pycharm部分好用快捷键

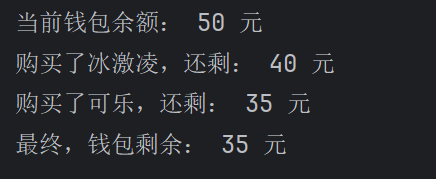
变量名的定义
与之前学习过的语言有所不同的是,python中变量名的定义更加的简洁
such as
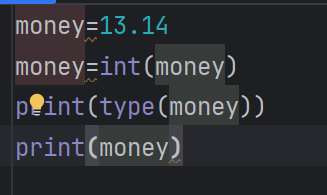
整形。浮点型和字符串的定义
money=50
haha=13.14
gaga="hello"
字符串的定义依然是需要加上引号,也不需要写;了
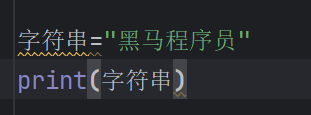
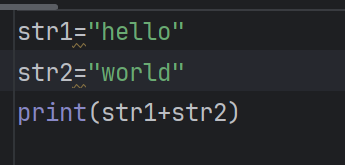
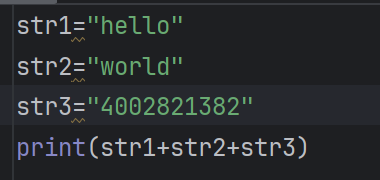
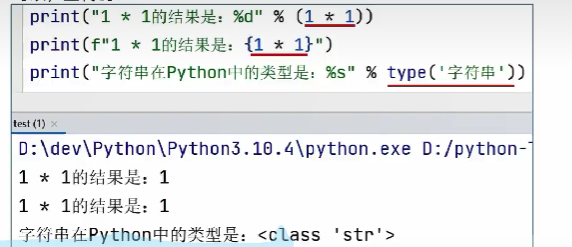
字符串拼接
在print输出时使用“,”进行连接

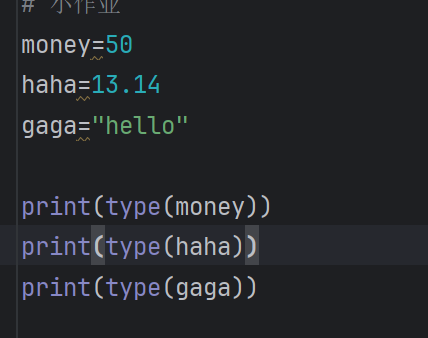
type的使用方式
可以查看数据类型
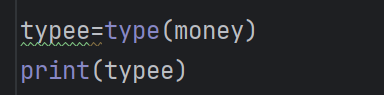
也可以三方中转
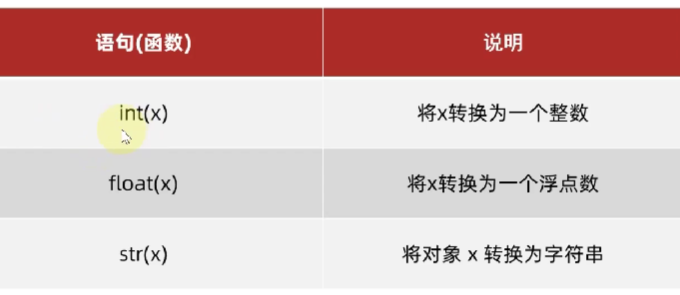
数据类型转换
转换成字符串可能比较方便,但是float转换成int可能会损失精度
标识符命名规则
真好可以用中文
其他没啥要注意的,和其他语言一样
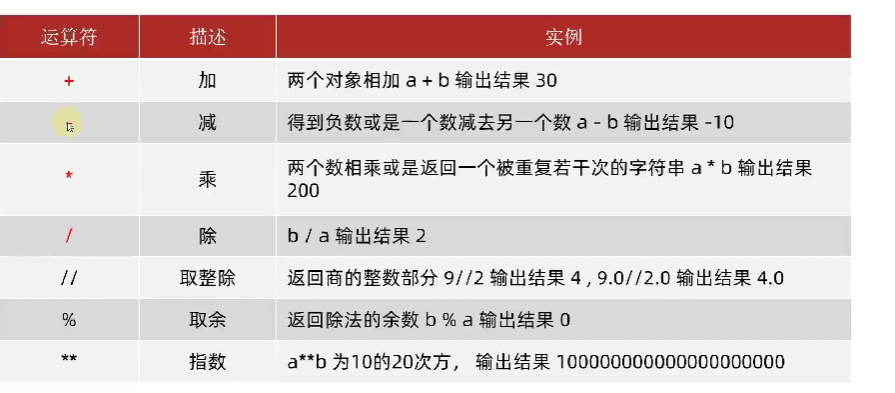
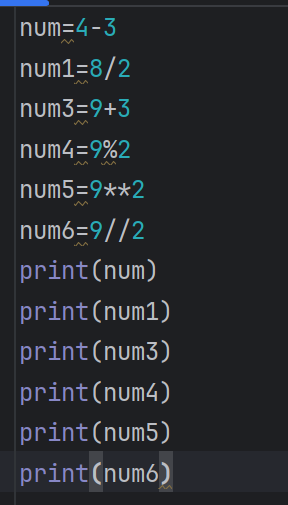
基本运算符
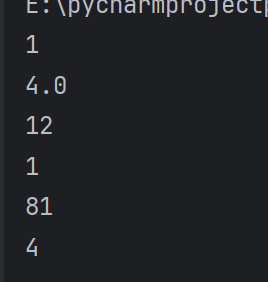
ps:从来没见过这么省事的编辑器,他居然会猜你想写什么就给你写好。它真的我哭死
字符串的多种定义方式
感觉python有一种独特的疯感,freedom!

字符串拼接
ps字符串之间才可以拼接
数字的话需要定义的时候是字符串类型
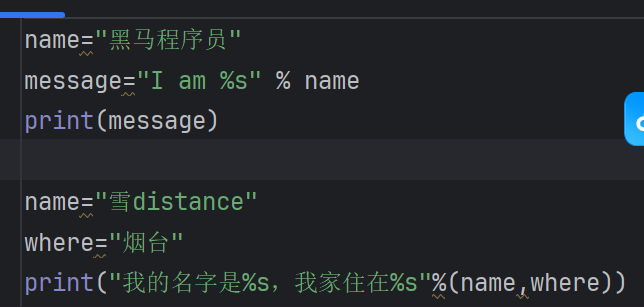
字符串格式化
name="黑马程序员"
message="I am %s" % name
print(message)
这里必须是%和s,表示字符串站位
假如有很多个字符串的话

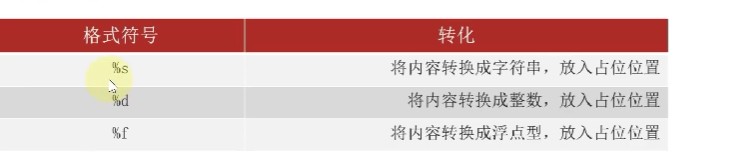
name="雪distance"
where="烟台"
age=21
xiaoshu=13.14
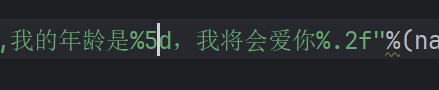
print("我的名字是%s,我家住在%s,我的年龄是%d,我将会爱你%f"%(name,where,age,xiaoshu))

数字精度设置
不够的会在前面补上空格,小数就可以约束后面的位数



快速字符串格式化
print(f"我的名字是{name},我家住在{where},我的年龄是{age},我将会爱你{xiaoshu}")
课后练习

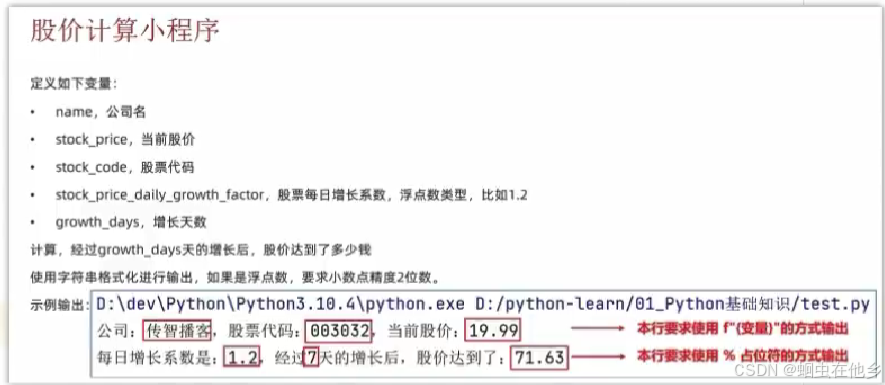
name="传智播客"
stock_code="003032"
stock_price=19.99
yinzi=1.2
growth=7
finalprice=stock_price*yinzi**growth
print(f"公司{name},股票代码{stock_code},当前股价{stock_price}")
print("每日增长系数是:%.1f,经过%d天增长后,股价达到了:%.2f"%(yinzi,growth,finalprice))
上面的修改一下股票价格不需要加上引号
这里一个很智障的问题,没搞明白数学公式咋写

input的用法
print("告诉我你是谁")
name=input()
age=input()
print(f"{name}")
print("我知道了你是%s,年龄是%s" % (name,age))
input接受的是字符串形式的数据,故上面是%s,尝试了一下%d会报错
所以需要强制类型转换

name=input("please tell me who are you")
name=int(name)
print(type(name))
小练习



user_name = input()
user_type=input()
print("您好:%s,您是尊贵的:%s用户,欢迎您光临。" % (user_name, user_type))

真假判断
bool_1=True
bool_2=False
print(f"bool_1的内容是{bool_1},类型是{type(bool_1)}")
num1=10
num2=20
print(f"the final is {num1>=num2}")
需要注意的是,这里的True和False必须首字母大写

if判断语句
age=30
if age<=18:
print("you are a kid")
python中没有大括号的限制了,所以主要就是看前面缩进,别忘了加冒号
小练习

print("欢迎来到黑马儿童游乐场,儿童免费,成人收费")
age=input("请输入你的年龄")
age=int(age)
if age >= 18:
print("您已成年,游玩需要补票10元。")
print("祝您游玩愉快")

if-else语句
if和else都需要加:

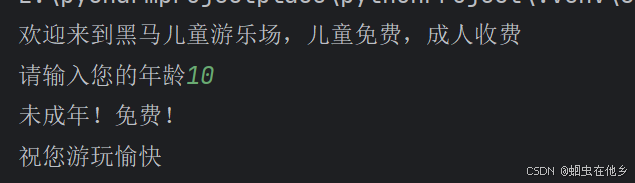
print("欢迎来到黑马儿童游乐场,儿童免费,成人收费")
age=int(input("请输入您的年龄"))
if age >= 18:
print("您已成年,游玩需要补票10元。")
else:
print("未成年!免费!")
print("祝您游玩愉快")
小练习

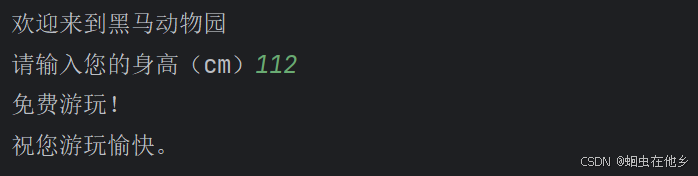
print("欢迎来到黑马动物园")
age=int(input("请输入您的身高(cm)"))
if age >= 120:
print("您的身高超出120cm,游玩需要补票10元。")
else:
print("免费游玩!")
print("祝您游玩愉快。")
if-else多条件判断
elseif写成elif了非常摆烂
if-elif-else
小练习
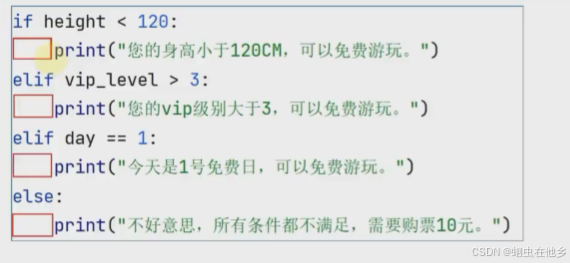

