1.1 引言
我们在修改网络模型,添加或删除模块,或者更改了某一层之后,直接加载原先的预训练权重,肯定是会报错的,因为原来的模型权重和修改后的模型权重之间的结构是不匹配的。
那么我们只想加载那些没有更改过的那个部分的权重来初始化,应该怎么做?
1.2 问题的产生
以ResNet34为例,我在原有模型基础上添加一个模块,以SEAttention为例:

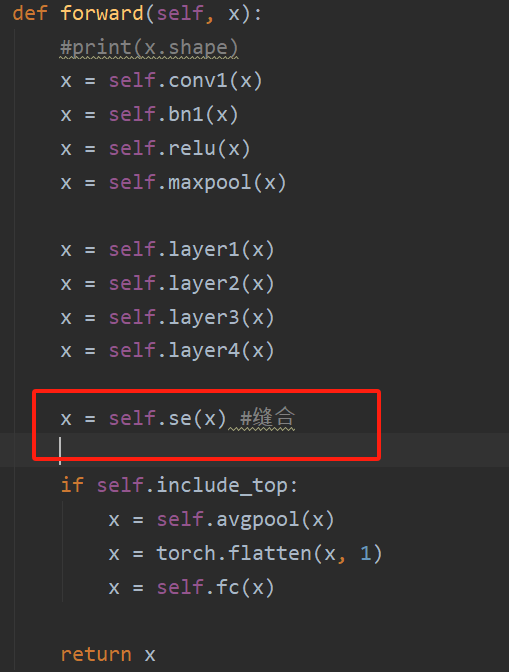
然后,加载训练文件,可以看到,报错以下信息:
fc.0和fc.2缺少权重。因为我们之前的模型的预训练权重是没有这两个部分的。

1.3 解决方法一
问题所在:
我们先转去看训练文件:
在加载预训练权重时有这么一个函数"load_state_dict"

我们ctrl+p查看一下该函数的参数:

注意看,最后面有一个叫"strict"的参数,它的默认值是True,也就是说在默认值的情况下,如果预训练的权重和模型的权重关键字不一致,就会报错。所以我们需要把这里的strict的值更改为False。
也就是说,之前训练不能对应的关键字,直接选择忽视掉。相当于一个包容的关系。
我们此时再次运行:正常训练。

现在,我们需要去原来的预训练权重文件中去看,查看里面的字典关键字。
在模型文件中进行:
1.查看预训练权重的关键字:
#1.查看预训练权重的关键字:
pretrained_weights_path ="./resnet34-pre.pth"
state_dict = torch.load(pretrained_weights_path)
#获取预训练权重的关键字
pretrained_keys = state_dict.keys()
print("预训练权重的关键字:")
for key in pretrained_keys:
print(key)
运行结果如下:
预训练权重的关键字:
conv1.weight
bn1.running_mean
bn1.running_var
bn1.weight
bn1.bias
layer1.0.conv1.weight
layer1.0.bn1.running_mean
layer1.0.bn1.running_var
layer1.0.bn1.weight
layer1.0.bn1.bias
layer1.0.conv2.weight
layer1.0.bn2.running_mean
layer1.0.bn2.running_var
layer1.0.bn2.weight
layer1.0.bn2.bias
layer1.1.conv1.weight
layer1.1.bn1.running_mean
layer1.1.bn1.running_var
layer1.1.bn1.weight
layer1.1.bn1.bias
layer1.1.conv2.weight
layer1.1.bn2.running_mean
layer1.1.bn2.running_var
layer1.1.bn2.weight
layer1.1.bn2.bias
layer1.2.conv1.weight
layer1.2.bn1.running_mean
layer1.2.bn1.running_var
layer1.2.bn1.weight
layer1.2.bn1.bias
layer1.2.conv2.weight
layer1.2.bn2.running_mean
layer1.2.bn2.running_var
layer1.2.bn2.weight
layer1.2.bn2.bias
layer2.0.conv1.weight
layer2.0.bn1.running_mean
layer2.0.bn1.running_var
layer2.0.bn1.weight
layer2.0.bn1.bias
layer2.0.conv2.weight
layer2.0.bn2.running_mean
layer2.0.bn2.running_var
layer2.0.bn2.weight
layer2.0.bn2.bias
layer2.0.downsample.0.weight
layer2.0.downsample.1.running_mean
layer2.0.downsample.1.running_var
layer2.0.downsample.1.weight
layer2.0.downsample.1.bias
layer2.1.conv1.weight
layer2.1.bn1.running_mean
layer2.1.bn1.running_var
layer2.1.bn1.weight
layer2.1.bn1.bias
layer2.1.conv2.weight
layer2.1.bn2.running_mean
layer2.1.bn2.running_var
layer2.1.bn2.weight
layer2.1.bn2.bias
layer2.2.conv1.weight
layer2.2.bn1.running_mean
layer2.2.bn1.running_var
layer2.2.bn1.weight
layer2.2.bn1.bias
layer2.2.conv2.weight
layer2.2.bn2.running_mean
layer2.2.bn2.running_var
layer2.2.bn2.weight
layer2.2.bn2.bias
layer2.3.conv1.weight
layer2.3.bn1.running_mean
layer2.3.bn1.running_var
layer2.3.bn1.weight
layer2.3.bn1.bias
layer2.3.conv2.weight
layer2.3.bn2.running_mean
layer2.3.bn2.running_var
layer2.3.bn2.weight
layer2.3.bn2.bias
layer3.0.conv1.weight
layer3.0.bn1.running_mean
layer3.0.bn1.running_var
layer3.0.bn1.weight
layer3.0.bn1.bias
layer3.0.conv2.weight
