章节内容
上一节我们完成了:
- Hive中数据导出:HDFS
- HQL操作
- 上传内容至Hive、增删改查等操作
背景介绍
这里是三台公网云服务器,每台 2C4G,搭建一个Hadoop的学习环境,供我学习。
之前已经在 VM 虚拟机上搭建过一次,但是没留下笔记,这次趁着前几天薅羊毛的3台机器,赶紧尝试在公网上搭建体验一下。
注意,如果你和我一样,打算用公网部署,那一定要做好防火墙策略,避免不必要的麻烦!!!
请大家都以学习为目的,也请不要对我的服务进行嗅探或者攻击!!!
但是有一台公网服务器我还运行着别的服务,比如前几天发的:autodl-keeper 自己写的小工具,防止AutoDL机器过期的。还跑着别的Web服务,所以只能挤出一台 2C2G 的机器。那我的配置如下了:
- 2C4G 编号 h121
- 2C4G 编号 h122
- 2C2G 编号 h123

Metastore
在Hive具体的使用中,首先面临的问题是如何定义表结构信息和结构化的数据映射成功。
所谓的映射指的是一种对应关系。在Hive中需要描述清楚表和文件之间的映射关系、列和字段之间的关系等等信息。
这描述映射关系的数据称为Hive的元数据。
所以此数据很重要,因为只有通过查询它才可以确定用户编写SQL和最终操作文件之间的关系。
Metastore三种形式
内嵌模式
内嵌模式是使用Derby数据库来存储元数据,而不需要额外起Metastore服务。数据库和Metastore服务都嵌入在主HiveServer进程中。
该方案为默认,但一次只能和一个客户端连接,适合实验,不适合生产。
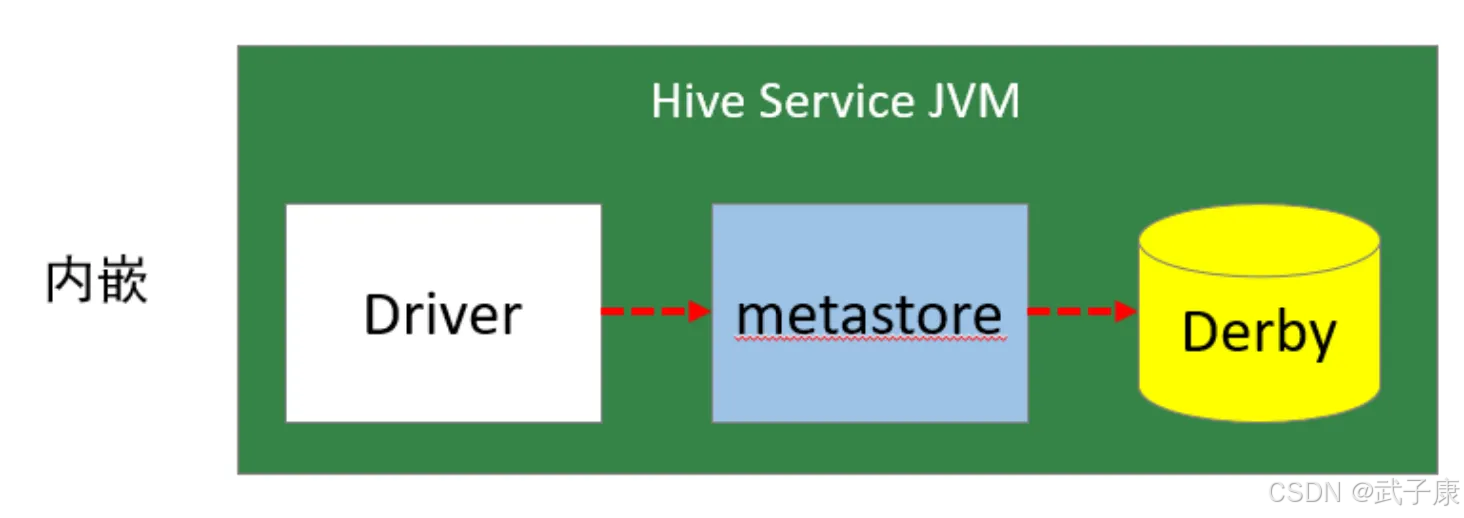
本地模式