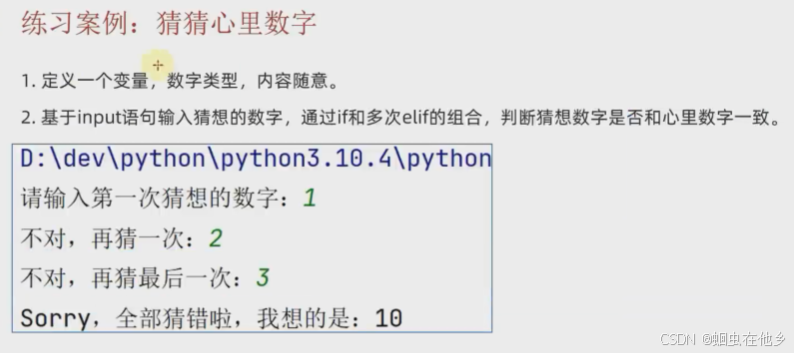
num=4
num1=int(input("请输入第一次猜想的数字"))
if num1==num:
print("猜对啦")
elif int(input("猜错了在猜一次"))==num:
print("猜对啦")
elif int(input("猜错了,在猜最后一次"))==num:
print("猜对了")
else:
print("Sorry,猜错了,我猜想的数字是%d" % num)
ps猜数字小游戏

# 猜数字小游戏
num=4
while True:
num1 = int(input("请输入一个数字"))
if num1==num:
print("你猜对啦")
break
elif num1>num:
print("你猜的数偏大了")
else:
print("你猜的数偏小了")
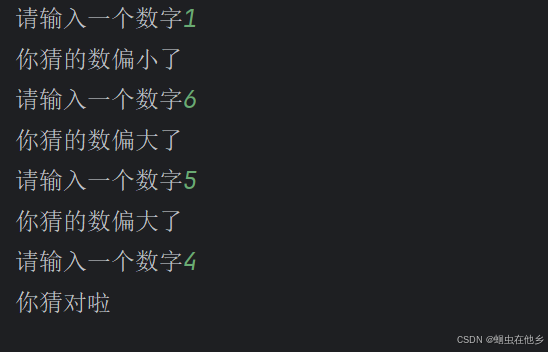
嵌套判断语句
if int(input("你的身高是多少cm"))>120:
print("不免费")
print("但是VIP等级大于3,可以免费,请输入VIP等级")
if int(input("你的VIP级别是多少"))>3:
print("免费!")
else:
print("不免费啦")
else:
print("欢迎小朋友游玩")
这种只要题干里面描述清楚一般没得问题

little练习

age=int(input("Enter your age:"))
time=int(input("Enter your enter time:"))
level=int(input("Enter your enter level:"))
if age>=18 and age<30:
if time>2 or level>3:
print("可以领取嗷")
else:
print("不能领取嗷")
else:
print("不能领取嗷")
到是也能实现,但是和老师希望的可能不太一样(老师希望可能一步一判断),顺便python的并且和或者竟然改成and和or了真好哇!
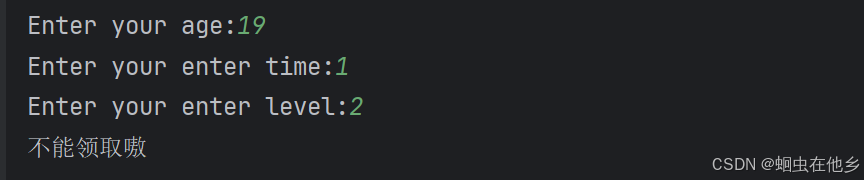
老师写的代码:
age=int(input("Enter your age:"))
time=int(input("Enter your enter time:"))
level=int(input("Enter your enter level:"))
if age>=18:
print("你是成年人")
if age<30:
print("你的年龄达标")
if time>2:
print("你的入职时间达标")
elif level>3:
print("你的级别达标")
else:
print("入职时间或者级别不达标不能领取")
else:
print("你的年龄太大了嗷,不能领取")
else:
print("未成年,不能领取嗷")
每一个if记得对应一个else
实战训练
代码如下所示

import random
num=random.randint(1,10)
num1=int(input("请输入数字"))
if num1==num:
print("bingo")
elif num1>num:
print("too big")
num1=int(input("请第二次输入数字"))
if num1>num:
print("too big")
num1=int(input("请第三次输入数字"))
if num1>num:
print("too big the num is %d"%num)
elif num1<num:
print("too small the num is %d"%num)
else:
print("bingo")
elif num1<num:
print("too small")
num1 = int(input("请第三次输入数字"))
if num1 > num:
print("too big the num is %d"%num)
elif num1 < num:
print("too small the num is %d"%num)
else:
print("bingo")
else:
print("bingo")
else:
print("too small")
num1 = int(input("请第二次输入数字"))
if num1 > num:
print("too big")
num1 = int(input("请第三次输入数字"))
if num1 > num:
print("too big the num is %d"%num)
elif num1 < num:
print("too small the num is %d"%num)
else:
print("bingo")
elif num1 < num:
print("too small")
num1 = int(input("请第三次输入数字"))
if num1 > num:
print("too big the num is %d"%num)
elif num1 < num:
print("too small the num is %d"%num)
else:
print("bingo")
else:
print("bingo")
感觉是非常费劲的计算方式,假如使用上面的while循环或者for循环会比较简单,这个就用来锻炼逻辑
ps:三次猜数太难猜了,私心偷偷加了最后一次再猜不中就把数告诉我就完了,玩不过人工智能

while循环
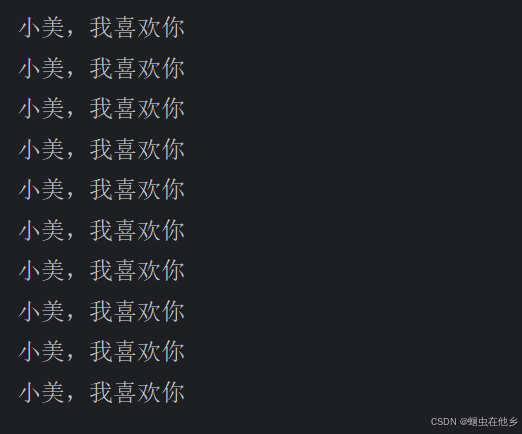
假如表白100次就能成功!
n=10
while n>0:
print("小美,我喜欢你")
n-=1
怕给我电脑烧了,表白10次意思意思吧
little作业

n=1
sum1=0
while n<=100:
sum1+=n
n+=1
# print(n)
# print(sum1)
print(sum1)
这里出现101不重要,重要的是n=1和n=100之间就是100个数,假如从0开始,那么就要<100了

while循环猜数案例
带生成随机数版循环猜数案例
import random
num=random.randint(1,100)
while True:
num1=int(input("请输入数字"))
if num1==num:
print("you are right")
break
elif num1>num:
print("too big")
else:
print("too small")
哈哈,也是猜了好多遍
老师没有用break,使用的是修改flag,顺便还记录了一下你猜了多少次
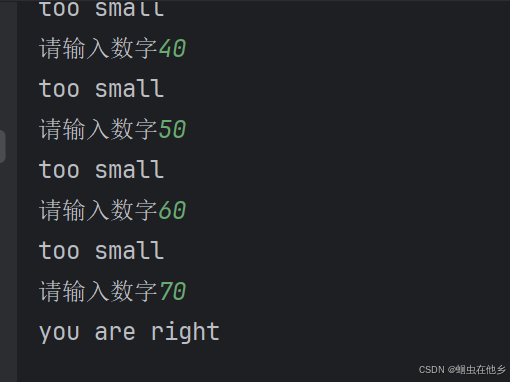
import random
num=random.randint(1,100)
count=0
flag=True
while flag:
count+=1
num1=int(input("请输入数字"))
if num1==num:
print("you are right")
flag=False
elif num1>num:
print("too big")
else:
print("too small")
print(f"你一共猜了{count}次")

while嵌套循环

让print语句输出不换行

制表符\t
这个对于中文可能有点问题,用英文是没有问题的

print("hello\tworld")
print("你好\tlihua")
print("itheima\tbest")
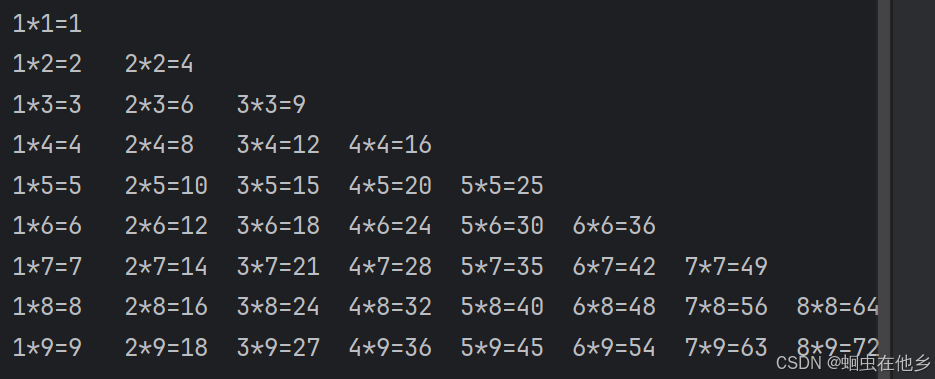
小练习
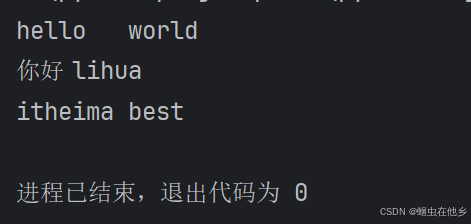

n=1
while n<=9:
m=1
while m<=n:
print(f"{m}*{n}={m*n}\t",end='')
m+=1
n+=1
print()
for循环

利用for循环遍历字符串
name="hhagegege"
for x in name:
print(x,end='')
小练习



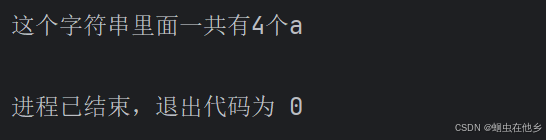
count=0
for x in "itheima is a brand of itcast":
if x=="a":
count+=1
print(f"这个字符串里面一共有{count}个a")
暂时没有区分大小写
count=0
for x in "itheima is a brand of itcastAAA":
if x=="a" or x=="A":
count+=1
print(f"这个字符串里面一共有{count}个a")
这是区分大小写的

for循环range语句
range里面一个数:到这个数有多少个
range两个数:这两个数字之前的所有数,不包含右端,包含左端
range三个数:左端,右端-1,加步长
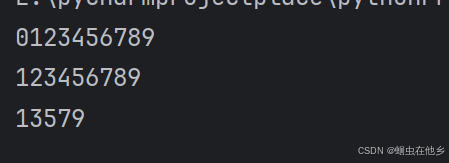
上面三种语法代码:


