套索回归算法概述
套索回归算法简介
在统计学和机器学习中,套索回归是一种同时进行特征选择和正则化(数学)的回归分析方法,旨在增强统计模型的预测准确性和可解释性,
正则化是一种回归的形式,它将系数估计(coefficient estimate)朝零的方向进行约束、调整或缩小。也就是说,正则化可以在学习过程中降低模型复杂度和不稳定程度,从而避免过拟合的危险。一个简单的线性回归关系如下式。其中 Y 代表学习关系,β 代表对不同变量或预测因子 X 的系数估计。
Y ≈ β_0 + β_1X_1 + β_2X_2 + …+ β_pX_p
拟合过程涉及损失函数,称为残差平方和(RSS)。系数选择要使得它们能最小化损失函数。
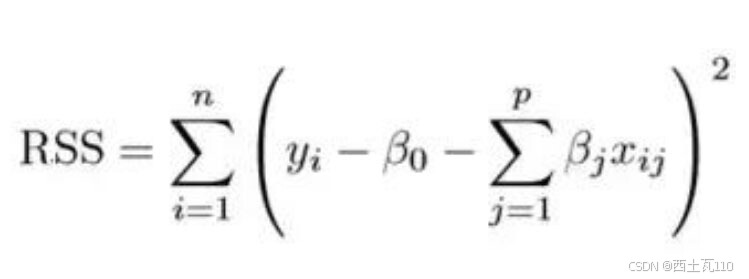
这个式子可以根据你的训练数据调整系数。但如果训练数据中存在噪声,则估计的系数就不能很好地泛化到未来数据中。这正是正则化要解决的问题,它能将学习后的参数估计朝零缩小调整。
套索和岭回归都是正则化的方法,我们将对比着描述,其中套索需要最小化下图的函数:
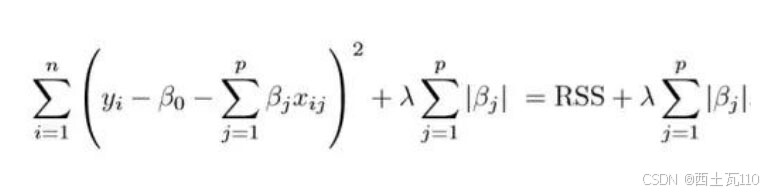
很明显,这种变体只有在惩罚高系数时才有别于岭回归。它使用 |β_j|(模数)代替 β 的平方作为惩罚项。在统计学中,这被称为 L1 范数。让我们换个角度看看上述方法。岭回归可以被认为是求解一个方程,其中系数的平方和小于等于 s。而 套索 可以看作系数的模数之和小于等于 s 的方程。其中,s 是一个随收缩因子 λ 变化的常数。这些方程也被称为约束函数。
假定在给定的问题中有 2 个参数。那么根据上述公式,岭回归的表达式为 β1² + β2² ≤ s。这意味着,在由 β1² + β2² ≤ s 给出的圆的所有点当中,岭回归系数有着最小的 RSS(损失函数)。同样地,对 套索 而言,方程变为 |β1|+|β2|≤ s。这意味着在由 |β1|+|β2|≤ s 给出的菱形当中,套索 系数有着最小的 RSS(损失函数)。
下图描述了这些方程。
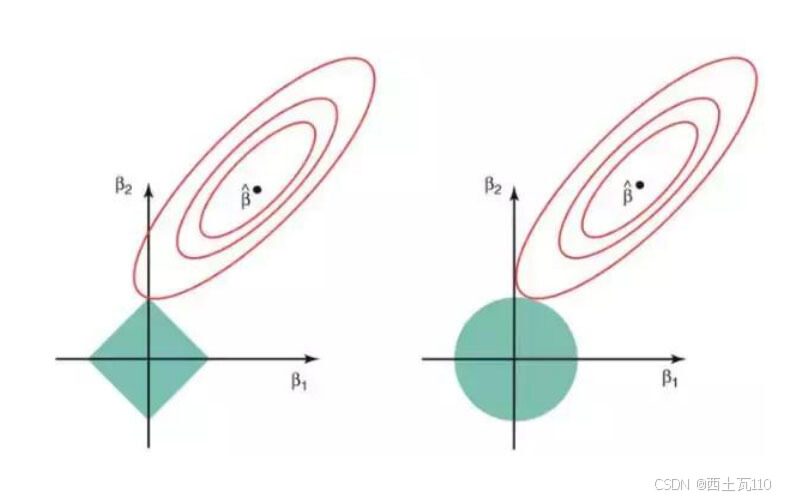
上图的绿色区域代表约束函数域:左侧代表 套索,右侧代表岭回归。其中红色椭圆是 RSS 的等值线,即椭圆上的点有着相同的 RSS 值。对于一个非常大的 s 值,绿色区域将会包含椭圆的中心,使得两种回归方法的系数估计等于最小二乘估计。但是,上图的结果并不是这样。在上图中,套索 和岭回归系数估计是由椭圆和约束函数域的第一个交点给出的。因为岭回归的约束函数域没有尖角,所以这个交点一般不会产生在一个坐标轴上,也就是说岭回归的系数估计全都是非零的。然而,套索 约束函数域在每个轴上都有尖角,因此椭圆经常和约束函数域相交。发生这种情况时,其中一个系数就会等于 0。在高维度时(参数远大于 2),许多系数估计值可能同时为 0。
这说明了岭回归的一个明显缺点:模型的可解释性。它将把不重要的预测因子的系数缩小到趋近于 0,但永不达到 0。也就是说,最终的模型会包含所有的预测因子。但是,在 套索 中,如果将调整因子 λ 调整得足够大,L1 范数惩罚可以迫使一些系数估计值完全等于 0。因此,套索 可以进行变量选择,产生稀疏模型。
套索回归发展历史
套索是由斯坦福大学统计学教授Robert Tibshirani于1996年基于Leo Breiman的非负参数推断(Nonnegative Garrote, NNG)提出。后者于其1995年的论文中发表。Robert Tibshirani最初使用套索来提高预测的准确性与回归模型的可解释性,他修改了模型拟合的过程,在协变量中只选择一个子集应用到最终模型中,而非用上全部协变量。
在随后的研究中不同的套索变体被创造出来。几乎所有这些变体都集中于尊重或利用协变量之间的不同类型的依赖性。2005年,Hui Zou和Trevor Hastie提出通过弹性网(elastic net)来实现正则化和变量选择。当预测变量的数量大于样本大小时,弹性网络正则化会增加额外的岭回归类惩罚,从而提高性能,允许方法一起选择强相关变量,并提高整体预测精度。
