正则表达式

为什么要学习正则表达式
1.新建java项目chapter27
2.新建E:\idea_project\zzw_javase\idea_java_project\chapter27\src\com\zzw\regexp\Regexp_.java
public class Regexp_ {
public static void main(String[] args) {
String content = "私有地址(Private address)属于非注册地址,专门为组织机构内部使用。\n" +
"以下列出留用的内部私有地址\n" +
"A类 10.0.0.0--10.255.255.255\n" +
"B类 172.16.0.0--172.31.255.255\n" +
"C类 192.168.0.0--192.168.255.255";
//1.先创建一个Pattern对象(模式对象), 可以理解成就是一个正则表达式对象
//(1)提取文章中所有的英文单词 -> 传统方法, 使用遍历, 代码量大
Pattern pattern = Pattern.compile("[a-zA-Z]+");
//(2)提取文章中所有的数字
//Pattern pattern = Pattern.compile("[0-9]+");
//(3)提取文章中所有的英文单词和数字
//Pattern pattern = Pattern.compile("[a-zA-Z0-9]+");
//2.创建一个匹配器对象
// matcher 匹配器按照 pattern(模式/样式) 到content中去查找/匹配
Matcher matcher = pattern.matcher(content);
//3.开始循环匹配
while (matcher.find()) {
//匹配内容/文本, 放到matcher.group(0)
System.out.println("找到: " + matcher.group(0));
}
}
}
3.结论:正则表达式是处理文本的利器.
再提几个问题
1.给你一个字符串(或文章), 请你找你所有四个数字连在一起的子串?
2.给你一个字符串(或文章), 请你找出所有四个数字连在一起的子串, 并且这四个数字要满足: 第一位与第四位相同, 第二位与第三位相同. 比如: 1221, 3443.
3.请验证输入的邮件, 是否符合电子邮件格式.
4.请验证输入的手机号, 是否符合手机号格式.
解决之道-正则表达式
1.为了解决上述问题, Java提供了正则表达式技术, 专门用于处理类似文本问题.
2.简单地说: 正则表达式是对字符串执行模式匹配的技术.
3.正则表达式: regular expression => RegExp
正则表达式基本介绍
介绍
1.一个正则表达式, 就使用某种模式去匹配字符串的一个公式. 很多人认为它们看上去比较古怪而且复杂所以不敢去使用. 不过, 经过练习后, 就觉得这些复杂的表达式写起来还是相当简单的, 而且, 一旦你弄懂它们, 你就能把数小时辛苦而且易错的文本处理工作缩短在几分钟(甚至几秒钟)内完成.
2.这里特别强调, 正则表达式不是只有java才有, 实际上很多编程语言都支持正则表达式进行字符串操作!
正则表达式底层实现
实例分析
需求: 为了让大家对正则表达式底层实现有一个直观的印象, 给大家举个实例. 给你一段字符串(文本), 请找出所有四个数字连在一起的子串. 比如, 应该找到 2000, 1998, 2012, 2020.
分析底层实现
1.新建src/com/zzw/regexp/RegTheory.java
//分析java正则表达式的底层实现
public class RegTheory {
public static void main(String[] args) {
String content = "1998 年 12 月 8 日,第二代 Java 平台的企业版 J2EE 发布。1999 年 6 月,Sun 公司发布了\" +\n" +
"\"第二代 Java 平台(简称为 Java2)的 3 个版本:J2ME(Java2 Micro Edition,Java2 平台的微型\" +\n" +
"\"版),应用于移动、无线及有限资源的环境;J2SE(Java 2 Standard Edition,Java 2 平台的\" +\n" +
"\"标准版),应用于桌面环境;J2EE(Java 2Enterprise Edition,Java 2 平台的企业版),应\" +\n" +
"\"用 3443 于基于 Java 的应用服务器。Java 2 平台的发布,是 Java 发展过程中最重要的一个\" +\n" +
"\"里程碑,标志着 Java 的应用开始普及 9889 \"";
//目标: 匹配所有四个数字
//说明
//1. \\d表示一个任意的数字
String regStr = "(\\d\\d)(\\d\\d)";
//2. 创建模式对象[即正则表达式对象]
Pattern pattern = Pattern.compile(regStr);
//3. 创建匹配器
//说明: 创建匹配器 matcher, 按照正则表达式的规则 去匹配 content 字符串
Matcher matcher = pattern.matcher(content);
//4. 开始循环匹配
/**
* matcher.find() 完成的任务(这里考虑分组)
* 什么是分组, 比如 (\d\d)(\d\d), 正则表达式中有()表示分组, 第1个()表示第1组, 第2个()表示第2组...
