B站对应视频:
Elasticsearch01-01.为什么学习elasticsearch_哔哩哔哩_bilibili
大多数日常项目,搜索肯定是访问频率最高的页面之一。目前搜索功能是基于数据库的模糊搜索来实现的,存在很多问题。
首先,查询效率较低。
由于数据库模糊查询不走索引,在数据量较大的时候,查询性能很差。
改为基于搜索引擎后速度会有显著提升。
需要注意的是,数据库模糊查询随着表数据量的增多,查询性能的下降会非常明显,而搜索引擎的性能则不会随着数据增多而下降太多。
其次,功能单一
数据库的模糊搜索功能单一,匹配条件非常苛刻,必须恰好包含用户搜索的关键字。而在搜索引擎中,用户输入出现个别错字,或者用拼音搜索、同义词搜索都能正确匹配到数据。
综上,在面临海量数据的搜索,或者有一些复杂搜索需求的时候,推荐使用专门的搜索引擎来实现搜索功能。
目前全球的搜索引擎技术排名如下:
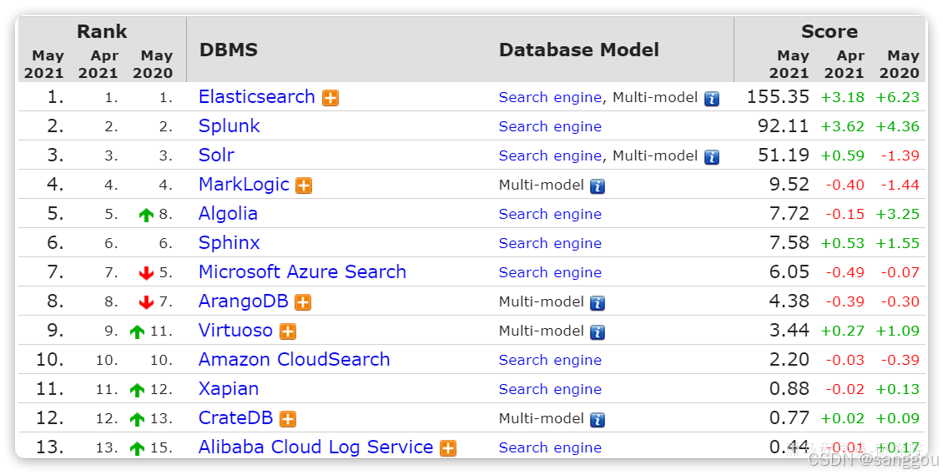
排名第一的就是我们今天要学习的elasticsearch.
elasticsearch是一款非常强大的开源搜索引擎,支持的功能非常多,例如:
代码搜索
商品搜索

解决方案搜索

地图搜索
通过今天的学习大家要达成下列学习目标:
-
理解倒排索引原理
-
会使用IK分词器
-
理解索引库Mapping映射的属性含义
-
能创建索引库及映射
-
能实现文档的CRUD
1.初识elasticsearch
Elasticsearch的官方网站如下:
https://www.elastic.co/cn/elasticsearch/
