摘要
本文全面回顾了深度学习中激活函数的发展历程,从早期的Sigmoid和Tanh函数,到广泛应用的ReLU系列,再到近期提出的Swish、Mish和GeLU等新型激活函数。深入分析了各类激活函数的数学表达、特点优势、局限性以及在典型模型中的应用情况。通过系统的对比分析,本文探讨了激活函数的设计原则、性能评估标准以及未来可能的发展方向,为深度学习模型的优化和设计提供理论指导。
1. 引言
激活函数是神经网络中的关键组件,它在神经元的输出端引入非线性特性,使得神经网络能够学习和表示复杂的非线性映射。没有激活函数,无论多么深的神经网络本质上都只能表示线性变换,这大大限制了网络的表达能力。
随着深度学习的快速发展,激活函数的设计和选择已成为影响模型性能的重要因素。不同的激活函数具有不同的特性,如梯度流动性、计算复杂度、非线性程度等,这些特性直接影响着神经网络的训练效率、收敛速度和最终性能。
本文旨在全面回顾激活函数的演变历程,深入分析各类激活函数的特性,并探讨其在现代深度学习模型中的应用。我们将从以下几个方面展开讨论:
- 经典激活函数:包括Sigmoid、Tanh等早期常用的激活函数。
- ReLU及其变体:包括ReLU、Leaky ReLU、PReLU、ELU等。
- 新型激活函数:如Swish、Mish、GeLU等近期提出的函数。