* 1.根据指定的规则, 定位满足规则的子字符串(比如(19)(98))
* 2.找到后, 将子字符串的开始与结束的索引, 记录到 matcher 对象的属性 int[] groups;
* (1) groups[0] = 0, 把该子字符串(1998)结束的索引+1 的值记录到 groups[1] = 4
* (2) 记录第1组()匹配到的字符串 groups[2] = 0, gourps[3] = 2
* (3) 记录第2组()匹配到的字符串 groups[4] = 2, groups[5] = 4
* (4) 如果有更多的分组...
* 3.同时记录oldLast的值为 子字符串的结束的索引+1的值, 即 4, 即下次执行find时, 就从 4 开始匹配
*
* matcher.group(0)分析
* 源码:
* public String group(int group) {
* if (first < 0)
* throw new IllegalStateException("No match found");
* if (group < 0 || group > groupCount())
* throw new IndexOutOfBoundsException("No group " + group);
* if ((groups[group*2] == -1) || (groups[group*2+1] == -1))
* return null;
* return getSubSequence(groups[group * 2], groups[group * 2 + 1]).toString();
* }
* 1.根据groups[0]=0 和 groups[1]=4 记录的位置, 从content开始到截取子字符串返回
* , 就是[0,4) 包含0但是不包含索引为35的位置
*
* 2.如果再次指向 find 方法, 仍然按上面分析来执行
*/
while (matcher.find()) {
/**
* 小结
* 1.如果正则表达式有(), 即分组
* 2.去除匹配的字符串规则如下
* (1)group(0) 表示匹配到的子字符串
* (2)group(1) 表示匹配到的子字符串的第一组子串
* (3)group(2) 表示匹配到的子字符串的第二组子串
* (4)分组的数不能越界...
*/
System.out.println("找到: " + matcher.group(0));
System.out.println("第1组()匹配到的值=" + matcher.group(1));
System.out.println("第2组()匹配到的值=" + matcher.group(2));
}
}
}


正则表达式语法
基本介绍
如果要想灵活地运用正则表达式,必须了解其中各种元字符的功能,元字符从功能上大致分为:
1.限定符
2.选择匹配符
3.分组组合和反向引用符
4.特殊字符
5.字符匹配符
6.定位符
元字符-转义号 \\
\\ 符号 说明: 在我们使用正则表达式去检索某些特殊字符的时候,需要用到转义符号, 否则检索不到结果,甚至会报错的。
案例:用 $ 去匹配 “abc$(” 会怎样?
提示: 在Java正则表达式中, 两个 \\ 代表其它语言中的一个 \
1.新建src/com/zzw/regexp/RegExp02.java
//演示转义字符的使用
public class RegExp02 {
public static void main(String[] args) {
String content = "abc$(a.bc(123( )";
//匹配 ( => \\(
//String regStr = "\\(";
//匹配 . => \\.