2006年Ming Yuan和Yi Lin提对变量进行组合,即group 套索,允许选择相关协变量组作为单个单元,主要针对某些情况下变量不单个出现而仅与其他变量一同出现。
2009年,Arnau Tibau Puig等人对group 套索进一步扩展,以在各个组(稀疏组套索)中执行变量选择并允许组之间的重叠(重叠组套索)。
套索结合了上述的两种方法,它通过强制让回归系数绝对值之和小于某固定值,即强制一些回归系数变为0,有效地选择了不包括这些回归系数对应的协变量的更简单的模型。这种方法和岭回归类似,在岭回归中,回归系数平方和被强制小于某定值,不同点在于岭回归只改变系数的值,而不把任何值设为0。
套索回归主要事件
| 年份 | 事件 | 相关论文/Reference |
| 1995 | Leo Breiman提出非负参数推断 | Breiman, L.(1995). Better Subset Regression Using the Nonnegative Garrote. Technometrics. 37 (4): 373–384. |
| 1996 | 斯坦福大学统计学教授Robert Tibshirani于1996年基于Leo Breiman的非负参数推断(Nonnegative Garrote, NNG)提出套索 | Tibshirani, R. (1996). Regression Shrinkage and Selection via the 套索. Journal of the Royal Statistical Society. Series B (methodological). 58 (1): 267–88. |
| 2005 | Hui Zou和Trevor Hastie提出通过弹性网(elastic net)来实现正则化和变量选择 | Zou, H.; Hastie, T. (2005). Regularization and Variable Selection via the Elastic Net. Journal of the Royal Statistical Society. Series B (statistical Methodology). 67 (2): 301–20. |
| 2006 | Ming Yuan和Yi Lin提对变量进行组合,即group 套索 | Yuan, M.; Lin, Y. (2006). Model Selection and Estimation in Regression with Grouped Variables. Journal of the Royal Statistical Society. Series B (statistical Methodology). 68 (1): 49–67. |
| 2009 | Arnau Tibau Puig等人对group 套索进一步扩展,以在各个组(稀疏组套索)中执行变量选择并允许组之间的重叠(重叠组套索) | Puig, A. T., Wiesel, A.; Hero, A. O. (2009). A Multidimensional Shrinkage-Thresholding Operator. Proceedings of the 15th workshop on Statistical Signal Processing, SSP’09, IEEE, pp. 113–116. |
套索回归算法的原理及作用
套索回归算法的原理
套索算法的核心思想是在最小二乘估计的基础上,增加一个关于回归系数的L1正则化项。这个正则化项的作用是对回归系数进行惩罚,使得部分系数被压缩至零,从而实现特征选择。
具体来说,套索算法的优化目标可以表示为:
β_hat = argmin { ∑(y_i - β_0 - ∑x_ij * β_j)^2 + λ∑|β_j| }
其中,y_i表示观测值,x_ij表示特征值,β_0表示截距项,β_j表示回归系数,λ是正则化参数,用于控制正则化项的权重。