本地模式不需要单独启动Metastore服务,而是和Hive在同一个进程里的Metastore服务。也就是说当启动Hive服务时,内部会启动一个Metastore服务。
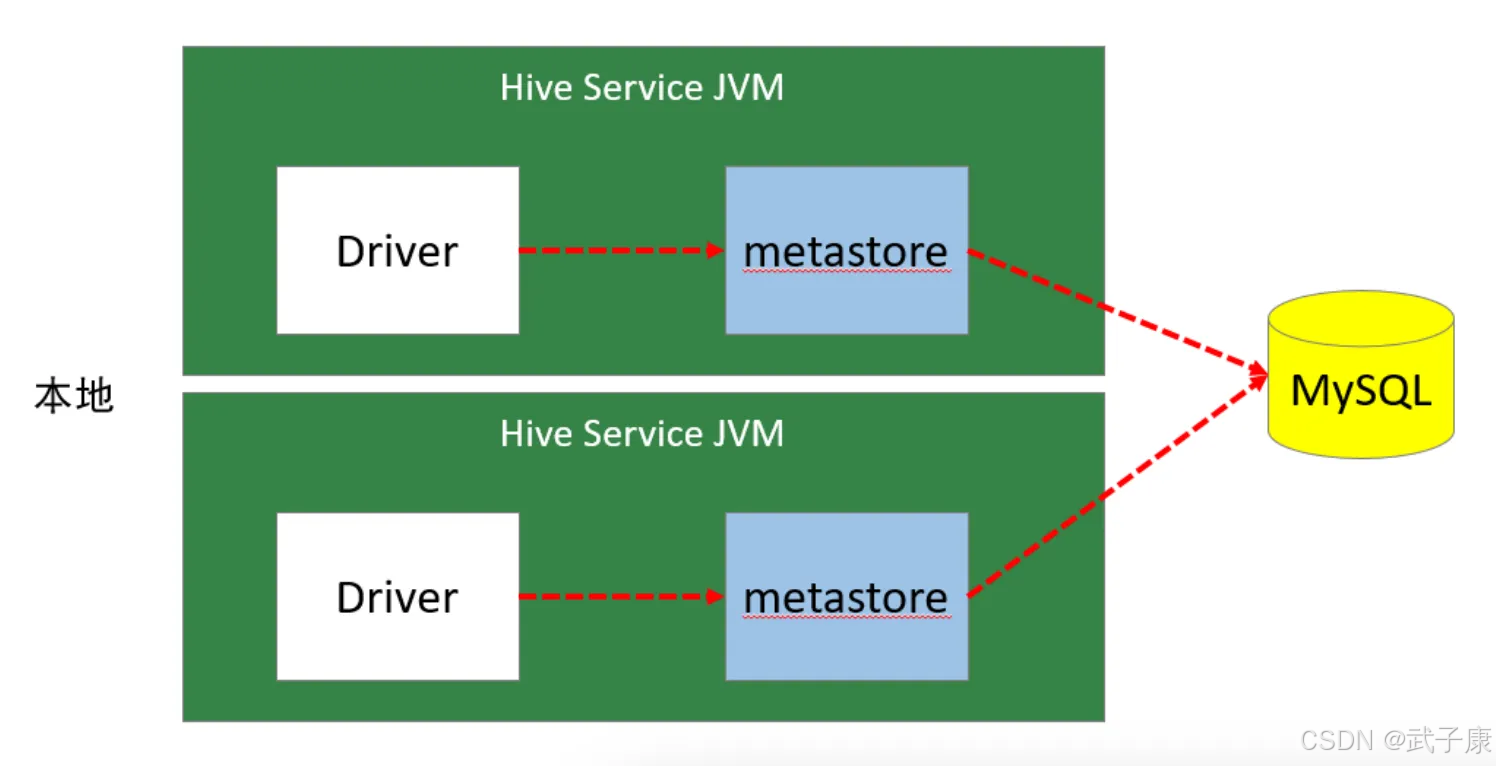
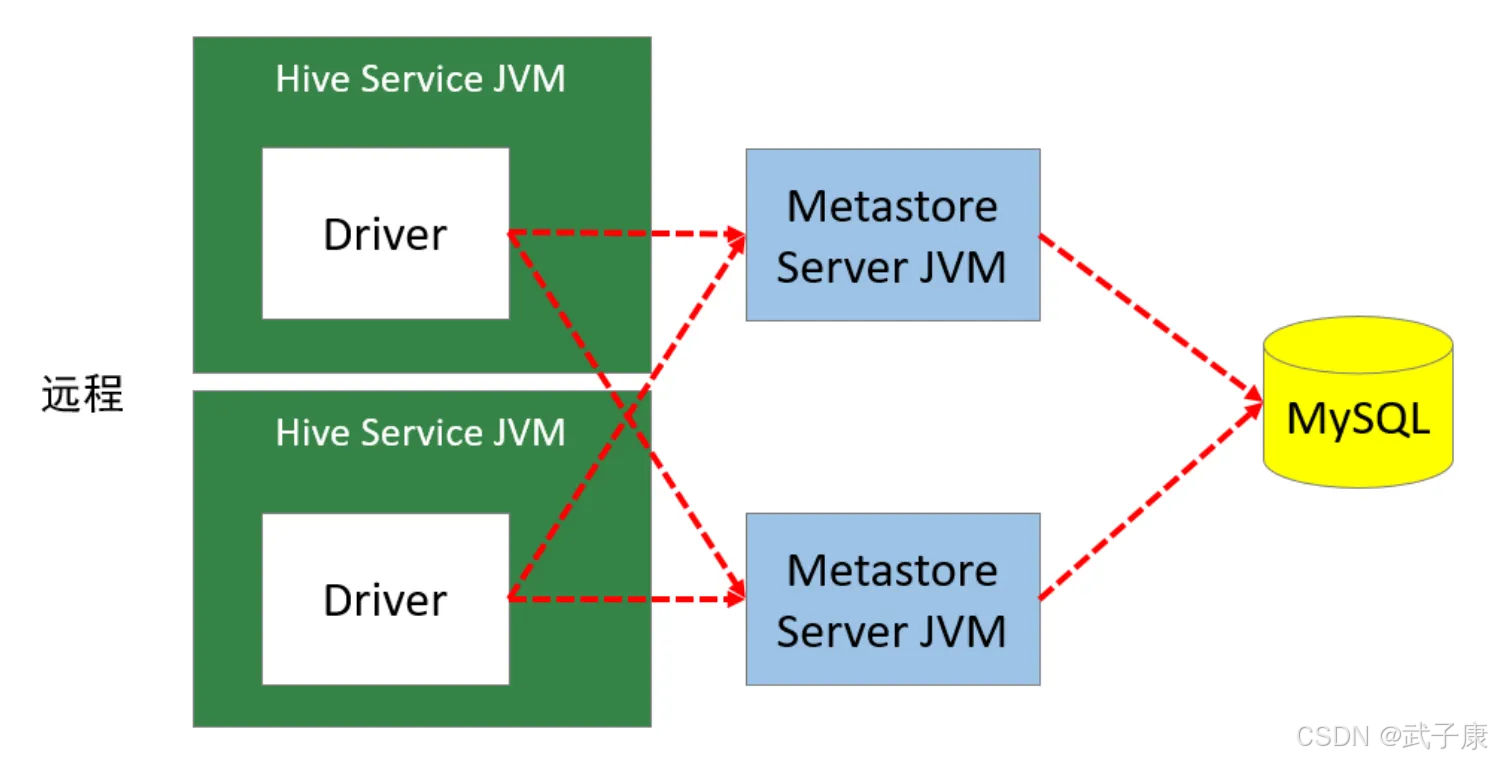
远程模式
远程模式下,需要的单独运行 Metastore服务,每个客户端都在配置文件里配置连接到该Metastore的信息。(推荐生产环境使用)
配置环境
集群规划

同步文件
之前我们完成了单节点的 Hive 部署和测试,现在要改成多集群的。
你可以使用类似于下面的方式,将 Hive 的安装包等内容发送到别的节点上。
将之前的 Hive 文件拷贝到 h121、h122、h123中。
也就是现在要求我们集群中的三台节点都要拥有Hive环境
