2个doc有些相似有些不相似,如何衡量这个相似度;
直接用Jaccard距离,计算量太大
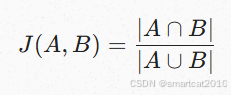
TF-IDF: TF*IDF
TF:该词在该文档中的出现次数,
IDF:该词在所有文档中的多少个文档出现是DF,lg(N/(1+DF))

MinHash
代码:
import random from typing import List, Set, Tuple class MinHash: def __init__(self, num_hashes: int = 100): self.num_hashes = num_hashes self.hash_functions = self._generate_hash_functions() def _generate_hash_functions(self) -> List[Tuple[int, int, int]]: """Generate hash functions of the form (a*x + b) % c.""" max_prime = 2**31 - 1 # Mersenne prime return [(random.randint(1, max_prime), random.randint(0, max_prime), max_prime) for _ in range(self.num_hashes)] def _minhash(self, document: Set[str]) -> List[int]: """Compute MinHash signature for a document.""" signature = [float('inf')] * self.num_hashes for word in document: for i, (a, b, c) in enumerate(self.hash_functions): hash_value = (a * hash(word) + b) % c signature[i] = min(signature[i], hash_value) return signature def jaccard_similarity(self, sig1: List[int], sig2: List[int]) -> float: """Estimate Jaccard similarity from MinHash signatures.""" return sum(s1 == s2 for s1, s2 in zip(sig1, sig2)) / self.num_hashes def deduplicate(self, documents: List[str], threshold: float = 0.5) -> List[str]: """Deduplicate documents based on MinHash similarity.""" # Preprocess documents into sets of words doc_sets = [set(doc.lower().split()) for doc in documents] # Compute MinHash signatures for all documents signatures = [self._minhash(doc_set) for doc_set in doc_sets] # Find unique documents unique_docs = [] for i, doc in enumerate(documents): is_duplicate = False for j in range(len(unique_docs)): if self.jaccard_similarity(signatures[i], signatures[j]) >= threshold: is_duplicate = True break if not is_duplicate: unique_docs.append(doc) return unique_docs100个hash函数;
在某个hash函数上,1个doc里的所有word,在该函数上的hash值,其中最小的那个,记下来;
该doc得到100个最小hash值,该100维向量,作为其signature;
2个doc的相似度,就是100个维度里的相等数目,除以100;
SimHash
MinHash和SimHash_minhash simhash-CSDN博客
海量文本去重(允许一定的噪声);文档里权重最大的前N个词(或词组)进行Hash编码,1正0负乘以词的权重,N个词的向量按位相加,再反编码(正1负0),得到该文档的编码;两篇文档的距离用编码的海明距离,小于Bar(例如3)则认为二者相似;
import hashlib from typing import List, Tuple class SimHash: def __init__(self, hash_bits: int = 64): self.hash_bits = hash_bits def _string_hash(self, text: str) -> int: """Create a hash for a given string.""" return int(hashlib.md5(text.encode('utf-8')).hexdigest(), 16) def _create_shingles(self, text: str, k: int = 2) -> List[str]: """Create k-shingles from the text.""" return [text[i:i+k] for i in range(len(text) - k + 1)] def _compute_simhash(self, features: List[str]) -> int: """Compute the SimHash of a list of features.""" v = [0] * self.hash_bits for feature in features: feature_hash = self._string_hash(feature) for i in range(self.hash_bits): bitmask = 1 << i if feature_hash & bitmask: v[i] += 1 else: v[i] -= 1 fingerprint = 0 for i in range(self.hash_bits): if v[i] >= 0: fingerprint |= 1 << i return fingerprint def _hamming_distance(self, hash1: int, hash2: int) -> int: """Compute the Hamming distance between two hashes.""" xor = hash1 ^ hash2 return bin(xor).count('1') def compute_similarity(self, hash1: int, hash2: int) -> float: """Compute the similarity between two SimHashes.""" distance = self._hamming_distance(hash1, hash2) return 1 - (distance / self.hash_bits) def deduplicate(self, documents: List[str], threshold: float = 0.9) -> List[Tuple[str, int]]: """Deduplicate documents based on SimHash similarity.""" unique_docs = [] for doc in documents: shingles = self._create_shingles(doc.lower()) doc_hash = self._compute_simhash(shingles) is_duplicate = False for unique_doc, unique_hash in unique_docs: if self.compute_similarity(doc_hash, unique_hash) >= threshold: is_duplicate = True break if not is_duplicate: unique_docs.append((doc, doc_hash)) return unique_docs # Example usage if __name__ == "__main__": simhash = SimHash(hash_bits=64) documents = [ "The quick brown fox jumps over the lazy dog", "The quick brown fox jumps over the sleeping dog", "The lazy dog is sleeping", "A completely different document" ] unique_docs = simhash.deduplicate(documents, threshold=0.7) print("Original documents:") for doc in documents: print(f"- {doc}") print("\nUnique documents:") for doc, _ in unique_docs: print(f"- {doc}")
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 文档去重(TF-IDF,MinHash, SimHash)

发表评论 取消回复