论文:https://arxiv.org/abs/2401.17270
code: https://github.com/AILab-CVC/YOLO-World
1、为什么要做这个研究(理论走向和目前缺陷) ?
之前的开集检测器大多比较慢,不利于部署。
2、他们怎么做这个研究 (方法,尤其是与之前不同之处) ?
结合CLIP和yolov8,CLIP提取文本特征,yolov8提取图像特征,核心是如何将文本特征和图像特征融合,这个特征融合模块要非常简单,最好融合一次就行,不用多多阶段融合,这样部署的时候就可以直接用CLIP离线编码好的文本特征,而不用再实时推理了,节约了大量的计算量,并且非常简单。
3、发现了什么(总结结果,补充和理论的关系)?
提出YOLO-World, 快且实时在V100上可以打到50+FPS?
实际使用下来发现还是比Grounding DINO效果要差一些。
摘要
YOLO系列的检测器在工业界是非常实用的,但是它们有个非常大的问题就是只能检测预定义的类别。本文提出的方法可以通过视觉语言模型在大规模数据集上训练,实现了检测任意类别的目的。在LVIS数据集上AP35.4, V100上52FPS。
1 引言
现有的做开集检测的视觉语言模型(BERT, OV-COCO)计算量都太大了,而且部署不友好。已经有一些论文证明了预训练的大模型效果非常好,但是用预训练的小模型做开集检测的能力仍有待探索。
Yolo-world 的yolov8的检测架构,结合预训练clip文本编码器来编码输入的文本,并用作者设计的重参数化视觉鱼眼数据聚合网络来融合文本和图像特征。在推理阶段,文本编码器可以直接拿掉,只用文本embeddings来作为输入就行。
之前的开集检测方法都需要在线编码文本,以获取需要检测的类别,而yolo-world只需要离线编码一次就行了,后面推理阶段直接用离线编码的文本就行,对部署非常友好。
2 相关研究
传统目标检测
开集目标检测(OVD)
OWL-ViTs, GLIP, Grounding DINO. ZSD-YOLO
3 方法
3.1 预训练方法:区域文本对
传统检测方法的实例标注是类别区域对(类别对应的是类别ID),本文方法使用的是文本类别对,文本可以类别名、短语或一句话。YOLO-World已图像和一系列文本作为输入输出的是框和对应的目标的嵌入特征。
3.2 模型架构
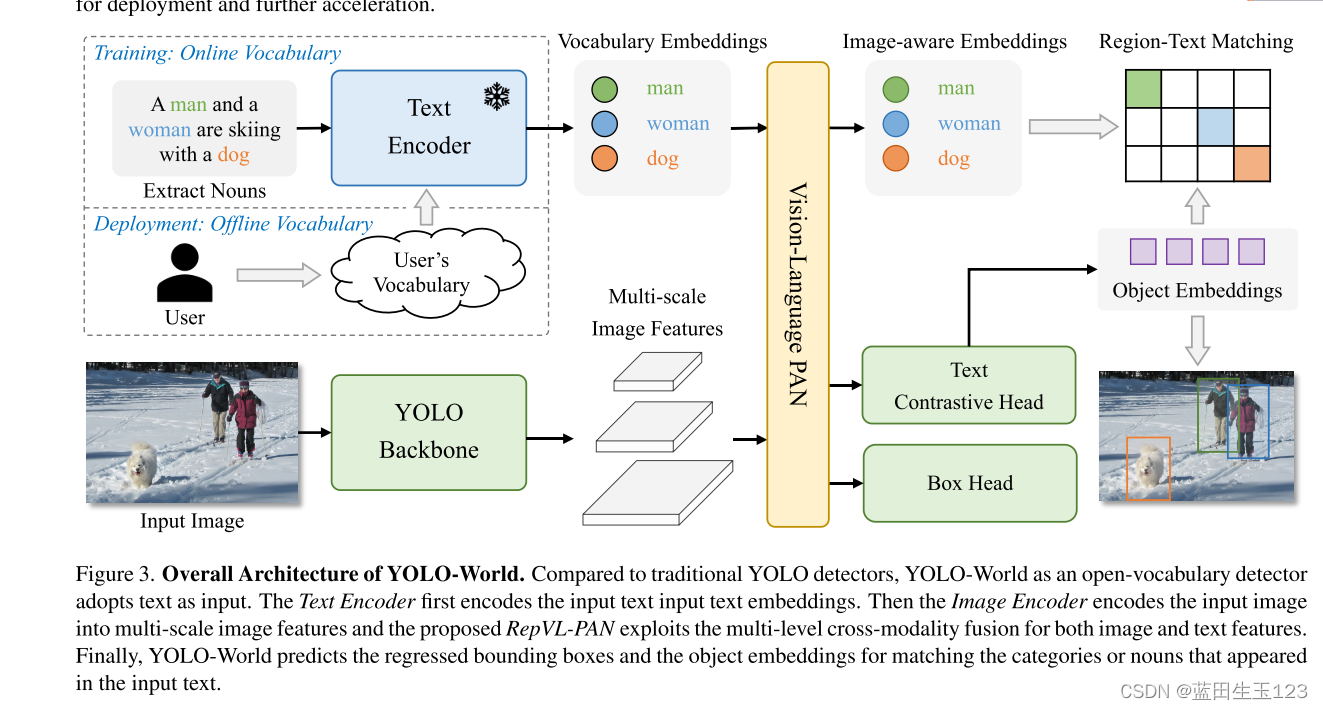
检测器:yolov8
文本编码器:CLIP
文本对比头:文本特征和图像框特征计算余弦相似度
在线训练:马赛克增强
离线推理:输入自定义离线文本特征
3.3 文本图像特征融合模块
