上篇介绍绍了Apache Hadoop的分布式集群环境搭建,并测试了MapReduce分布式计算案例。但集群历史做了哪些任务,任务执行日志等信息还需要配置历史服务器和日志聚集才能更好的查看。
配置历史服务器
在Yarn中运行的任务产生的日志数据不能查看,为了查看程序的历史运行情况,需要配置一下历史日志服务器。
- 配置mapred-site.xml
三个节点配置一致
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>- 启动历史服务器
[root@hadoop01 hadoop-2.9.2]# sbin/mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /opt/hadoop-2.9.2/logs/mapred-root-historyserver-hadoop01.out- 查看JobHistory
访问:http://hadoop01:19888/jobhistory
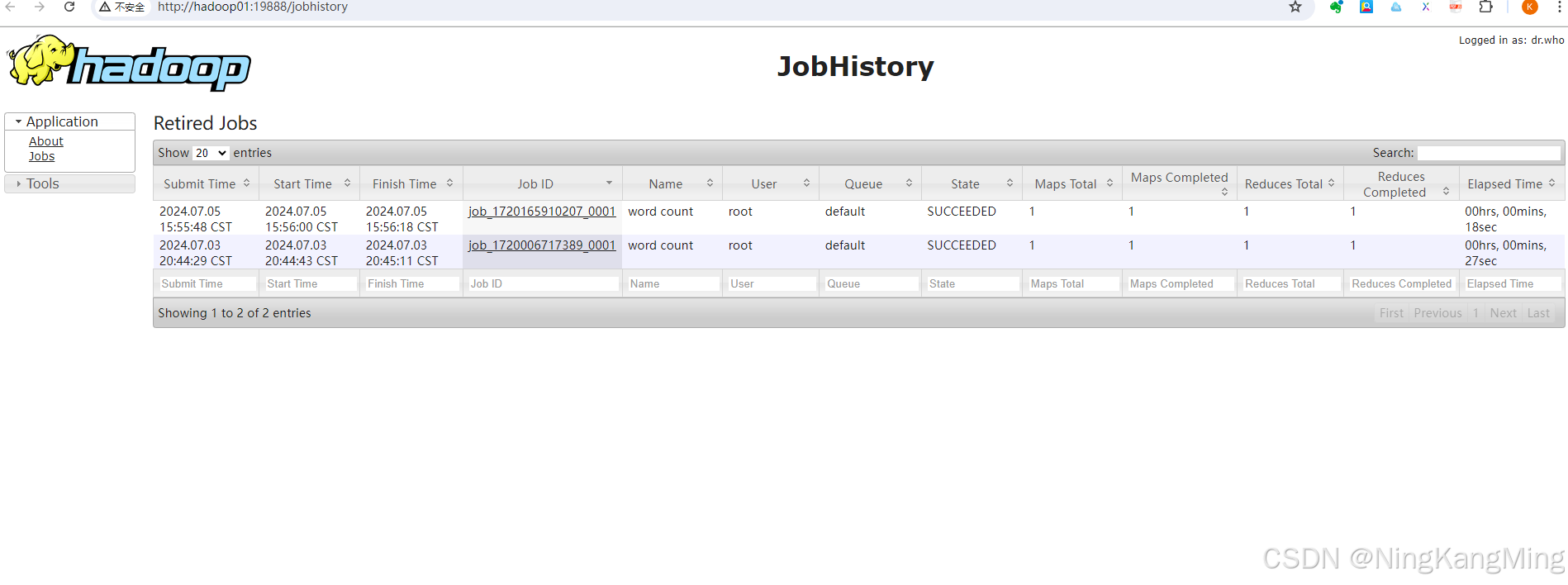
配置日志聚集
日志聚集:应用(Job)运行完成以后,将应用运行日志信息从各个task汇总上传到HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryManager。
- 配置yarn-site.xml
三个节点配置一致
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop01:19888/jobhistory/logs</value>
</property>- 重启hadoop集群
关闭
sbin/stop-dfs.sh
sbin/mr-jobhistory-daemon.sh stop historyserver
sbin/stop-yarn.sh启动
sbin/start-dfs.sh
sbin/mr-jobhistory-daemon.sh start historyserver
sbin/start-yarn.sh- 删除HDFS上已经存在的输出文件
bin/hdfs dfs -rm -R /wcoutput- 执行WordCount程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /wcinput/ /wcoutput- 查看日志,如图所示
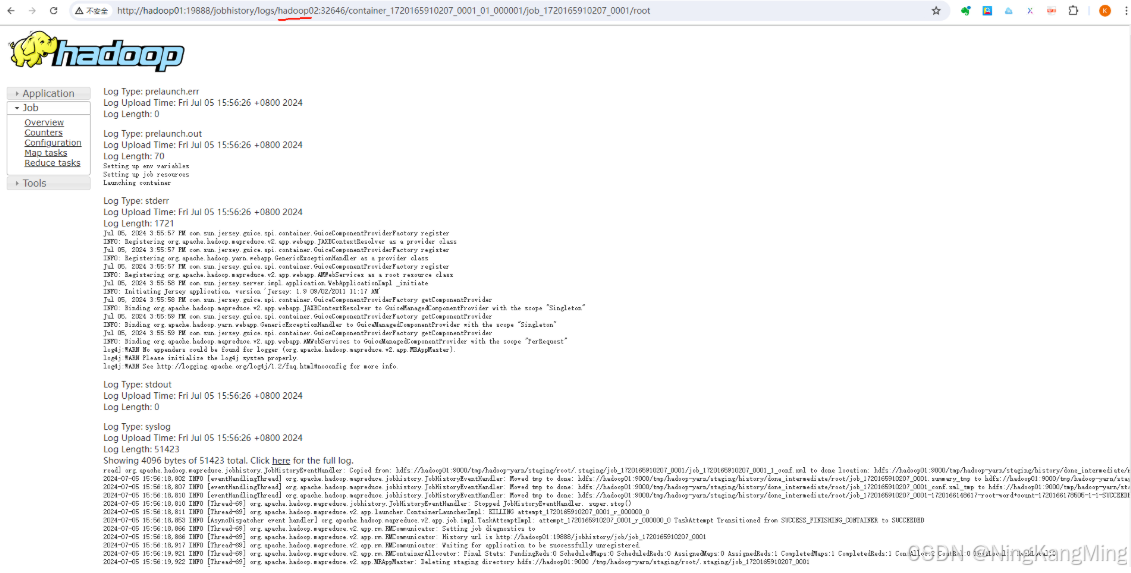
这样一来,位于hadoop02中的日志在hadoop01中也可以查看
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Apache Hadoop之历史服务器&日志聚集配置

发表评论 取消回复