- 特殊用途的激活函数:如Softmax、Maxout等。
- 激活函数的比较与选择:讨论不同场景下激活函数的选择策略。
- 未来展望:探讨激活函数研究的可能发展方向。
通过这一系统的回顾和分析,希望能为研究者和实践者提供一个全面的参考,帮助他们在深度学习模型设计中更好地选择和使用激活函数。
2. 经典激活函数
2.1 Sigmoid函数
Sigmoid函数是最早被广泛使用的激活函数之一,其数学表达式为:
σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1 + e^{-x}} σ(x)=1+e−x1
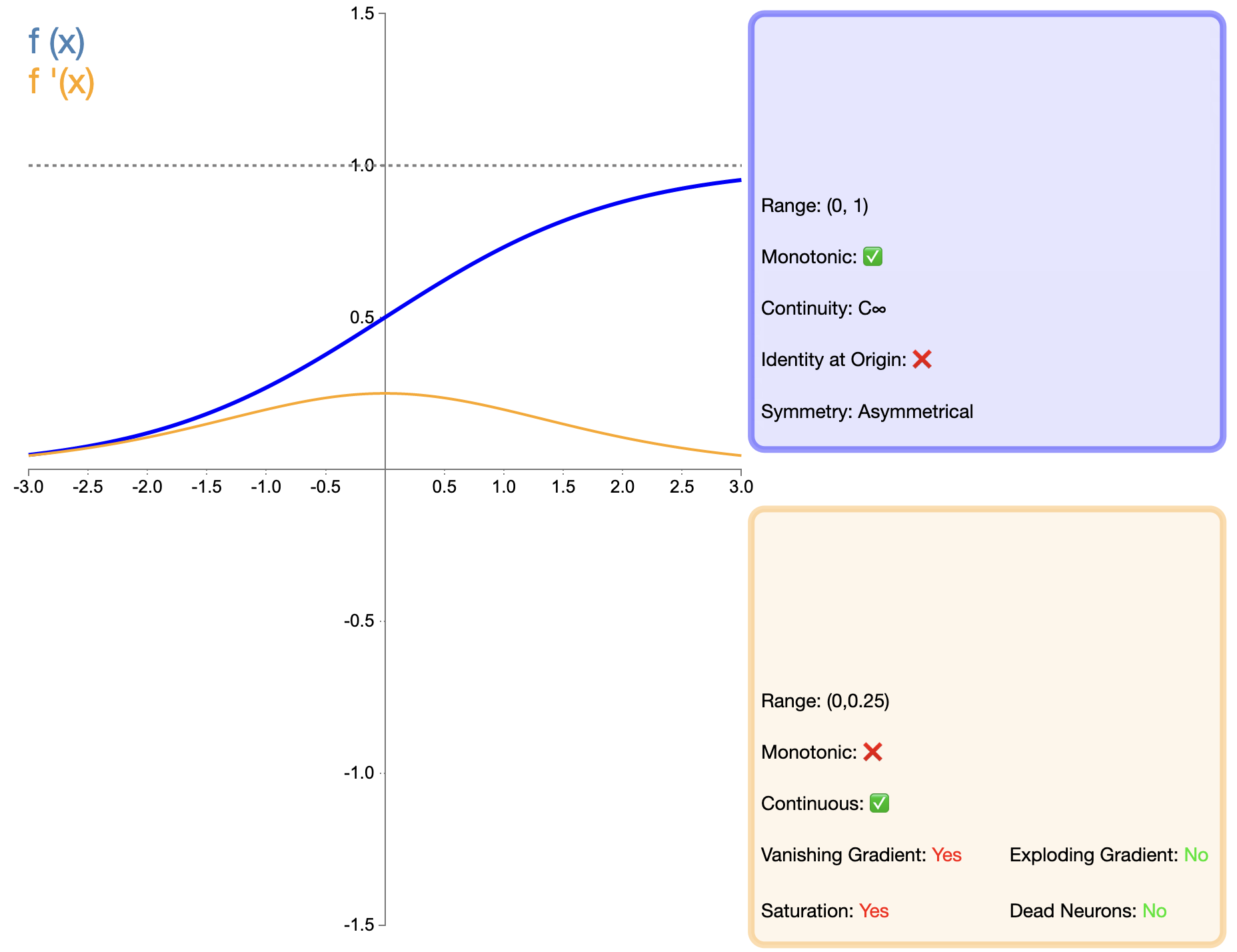
特点与优点:
- 输出范围有界:Sigmoid函数的输出范围在(0, 1)之间,这使其特别适合于处理概率问题。
- 平滑可导:函数在整个定义域内都是平滑且可导的,这有利于梯度下降算法的应用。
- 解释性强:输出可以被解释为概率,特别适用于二分类问题的输出层。
缺点与限制:
- 梯度消失问题:当输入值很大或很小时,梯度接近于零,这会导致深层网络中的梯度消失问题。
- 输出非零中心:Sigmoid的输出均为正值,这可能会导致后一层神经元的输入总是正的,影响模型的收敛速度。
- 计算复杂度:涉及指数运算,计算复杂度相对较高。