# 语法一
for x in range(10):
print(x,end='')
print()
# 语法二
for x in range(1,10):
print(x,end='')
print()
# 语法三
for x in range(1,10,2):
print(x,end='')
print()
这种就是类似其他语言的for循环,也是实现执行几遍的功能
small练习
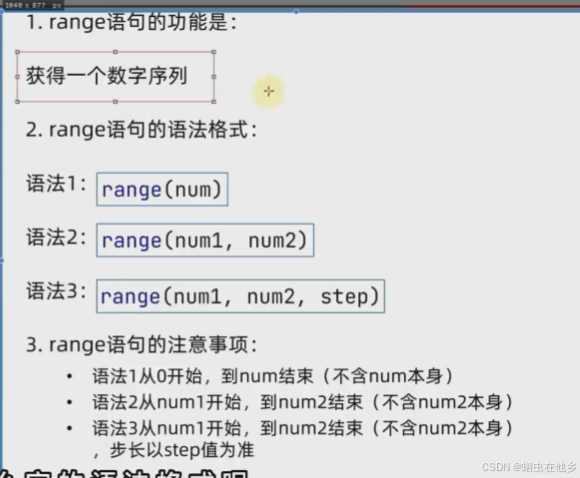
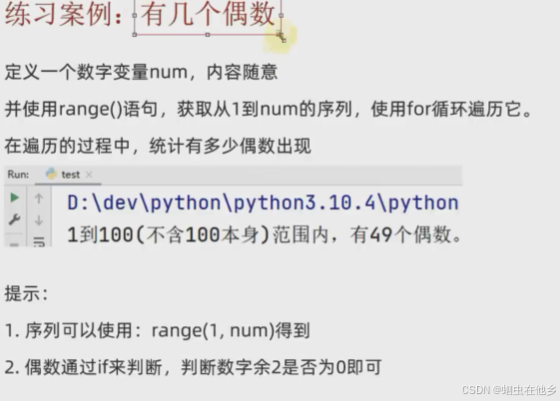
num=int(input("Enter a number:"))
count=0
for x in range(1,num):
if x%2==0:
count+=1
print(f"1到{num}(不含100本身)有{count}个偶数")
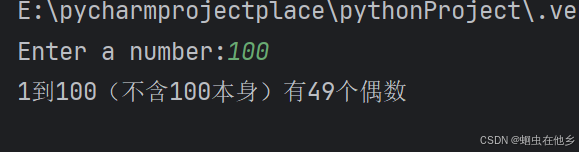
for循环变量作用域
也就是我们之前学习的局部变量和全局变量
for i in range(5):
print(i)
print(i)
这里实际上pycharm没有和你计较,最好还是用比较规范的版本,进行全局定义
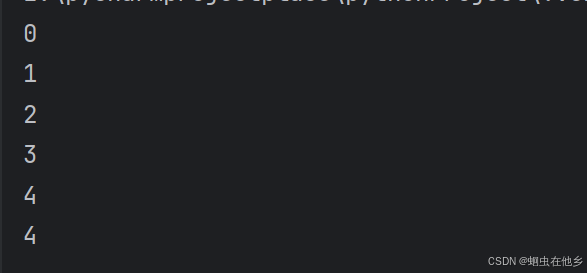

for循环的嵌套使用
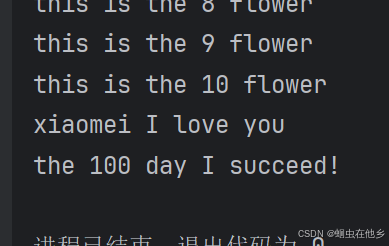
想小美表白案例,一共一百天,每天10朵玫瑰

for i in range(1,101):
print(f"the {i} day")
for j in range(1,11):
print(f"this is the {j} flower")
print("xiaomei I love you")
print(f"the {i} day I succeed!")
我们之前使用while循环时,我们最后第几天是i先++了,然后while判断不执行,我们在输出时还需要i-1现在for循环则是不管右端点的101,因此我们此时不需要进行i–的操作
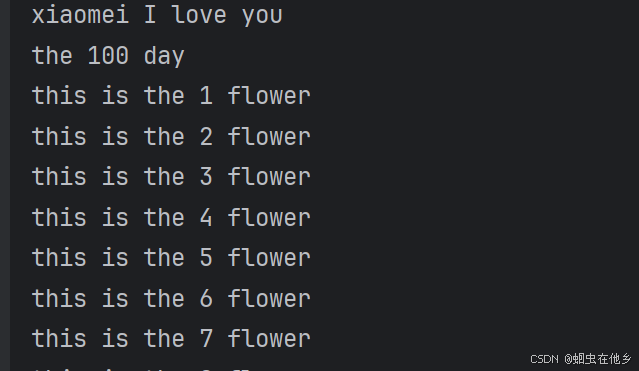
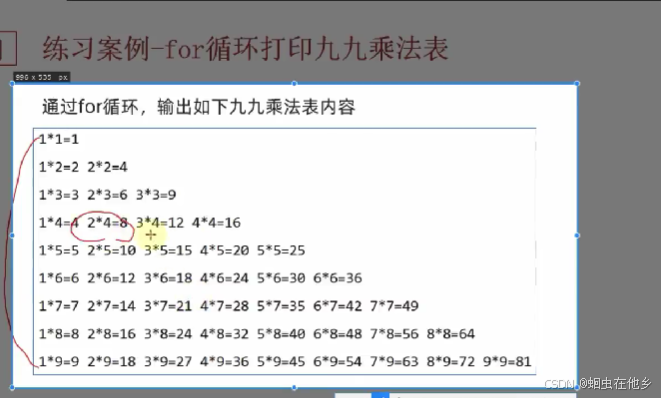
练习for循环打印九九乘法表
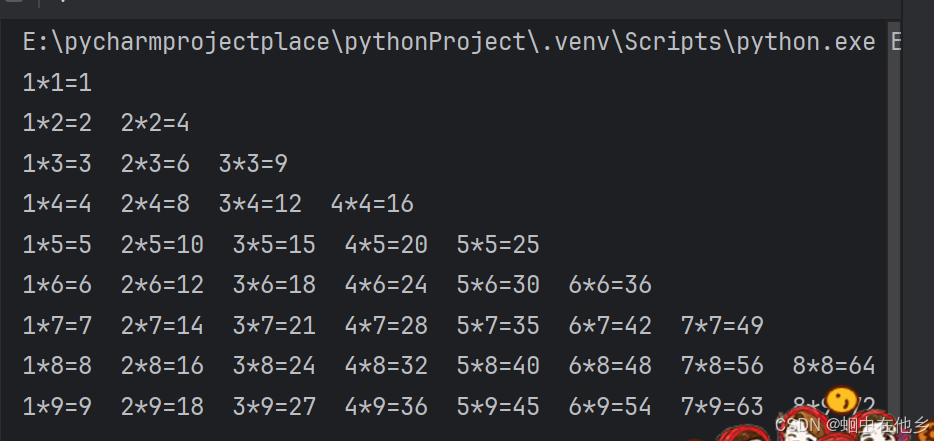
for i in range(1,10):
j=1
for j in range(1,i+1):
print(f"{j}*{i}={i*j} ",end='')
j=j+1
print("\t")
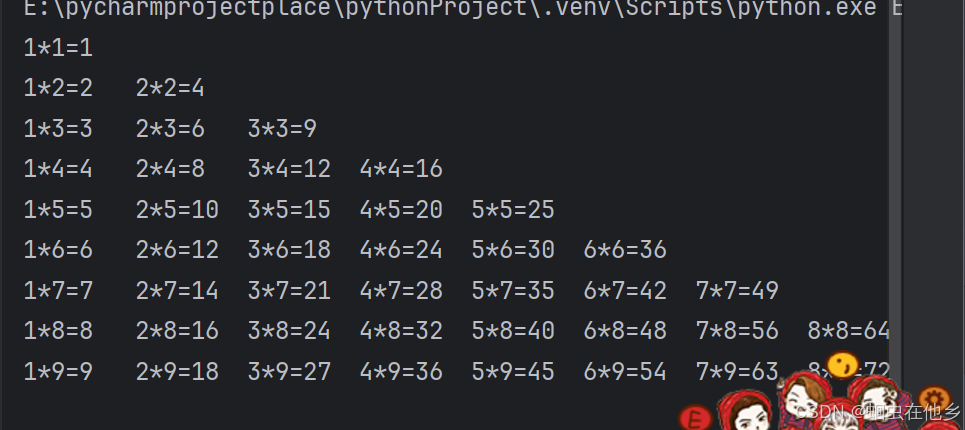
下面老师写的
for i in range(1,10):
j=1
for j in range(1,i+1):
print(f"{j}*{i}={i*j}\t",end='')
j=j+1
print()
可以看出在间断方面做得更加完美
continue和break的使用
continue:暂时跳过这一次(程序读到continue就结束本次循环,直接到下一次)
break:结束循环,整个循环都结束
永远不会执行语句2


永远不会执行语句3,但是其他的都会被执行,这里注意一下语句4跟的谁
假如上面这个没有break


for i in range(1,10):
print("1")
for j in range(1,10):
print("2",end='')
# break
print("3",end='')
print("4")
是这样
循环综合案例

import random
num=random.randint(1,100)
money=10000
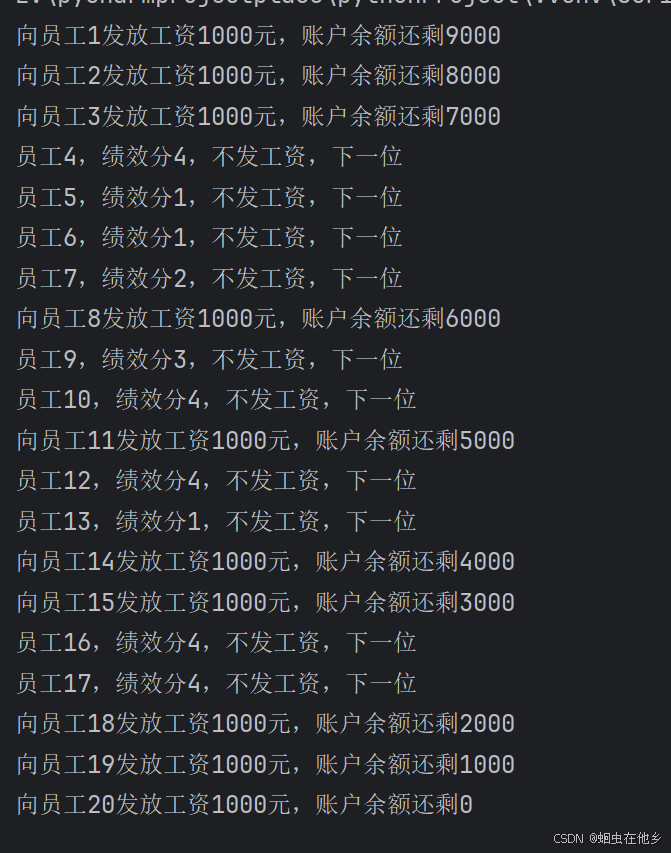
for i in range(1,21):
level=random.randint(1,10)
if level>=5:
if money>=1000:
money=money-1000
print(f"向员工{i}发放工资1000元,账户余额还剩{money}")
else:
print("工资发完了,下个月领取把")
break
else:
print(f"员工{i},绩效分{level},不发工资,下一位")
continue和break还是非常重要的
函数
提前写好方便直接使用


str1="hahsdwibcwidb"
str2="hfbiurwb"
str3="cnefbvu"
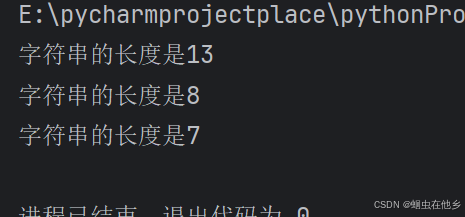
def mylen(str):
count = 0
for i in str:
count += 1
print(f"字符串的长度是{count}")
length1=mylen(str1)
length2=mylen(str2)
length3=mylen(str3)
eg:统计字符串长度的函数,实际上python已经提供了一个方法len()方法,也可直接调用
函数定义
简单小函数
def sayhi():
print("hi")
sayhi()

非常的人性!
我们调用要严格的遵循,调用在定义后面
小练习

def welcome():
print("欢迎来到黑马程序员")
print("请出示您的72小时核酸检测证明")
welcome()
老师写的,差点忘记我们的老朋友\n

def welcome():
print("欢迎来到黑马程序员\n请出示您的72小时核酸检测证明")
# print("")
welcome()
函数的传入参数
一个加法小函数
def add(a,b):
result=a+b
print(f"{a}和{b}相加的结果是{result}")
add(1,2)