你可以通过类似于 SCP 的指令完成文件的传输,或者用脚本分发工具也可以。
scp apache-hive-2.3.9-bin.tar.gz root@h121.wzk.icu:/opt/software
确保你的三台机器都有了Hive的环境,同时不要忘记配置环境变量。
你需要回到之前的章节,完整一系列的配置。不然后续无法进行。
h121节点
h122节点
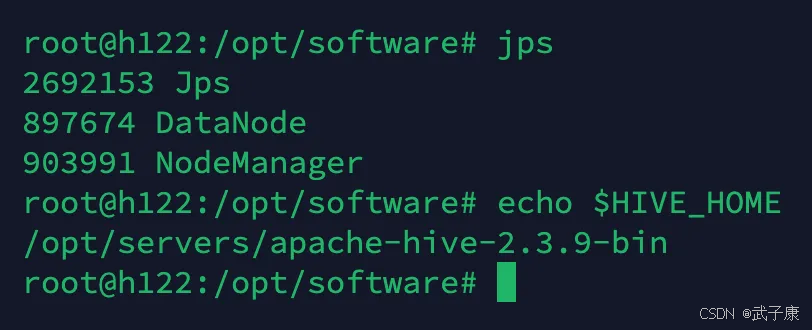
h123节点
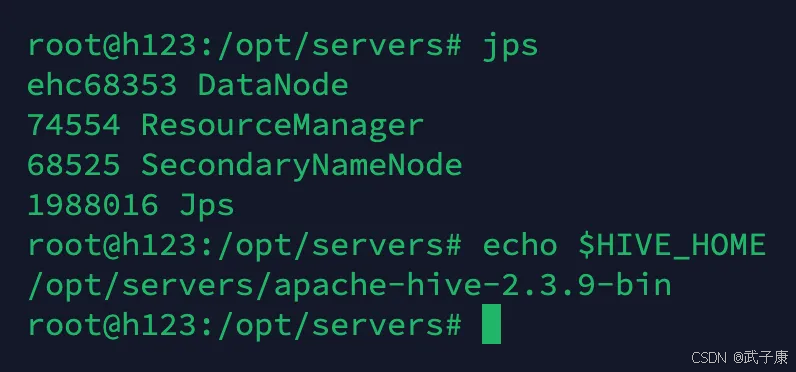
配置注意
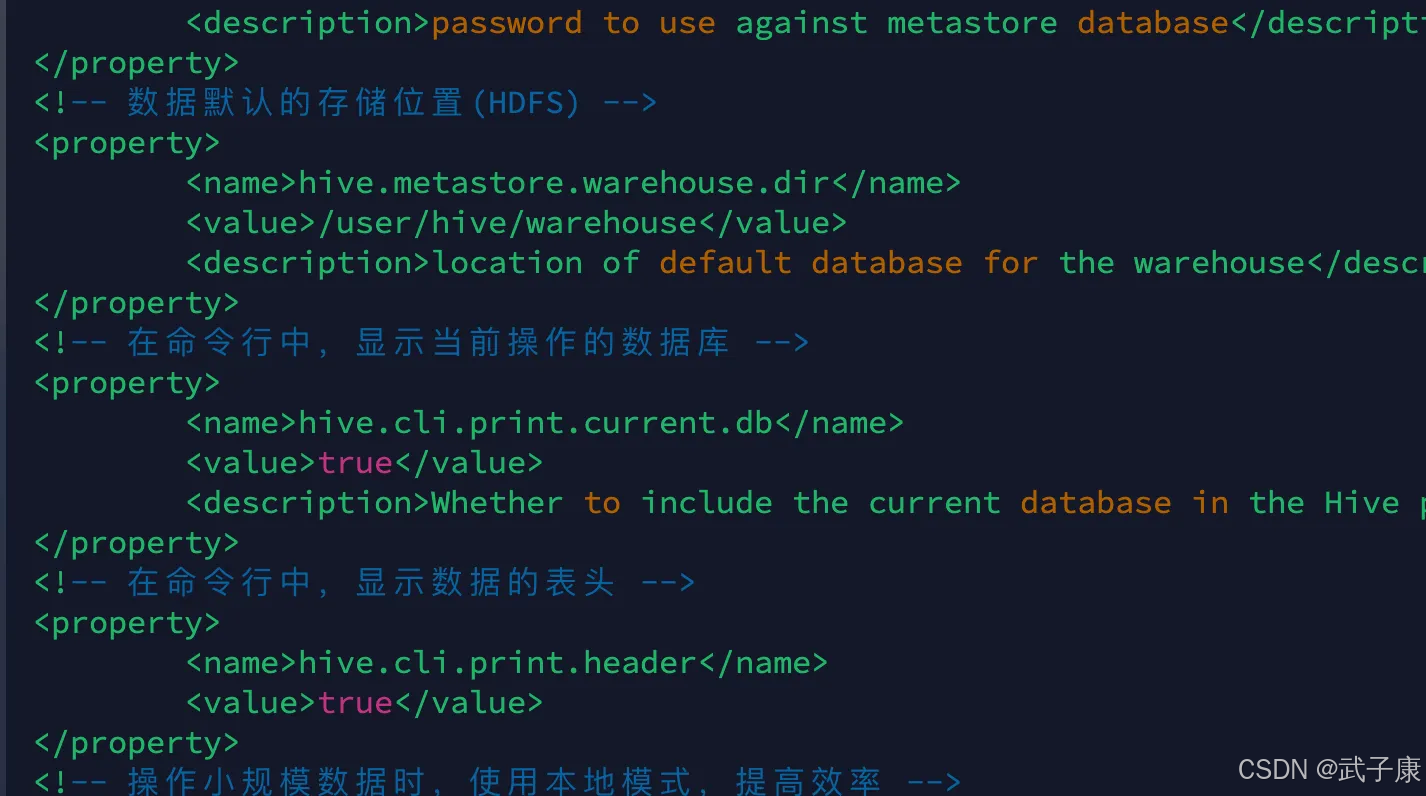
这里多唠叨几句,h121、h122、h123的 hive-site.xml 的内容是一样的。
- Hive 环境变量!!!