适用场景:
- 早期的浅层神经网络。
- 二分类问题的输出层。
- 需要将输出限制在(0, 1)范围内的场景。
与其他函数的对比:
相比于后来出现的ReLU等函数,Sigmoid在深度网络中的应用受到了很大限制,主要是因为其梯度消失问题。然而,在某些特定任务(如二分类)中,Sigmoid仍然是一个有效的选择。
2.2 Tanh函数
Tanh(双曲正切)函数可视为Sigmoid函数的改进版本,其数学表达式为:
tanh ( x ) = e x − e − x e x + e − x \tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} tanh(x)=ex+e−xex−e−x
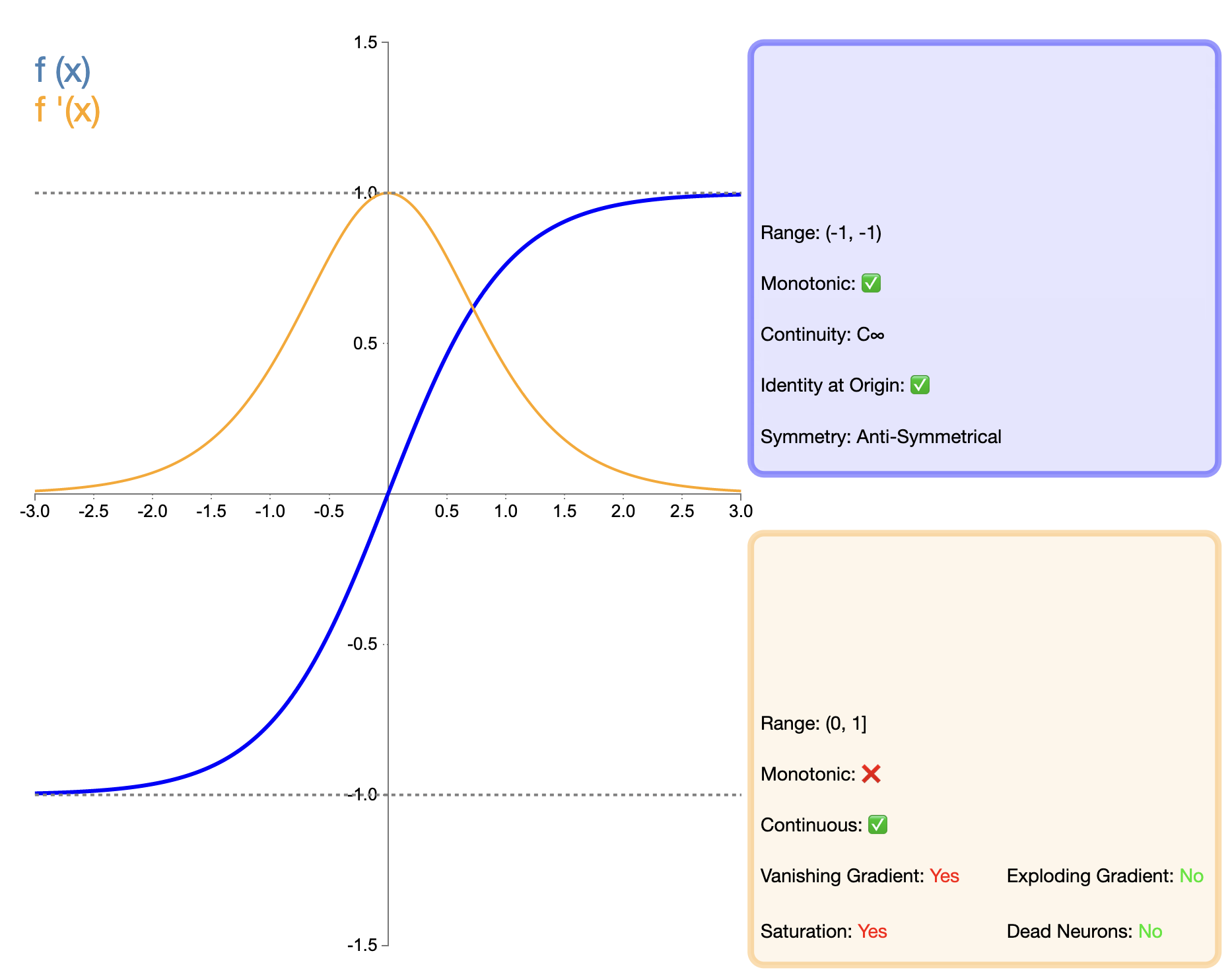
特点与优点:
- 零中心输出:Tanh函数的输出范围在(-1, 1)之间,解决了Sigmoid的非零中心问题。
- 梯度更强:在输入接近零的区域,Tanh函数的梯度比Sigmoid函数更大,有助于加快学习速度。
- 平滑可导:与Sigmoid类似,Tanh也是平滑且可导的。
缺点与限制:
- 梯度消失问题:虽然比Sigmoid有所改善,但Tanh在输入值较大或较小时仍然存在梯度消失的问题。