//String regStr = "\\.";
//匹配 3个数字 => \\d\\d\\d
//String regStr = "\\d\\d\\d";
String regStr = "\\d{3}";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
System.out.println("找到: " + matcher.group(0));
}
}
}
2.需要用到转移符号的字符有以下: . * + ( ) $ / \ ?[ ] ^ { }
元字符-字符匹配符
| 符号 | 含义 | 示例 | 解释 |
|---|---|---|---|
| [ ] | 可接收的字符列表 | [abcd] | a、b、c、d中的任意一个字符 |
| [ ^ ] | 不可接收的字符列表 | [^abcd] | 除a、b、c、d外的任意一个字符(包括数字和特殊符号) |
| - | 连字符 | A-Z | 任意单个大写字母 |
| 符号 | 含义 | 示例 | 解释 | 匹配输入 |
|---|---|---|---|---|
| . | 匹配除 \n 以外的任何字符 | a..b | 以a开头,b结尾,中间包括2个 任意字符的长度为4的字符串 | accb, a22b, a$#b |
| \\d | 匹配单个数字字符, 相当于[0-9] | \d{3}(\d)? | 包含3个或4个数字的字符串 | 123,1234 |
| \\D | 匹配单个非数字字符, 相当于[^0-9] | \\D(\\d)* | 以单个非数字字符开头,后接 任意个数字字符串 | e1231, E332 |
| \\w | 匹配单个数字, 大小写字母字符,相当于[0-9a-zA-Z] | \d{3}\w{4} | 以3个数字字符开头的 长度为7的数字字符串 | 123qwer, 12345qw |
| \\W | 匹配单个非数字,大小写字母字符,相当于[^0-9a-zA-Z] | \\W+\\d{2} | 以至少一个非数字字母开头,2个 数字字符结尾的字符串 | #12, #$#@32 |
1.新建src/com/zzw/regexp/RegExp03.java
//演示字符匹配符的使用
public class RegExp03 {
public static void main(String[] args) {
String content = "a11c8abc _ABCy @";
//String regStr = "[a-z]";//匹配a-z之间任意一个字符
//String regStr = "[A-Z]";//匹配A-Z之间任意一个字符
//String regStr = "abc";//匹配abc字符串[默认区分大小写]
//(?i) 是一个模式修饰符,表示不区分大小写(ignore case)
//String regStr = "(?i)abc";//匹配abc字符串[不区分大小写]
//String regStr = "[0-9]";//匹配0-9之间任意一个字符
//String regStr = "[^a-z]";//匹配不在a-z之间任意一个字符
//String regStr = "[^0-9]";//匹配不在0-9之间任意一个字符
//String regStr = "[abcd]";//匹配abcd中任意一个字符
//String regStr = "\\D";//匹配不在0-9的任意一个字符
//String regStr = "\\w";//匹配一个大小写英文字母,数字,下划线
//String regStr = "\\W";//匹配,等价于[^0-9a-zA-Z]
//String regStr = "\\s";//\\s 匹配任何空白字符(空格,制表符等)
//String regStr = "\\S";//\\S 匹配任何非空白字符,和\\s相反
String regStr = ".";// . 匹配除\n之外的所有单个字符, 如果要匹配本身则使用\\.
//注意: 当创建Pattern对象时, 指定 Pattern.