函数的传入参数案例
def check(tem):
if tem<=37.5:
print(f"balabala……您是{tem}体温正常,请进!")
else:
print(f"balabala……您是{tem}体温异常,隔离去吧")
check(36)
check(40)
函数返回值
我们假如使用return进行传递返回值的时候,需要拿一个变量来接
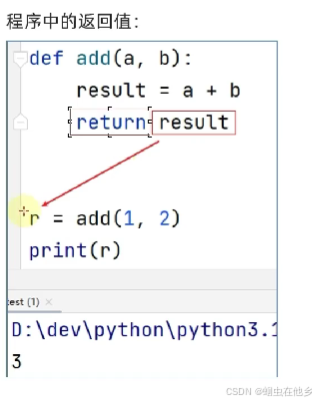

def add(a,b):
return a+b
result=add(1,2)
print(result)
有返回值,只不过这里的返回值是None


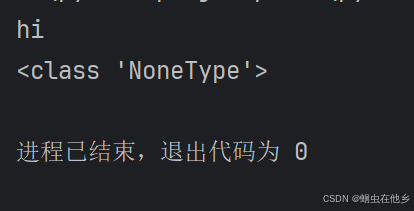
def sayhi():
print("hi")
result=sayhi()
print(type(result))

def check(age):
if age > 18:
return "success"
else:
return None
result = check(18)
if not result:
print("未成年禁止进入")
None=False
这里修改为True和False也是可以的,因为这样返回类型就不为空了,就是返回的布尔类型
函数的说明文档
主要就是在函数体前面记得备注,详细一点,让自己和他人都能看懂



函数的嵌套调用

def funb():
print("funb")
def funa():
print("funa")
funb()
print("func")
funa()
这个也是调用的函数需要提前定义完毕


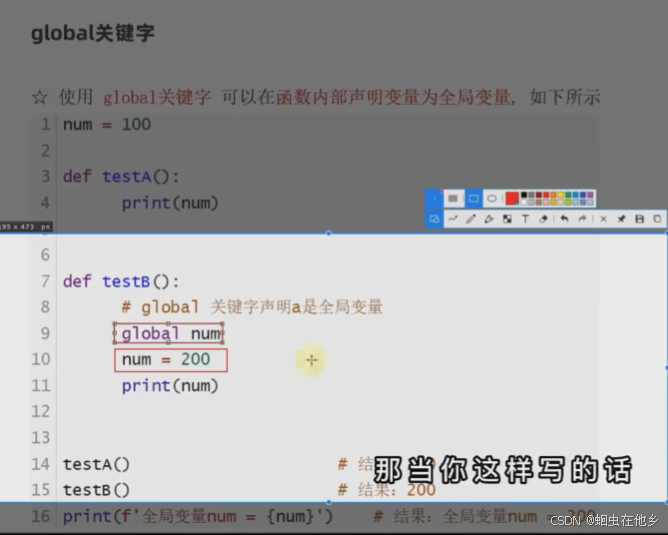
变量在函数中的作用域
出了函数体在外面没法用
全局变量在函数内外都是可以使用的
正常在函数里面修改全局变量的值是没门的,但是在函数里面print一下能发现被修改了
引入global
在函数里面定义一下就是全局变量了



函数综合案例
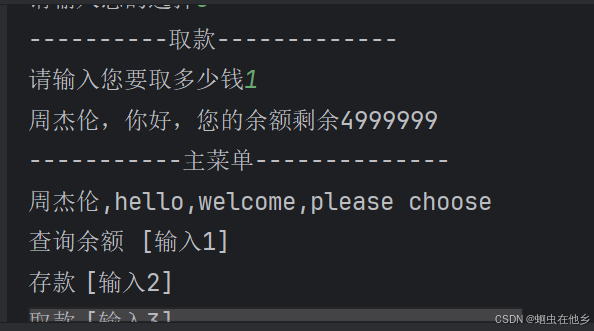
自个写的感觉挺全面的
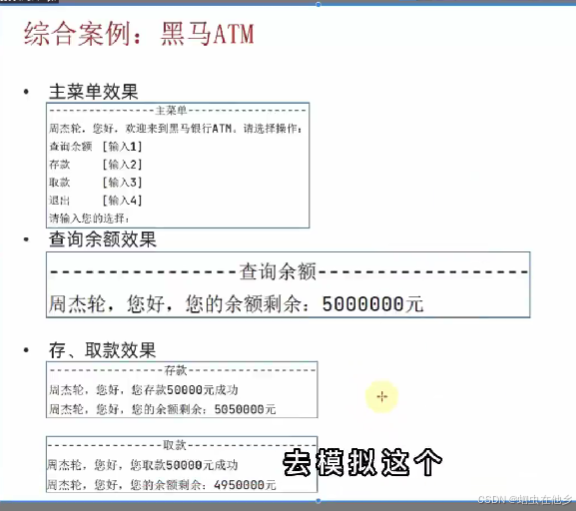
money=5000000
name=input("Enter your name: ")
def check():
print("----------查询余额-------------")
print(f"{name},你好,您的余额剩余{money}")
def cunkuan():
print("----------存款-------------")
money1=int(input("请输入您要存多少钱"))
print(f"{name},你好,您的余额剩余{money+money1}")
def qukuan():
print("----------取款-------------")
money1 = int(input("请输入您要取多少钱"))
print(f"{name},你好,您的余额剩余{money - money1}")
while(True):
print("-----------主菜单--------------")
print(f"{name},hello,welcome,please choose")
print("查询余额\t[输入1]\t")
print("存款\t[输入2]\t")
print("取款\t[输入3]\t")
print("退出\t[输入4]\t")
choose=int(input("请输入您的选择"))
if choose==1:
check()
elif choose==2:
cunkuan()
elif choose==3:
qukuan()
else:
print("您已成功退出")
break
唯一注意一下,这里的处理,对齐展示,一个不行那就多加几个
ps老师原视频指路,想看老师写的代码可以看
视频链接P61

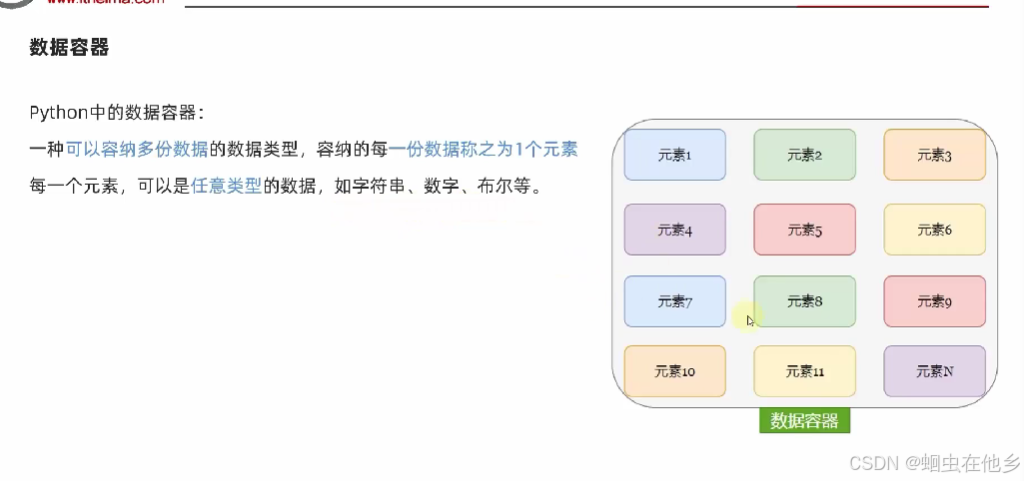
数据容器
但是猜测都是一个数据元素都是同类的里面

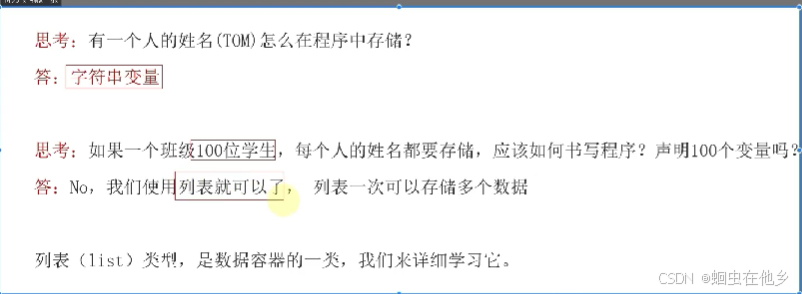
列表的定义
列表中可以存储不同的数据类型
之前好像写错了,写成只能一种类型了
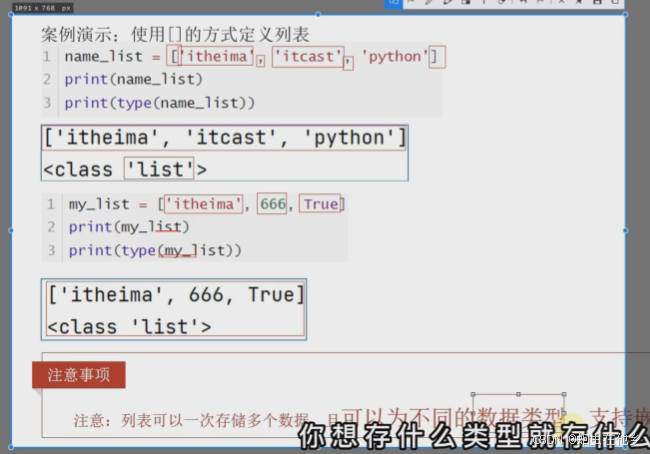
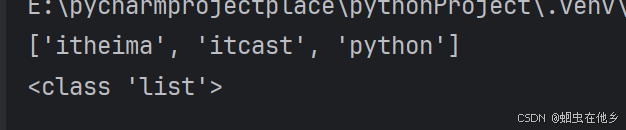
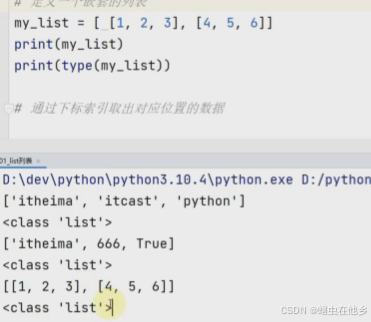
name_list=['itheima','itcast','python']
print(name_list)
print(type(name_list))
假如里面放的不是一种数据类型,那么type依然是list类型
列表的下标索引
python支持正负进行取元素(虽然暂时不知道有啥用,但是很高级)
正向举例