- 计算复杂度:与Sigmoid类似,Tanh也涉及指数运算,计算复杂度较高。
适用场景:
- 在需要零中心化输出的场景中优于Sigmoid。
- 在循环神经网络(RNN)和长短时记忆网络(LSTM)中经常使用。
- 在一些归一化输出很重要的场景中使用。
改进与对比:
Tanh函数可以看作是Sigmoid函数的改进版本,主要改进在于输出的零中心化。这一特性使得Tanh在许多情况下比Sigmoid表现更好,特别是在深度网络中。然而,与后来出现的ReLU等函数相比,Tanh仍然存在梯度消失的问题,在非常深的网络中可能会影响模型的性能。
Sigmoid和Tanh这两个经典的激活函数在深度学习早期发挥了重要作用,它们的特性和局限性也推动了后续激活函数的发展。虽然在很多场景下已经被更新的激活函数所替代,但在特定的任务和网络结构中,它们仍然有其独特的应用价值。
3. ReLU及其变体
3.1 ReLU (Rectified Linear Unit)
ReLU函数的提出是激活函数发展的一个重要里程碑。其数学表达式简单:
ReLU ( x ) = max ( 0 , x ) \text{ReLU}(x) = \max(0, x) ReLU(x)=max(0,x)
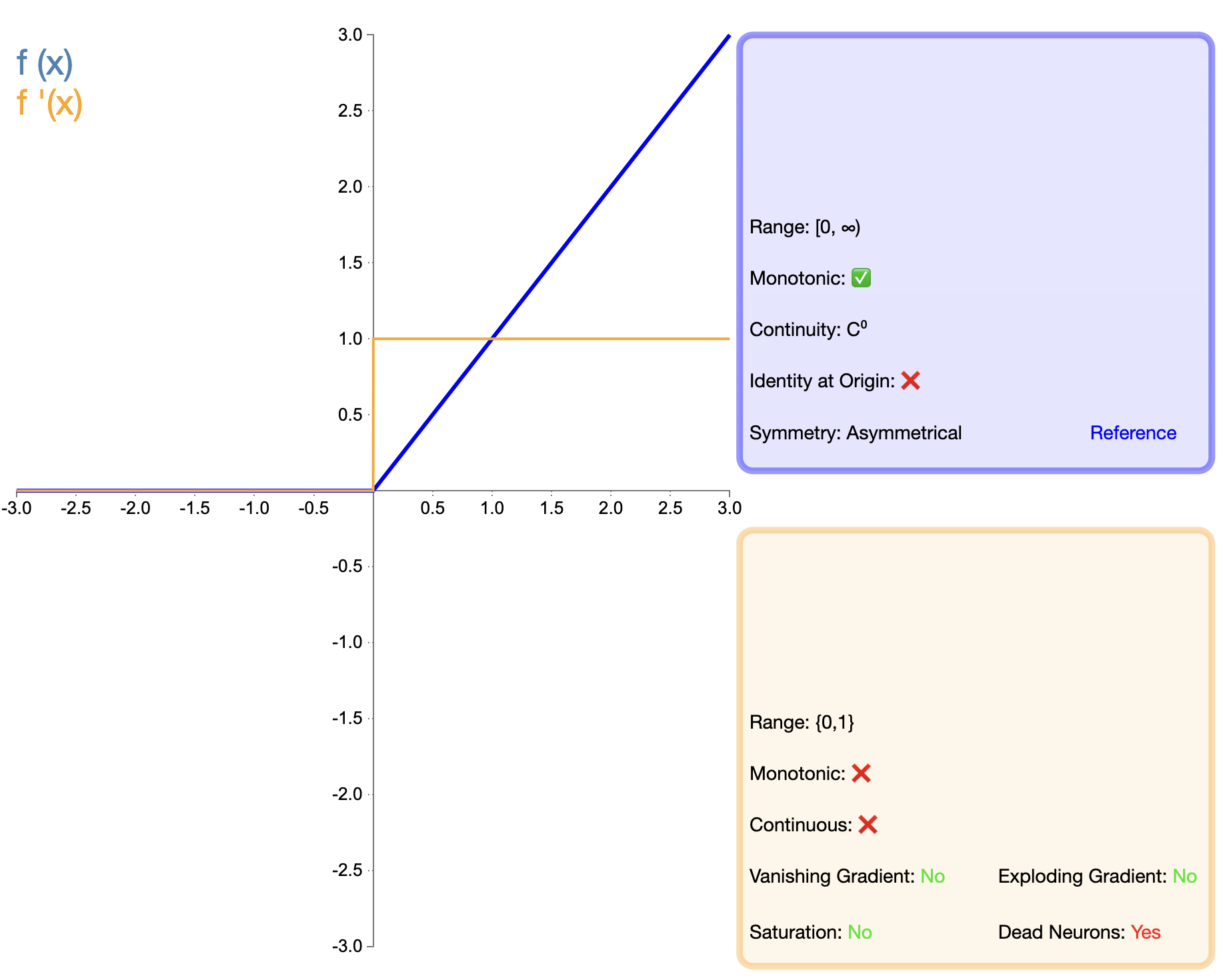
特点与优点:
- 计算简单:ReLU的计算复杂度远低于Sigmoid和Tanh,有利于加速网络训练。
- 缓解梯度消失:对于正输入,ReLU的梯度恒为1,有效缓解了深层网络中的梯度消失问题。
- 稀疏激活:ReLU可以使一部分神经元的输出为0,导致网络的稀疏表达,这在某些任务中是有益的。
- 生物学解释:ReLU的单侧抑制特性与生物神经元的行为相似。
缺点与限制:
- "死亡ReLU"问题:当输入为负时,梯度为零,可能导致神经元永久失活。
- 非零中心输出:ReLU的输出均为非负值,这可能会影响下一层的学习过程。
适用场景:
- 深度卷积神经网络(如ResNet, VGG)中广泛使用。
- 适用于大多数前馈神经网络。
与其他函数的对比:
相比Sigmoid和Tanh,ReLU在深度网络中表现出显著优势,主要体现在训练速度和缓解梯度消失方面。然而,"死亡ReLU"问题促使研究者们提出了多种改进版本。
3.2 Leaky ReLU
为了解决ReLU的"死亡"问题,Leaky ReLU被提出:
Leaky ReLU ( x ) = { x , if x > 0 α x , if x ≤ 0 \text{Leaky ReLU}(x) = \begin{cases} x, & \text{if } x > 0 \\ \alpha x, & \text{if } x \leq 0 \end{cases} Leaky ReLU(x)={