Pattern pattern = Pattern.compile(regStr, Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
System.out.println("找到: " + matcher.group(0));
}
}
}
注意:
String regStr = "."只会匹配一个字符
String regStr = ".*"则会匹配任意个字符
元字符-选择匹配符
在匹配某个字符串的时候是选择性的,即:即可以匹配这个,有可以匹配那个,这时需要使用到 选择匹配符号 |
1.新建src/com/zzw/regexp/RegExp04.java
//演示选择匹配符的使用
public class RegExp04 {
public static void main(String[] args) {
String content = "abcde赵志伟love赵培竹";
String regStr = "赵|伟|培|竹";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
System.out.println("找到: " + matcher.group(0));
}
}
}
输出
找到: 赵
找到: 伟
找到: 赵
找到: 培
找到: 竹
元字符-限定符
用于指定其前面的字符和组合连续出现多少次
| 符号 | 含义 | 示例 | 解释 | 匹配输入 |
|---|---|---|---|---|
| * | 指定字符重复0次或n次(无要求,零到多) | (abc)* | 仅包含任意个abc的字符串, 等效于\w* | abc, abcabca |
| + | 指定字符重复1次或n次(至少一次, 一到多) | m+(abc)* | 以至少一个m开头, 后接 任意个abc的字符串 | m,mabc,mabcabc |
| ? | 指定字符重复0次或1次(最多一次, 零到一) | m+abc? | 以至少一个m开头, 后接ab或abc的字符串 | mab, mabc,mmab, mmabc |
| {n} | 只能输入n个字符 | [abcd]{3} | 由abcd中任意字母组成的 长度为3的字符串 | aac, dbc, adc |
| {n,} | 至少指定n个匹配 | [abcd]{3,} | 由abcd中任意字母组成的 长度不小于3的字符串 | aab, dbc, abcada |
| {n,m} | 指定至少n个但不多于m个匹配 | [abcd]{3,5} | 由abcd中任意字母组成的长度 不小于3,不大于5的字符串 | abc, abcd, abaaa, bbbbb |
1.新建src/com/zzw/regexp/RegExp05.java
//演示限定符的使用
public class RegExp05 {
public static void main(String[] args) {
String content = "a211111aaaaaahello";
//String regStr = "a{3}";//匹配 aaa
//String regStr = "1{4}";//匹配 1111
//String regStr = "\\d{2}";//匹配 两位任意数字字符
//细节: java匹配默认是贪婪匹配, 即尽可能匹配多的
//String regStr = "a{3,4}";//表示匹配 aaa或者aaaa
//String regStr = "1{4,5}";//表示匹配 1111或11111
//String regStr = "\\d{2,5}";//表示匹配 两位任意数字字符 或者三位,四位,五位
//String regStr = "1+";//表示匹配1个或多个1
//String regStr = "\\d+";//表示匹配一个数字或多个数字
//String regStr = "1*";//表示匹配0个或多个1
//演示?的使用, 遵守贪婪匹配
String regStr = "a1?";//匹配 a或者a1
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
System.out.println("找到: " + matcher.group(0));
}
}
}
元字符-定位符
定位符, 规定要匹配的字符串出现的位置, 比如在字符串的开始还是在结束的位置, 必须掌握.
| 符号 | 含义 | 示例 | 解释 | 匹配输入 |
|---|---|---|---|---|
| ^ | 指定起始字符 | ^[0-9]+[a-z]* | 以至少一个数字开头, 后接 任意个小写字符的字符串 | 123,6aa,555edf |
| $ | 指定结束字符 | ^[0-9]\-[a-z]+$ | 以一个数字开头后接连字符"=" 并以至少一个小写字母结尾的字符串 | 1-a |
| \\b | 匹配目标字符串的边界 | wei\\b | 这里说的字符串的边界指的是子串间有空格 或者是目标字符串的结束位置 | |
| \\B | 匹配目标字符串的非边界 | wei\\B | 和\\b的含义正好相反 |
1.新建`src/com/zzw/regexp/RegExp06.java`
//演示定位符的使用
public class RegExp06 {
public static void main(String[] args) {
String content = "hanshunping sphan nnhan";
//String content = "123-abc";
//以至少一个数字字符开头, 后接任意个小写字母