本章我们一起来初步了解一下Elasticsearch的基本原理和一些基础概念。
1.1.认识和安装
Elasticsearch是由elastic公司开发的一套搜索引擎技术,它是elastic技术栈中的一部分。完整的技术栈包括:
-
Elasticsearch:用于数据存储、计算和搜索
-
Logstash/Beats:用于数据收集
-
Kibana:用于数据可视化
整套技术栈被称为ELK,经常用来做日志收集、系统监控和状态分析等等:

整套技术栈的核心就是用来存储、搜索、计算的Elasticsearch,因此我们接下来学习的核心也是Elasticsearch。
我们要安装的内容包含2部分:
-
elasticsearch:存储、搜索和运算
-
kibana:图形化展示
首先Elasticsearch不用多说,是提供核心的数据存储、搜索、分析功能的。
然后是Kibana,Elasticsearch对外提供的是Restful风格的API,任何操作都可以通过发送http请求来完成。不过http请求的方式、路径、还有请求参数的格式都有严格的规范。这些规范我们肯定记不住,因此我们要借助于Kibana这个服务。
Kibana是elastic公司提供的用于操作Elasticsearch的可视化控制台。它的功能非常强大,包括:
-
对Elasticsearch数据的搜索、展示
-
对Elasticsearch数据的统计、聚合,并形成图形化报表、图形
-
对Elasticsearch的集群状态监控
-
它还提供了一个开发控制台(DevTools),在其中对Elasticsearch的Restful的API接口提供了语法提示
1.1.1.安装elasticsearch