![[图片]](/uploads/article_img/53f5c10cdba84c2fadf08d3d6e05df2f)
文本引导的 CSPLayer: 类似与fpn结构的图像文本特征融合层, 文本引导。
Image-Pooling Attention:
3.4 预训练方法
图像文本对伪标注:1)先用n-gram方法从文本中提取名词短语。2)将名词短语输入GLIP获取生成标注框,这样就可以提供粗糙的文本检测框对。3)用CLIP来评估名词短语和对应检测框的相关性,剔除相关性比较低的文本检测框对。如此便可以制作出大规模的用于训练的数据集(CC3M 246K帧)了。
4 实验
4.1实现细节
4.2 预训练
实验设置:预训练阶段文本编码器参数冻结
预训练数据:
![[图片]](/uploads/article_img/fd54715bb0244ddaa38255ef78c4d9a4)
零样本评估:预训练数据中没有LVIS, 在LVIS进行评估
![[图片]](/uploads/article_img/09b3a7008b42417c8f81e3725bb16e5b)
4.3 消融实验
预训练数据:数据越多越好
![[图片]](/uploads/article_img/4386a4d460354be0be87286ba89b501e)
文本图像特征融合模块(RepVL-PAN):
![[图片]](/uploads/article_img/5b346e50214745e68c25d8be23ee91a4)
文本编码器:比较了BERT和CLIP这两种文本编码器,CLIP比bert好很多。且CLIP如果微调的话效果会变差,因为CLIP本来训练用的数据已经就足够丰富了。
![[图片]](/uploads/article_img/0b797d93689e4ba4b95ea3eccda55827)
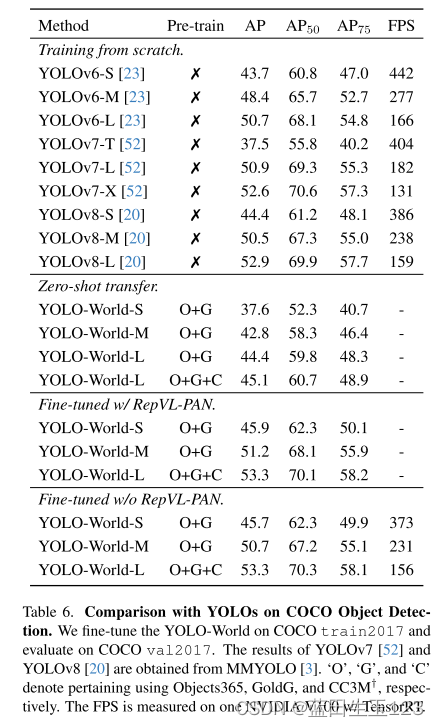
4.4 在COCO和LVIS上微调YOLO-World
实验建立: CLIP也进行了微调,学习率0.01
COCO目标检测:微调时移除了RepVL-PAN以加速训练。
LVIS目标检测
![[图片]](/uploads/article_img/5514b44a0b544c598be1250c40e36717)
4.5 开集实例分割
需要有实例集的分割标注
只微调分割头的话会有更好的开集分割能力(泛化能力)。
[图片]
5结论
提出了YOLO-World,开集实时目标检测器,设计了文本和图像特征融合模块,支持离线部署。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » YOLO-world论文阅读笔记

发表评论 取消回复