- hive-site.xml 配置一样!!!
- JDBC 驱动也别忘了!!!
启动服务
h121 & h123
在 h121 和 h123 上启动 MetaData 服务
# 启动 metastore 服务
nohup hive --service metastore &
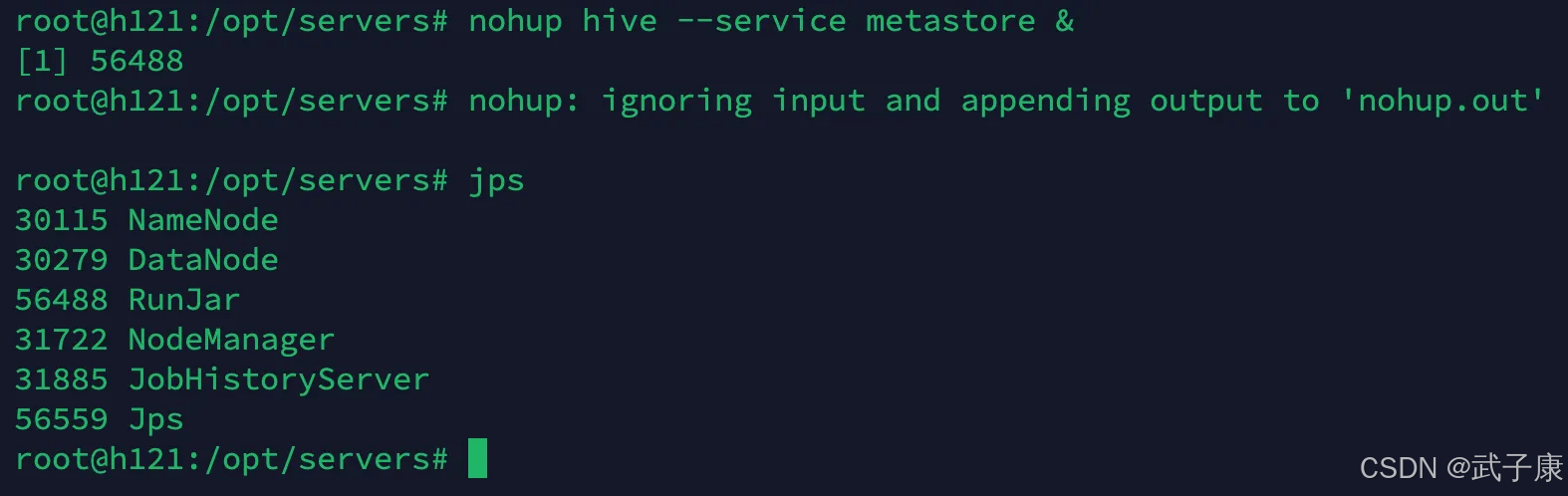
# 查询9083端口(metastore服务占用的端口)
lsof -i:9083
可以看到服务已经正常的启动了, 查询到了端口服务。

h122
<!-- hive metastore 服务地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://h121.wzk.icu:9083,thrift://h123.wzk.icu:9083</value>
</property>
此时我们在 h122 上启动 Hive
hive
SELECT * FROM emp;
查看连接
我们分别在 h121、h122、h123 上查看端口的信息
lsof -i:9083

本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Hadoop-15-Hive 元数据管理与存储 Metadata 内嵌模式 本地模式 远程模式 集群规划配置 启动服务 3节点云服务器实测

发表评论 取消回复