
目录
一·命名空间(namespace):
namespace ns {
int t = 5;
}//习惯写法:namespace+名字,注:末尾无;
这里相当于命名空间域;访问的时候要ns::+内部的量
对于c++域的理解:可分为四大域:函数局部域,全局域,命名空间域,类域。
其中前两个影响编译逻辑和生命周期,后两者不影响。
对于命名空间特点:

首先它是可以嵌套的:
namespace ns {
int i = 10;
int a = 10;
namespace ne {
int a = 2;//命名空间的嵌套
}
}这时如果访问ne内的a:可以ns::ne::a;或者可以不完全展开即 using namespace ns::ne。
还有一个就是多文件定义同一个命名空间它会自动合并如:
在头文件中定义一个ns命名空间,在cpp中也存在ns命名空间,同时在cpp调用就可以用到头文件中的ns。
对于standard 命名空间,在iostream库里存在的cin cout 就定义在std这个命名空间里。
二·cout与cin简述:
cin输入的数据自动识别为字符型,cout输出也是类同。
前者配合>>后者配合<<,由于是二元操作符,故只能是两个操作数即里面要么是变量自动识别,要么是字符串。
结合endl(end line ):都是存在于iostream库中的namespace std,故可以对它展开或者std::来使用。
int k= 10;
int e = 0;
int main() {
std::cout << "k是" << k<< endl;
std::cin >> e >> k;
std::cout << "k是" << k << endl;
std::cout << "e是" << e << endl;
}为了提高io效率,可以在程序中加入:
ios_base::sync_with_stdio(false);
cin.tie(nullptr);
cout.tie(nullptr);
三·缺省参数:
顾名思义,就是对于函数有的参数没有的时候可以去固定值,也可以输入:

大致就是要从函数所有参数的右边开始缺省,到左边,但是不能跳跃,当传参的时候省略的可传可不传。
using namespace std;
namespace hs {
int Func(int a, int b, int c = 10) {
return a + b + c;
}
}
#if 0
int main() {
cout << hs::Func(1, 2) << endl;
}
#endif这里由于为给传参,故用默认的即输出13。
四·函数重载:

即重载在同一作用域下,参数个数不同或者类型不同而函数名相同可以构成重载。通过调用函数的时候传参个数或者类型来取决调用哪个函数。
如:
using namespace std;
namespace hs {
int Func(int a, int b, int c = 10) {
return a + b + c;
}
double Func(double a, int b, int c = 11) {
return a + b + c;
}
}
#if 0
int main() {
cout << hs::Func(1.1, 2) << endl;
}
#endif这里调用的就是double类型的Func。(参数类型不同)
using namespace std;
namespace hs {
int Func(int a, int b) {
return a + b ;
}
int Func(int a, int b, int c = 11) {
return a + b + c;
}
}
#if 0
int main() {
cout << hs::Func(1, 2) << endl;
}
#endif这里调用的就是第一个Func。(参数个数不同),当然,也可以是参数顺序不同等等。
而函数重载是为了能调用的时候根据输入区分开不同的函数,故当只有返回值不同时不能作为重载条件:
void fxx()
{}
int fxx()
{
return 0;
}上面这样当调用的时候编译器无法区分。
void f1 ()
{
cout << "f()" << endl;
}
void f1 ( int a = 10)
{
cout << "f(int a)" << endl;
}//由于参数是不同的,可以构成重载,但是调用的时候如果不输入,编译器无法区分调哪一个。五·引用:
即类型&引⽤别名=引⽤对象
相当于给它取了一个新的名字,但还是同一块内存区域,即地址不变,可以理解为改变的时候类似于指针操作。
因此就可以换一种方式交换两个数:
namespace yy {
int c = 10;
int& b = c;
namespace jh {
int m = 1;
int n = 2;
void swap(int& a, int& b) {
int tmp = a;
a = b;
b = tmp;
}
}
}
using namespace yy::jh;
#if 0
int main() {
cin >> yy::c;
cout << &yy::b <<'\n'<< & yy::c << endl;
cout << m <<" "<< n << endl;
swap(m, n);
cout << m << " " << n << endl;
}
#endif这里通过这个引用把m n的值交换了,但m n这块地址没有变,通过m n找到对应的地址把里面的数据改变。(因为a,b是m n的别名故改变a b即改变m n) 。
这里注意一旦引用实体,不能再引用其他:
int main() {
int a = 10;
int& b = a;
int d = 11;
b = d;
cout << "b" <<&b<<" "<<"a" << &a << " " << "d" << &d << endl;
return 0;
}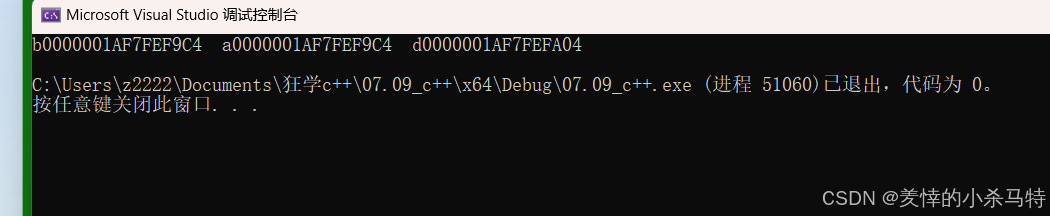
这里可以看出,a b还是同一块地址,b指向的地址里数据只是对d数据的一次拷贝,而不是让b这个实体再次引用d。
const引用:对于权限引用:范围可以缩小,可以等同,但不能放大:
即:
const int a=10;
const int &b=a;//等同
int c=10;
const int& d=c;//缩小这里虽然地址是同一个,但访问权限不同。
再看着一个例子:
const int a=10;
int d=a;//这里并非扩大访问,只是把a值copy给d,两者地址不同
下面引出临对象:所谓临时对象就是编译器需要⼀个空间暂存表达式的求值结果时临时创建的⼀个未命名的对象。
而当在c++中经常会出现,那么把它就要当成常性对待,不可修改故用const修饰。
int a=10;
int b=1;
const int &c=(a+b);
//这里a+b就是临时对象再比如隐式类型转化出现的临时对象:
double d = 3.14;
int i = d;
const int& ra = d;
cout << i << " " << ra << endl;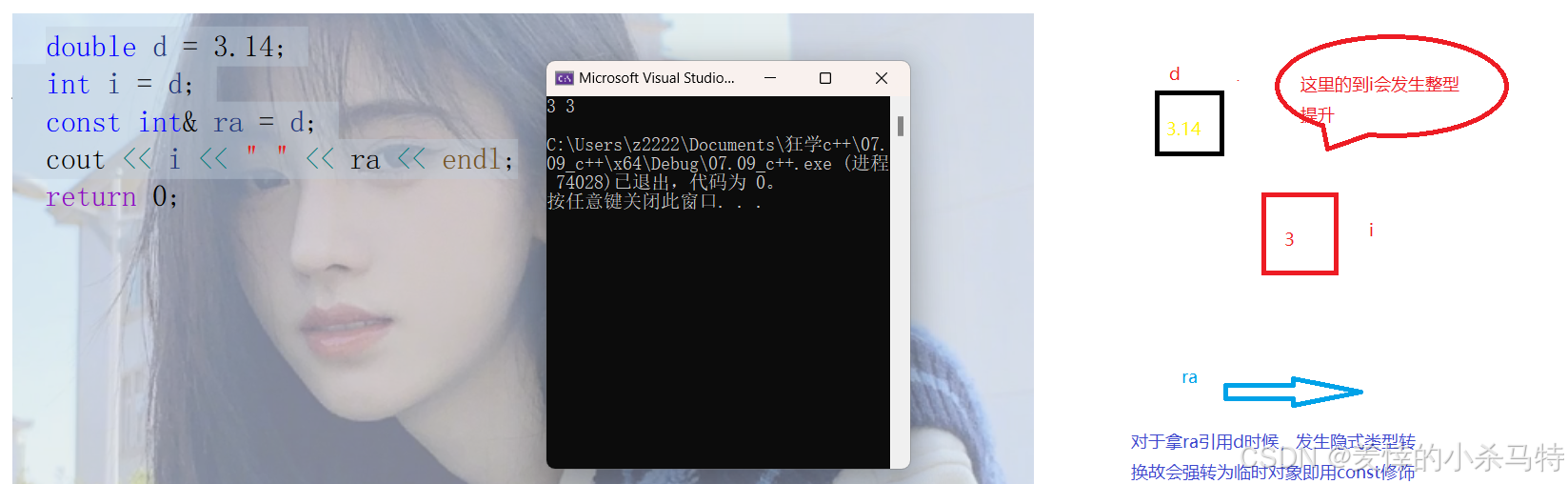
六·内联函数:
即用inline修饰的函数,设计出来代替宏:
而宏:采用直接替换,不开辟空间,但效率慢。
普通函数:开辟多余空间,即建立栈帧,效率高。
而内联函数结合了这两点:
即当使用内联函数,如果遇到短小函数,不复杂的则编译器按照宏的方式去直接替换;但是遇到比如有递归等,就会按照函数方式直接展开建立栈帧去执行如:
namespace nl{
inline int add(int& a, int &b) {
return a + b;
}
inline int Add(int a, int b) {
if (a + b > 10) {
return a + b;
}
return Add(a+3,b+3)+1;
}
}
int main() {
int m = 1, n = 2;
cout << nl::add(m, n) << endl;
//这里由于短小函数,故采用类似宏的直接替换。
cout << nl::Add(m, n) << endl;
//这里由于出现了递归故采用直接展开即开辟一定空间。
return 0;
}再如c++库里面swap函数就用的inline修饰的内联函数;
适用范围:频繁调用的短小函数(非递归)。
七·c++中的nullptr简述:
C++11中引⼊nullptr,nullptr是⼀个特殊的关键字,nullptr是⼀种特殊类型的字⾯量,它可以转换 成任意其他类型的指针类型。使⽤nullptr定义空指针可以避免类型转换的问题,因为nullptr只能被 隐式地转换为指针类型,⽽不能被转换为整数类型。类似c中的NULL。
void f(int x)
{
cout << "f(int x)" << endl;
}
void f(int* ptr)
{
cout << "f(int* ptr)" << endl;
}
int main() {
f(0);
f(NULL);
f(nullptr);
return 0;
}
这里对于c语言可能NULL可以这样,但是c++会直接识别为0;故在这里c++对空指针用nullptr。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » ☺初识c++(语法篇)☺

发表评论 取消回复