layer3.0.bn2.running_mean
layer3.0.bn2.running_var
layer3.0.bn2.weight
layer3.0.bn2.bias
layer3.0.downsample.0.weight
layer3.0.downsample.1.running_mean
layer3.0.downsample.1.running_var
layer3.0.downsample.1.weight
layer3.0.downsample.1.bias
layer3.1.conv1.weight
layer3.1.bn1.running_mean
layer3.1.bn1.running_var
layer3.1.bn1.weight
layer3.1.bn1.bias
layer3.1.conv2.weight
layer3.1.bn2.running_mean
layer3.1.bn2.running_var
layer3.1.bn2.weight
layer3.1.bn2.bias
layer3.2.conv1.weight
layer3.2.bn1.running_mean
layer3.2.bn1.running_var
layer3.2.bn1.weight
layer3.2.bn1.bias
layer3.2.conv2.weight
layer3.2.bn2.running_mean
layer3.2.bn2.running_var
layer3.2.bn2.weight
layer3.2.bn2.bias
layer3.3.conv1.weight
layer3.3.bn1.running_mean
layer3.3.bn1.running_var
layer3.3.bn1.weight
layer3.3.bn1.bias
layer3.3.conv2.weight
layer3.3.bn2.running_mean
layer3.3.bn2.running_var
layer3.3.bn2.weight
layer3.3.bn2.bias
layer3.4.conv1.weight
layer3.4.bn1.running_mean
layer3.4.bn1.running_var
layer3.4.bn1.weight
layer3.4.bn1.bias
layer3.4.conv2.weight
layer3.4.bn2.running_mean
layer3.4.bn2.running_var
layer3.4.bn2.weight
layer3.4.bn2.bias
layer3.5.conv1.weight
layer3.5.bn1.running_mean
layer3.5.bn1.running_var
layer3.5.bn1.weight
layer3.5.bn1.bias
layer3.5.conv2.weight
layer3.5.bn2.running_mean
layer3.5.bn2.running_var
layer3.5.bn2.weight
layer3.5.bn2.bias
layer4.0.conv1.weight
layer4.0.bn1.running_mean
layer4.0.bn1.running_var
layer4.0.bn1.weight
layer4.0.bn1.bias
layer4.0.conv2.weight
layer4.0.bn2.running_mean
layer4.0.bn2.running_var
layer4.0.bn2.weight
layer4.0.bn2.bias
layer4.0.downsample.0.weight
layer4.0.downsample.1.running_mean
layer4.0.downsample.1.running_var
layer4.0.downsample.1.weight
layer4.0.downsample.1.bias
layer4.1.conv1.weight
layer4.1.bn1.running_mean
layer4.1.bn1.running_var
layer4.1.bn1.weight
layer4.1.bn1.bias
layer4.1.conv2.weight
layer4.1.bn2.running_mean
layer4.1.bn2.running_var
layer4.1.bn2.weight
layer4.1.bn2.bias
layer4.2.conv1.weight
layer4.2.bn1.running_mean
layer4.2.bn1.running_var
layer4.2.bn1.weight
layer4.2.bn1.bias
layer4.2.conv2.weight
layer4.2.bn2.running_mean
layer4.2.bn2.running_var
layer4.2.bn2.weight
layer4.2.bn2.bias
fc.weight
fc.bias
2.查看你自身网络模型的关键字:
#2.查看你自身网络模型的关键字:
net = resnet34()
model_keys = net.state_dict().keys()
print("\n模型权重的关键字:")
for key in model_keys:
print(key)模型权重的关键字:
conv1.weight
bn1.weight
bn1.bias
bn1.running_mean
bn1.running_var
bn1.num_batches_tracked
layer1.0.conv1.weight
layer1.0.bn1.weight
layer1.0.bn1.bias
layer1.0.bn1.running_mean
layer1.0.bn1.running_var
layer1.0.bn1.num_batches_tracked
layer1.0.conv2.weight
layer1.0.bn2.weight
layer1.0.bn2.bias
layer1.0.bn2.running_mean
layer1.0.bn2.running_var
layer1.0.bn2.num_batches_tracked
layer1.1.conv1.weight