//String regStr = "^[0-9]+[a-z]*$";
//以至少一个数字字符开头, 以至少一个小写字母结束(体现了贪婪匹配)
//String regStr = "^[0-9]+\\-[a-z]+$";
//表示匹配边界的han
// (这里的边界是指: 被匹配的字符串最后, 也可以是空格的子字符串的最后)
/*
找到: han
找到: han
*/
//String regStr = "han\\b";
//和\\b的含义刚刚相反
/*
找到: han
找到: han
*/
String regStr = "\\Bhan";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
System.out.println("找到: " + matcher.group(0));
}
}
}
分组
| 常用分组构造形式 | 说明 |
|---|---|
| (pattern) | 非命名捕获. 捕获匹配的子字符串. 编号为零的第一个捕获是由整个正则表达式模式匹配的文本. 其它捕获结果则根据左括号的顺序从1开始自动编号. |
| (?<name>pattern) | 命名捕获, 将匹配的子字符串捕获到一个组名称或编号名称中. 用于name的字符串 不能包含任何标点符号, 并且不能以数字开头, 可以使用单引号替代尖括号. 例如 (?‘name’) |
| (?:pattern) | 匹配 pattern 但不捕获该匹配的子表达式, 即它是一个非捕获匹配, 不存储供以后使用的匹配. 这对于用"or"字符 (|) 组合模式部件的情况很有用. 例如: 'industr(?:y|ies) 是比 industry|industries更经济的表达式. |
| (?=pattern) | 它是一个非捕获匹配. 例如: Windows (?=95|98|NT|2000) 匹配 Windows 2000 中的 Windows, 但不匹配 Windows 3.1 中的 Windows |
| (?!pattern) | 该表达式匹配不处于匹配 pattern 的字符串的起始点的搜索字符串. 它是一个非捕获匹配. 例如, Windows (?!95|98|NT|2000) 匹配 Windows 3.1 中的 Windows, 但不匹配 Windows 2000 中的 Windows |
1.新建src/com/zzw/regexp/RegExp07.java
public class RegExp07 {
public static void main(String[] args) {
String content = "zhaozhiwei s2012 nihao1015zhao";
//下面就是非命名分组
//说明
//1. matcher.group(0) 得到匹配到的字符串
//2. matcher.group(1) 得到匹配到的字符串的第1个分组内容
//3. matcher.group(2) 得到匹配到的字符串的第2个分组内容
//String regStr = "(\\d\\d)(\\d\\d)";//匹配4个数字的字符串
//命名分组: 即可以给分组取名
String regStr = "(?<g1>\\d\\d)(?<g2>\\d\\d)";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
System.out.println("找到: " + matcher.group(0));
System.out.println("第1个分组内容: " + matcher.group(1));
System.out.println("第2个分组内容: " + matcher.group(2));
System.out.println("第一个分组内容[通过组名]: " + matcher.group("g1"));
System.out.println("第二个分组内容[通过组名]: " + matcher.group("g2"));
}
}
}
2.新建src/com/zzw/regexp/RegExp08.java
//演示非捕获分组, 语法比较奇怪
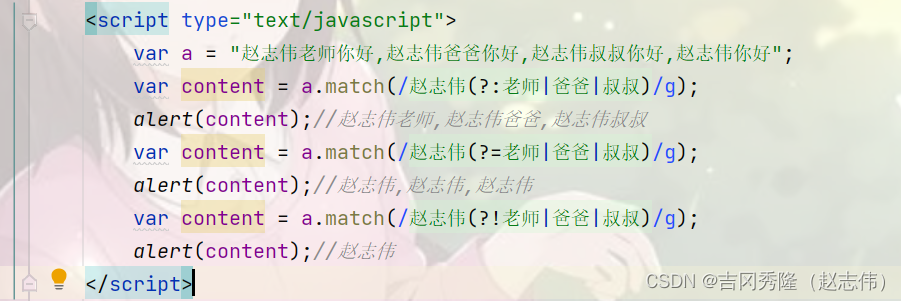
public class RegExp08 {
public static void main(String[] args) {
String content = "hello 周杰伦歌手 hello 周杰伦导演 hello 周杰伦老师 hello 周杰伦演员 hello 周杰伦baby";
//找到: 周杰伦歌手, 周杰伦导演, 周杰伦老师, 周杰伦演员, 周杰伦baby
//String regStr = "周杰伦歌手|周杰伦导演|周杰伦老师周杰伦演员|周杰伦baby";
//下面的写法可以等价非捕获分组. 注意: 不能 matcher.group(1)
//String regStr = "周杰伦(?:歌手|导演|老师|演员|baby)";
//找到 周杰伦 这个关键词, 但是要求只是查找周杰伦歌手, 周杰伦演员 中包含的周杰伦
//下面也是非捕获分组, 不能使用 matcher.group(1)
//String regStr = "周杰伦(?=歌手|演员)";
//找到 周杰伦 这个关键词, 但是要求只是查找 不是 (周杰伦歌手 和 周杰伦演员) 中包含的周杰伦
//下面也是非捕获分组, 不能使用 matcher.group(1)
String regStr = "周杰伦(?!歌手|演员)";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