通过下面的Docker命令即可安装单机版本的elasticsearch:
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network hm-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1注意,这里我们采用的是elasticsearch的7.12.1版本,由于8以上版本的JavaAPI变化很大,在企业中应用并不广泛,企业中应用较多的还是8以下的版本。
如果拉取镜像困难,可以直接使用这个镜像tar包(所有资料在文章末尾可以一次性提取):

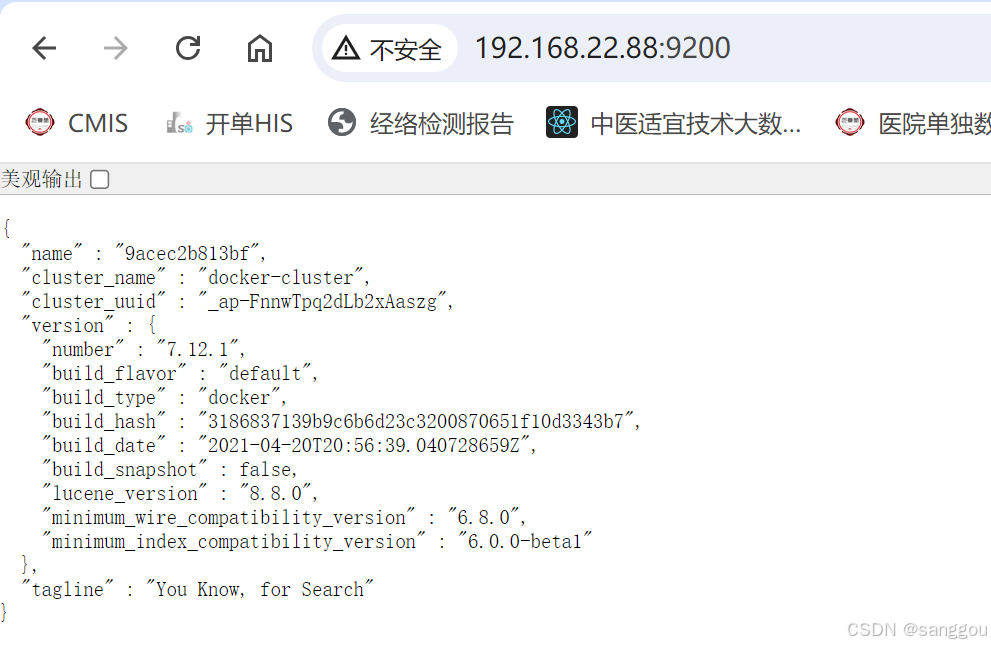
安装完成后,访问9200端口,即可看到响应的Elasticsearch服务的基本信息:
1.1.2.安装Kibana
通过下面的Docker命令,即可部署Kibana:
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=hm-net \
-p 5601:5601 \
kibana:7.12.1如果拉取镜像困难,可以直接导入课前资料提供的镜像tar包:

安装完成后,直接访问5601端口,即可看到控制台页面:
选择Explore on my own之后,进入主页面:

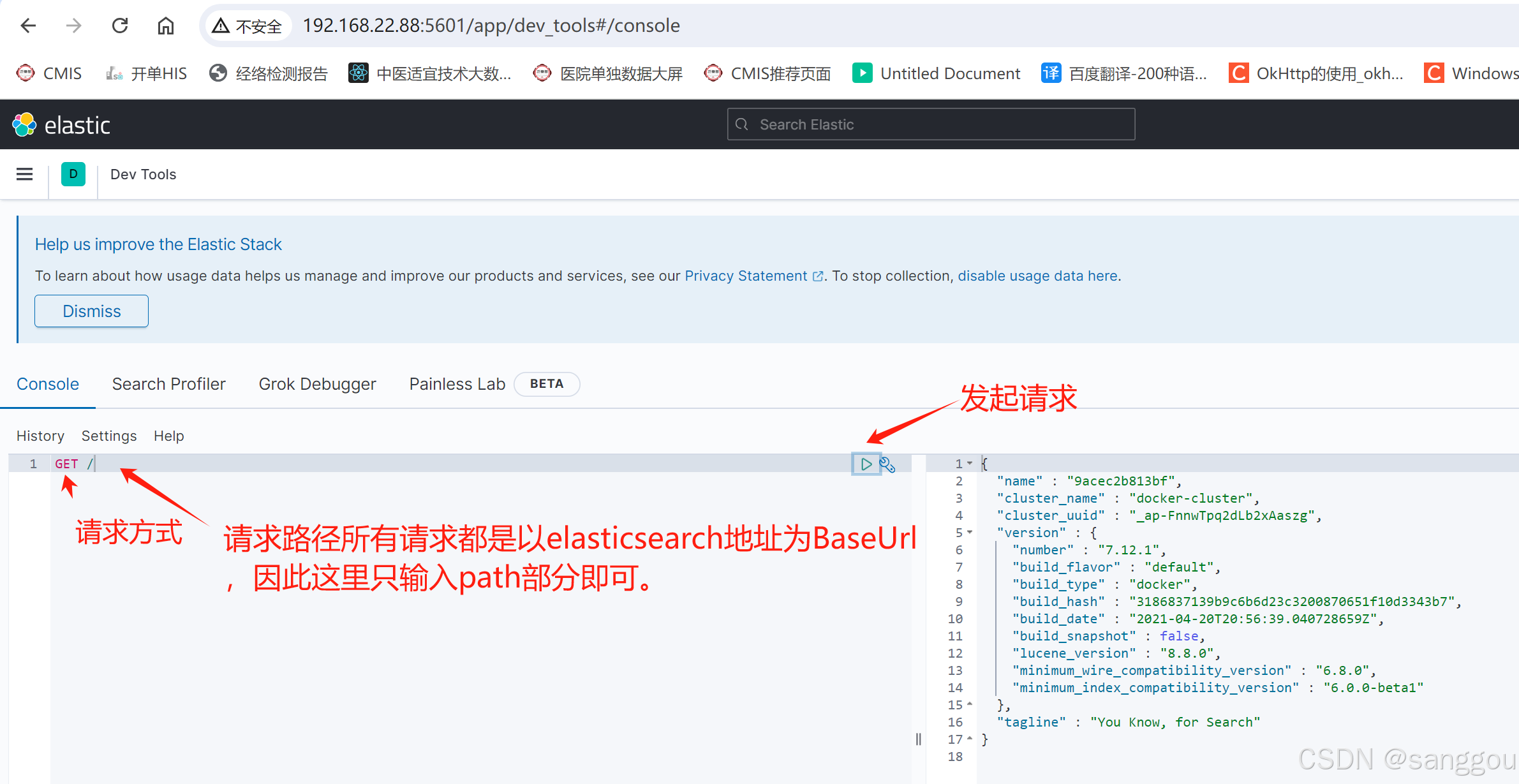
然后选中Dev tools,进入开发工具页面:
1.2.倒排索引
elasticsearch之所以有如此高性能的搜索表现,正是得益于底层的倒排索引技术。那么什么是倒排索引呢?