layer1.1.bn1.weight
layer1.1.bn1.bias
layer1.1.bn1.running_mean
layer1.1.bn1.running_var
layer1.1.bn1.num_batches_tracked
layer1.1.conv2.weight
layer1.1.bn2.weight
layer1.1.bn2.bias
layer1.1.bn2.running_mean
layer1.1.bn2.running_var
layer1.1.bn2.num_batches_tracked
layer1.2.conv1.weight
layer1.2.bn1.weight
layer1.2.bn1.bias
layer1.2.bn1.running_mean
layer1.2.bn1.running_var
layer1.2.bn1.num_batches_tracked
layer1.2.conv2.weight
layer1.2.bn2.weight
layer1.2.bn2.bias
layer1.2.bn2.running_mean
layer1.2.bn2.running_var
layer1.2.bn2.num_batches_tracked
layer2.0.conv1.weight
layer2.0.bn1.weight
layer2.0.bn1.bias
layer2.0.bn1.running_mean
layer2.0.bn1.running_var
layer2.0.bn1.num_batches_tracked
layer2.0.conv2.weight
layer2.0.bn2.weight
layer2.0.bn2.bias
layer2.0.bn2.running_mean
layer2.0.bn2.running_var
layer2.0.bn2.num_batches_tracked
layer2.0.downsample.0.weight
layer2.0.downsample.1.weight
layer2.0.downsample.1.bias
layer2.0.downsample.1.running_mean
layer2.0.downsample.1.running_var
layer2.0.downsample.1.num_batches_tracked
layer2.1.conv1.weight
layer2.1.bn1.weight
layer2.1.bn1.bias
layer2.1.bn1.running_mean
layer2.1.bn1.running_var
layer2.1.bn1.num_batches_tracked
layer2.1.conv2.weight
layer2.1.bn2.weight
layer2.1.bn2.bias
layer2.1.bn2.running_mean
layer2.1.bn2.running_var
layer2.1.bn2.num_batches_tracked
layer2.2.conv1.weight
layer2.2.bn1.weight
layer2.2.bn1.bias
layer2.2.bn1.running_mean
layer2.2.bn1.running_var
layer2.2.bn1.num_batches_tracked
layer2.2.conv2.weight
layer2.2.bn2.weight
layer2.2.bn2.bias
layer2.2.bn2.running_mean
layer2.2.bn2.running_var
layer2.2.bn2.num_batches_tracked
layer2.3.conv1.weight
layer2.3.bn1.weight
layer2.3.bn1.bias
layer2.3.bn1.running_mean
layer2.3.bn1.running_var
layer2.3.bn1.num_batches_tracked
layer2.3.conv2.weight
layer2.3.bn2.weight
layer2.3.bn2.bias
layer2.3.bn2.running_mean
layer2.3.bn2.running_var
layer2.3.bn2.num_batches_tracked
layer3.0.conv1.weight
layer3.0.bn1.weight
layer3.0.bn1.bias
layer3.0.bn1.running_mean
layer3.0.bn1.running_var
layer3.0.bn1.num_batches_tracked
layer3.0.conv2.weight
layer3.0.bn2.weight
layer3.0.bn2.bias
layer3.0.bn2.running_mean
layer3.0.bn2.running_var
layer3.0.bn2.num_batches_tracked
layer3.0.downsample.0.weight
layer3.0.downsample.1.weight
layer3.0.downsample.1.bias
layer3.0.downsample.1.running_mean
layer3.0.downsample.1.running_var
layer3.0.downsample.1.num_batches_tracked
layer3.1.conv1.weight
layer3.1.bn1.weight
layer3.1.bn1.bias
layer3.1.bn1.running_mean
layer3.1.bn1.running_var
layer3.1.bn1.num_batches_tracked
layer3.1.conv2.weight
layer3.1.bn2.weight
layer3.1.bn2.bias
layer3.1.bn2.running_mean
layer3.1.bn2.running_var
layer3.1.bn2.num_batches_tracked
layer3.2.conv1.weight
layer3.2.bn1.weight