x,αx,if x>0if x≤0
其中, α \alpha α 是一个小的正常数,通常取0.01。
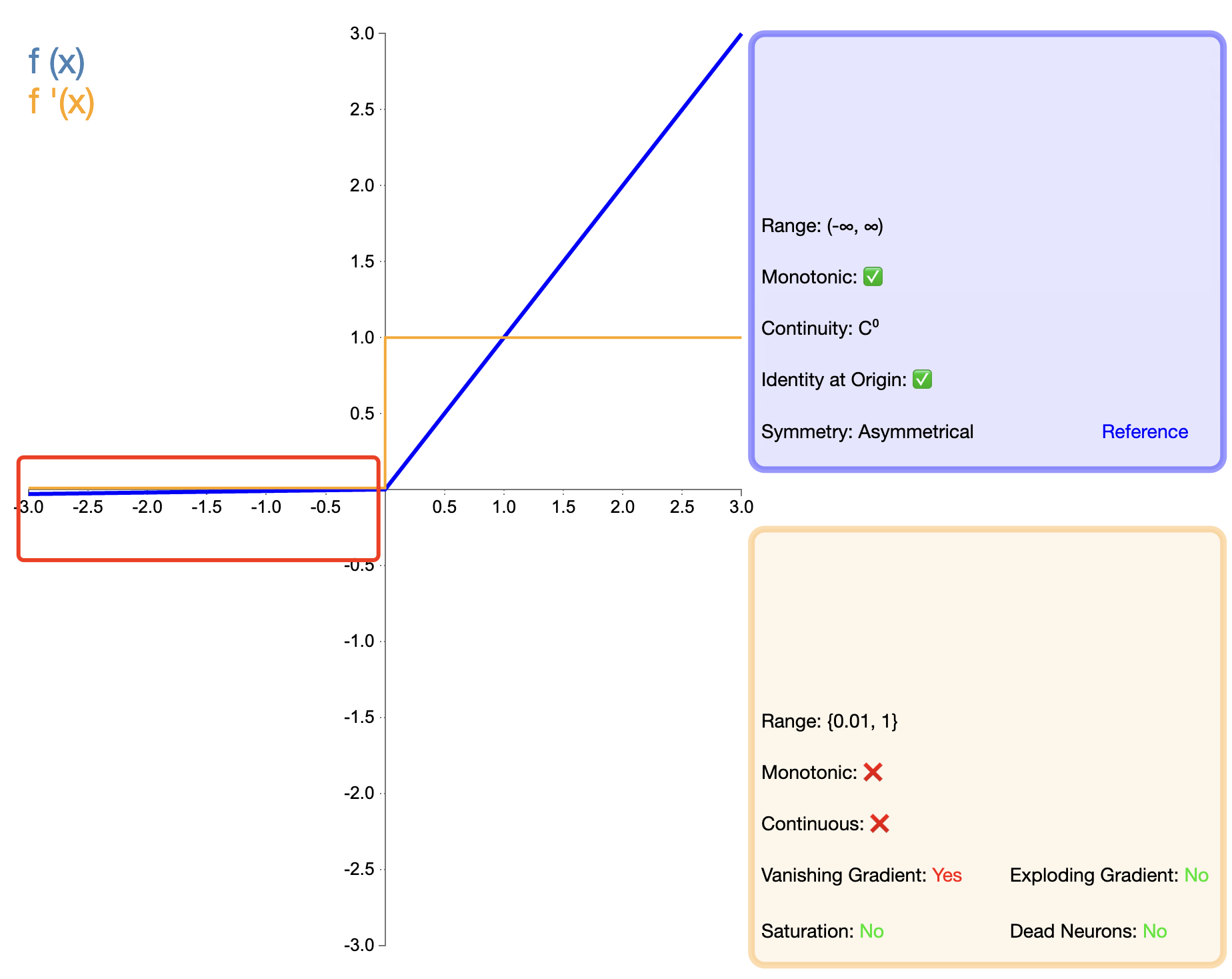
特点与优点:
- 缓解"死亡ReLU"问题:在输入为负时仍然保留一个小的梯度,避免神经元完全失活。
- 保留ReLU的优点:在正半轴保持线性,计算简单,有助于缓解梯度消失。
缺点与限制:
- 引入超参数: α \alpha α值的选择需要调优,增加了模型复杂度。
- 非零中心输出:与ReLU类似,输出仍然不是零中心的。
适用场景:
- 在ReLU表现不佳的场景中作为替代选择。
- 在需要保留一些负值信息的任务中使用。
3.3 PReLU (Parametric ReLU)
PReLU是Leaky ReLU的一个变体,其中负半轴的斜率是可学习的参数:
PReLU ( x ) = { x , if x > 0 α x , if x ≤ 0 \text{PReLU}(x) = \begin{cases} x, & \text{if } x > 0 \\ \alpha x, & \text{if } x \leq 0 \end{cases} PReLU(x)={
x,αx,if x>0if x≤0