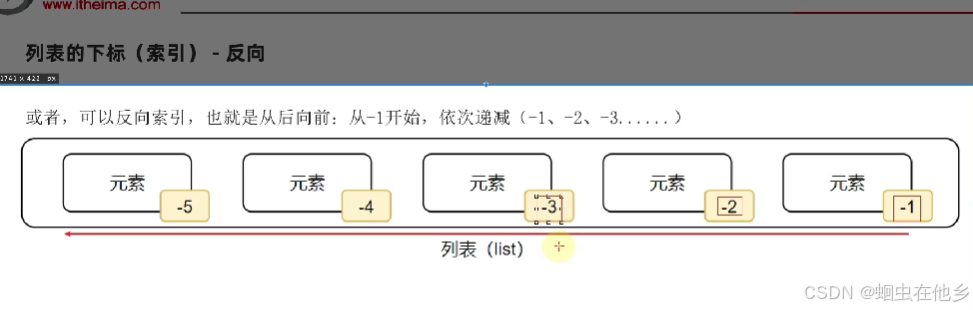
name_list=['tom','Lily','sam']
print(name_list[0])
print(name_list[1])
print(name_list[2])
负向举例
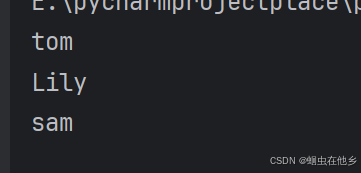
name_list=['tom','Lily','sam']
print(name_list[-1])
print(name_list[-2])
print(name_list[-3])
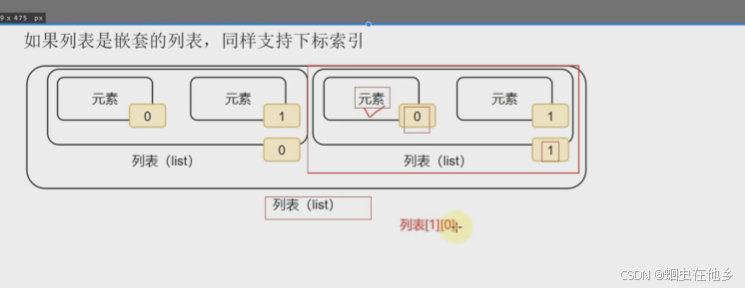
嵌套索引同样可以用下标
用二维数字数组表示,第一个内列表里面第一个个就是按照顺序进行表示
name_list=[[9,8,6],[1,2,3]]
print(name_list[0][0])
print(name_list[0][2])
print(name_list[1][1])
唯一就是别忘了内部列表之间记得加,
还有下标是从0开始的,数对下标
列表的常用操作方法
也就是某个类给我们提供了一堆函数(方法)



name_list=["itcast","itheima","python"]
index=name_list.index("itheima")
print(f"itheima在列表中的下标索引是{index}")
输入列表中的元素,查找元素在列表的那个位置

name_list=["itcast","itheima","python"]
name_list[0]="afteritcast"
print(name_list)
可以看到元素被修改成功了


name_list=[1,2,3]
name_list.insert(1,"insert")
print(name_list)
输入的是什么数字,到最后就会插入到对应位置
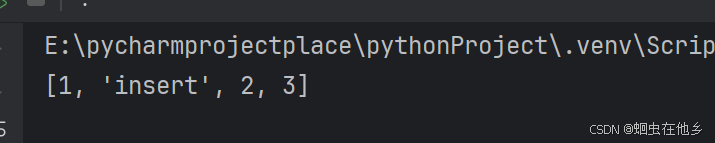

name_list=[1,2,3]
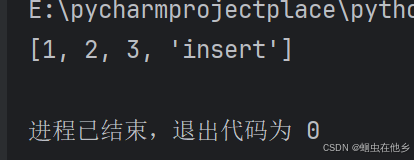
name_list.append("insert")
print(name_list)
听着,所谓追加元素,那肯定是在末尾(致敬杀手)
追加好多元素:extend

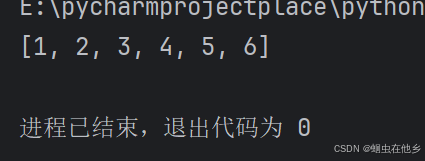
name_list=[1,2,3]
name_list.extend([4,5,6])
print(name_list)
追加的格式也是列表
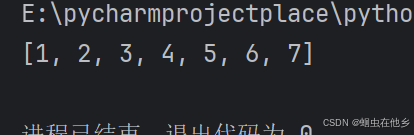
name_list=[1,2,3]
name_list2=[4,5,6,7]
name_list.extend(name_list2)
print(name_list)
合并字符串变的轻轻松松
删除第一种方法:del 列表【下标】
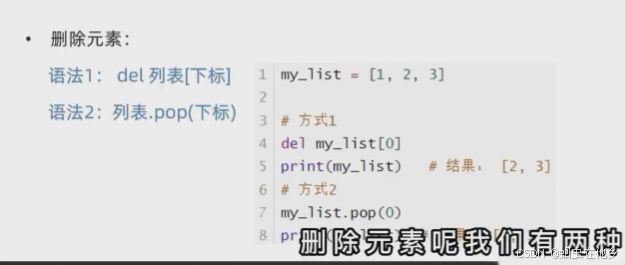
name_list=["itcast","itheima","python"]
del name_list[0]
print(f"列表删除元素后,列表是{name_list}")
删除第二种方法:列表.pop(下标)

name_list=["itcast","itheima","python"]
# del name_list[0]
element=name_list.pop(1)
print(f"列表删除元素后,列表是{name_list},取出的元素是{element}")
瞎联想一下,这个很想弹出栈内元素
del仅仅能完成删除,但pop不仅可以删除,还可以拿到这个元素


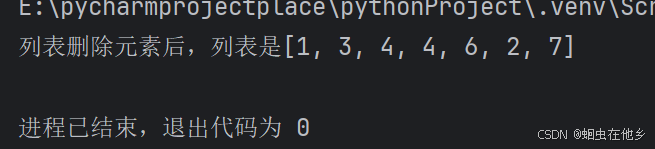
name_list=[1,2,3,4,4,6,2,7]
# del name_list[0]
name_list.remove(2)
print(f"列表删除元素后,列表是{name_list}")
删除第一个匹配的(希望赶快出一个全部匹配删掉的,代码题里面很常见)
列表全部清空
name_list=[1,2,3,4,4,6,2,7]
name_list.clear()
print(f"列表删除元素后,列表是{name_list}")
统计某元素在列表内的数量

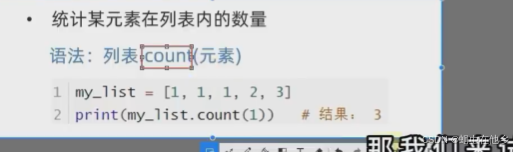
name_list=[1,2,3,4,4,6,2,7]
count=name_list.count(2)
print(f"列表2元素出现的次数为{count}")

列表增删改查巴拉巴拉方法的总结(非常好)
查找某元素的下标
语法:列表.index(元素)
列表的插入元素
语法:列表.insert(下标,元素)
列表的追加元素
语法:列表.append(元素)
列表的大量追加元素
语法:列表.extend(其他列表)
列表的删除元素
语法1:del 列表【下标】
语法2:列表.pop(下标)
列表删除某元素在列表中的第一个匹配项
语法:列表.remove(元素)
清空整个列表
语法:列表.clear()
统计某元素在列表内的数量
语法:列表.count(元素)

列表课后练习

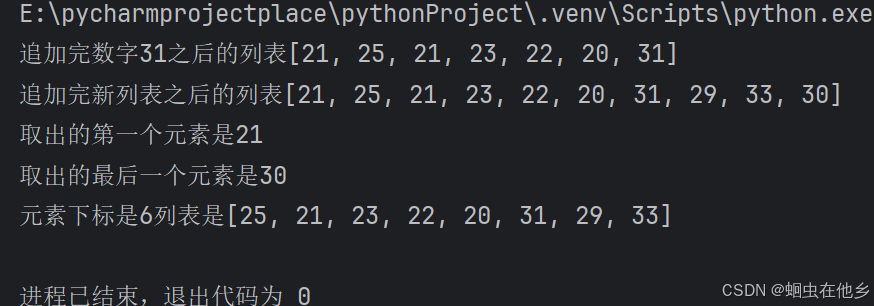
# 定义
student=[21,25,21,23,22,20]
# 追加31
student.append(31)
print(f"追加完数字31之后的列表{student}")
# 追加新列表
student.extend([29,33,30])
print(f"追加完新列表之后的列表{student}")
# 取出第一个元素
num=student.pop(0)
print(f"取出的第一个元素是{num}")
# 取出最后一个元素
num1=student.pop(-1)
print(f"取出的最后一个元素是{num1}")
# 查找元素
index=student.index(31)
print(f"元素下标是{index+1}列表是{student}")
通过这个例题我知道取负数下标有啥用了,假装当我们不知道一共有几个元素的时候,我们需要取元素,就可以直接取-1,就是最后一个元素
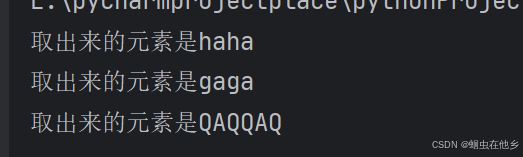
列表循环遍历


student=["haha","gaga","QAQQAQ"]
len=len(student)
index=0
while index<len:
element=student[index]
print(f"取出来的元素是{element}")
index+=1

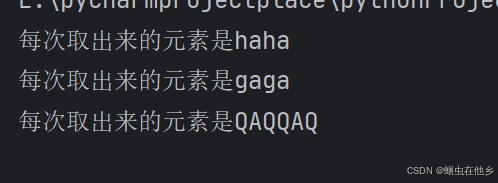
student=["haha","gaga","QAQQAQ"]
for i in student:
print(f"每次取出来的元素是{i}")
小练习
使用while循环

list=[1,2,3,4,5,6,7,8,9,10]
list1=[]
# 使用while循环
num=0
while num<len(list):
if list[num]%2==0:
list1.append(list.pop(num))
num+=1
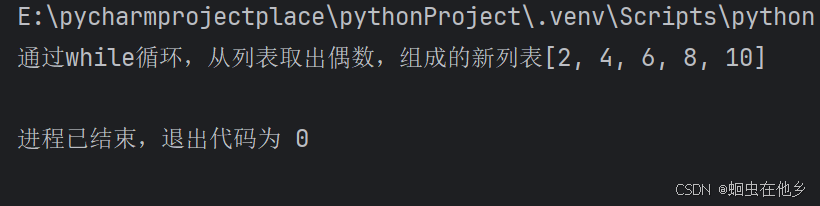
print(f"通过while循环,从列表取出偶数,组成的新列表{list1}")
使用for循环(偷偷给改成奇数了,反正偶数已经打印了一遍了)
list=[1,2,3,4,5,6,7,8,9,10]
list1=[]
# 使用for循环
num=0
for num in list:
if num%2!=0:
list1.append(num)
num+=1
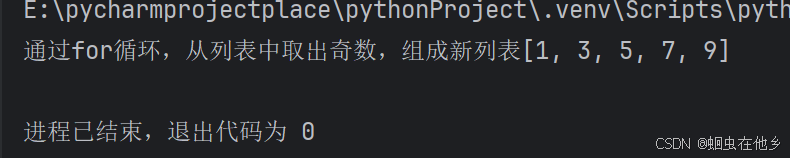
print(f"通过for循环,从列表中取出奇数,组成新列表{list1}")
while循环里面num类似于下标,但是for里面的num就类似于列表中的内容了
元组的定义和相关操作
元组相当于一个只读的列表
元组的操作:比较全




# 定义元组
t1=(1,"hello",True)
print(f"t1的类型是{type(t1)},内容是{t1}")
# 定义单个元素的元组
t2=("hello")
print(f"t1的类型是{type(t2)},内容是{t2}")
# 元组后面假如只有一个数据,数据后面要添加,不然就不是元组类型了,就是元素的类型了
# 元组的嵌套
t3=((1,2,3),(4,5,6))
print(f"t1的类型是{type(t3)},内容是{t3}")
# 下标索引取出内容,假设要取t3里面的5元素
num=t3[1][1]
print(f"取出的元素是{num}")
# 元组的操作:index查找方法
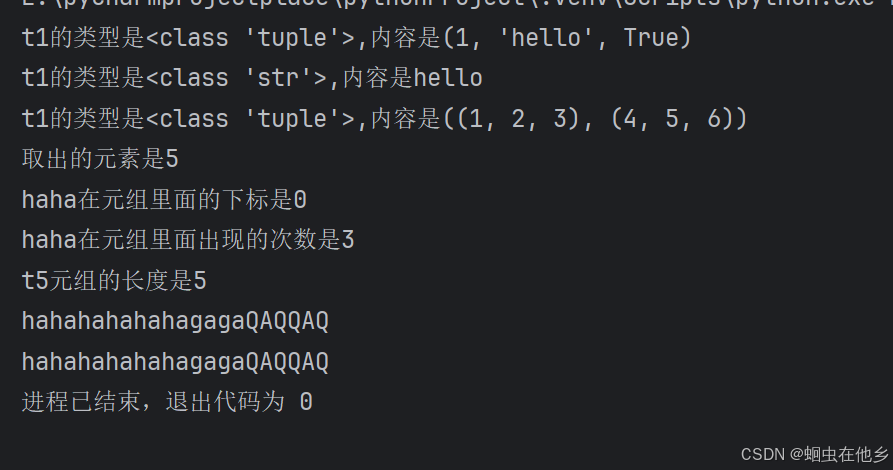
t4=("haha","gaga","QAQQAQ")
index=t4.index("haha")
print(f"haha在元组里面的下标是{index}")
# 元组的操作:count统计方法
t5=("haha","haha","haha","gaga","QAQQAQ")
count=t5.count("haha")
print(f"haha在元组里面出现的次数是{count}")
# 元组的操作:len函数统计元组元素数量
length=len(t5)
print(f"t5元组的长度是{length}")
# 元组的while遍历,这里就是遍历t5元组
num=0
while num<length:
print(t5[num],end='')
num+=1
print("")
# 元组的for遍历
for element in t5:
print(element,end='')
元组里面的元素不能修改
but元组里面的列表可以修改

t9=(1,2,["haha","gaga","QAQQAQ"])
print(t9)
t9[2][0]="hahaha"
t9[2][1]="gagaga"
print(t9)
现在不知道为什么这么设定,功能有点鸡肋,但是它这么做一定有他的道理!