倒排索引的概念是基于MySQL这样的正向索引而言的。
1.2.1.正向索引
我们先来回顾一下正向索引。
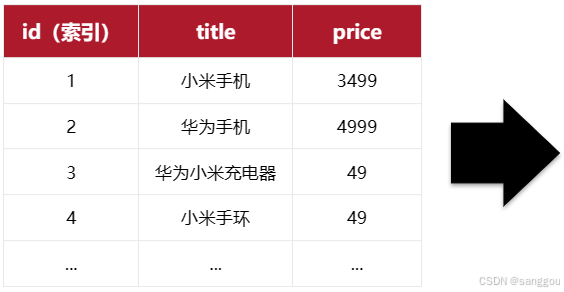
例如有一张名为tb_goods的表:
| id | title | price |
|---|---|---|
| 1 | 小米手机 | 3499 |
| 2 | 华为手机 | 4999 |
| 3 | 华为小米充电器 | 49 |
| 4 | 小米手环 | 49 |
| ... | ... | ... |
其中的id字段已经创建了索引,由于索引底层采用了B+树结构,因此我们根据id搜索的速度会非常快。但是其他字段例如title,只在叶子节点上存在。
因此要根据title搜索的时候只能遍历树中的每一个叶子节点,判断title数据是否符合要求。
比如用户的SQL语句为:
select * from tb_goods where title like '%手机%';那搜索的大概流程如图:
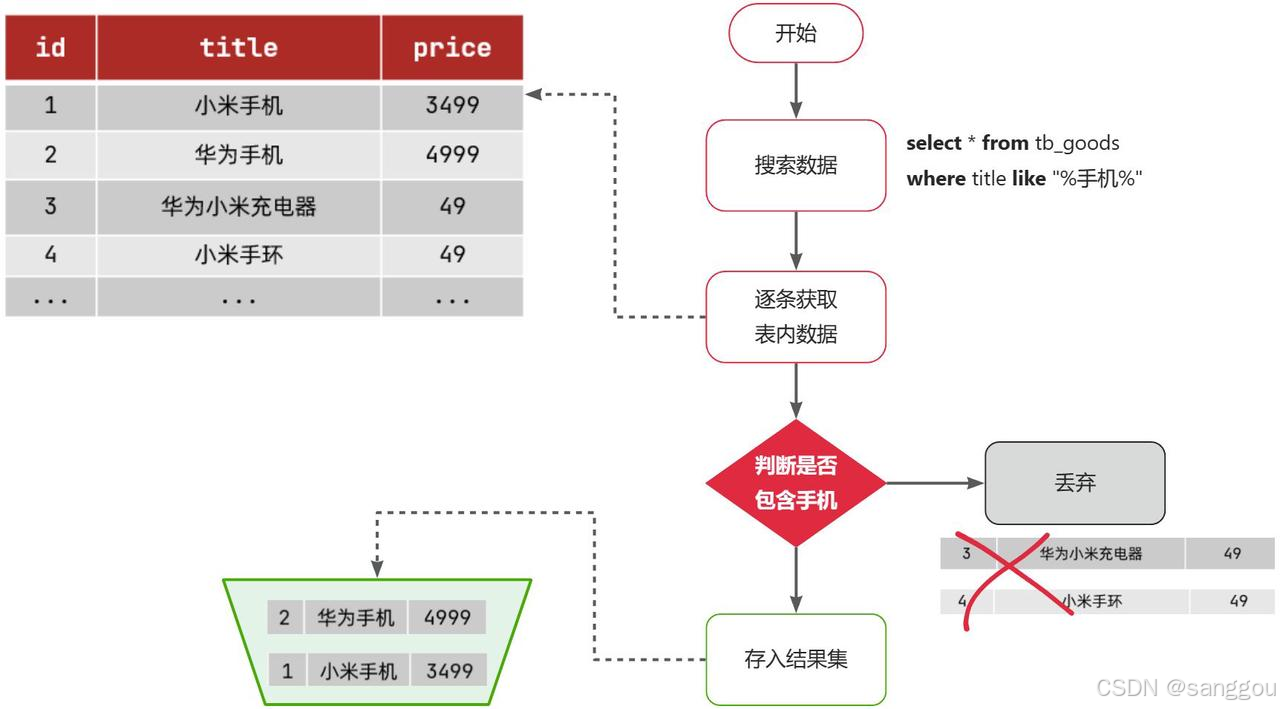
说明:
-
1)检查到搜索条件为
like '%手机%',需要找到title中包含手机的数据 -
2)逐条遍历每行数据(每个叶子节点),比如第1次拿到
id为1的数据 -
3)判断数据中的
title字段值是否符合条件 -
4)如果符合则放入结果集,不符合则丢弃
-
5)回到步骤1
综上,根据id精确匹配时,可以走索引,查询效率较高。而当搜索条件为模糊匹配时,由于索引无法生效,导致从索引查询退化为全表扫描,效率很差。
因此,正向索引适合于根据索引字段的精确搜索,不适合基于部分词条的模糊匹配。
而倒排索引恰好解决的就是根据部分词条模糊匹配的问题。
1.2.2.倒排索引
倒排索引中有两个非常重要的概念:
-
文档(
Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息 -
词条(
Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条
创建倒排索引是对正向索引的一种特殊处理和应用,流程如下:
-
将每一个文档的数据利用分词算法根据语义拆分,得到一个个词条
-
创建表,每行数据包括词条、词条所在文档id、位置等信息
-
因为词条唯一性,可以给词条创建正向索引
此时形成的这张以词条为索引的表,就是倒排索引表,两者对比如下:
正向索引
| id(索引) | title | price |
|---|---|---|
| 1 | 小米手机 | 3499 |
| 2 | 华为手机 | 4999 |
| 3 | 华为小米充电器 | 49 |
| 4 | 小米手环 | 49 |
| ... | ... | ... |
倒排索引
| 词条(索引) | 文档id |
|---|---|
| 小米 | 1,3,4 |
| 手机 | 1,2 |
| 华为 | 2,3 |
| 充电器 | 3 |
| 手环 | 4 |
倒排索引的搜索流程如下(以搜索"华为手机"为例),如图:
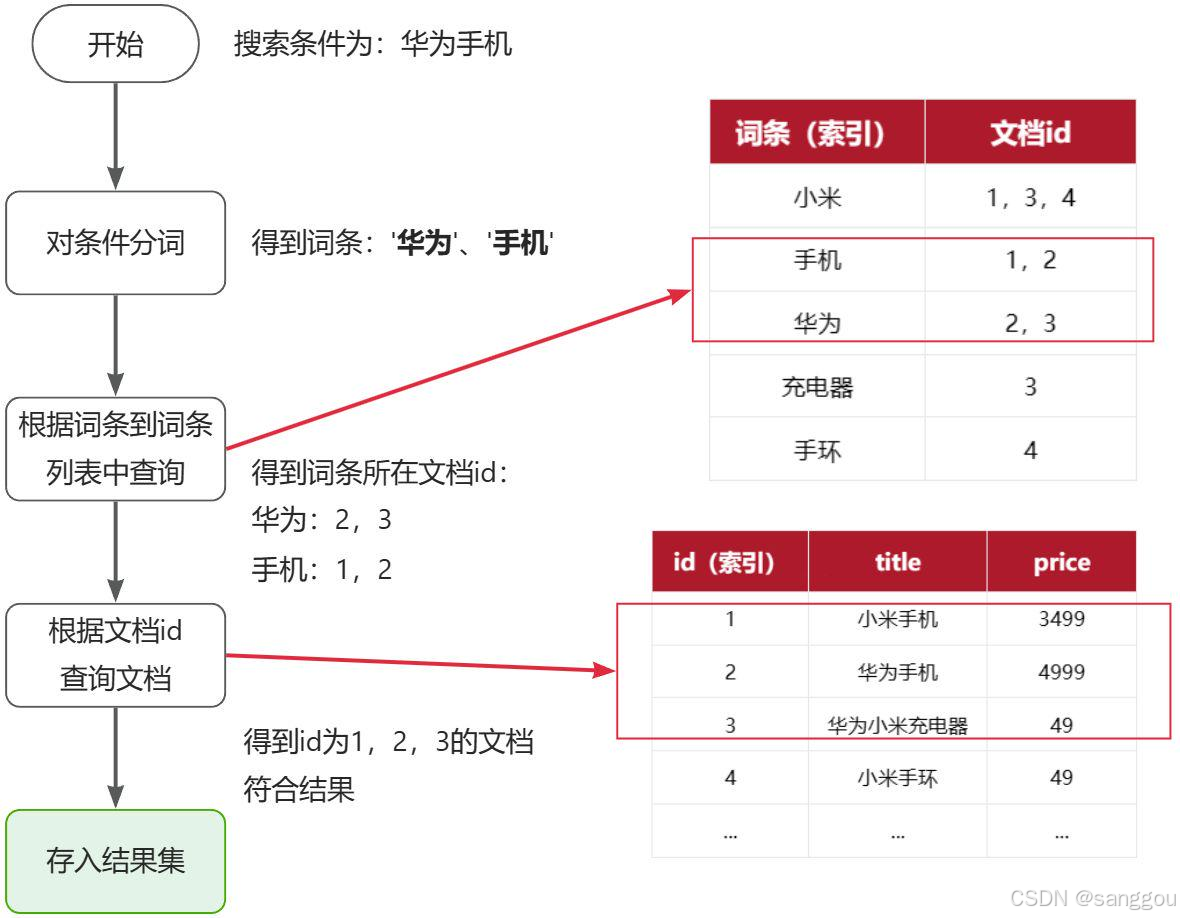
流程描述:
1)用户输入条件"华为手机"进行搜索。
2)对用户输入条件分词,得到词条:华为、手机。
3)拿着词条在倒排索引中查找(由于词条有索引,查询效率很高),即可得到包含词条的文档id:1、2、3。
4)拿着文档id到正向索引中查找具体文档即可(由于id也有索引,查询效率也很高)。
虽然要先查询倒排索引,再查询倒排索引,但是无论是词条、还是文档id都建立了索引,查询速度非常快!无需全表扫描。
1.2.3.正向和倒排
那么为什么一个叫做正向索引,一个叫做倒排索引呢?