layer3.2.bn1.bias
layer3.2.bn1.running_mean
layer3.2.bn1.running_var
layer3.2.bn1.num_batches_tracked
layer3.2.conv2.weight
layer3.2.bn2.weight
layer3.2.bn2.bias
layer3.2.bn2.running_mean
layer3.2.bn2.running_var
layer3.2.bn2.num_batches_tracked
layer3.3.conv1.weight
layer3.3.bn1.weight
layer3.3.bn1.bias
layer3.3.bn1.running_mean
layer3.3.bn1.running_var
layer3.3.bn1.num_batches_tracked
layer3.3.conv2.weight
layer3.3.bn2.weight
layer3.3.bn2.bias
layer3.3.bn2.running_mean
layer3.3.bn2.running_var
layer3.3.bn2.num_batches_tracked
layer3.4.conv1.weight
layer3.4.bn1.weight
layer3.4.bn1.bias
layer3.4.bn1.running_mean
layer3.4.bn1.running_var
layer3.4.bn1.num_batches_tracked
layer3.4.conv2.weight
layer3.4.bn2.weight
layer3.4.bn2.bias
layer3.4.bn2.running_mean
layer3.4.bn2.running_var
layer3.4.bn2.num_batches_tracked
layer3.5.conv1.weight
layer3.5.bn1.weight
layer3.5.bn1.bias
layer3.5.bn1.running_mean
layer3.5.bn1.running_var
layer3.5.bn1.num_batches_tracked
layer3.5.conv2.weight
layer3.5.bn2.weight
layer3.5.bn2.bias
layer3.5.bn2.running_mean
layer3.5.bn2.running_var
layer3.5.bn2.num_batches_tracked
layer4.0.conv1.weight
layer4.0.bn1.weight
layer4.0.bn1.bias
layer4.0.bn1.running_mean
layer4.0.bn1.running_var
layer4.0.bn1.num_batches_tracked
layer4.0.conv2.weight
layer4.0.bn2.weight
layer4.0.bn2.bias
layer4.0.bn2.running_mean
layer4.0.bn2.running_var
layer4.0.bn2.num_batches_tracked
layer4.0.downsample.0.weight
layer4.0.downsample.1.weight
layer4.0.downsample.1.bias
layer4.0.downsample.1.running_mean
layer4.0.downsample.1.running_var
layer4.0.downsample.1.num_batches_tracked
layer4.1.conv1.weight
layer4.1.bn1.weight
layer4.1.bn1.bias
layer4.1.bn1.running_mean
layer4.1.bn1.running_var
layer4.1.bn1.num_batches_tracked
layer4.1.conv2.weight
layer4.1.bn2.weight
layer4.1.bn2.bias
layer4.1.bn2.running_mean
layer4.1.bn2.running_var
layer4.1.bn2.num_batches_tracked
layer4.2.conv1.weight
layer4.2.bn1.weight
layer4.2.bn1.bias
layer4.2.bn1.running_mean
layer4.2.bn1.running_var
layer4.2.bn1.num_batches_tracked
layer4.2.conv2.weight
layer4.2.bn2.weight
layer4.2.bn2.bias
layer4.2.bn2.running_mean
layer4.2.bn2.running_var
layer4.2.bn2.num_batches_tracked
fc.weight
fc.bias
se.fc.0.weight
se.fc.2.weight
3.找出模型中缺失/多余的权重
缺失
【针对你预训练关键字比模型关键字少】
#3.找出模型中缺失的权重【针对你预训练关键字比模型关键字少】
missing_keys = model_keys- pretrained_keys
print("\n模型中缺失的权重关键字")
for key in missing_keys:
print(key)运行结果如下:
模型中缺失的权重关键字:
layer1.1.bn1.num_batches_tracked
layer2.1.bn1.num_batches_tracked
layer1.0.bn2.num_batches_tracked
layer4.0.downsample.1.num_batches_tracked
layer4.0.bn2.num_batches_tracked
layer3.5.bn1.num_batches_tracked
layer2.0.bn2.num_batches_tracked
layer3.2.bn2.num_batches_tracked
layer3.1.bn2.num_batches_tracked
layer2.2.bn2.num_batches_tracked