小练习
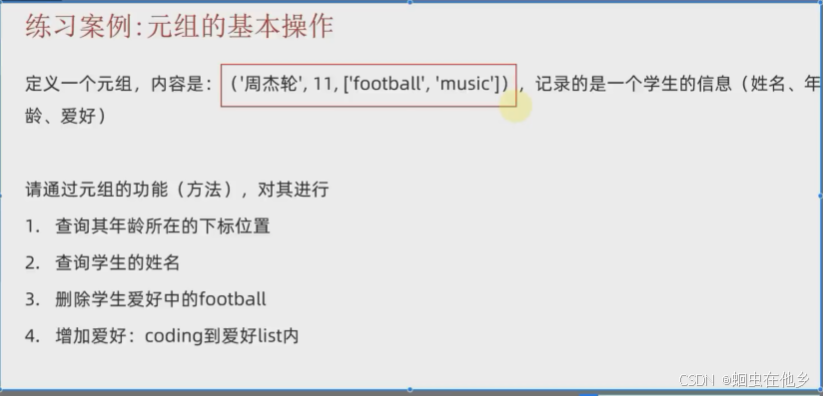
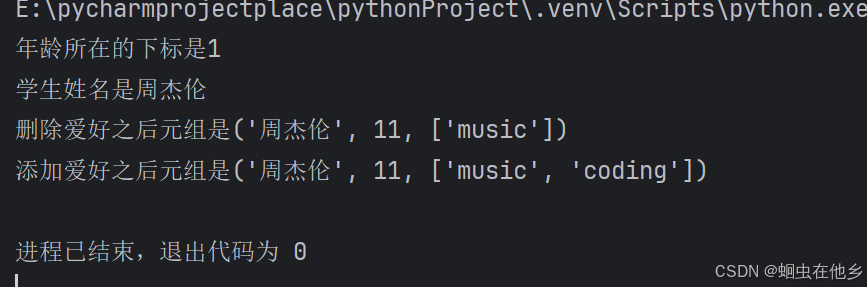
Jay=('周杰伦',11,['football','music'])
# 查询年龄在的下标
index=Jay.index(11)
print(f"年龄所在的下标是{index}")
# 查询学生姓名
str=Jay[0]
print(f"学生姓名是{str}")
# 删除学生爱好中的football
Jay[2].remove("football")
print(f"删除爱好之后元组是{Jay}")
# 增加爱好:coding(每日催眠,我爱编程我爱编程)
Jay[2].append("coding")
print(f"添加爱好之后元组是{Jay}")
字符串的定义和操作
这里的字符串就类似于我们之前学习过的列表和元组了,就是存放大量字符的地方
字符串也是一个不可以修改的数据容器
类似查找替换
分割字符串,到不同的列表中,也就是进行切分
简洁来说就是掐头去尾,去掉前后没有意义的东西
这个不知道是我使用有问题还是咋的,很鸡肋
空格就只能去两头空格
数字去完了之后假如有空格还是有




字符串操作汇总
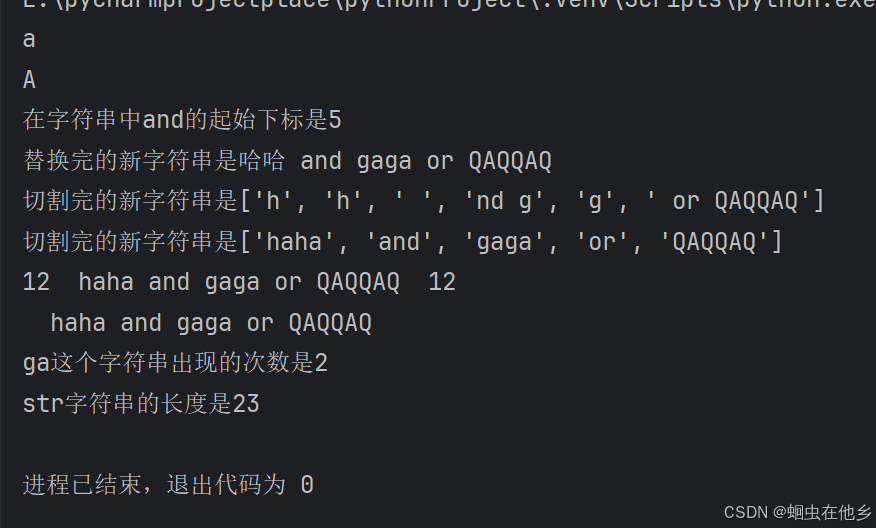
str="haha and gaga or QAQQAQ"
# 通过下标取索引
value=str[1]
value1=str[-5]
print(value)
print(value1)
# 假如我们要修改字符串里面的数据,就只能新增一个字符串
# index方法
value=str.index("and")
print(f"在字符串中and的起始下标是{value}")
# replace方法,老的字符串并不会修改,需要一个新的字符串取接它
str1=str.replace("haha","哈哈")
print(f"替换完的新字符串是{str1}")
# split方法
str2=str.split("a")
print(f"切割完的新字符串是{str2}")
str3=str.split(" ")
print(f"切割完的新字符串是{str3}")
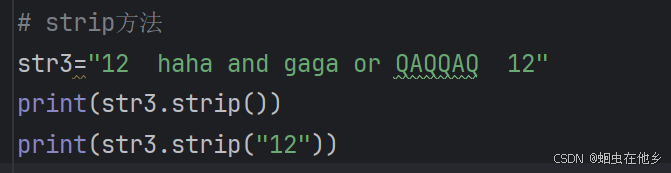
# strip方法
str3="12 haha and gaga or QAQQAQ 12"
print(str3.strip())
print(str3.strip("12"))
# 统计字符串中某字符串的出现次数,count
count=str.count("ga")
print(f"ga这个字符串出现的次数是{count}")
# 统计字符串的长度,len()
length= len(str)
print(f"str字符串的长度是{length}")
while循环和for循环
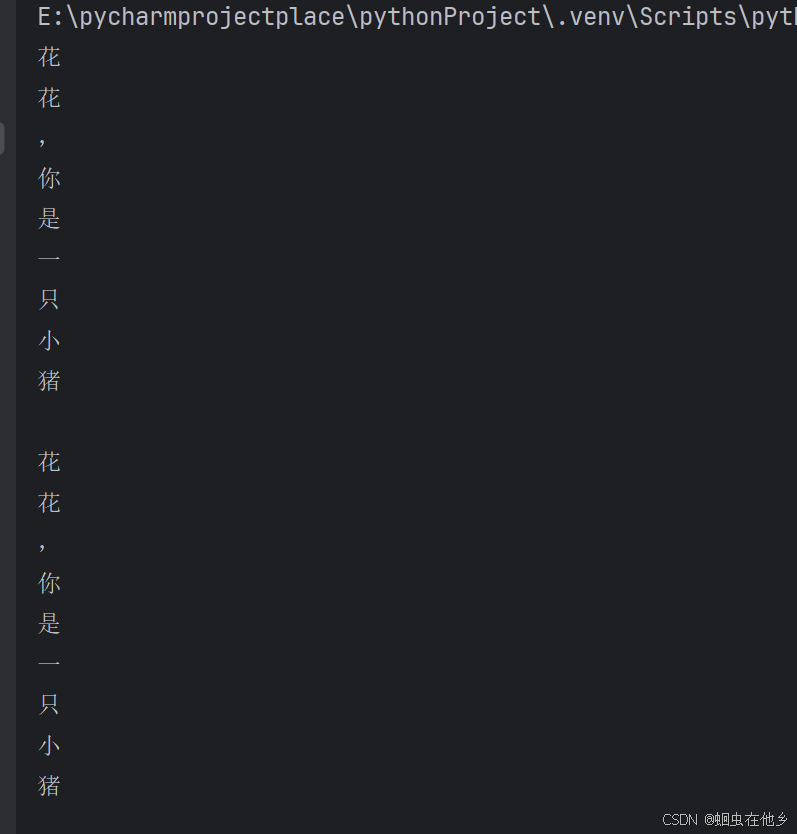
str="花花,你是一只小猪"
# while字符串循环
index=0
while index<len(str):
print(str[index])
index+=1
print("")
# for字符串循环
for i in str:
print(i)

字符串练习
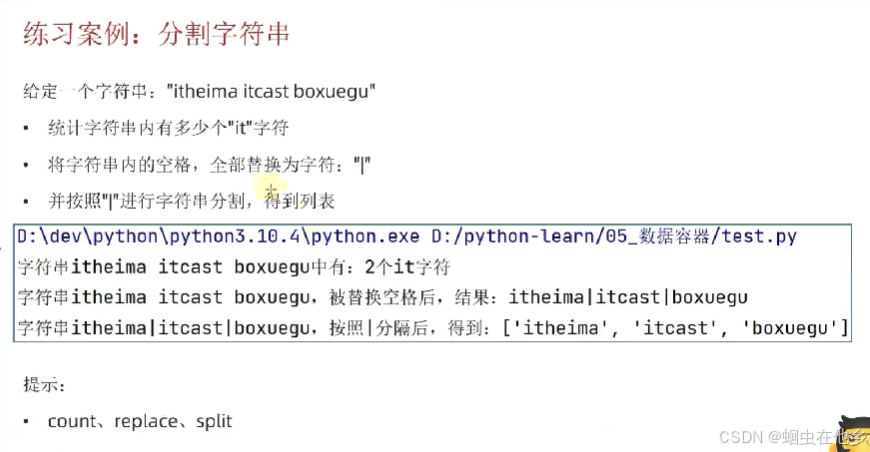
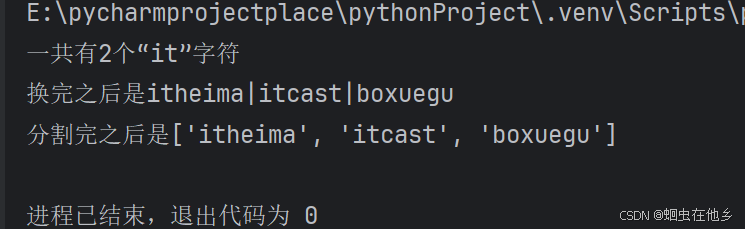
str="itheima itcast boxuegu"
# 统计一共有多少个“it”字符
count=str.count("it")
print(f"一共有{count}个“it”字符")
# 将字符串空格换成|
str1=str.replace(" ","|")
print(f"换完之后是{str1}")
# 按照|进行字符串分割,得到列表
str2=str1.split("|")
print(f"分割完之后是{str2}")
数据容器(序列)的切片
步长2,中间隔一个
步长3,中间隔两个
序列切片也是不会影响序列本身,而是整个新的序列