-
正向索引是最传统的,根据id索引的方式。但根据词条查询时,必须先逐条获取每个文档,然后判断文档中是否包含所需要的词条,是根据文档找词条的过程。
-
而倒排索引则相反,是先找到用户要搜索的词条,根据词条得到保护词条的文档的id,然后根据id获取文档。是根据词条找文档的过程。
是不是恰好反过来了?
那么两者方式的优缺点是什么呢?
正向索引:
-
优点:
-
可以给多个字段创建索引
-
根据索引字段搜索、排序速度非常快
-
-
缺点:
-
根据非索引字段,或者索引字段中的部分词条查找时,只能全表扫描。
-
倒排索引:
-
优点:
-
根据词条搜索、模糊搜索时,速度非常快
-
-
缺点:
-
只能给词条创建索引,而不是字段
-
无法根据字段做排序
-
1.3.基础概念
elasticsearch中有很多独有的概念,与mysql中略有差别,但也有相似之处。
1.3.1.文档和字段
elasticsearch是面向文档(Document)存储的,可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化为json格式后存储在elasticsearch中:

因此,原本数据库中的一行数据就是ES中的一个JSON文档;而数据库中每行数据都包含很多列,这些列就转换为JSON文档中的字段(Field)。
1.3.2.索引和映射
随着业务发展,需要在es中存储的文档也会越来越多,比如有商品的文档、用户的文档、订单文档等等:

所有文档都散乱存放显然非常混乱,也不方便管理。
因此,我们要将类型相同的文档集中在一起管理,称为索引(Index)。例如:
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Elasticsearch详细介绍

发表评论 取消回复