System.out.println("找到: " + matcher.group(0));
}
}
}
非贪婪匹配
1.新建com.zzw.regexp.RegExp09.java
public class RegExp09 {
public static void main(String[] args) {
String content = "hello1111111 ok";
//String regStr = "\\d+";//默认是贪婪匹配
String regStr = "\\d+?";//非贪婪匹配
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
System.out.println("找到: " + matcher.group(0));
}
}
}
应用实例
对字符串进行如下验证
1.汉字
2.邮政编码. 要求: 是1-9开头的一个六位数. 比如:123890
3.QQ号码. 要求:是1-9开头的一个(5位数-10位数) 比如: 12345, 123456789, 978964140
4.手机号码. 要求: 必须以13, 14, 15, 18开头的11位数, 比如 13031758275
5.URL : 比如
https://www.bilibili.com/video/BV16Z4y1i7vv/?p=7&spm_id_from=pageDriver&vd_source=03325a87946ce23102fa48daa830127a
新建com.zzw.regexp.RegExp10.java
//正则表达式应用实例
public class RegExp10 {
public static void main(String[] args) {
//汉字
//String content = "赵志伟";
//String regStr = "^[\\u0391-\\uffe5]+$";
//邮政编码
//要求: 是1-9开头的一个六位数. 比如:123890
//String content = "123890";
//String regStr = "^[1-9]\\d{5}$";
//QQ号码
//要求:是1-9开头的一个(5位数-10位数) 比如: 12345, 123456789, 978964140
//String content = "978964140";
//String regStr = "^[1-9]\\d{4,9}$";
//手机号码
//要求: 必须以13, 14, 15, 18开头的11位数, 比如 13031758275
String content = "13031758275";
String regStr = "^(?:13|14|15|18)\\d{9}$";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
if (matcher.find()) {
System.out.println("满足格式");
} else {
System.out.println("不满足格式");
}
}
}
新建com.zzw.regexp.RegExp11.java
//正则表达式应用实例
public class RegExp11 {
public static void main(String[] args) {
String content = "https://www.bilibili.com/video/BV16Z4y1i7vv/?p=7&spm_id_from=pageDriver&vd_source=03325a87946ce23102fa48daa830127a";
/**
* 思路
* 1.先确定 url 的开始部分 http(?:s|)://
* 2.然后通过 ([\\w-]+\.)+[\\w-]+, 匹配 www.bilibili.com
* 3.通过 (\\/[\\w-?=&/%.#]*)? 匹配 /video/BV16Z4y1i7vv/?p=7&spm_id_from=pageDriver&vd_source=03325a87946ce23102fa48daa830127a
*/
String regStr = "(http(?:s|)://)?([\\w-]+\\.)+[\\w-]+(\\/[\\w-?=&/%.#]*)?";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
System.out.println("找到: " + matcher.group(0));
}
//这里如果使用 Pattern 的 matcheres 整体匹配 比较简洁
System.out.println(Pattern.matches(regStr, content));
}
}
正则表达式三个常用类
java.util.regex 包主要包括以下三个类 Patterh 类, Matcher类 和 PatternSyntaxException.
●Pattern类Pattern对象是一个正则表达式对象. Pattern类没有公共构造方法, 要创建一个 Pattern对象, 需调用其公共静态方法, 返回一个 Pattern对象. 该方法接受一个正则表达式作为它的第一个参数. 比如:Pattern pattern = Pattern.compile(regStr)
●Matcher类Matcher 对象是对输入字符串进行解释和匹配的引用. 与Pattern类一样, Matcher也没有公共构造方法, 需要调用 Pattern对象的matcher方法来获一个Matcher对象.