这个优化目标包含两部分:前半部分是最小二乘估计的损失函数,用于衡量模型拟合数据的能力;后半部分是L1正则化项,用于对回归系数进行惩罚。λ越大,惩罚力度越强,越多的回归系数将被压缩至零。
套索回归算法的作用
在处理具有大量特征的数据集时,我们常常面临两个主要的挑战:
- 特征之间可能存在多重共线性,这会导致模型参数估计不稳定甚至无法计算;
- 并非所有特征都对预测结果有显著影响,一些无关或冗余的特征可能会干扰模型的预测性能。传统的最小二乘法(Ordinary Least Squares, OLS)回归在这样的高维数据上往往会得到过拟合的模型,即模型在训练集上表现良好但在新数据上泛化能力弱。
为了解决这些问题,统计学家和发展机器学习算法的研究人员提出了一系列的正则化技术,其中套索回归(套索 Regression)就是一种被广泛应用的方法。套索回归通过在回归模型中加入一个调节复杂度的惩罚项来克服上述问题。这个惩罚项是模型系数绝对值之和的λ倍,也就是所谓的L1范数,其中λ是一个非负的调节参数。
引入L1范数作为惩罚项有几个关键的优势:
- 稀疏性:L1范数有助于模型产生稀疏解,即推动某些系数减小至零。这一性质特别有用,因为它不仅降低了模型的复杂性,还实现了特征选择的目的,即自动地识别出对响应变量有重要影响的变量。
- 可解释性:通过减少特征的数量,模型变得更加容易解释。这对于高维数据尤其重要,因为在高维情况下,找出重要的特征并理解每个特征如何影响预测结果是非常关键的。
- 计算效率:尽管套索回归是一个复杂的优化问题,存在多种算法可以高效地求解,如坐标下降法、最小角回归法等。
套索回归算法的实现过程
- 数据准备:首先,收集并整理好用于回归分析的数据集,包括观测值、特征值等。
- 参数设置:选择合适的正则化参数λ。这通常需要通过交叉验证等方法来确定最优值。
- 优化求解:利用优化算法(如坐标下降法、最小角回归等)求解上述优化目标,得到回归系数的估计值。
- 特征选择:根据回归系数的估计值,将绝对值较小的系数置为零,从而实现特征选择。这些被置为零的特征在后续建模中将不再考虑。
- 模型评估:利用测试数据集对得到的模型进行评估,包括拟合优度、预测误差等指标。根据评估结果调整模型参数,以达到更好的性能。
套索回归算法的代码实现
from sklearn.linear_model import Lasso
lamb = 0.025
lasso_reg = Lasso(alpha=lamb)
lasso_reg.fit(X_poly_d, y)
print(lasso_reg.intercept_, lasso_reg.coef_)
print(
L_theta_new(intercept=lasso_reg.intercept_,
coef=lasso_reg.coef_.T,
X=X_poly_d,
y=y,
lamb=lamb))
X_plot = np.linspace(-3, 2, 1000).reshape(-1, 1)
X_plot_poly = poly_features_d.fit_transform(X_plot)
h = np.dot(X_plot_poly, lasso_reg.coef_.T) + lasso_reg.intercept_
plt.plot(X_plot, h, 'r-')
plt.plot(X, y, 'b.')
plt.show()套索回归算法的应用场景
套索回归可以用于特征选择、解决多重共线性问题以及解释模型结果等应用场景。例如,在医疗诊断领域,我们可以使用套索回归来识别哪些疾病风险因素对预测结果具有最大的影响。在金融领域,我们可以使用套索回归来寻找哪些因素对股票价格变化有最大的影响。
此外,套索回归也可以与其他算法结合使用,例如随机森林、支持向量机等。通过结合使用,我们可以充分利用套索回归的特征选择功能,同时获得其他算法的优点,从而提高模型的性能。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » AI算法14-套索回归算法Lasso Regression | LR

发表评论 取消回复