、裁剪、尺寸调整、归一化等预处理操作,确保输入数据符合模型的要求。
推理引擎集成
- 选择高效的推理引擎,如 TensorFlow Lite 推理引擎或 ONNX Runtime 等,并将其集成到插件中。
错误处理与异常情况
- 设计完善的错误处理机制,处理输入数据异常、模型加载失败、推理过程中的错误等情况。
性能优化
- 利用多线程、并行计算等技术提高推理效率。
- 对内存使用进行优化,避免内存泄漏。
测试与验证
- 使用大量的测试数据对插件进行准确性和性能测试。
- 与其他已有的表情识别方法进行对比,验证插件的优越性。
例如,假设我们构建了一个基于 TensorFlow Lite 的人脸表情识别插件。在输入一张人脸图像后,插件首先读取图像并进行预处理,然后通过 TensorFlow Lite 推理引擎进行计算,最终输出表情类别为“高兴”的预测结果。在整个过程中,如果出现图像格式错误或模型加载异常,插件会返回相应的错误代码和提示信息。
系统开放插件
人脸图像获取插件实现
实现人脸图像获取插件通常涉及以下关键步骤和技术
摄像头访问与控制
- 使用相关的库和 API 来访问计算机或移动设备的摄像头。例如,在 Windows 平台上可以使用 DirectShow 库,在 Android 上可以使用 Camera2 API 等。
- 实现对摄像头参数的设置,如分辨率、帧率、对焦模式等,以满足不同的需求。
图像采集
- 按照设定的参数从摄像头实时获取图像帧。
- 可以选择采集单帧图像或连续的视频流。
人脸检测
- 集成人脸检测算法或使用现有的人脸检测库,如 OpenCV 中的人脸检测模块。
- 在获取的图像中检测并定位人脸区域。
图像裁剪与调整
- 基于人脸检测的结果,裁剪出只包含人脸的图像区域。
- 对裁剪后的人脸图像进行大小调整、旋转校正等操作,以确保图像的一致性和规范性。
图像质量优化
- 进行图像去噪、增强对比度等处理,提高图像质量。
数据格式转换
- 将获取和处理后的图像数据转换为适合后续处理或传输的格式,如 JPEG、PNG 或 RAW 格式。
实时性与性能优化
- 采用缓冲机制和多线程技术,确保图像获取的实时性,避免卡顿和延迟。
- 对图像处理算法进行优化,减少计算量和内存占用。
跨平台支持
- 确保插件能够在多种操作系统(如 Windows、Mac OS、Linux、Android、iOS 等)上运行,并提供一致的接口和功能。
代码实现
以下是一个使用 Python 和 OpenCV 库实现简单人脸图像获取插件的示例代码:
import cv2
def get_face_image():
# 打开摄像头
cap = cv2.VideoCapture(0)
if not cap.isOpened():
print("无法打开摄像头")
return
# 加载人脸检测模型
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
while True:
# 读取一帧图像
ret, frame = cap.read()
if not ret:
print("无法获取图像")
break
# 转换为灰度图像,便于人脸检测
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 进行人脸检测
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
for (x, y, w, h) in faces:
# 裁剪出人脸区域
face_image = frame[y:y + h, x:x + w]
# 调整人脸图像大小
face_image_resized = cv2.resize(face_image, (200, 200))
# 显示人脸图像
cv2.imshow('Face Image', face_image_resized)
# 按 'q' 键退出
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放摄像头资源
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
get_face_image() 这段代码首先打开摄像头,加载人脸检测模型,然后在每一帧图像中检测人脸,裁剪并调整人脸图像大小进行显示。用户按下 q 键可退出程序。
人脸图像识别模型推理实现
以下是一个使用 TensorFlow 和 OpenCV 实现简单人脸图像识别模型推理的示例代码。这里假设已经有训练好的模型并保存为 model.h5 文件。
import tensorflow as tf
import cv2
import numpy as np
def recognize_face(image_path):
# 加载模型
model = tf.keras.models.load_model('model.h5')
# 读取图像
image = cv2.imread(image_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = cv2.resize(image, (224, 224)) # 根据模型输入要求调整大小
# 归一化
image = image / 255.0
image = np.expand_dims(image, axis=0)
# 推理
predictions = model.predict(image)
predicted_class = np.argmax(predictions)
# 假设类别标签为 0: 高兴, 1: 悲伤, 2: 愤怒 等
classes = ['高兴', '悲伤', '愤怒', '其他']
print(f'预测的表情是: {classes[predicted_class]}')
if __name__ == "__main__":
recognize_face('test_image.jpg')可视化交互界面插件实现
以下是一个使用 Python 的 Tkinter 库来创建简单可视化交互界面插件的示例代码:
from tkinter import Tk, Label, Button, Entry
def on_button_click():
input_text = entry.get()
label.config(text=f"您输入的是: {input_text}")
root = Tk()
# 标签
label = Label(root, text="这是一个示例界面")
label.pack()
# 输入框
entry = Entry(root)
entry.pack()
# 按钮
button = Button(root, text="点击我", command=on_button_click)
button.pack()
root.mainloop()在上述代码中,我们创建了一个窗口,包含一个标签用于显示提示信息,一个输入框用于用户输入,以及一个按钮。当点击按钮时,会获取输入框中的内容,并更新标签的显示内容。
总结
总的来说,人工智能为智能家居带来了巨大的潜力和机遇,将为我们创造更加便捷、舒适和安全的家居环境。但同时,我们也需要关注并解决相关的问题,确保其健康、可持续的发展。

本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【人工智能】-- 智能家居

发表评论 取消回复