●PatternSyntaxExceptionPatternSyntaxException是一个非强制异常类, 它表示一个正则表达式模式中的语法错误.
1.新建com.zzw.regexp.PatternMethod.java
//演示 matches 方法, 用于整体匹配, 在验证输入的字符串是否满足条件时使用
public class PatternMethod {
public static void main(String[] args) {
String content = "hello world 赵志伟 虚拟世界";
//String regStr = "hello";
String regStr = "hello.*";
boolean matches = Pattern.matches(regStr, content);
System.out.println("整体匹配: " + matches);
}
}
2.新建com.zzw.regexp.MatcherMethod.java
//Matcher类的常用方法
public class MatcherMethod {
public static void main(String[] args) {
String content = "hello tom hello jack hello king hello queen";
String regStr = "hello";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
System.out.println("==================");
System.out.println(matcher.start());
System.out.println(matcher.end());
System.out.println("找到: " + content.substring(matcher.start(), matcher.end()));
}
//整体匹配方法, 常用于 去校验某个字符串是否满足某个规则
System.out.println("整体匹配: " + matcher.matches());
//完成如果 content 有 king 替换成 国王
regStr = "king";
pattern = Pattern.compile(regStr);
matcher = pattern.matcher(content);
//注意: 返回的字符串才是替换后的字符串, 原来的 content 不变化
String newContent = matcher.replaceAll("国王");
System.out.println("替换后的字符串: " + newContent);
System.out.println("content: " + content);
}
}
分组, 捕获, 反向引用
提出需求
请看下面问题:
给你一段文本, 请你找出四个数字连在一起的字串, 并且这四个数字要满足第1位与第4位相同, 第2位与第3位相同, 比如 1221, 5775…
介绍
(\\d\\d)(\\d\\d)
要满足前面的问题, 我们需要了解正则表达式的几个概念
1.分组
我们可以用圆括号组成一个比较复杂的匹配模式, 那么一个圆括号的部分我们看作是一个子表达式/一个分组.
2.捕获
把正则表达式中子表达式/分组匹配的内容, 保存到内存中以数字编号或显示命名的组里, 方便后面引用. 从左向右, 以分组的左括号为标志, 第一个出现的分组的组号为1, 第二个为2, 依此类推, 组0代表的是整个正则式.
3.反向引用
圆括号的内容被捕获后, 可以在这个括号后被使用, 从而写出一个比较实用的匹配模式, 这个我们称为反向引用, 这种引用既可以使在正则表达式内部, 也可以是在正则表达式外部, 内部反向引用 \分组号, 外部反向引用 $分组号.
看几个小案例
1.要匹配两个连续的相同数字: (\\d)\\1
2.要匹配五个连续的相同数字: (\\d)\\1{4}
3.要匹配个位与千位相同, 十位与百位相同的数 (\\d)(\\d)\\2\\1
●思考题
请在字符串中检索商品编号, 形式如: 12321-333999111 这样的号码, 要求满足前面是一个五位数, 然后一个-号, 然后是一个九位数, 连续的每三位要相同.
1.新建com.zzw.regexp.RegExp12.java
public class RegExp12 {
public static void main(String[] args) {
String content = "1232112321-333666999321412";
String regStr = "\\d{5}\\-(\\d)\\1{2}(\\d)\\2{2}(\\d)\\3{2}";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
System.out.println("找到: " + matcher.group(0));
}
}
}
经典的结巴程序
把类似 “我…我要…学学学学…编程java!” 通过正则表达式 修改成 “我要学编程java!”
1.新建com.zzw.regexp.RegExp13.java
public class RegExp13 {
public static void main(String[] args) {
String content = "我....我要....学学学学....编程java!";
//1.去掉所有的 .