# 对list进行切片,从1开始,4结束,步长1
list=[1,2,3,4,5,6,7,8,9,10]
# 开始,结束,步长(步长可以省略不写list[1:4])
result=list[1:4:1]
print(f"结果是{result}")
# 对tuple进行切片,从头开始,到最后结束,步长1
tuple=(1,2,3,4,5,6,7,8,9,10)
# 可以这么表示,是开头和结尾的话,步长还是1就都可以省略了
result1=tuple[0:len(tuple):1]
# 省略之后是这样
# result1=tuple[:]
print(f"结果是{result1}")
# 对str进行切片,从头开始,到最后结束,步长2
str="12345678910"
result2=str[::2]
print(f"结果是{result2}")
# 对str进行切片,从头开始,到最后结束,步长-1
str1="12345"
result3=str1[::-1]
print(f"结果是{result3}")
# 对列表进行切片,从3开始,到1结束(不包含它本身),步长-1
list1=[1,2,3,4,5,6,7]
result4=list1[3:1:-1]
print(f"结果是{result4}")
# 对元组进行切片,从头开始,到尾结束,步长-2
tuple1=(1,2,3,4,5,6,7)
result5=tuple1[::-2]
print(f"结果是{result5}")
元组,字符串,列表都是可以划分的都是
【开始:结束:步长】需要一个东西来接输出结果


# 这一步主要是得到这个倒序的序列,我不想自己敲
str="学Python,来黑马程序员,月薪过万"
str1=str[::-1]
# 得到正序序列
str2=str1[::-1]
str3=str2.split(",")
str4=str3[1]
str5=str4.replace("来"," ")
str6=str5.strip(" ")
print(str6)
写的有点麻烦感觉
老师写的:

# 这一步主要是得到这个倒序的序列,我不想自己敲
str="学Python,来黑马程序员,月薪过万"
str1=str[::-1]
# 倒序字符串,然后切片
str2=str1[::-1][9:14]
print(str2)
# 切片,然后倒序
str3=str1[5:10][::-1]
print(str3)
# split分割,replace替换来为空,倒序字符串
str4=str1.split(",")[1][::-1].replace("来","")
print(str4)
被python一长串爽到了
不用加中间变量
集合的定义和操作
集合里面没有重复元素,并且也是无序的



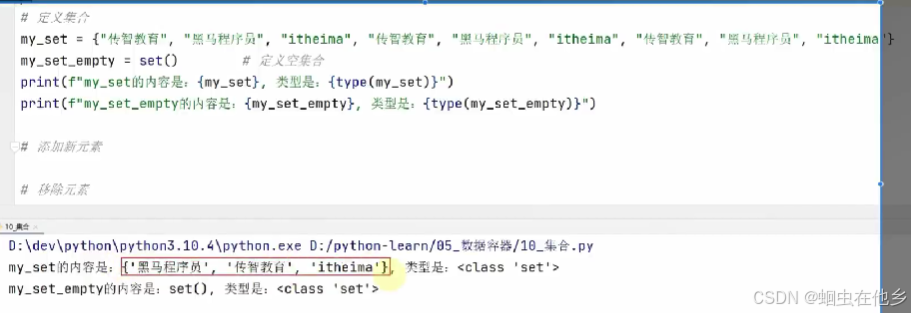

集合的操作






set1={"haha","gaga","QAQQAQ",}
my_set=set()
# 添加新元素
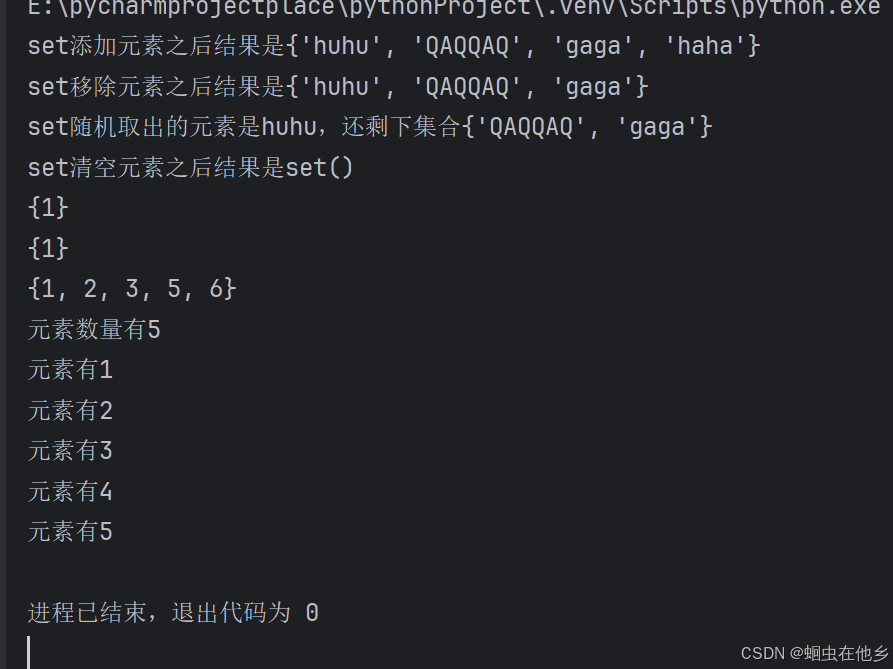
set1.add("huhu")
print(f"set添加元素之后结果是{set1}")
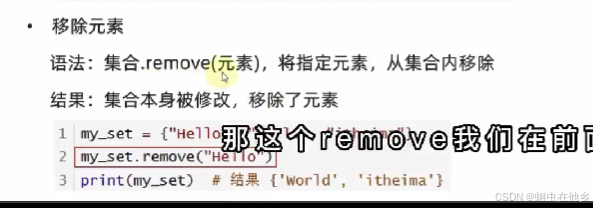
# 移除元素
set1.remove("haha")
print(f"set移除元素之后结果是{set1}")
# 随机取出一个元素
element=set1.pop()
print(f"set随机取出的元素是{element},还剩下集合{set1}")
# 清空集合
set1.clear()
print(f"set清空元素之后结果是{set1}")
# 取2个集合的差集
set2={1,2,3}
set3={2,3,4,5}
set4=set2.difference(set3)
print(set4)
# 消除2个集合的差集
set2.difference_update(set3)
print(set2)
# 2个集合合并为一个
set1={1,2,3}
set2={1,5,6}
set3=set1.union(set2)
print(set3)
# 统计集合元素数量len()
set1={1,2,3,4,5}
print(f"元素数量有{len(set1)}")
# 集合的遍历(不能用while循环,不支持下标索引)
for element in set1:
print(f"元素有{element}")


集合课后练习
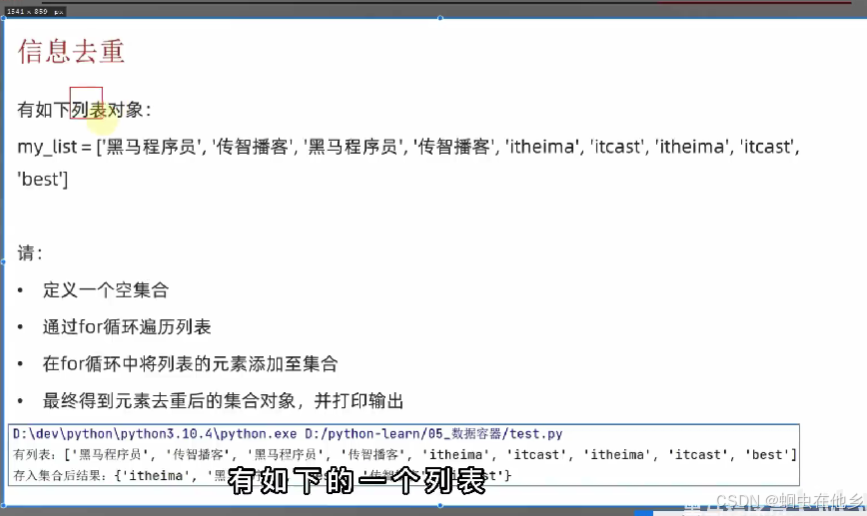
my_list=['黑马程序员','haha','黑马程序员','haha','gaga','gaga','huhu','huhu','best']
set1=set()
for element in my_list:
set1.add(element)
print(set1)
它自动得出来就是不重复的了
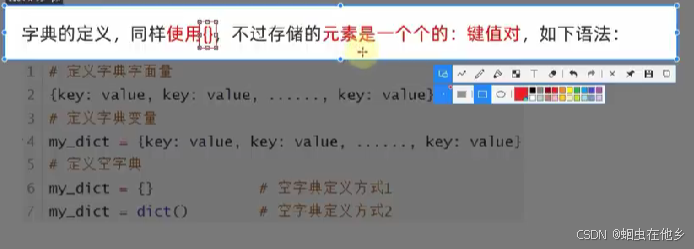
字典定义
类似于我们平常使用的字典
定义字典也是大括号(和集合一样)
但是里面是定义键值对
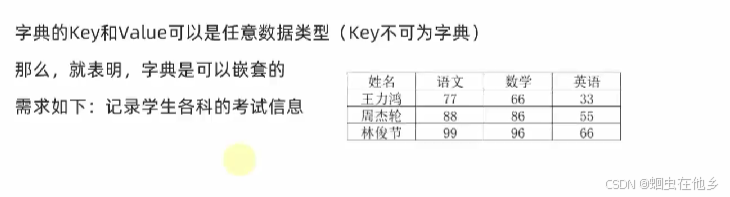
外层key是学生姓名,内层key是考试科目




# 字典定义
dict11={"xiaoming":99,"Jay":88,"lihua":77}
# 定义空字典
dict1={}
dict2=dict()
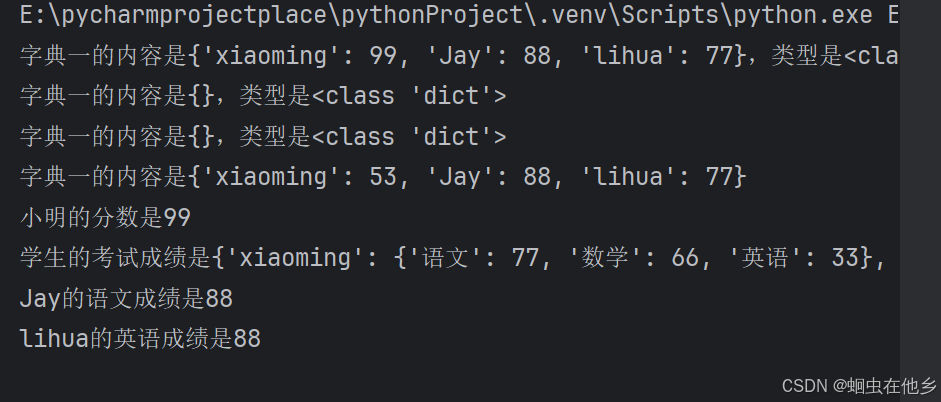
print(f"字典一的内容是{dict11},类型是{type(dict1)}")
print(f"字典一的内容是{dict1},类型是{type(dict1)}")
print(f"字典一的内容是{dict2},类型是{type(dict2)}")
# 定义重复key的字典,新的数会把老的数字覆盖掉
dict3={"xiaoming":99,"Jay":88,"lihua":77,"xiaoming":53}
print(f"字典一的内容是{dict3}")
# 从字典中基于key获取value
dict11={"xiaoming":99,"Jay":88,"lihua":77}
score=dict11["xiaoming"]
print(f"小明的分数是{score}")
# 定义嵌套字典
student_score_dict={
"xiaoming":{
"语文":77,
"数学":66,
"英语":33
},
"Jay":{
"语文":88,
"数学":86,
"英语":55
},
"lihua":{
"语文":99,
"数学":96,
"英语":66
}
}
print(f"学生的考试成绩是{student_score_dict}")
# 从嵌套字典中获取数据
score=student_score_dict["Jay"]["语文"]
print(f"Jay的语文成绩是{score}")
score1=student_score_dict["lihua"]["英语"]
print(f"lihua的英语成绩是{score}")