这里的 α \alpha α 是通过反向传播学习得到的参数。
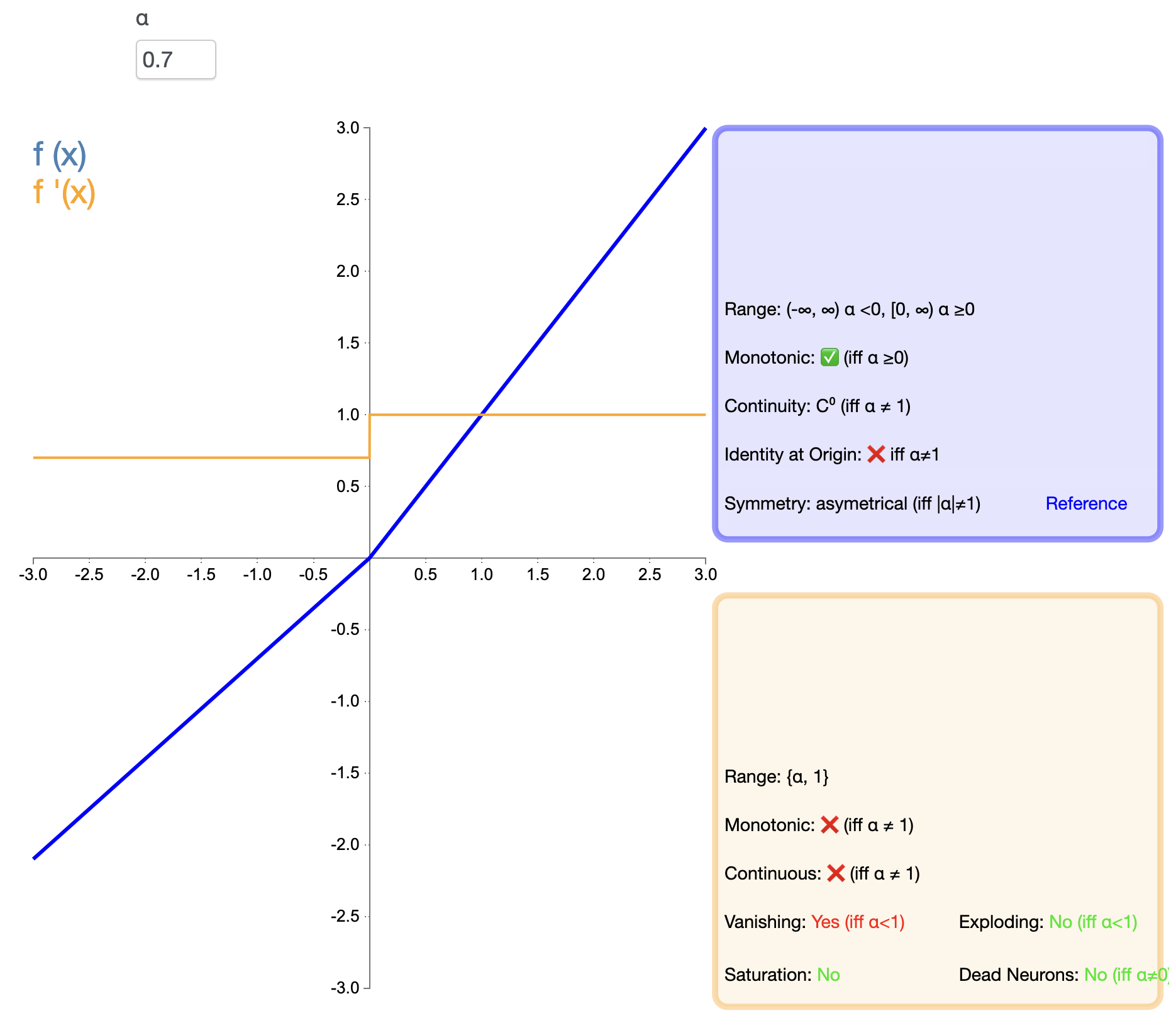
特点与优点:
- 自适应学习:可以根据数据自动学习最适合的负半轴斜率。
- 性能潜力:在某些任务中,PReLU可以获得比ReLU和Leaky ReLU更好的性能。
缺点与限制:
- 增加模型复杂度:引入额外的可学习参数,增加了模型的复杂度。
- 可能过拟合:在某些情况下,可能导致过拟合,特别是在小数据集上。
适用场景:
- 大规模数据集上的深度学习任务。
- 需要自适应激活函数的场景。
3.4 ELU (Exponential Linear Unit)
ELU试图结合ReLU的优点和负值输入的处理,其数学表达式为:
ELU ( x ) = { x , if x > 0 α ( e x − 1 ) , if x ≤ 0 \text{ELU}(x) = \begin{cases} x, & \text{if } x > 0 \\ \alpha(e^x - 1), & \text{if } x \leq 0 \end{cases} ELU(x)=
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 深度学习中激活函数的演变与应用:一个综述

发表评论 取消回复