String regStr = "\\.";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
String newContent = matcher.replaceAll("");
System.out.println("newContent=" + newContent);
//2.去掉连续重复的字
regStr = "(.)\\1+";
pattern = Pattern.compile(regStr);
matcher = pattern.matcher(newContent);
newContent = matcher.replaceAll("$1");
System.out.println("newContent=" + newContent);
}
}
String类中使用正则表达式
替换功能
public String replaceAll(String regex, String replacement)
判断功能
public boolean matches(String regex) 使用 Pattern 和 Matcher 类
分割功能
public String[] split(String regex)
1.新建com.zzw.regexp.StringReg.java
public class StringReg {
public static void main(String[] args) {
//使用正则表达式, 将 jdk1.3 和 jdk1.4 替换成 jdk
String content = "马踏飞燕jdk1.3 hello,worldjdk1.4 hello";
String regStr = "jdk1\\.(?:3|4)";
String newContent = content.replaceAll(regStr, "jdk");
System.out.println("newContent=" + newContent);
//要求: 验证一个手机号, 要求必须使以 138 139 开头的
content = "13812345678";
if (content.matches("^13(?:8|9)\\d{8}$")) {
System.out.println("验证成功");
} else {
System.out.println("验证失败");
}
//要求: 按照 # 或者 - 或者 ~ 或者 数字 来分割字符串
content = "赵志伟#山东省-济宁市~泗水县33泗张镇~付山庄村";
String[] split = content.split("#|-|~|\\d+");
for (String string : split) {
System.out.println(string);
}
}
}
本章作业
1.验证电子邮件格式是否合法. 规定电子邮件规则是
①只能有一个@
②@前面是用户名, 可以是a-z A-Z 0-9 _ - 字符
③@后面是域名, 并且域名只能是英文字母, 比如 sohu.com 或者 tsinghua.org.cn
④写出对应的正则表达式, 验证输入的字符串是否满足规则
新建com.zzw.homework.Homework01.java
public class Homework01 {
public static void main(String[] args) {
String content = "978964140@qq.com";
String regStr = "[\\w_-]+@([a-zA-Z]+\\.)+[a-zA-Z]+";
if (content.matches(regStr)) {
System.out.println("符合要求");
} else {
System.out.println("不符合要求");
}
}
}
2.要求验证是不是整数或者小数. 提示: 这个题要考虑整数和负数.
比如: 123, -123, 34.53, -21.54, 0.99, -0.43 等.
新建com.zzw.homework.Homework02.java
public class Homework02 {
public static void main(String[] args) {
String content = "-0.12";
//判断是不是整数
String regStr = "^(?:|\\+|-)[1-9]\\d*$";
if (content.matches(regStr)) {
System.out.println("是整数");
} else {
System.out.println("不是整数");
}
//判断是不是小数
regStr = "^(?:|\\+|-)\\d+\\.\\d+$";
if (content.matches(regStr)) {
System.out.println("是小数");
} else {
System.out.println("不是小数");
}
//判断是不是整数或小数
regStr = "^[+-]?([1-9]\\d*|0)(\\.\\d+)?$";
if (content.matches(regStr)) {
System.out.println("是整数或小数");
} else {
System.out.println("不是整数或小数");
}
}
3.对一个url进行解析
http://www.bilibili.com:8080/abc/index.html
①要求得到协议是什么? http
②域名是什么? www.sohu.com
③端口是什么? 8080
④文件名是什么? index.html
新建com.zzw.homework.Homework03.java
public class Homework03 {
public static void main(String[] args) {
String content = "http://www.bilibili.com:8080/abc/index.html";
String regStr = "^((?<g1>http(?:s|))://)?(?<g2>([\\w-]+\\.)+[\\w-]+):(?<g3>\\d+)/\\w+/(?<g4>([\\w-]+\\.)+[\\w-]+)$";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
System.out.println("找到: " + matcher.group("g1"));
System.out.println("找到: " + matcher.group("g2"));
System.out.println("找到: " + matcher.group("g3"));
System.out.println("找到: " + matcher.group("g4"));
}
}
}
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » JavaSe系列二十七: Java正则表达式

发表评论 取消回复