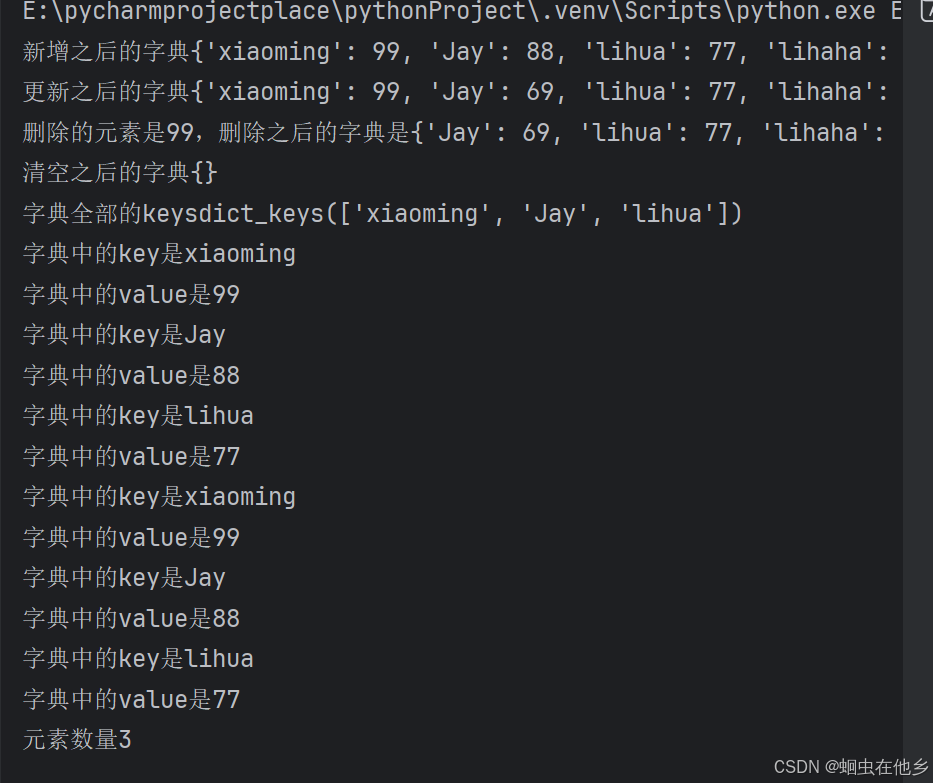
字典的常用操作
新增元素

更新元素


dict11={"xiaoming":99,"Jay":88,"lihua":77}
# 新增元素
dict11["lihaha"]=66
print(f"新增之后的字典{dict11}")
# 更新元素
dict11["Jay"]=69
print(f"更新之后的字典{dict11}")
# 删除元素
score=dict11.pop("xiaoming")
print(f"删除的元素是{score},删除之后的字典是{dict11}")
# 清空元素
dict11.clear()
print(f"清空之后的字典{dict11}")
# 获取全部的key
dict11={"xiaoming":99,"Jay":88,"lihua":77}
key=dict11.keys()
print(f"字典全部的keys{key}")
# 遍历字典,两种方法
for key,value in dict11.items():
print(f"字典中的key是{key}")
print(f"字典中的value是{value}")
for key in dict11.keys():
print(f"字典中的key是{key}")
print(f"字典中的value是{dict11[key]}")
# 统计字典内的元素数量
length=len(dict11.keys())
print(f"元素数量{length}")

字典课后练习
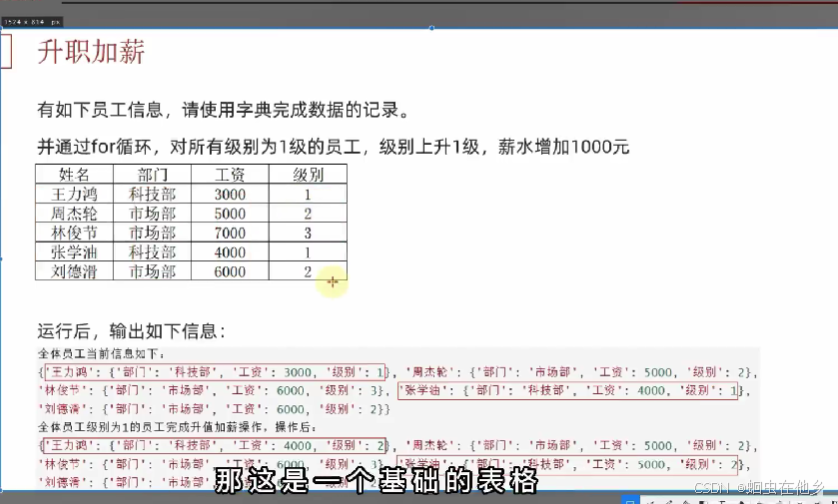
staff_information={
"王力宏":{
"部门":"科技部",
"工资":3000,
"级别":1
},
"周杰伦":{
"部门":"市场部",
"工资":5000,
"级别":2
},
"林俊杰":{
"部门":"市场部",
"工资":7000,
"级别":3
},
"张学友":{
"部门":"科技部",
"工资":4000,
"级别":1
},
"刘德华":{
"部门":"市场部",
"工资":6000,
"级别":2
}
}
print(f"全体员工的当前信息{staff_information}")
for name in staff_information:
if staff_information[name]["级别"] == 1:
# 获取到员工的信息字典!!!
employee_information=staff_information[name]
# 修改员工信息
employee_information["工资"]+=1000
employee_information["级别"]=2
# 将嵌套字典的东西更新回去!!!
staff_information[name]=employee_information
print(f"全体员工的当前信息{staff_information}")
这个案例很好,主要练习了嵌套的类型,很有借鉴意义

5类数据容器的总结(五颗星)

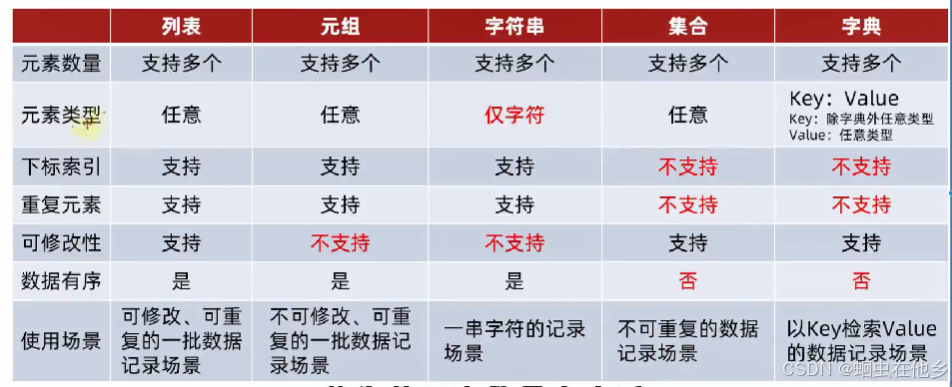

数据容器的通用操作
max,min,len
最大的收获就是又学了一个快捷键:
shift+Alt+鼠标拖动
可以批量选择,然后进行修改



my_list = [1,2,3,4,5,6,7,8,9]
my_tuple = (1,2,3,4,5,6,7,8,9)
my_string = 'hello world'
my_set = {1,2,3,4,5,6,7,8,9}
my_dict = {1,2,3,4,5,6,7,8,9}
print(f"列表 元素个数有{len(my_list)}")
print(f"元组 元素个数有{len(my_tuple)}")
print(f"字符串 元素个数有 {len(my_string)}")
print(f"集合 元素个数有{len(my_set)}")
print(f"字典 元素个数有{len(my_dict)}")
print(f"列表 最大的元素是{max(my_list)}")
print(f"元组 最大的元素是{max(my_tuple)}")
print(f"字符串最大的元素是{max(my_string)}")
print(f"集合 最大的元素是{max(my_set)}")
print(f"字典 最大的元素是{max(my_dict)}")
print(f"列表 最小的元素是{min(my_list)}")
print(f"元组 最小的元素是{min(my_tuple)}")
print(f"字符串最小的元素是{min(my_string)}")
print(f"集合 最小的元素是{min(my_set)}")
print(f"字典 最小的元素是{min(my_dict)}")
整整齐齐
转换不了字典:因为字典是键值对






print(f"列表对象的排序结果:{sorted(my_list)}")
print(f"元组对象的排序结果:{sorted(my_tuple)}")
print(f"字符串对象的排序结果:{sorted(my_string)}")
print(f"集合对象的排序结果:{sorted(my_set)}")
print(f"字典对象的排序结果:{sorted(my_dict)}")
本来乱七八槽的就变得有序了,都变成了列表对象
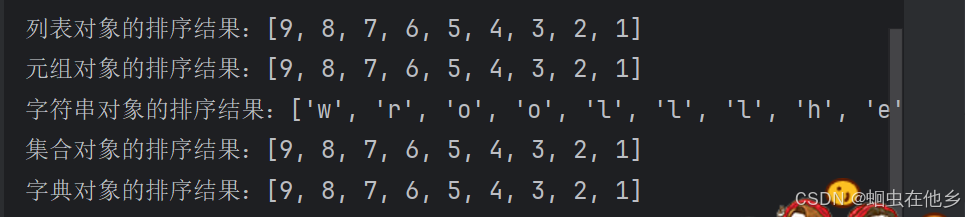
print(f"列表对象的排序结果:{sorted(my_list,reverse=True)}")
print(f"元组对象的排序结果:{sorted(my_tuple,reverse=True)}")
print(f"字符串对象的排序结果:{sorted(my_string,reverse=True)}")
print(f"集合对象的排序结果:{sorted(my_set,reverse=True)}")
print(f"字典对象的排序结果:{sorted(my_dict,reverse=True)}")
全倒过来了

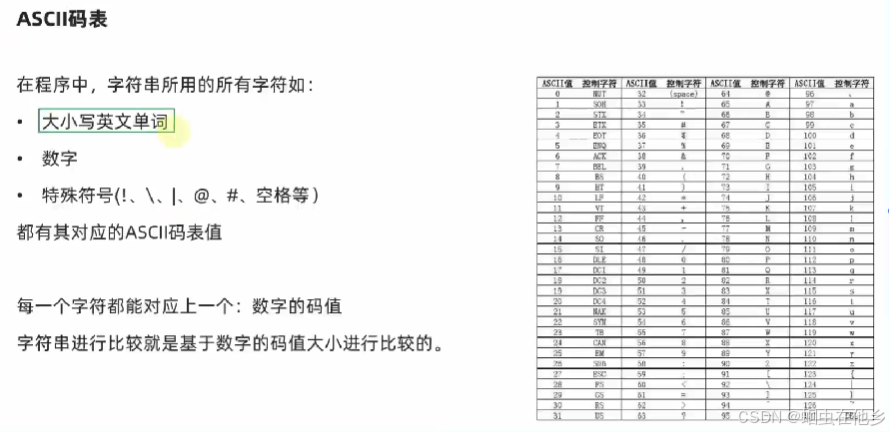
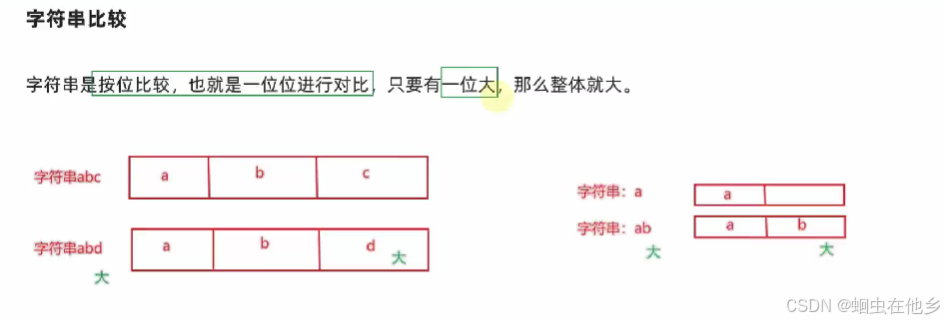
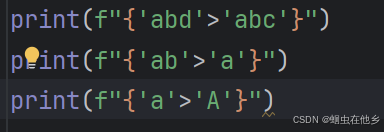
字符串大小比较
按照ASCII进行大小比较的65A,97a
小写a比较大
从前向后比较
不知道是我电脑的问题还是咋,感觉在这里面敲有点卡,换个文章继续干
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 从零开始的python学习生活

发表评论 取消回复