layer3.0.bn1.num_batches_tracked
layer4.1.bn2.num_batches_tracked
layer1.1.bn2.num_batches_tracked
se.fc.2.weight
layer4.2.bn1.num_batches_tracked
layer3.3.bn1.num_batches_tracked
layer3.4.bn2.num_batches_tracked
layer3.2.bn1.num_batches_tracked
layer2.3.bn1.num_batches_tracked
layer2.1.bn2.num_batches_tracked
layer3.0.downsample.1.num_batches_tracked
layer4.2.bn2.num_batches_tracked
layer2.2.bn1.num_batches_tracked
bn1.num_batches_tracked
se.fc.0.weight
layer1.2.bn2.num_batches_tracked
layer2.0.downsample.1.num_batches_tracked
layer3.1.bn1.num_batches_tracked
layer2.0.bn1.num_batches_tracked
layer3.5.bn2.num_batches_tracked
layer1.2.bn1.num_batches_tracked
layer4.0.bn1.num_batches_tracked
layer3.3.bn2.num_batches_tracked
layer1.0.bn1.num_batches_tracked
layer3.4.bn1.num_batches_tracked
layer3.0.bn2.num_batches_tracked
layer2.3.bn2.num_batches_tracked
layer4.1.bn1.num_batches_tracked
多余
【针对你预训练关键字比模型关键字多】
unexpected_keys = pretrained_keys -model_keys
print("\n预训练权重中多余的权重关键字:")
for key in unexpected_keys:
print(key)1.4 方法二:写一个判断语句
先找到训练文件的加载初始权重的代码:
net = resnet34()
# load pretrain weights
# download url: https://download.pytorch.org/models/resnet34-333f7ec4.pth
model_weight_path = "./resnet34-pre.pth"
assert os.path.exists(model_weight_path), "file {} does not exist.".format(model_weight_path)
net.load_state_dict(torch.load(model_weight_path, map_location='cpu'),strict=False)
# for param in net.parameters():
# param.requires_grad = False然后删掉,我们重新写一个:
#模板
model_weight_path ="./resnet34-pre.pth" #预训练权重的路径
ckpt = torch.load(model_weight_path) #加载预训练权重
net = resnet34() #实例化模型
model_dict = net.state_dict() #获取我们模型的参数
#判断预训练模型中网络的模块是否在修改后的网络中也存在,并且shape相同,如果相同则取出
pretrained_dict = {k:v for k,v in ckpt.items() if k in model_dict and(v.shape == model_dict[k].shape)}
#更新修改之后的model_dict
model_dict.update(pretrained_dict)
#加载我们真正需要的state_dict
net.load_state_dict(model_dict,strict=True)该代码可作为模板使用。
可以看到同样可以运行:

1.5 多GPU训练的关键字问题
看着确实非常简单,但有时候会出现一个问题,比如:
有些同学在单GPU上调用一个基于多GPU预训练像这个问题,报错:

这是因为在加载多GPU训练的模型的时候,由于用DataParallel训练的模型数据并行方式的训练,key中会包含"module“关键字。去掉DataParallel预训练模型中的module,修改如下:
明显看出,我要加载的预训练权重和网络模型结构是一样,只是每个名字前面多了module.这几个后面是一模一样,如果我按照之前的说直接忽略,是不是每一个都对应不上,那就相当于没有加载,【主要原因就是模型的key不一致,也就是层的名称不一致比如我使用的是resnet模型,那么层名应该是conv1.weight而不是module.conv1.weight】
那么如何解决呢:
net就是你实例化的模型名字
checkpoint指的是前面提到的“ckpt”也就是预训练权重。
net.load_state_dict({k.replace('module.',''):v for k,v in checkpoint['state_dict'].items()})附录:
在PyTorch中,使用torch.load()函数加载的预训练模型权重确实是一个字典类型,这个字典被称为状态字典(state_dict)。状态字典包含了模型中所有可学习参数(如权重和偏置)的键值对,键通常是参数的名称,值则是对应的Tensor(包含实际的数值)。
当你从文件中加载预训练权重时,代码通常看起来像这样:
pretrained_weights_path = 'path_to_pretrained_model.pth'
state_dict = torch.load(pretrained_weights_path)这里的state_dict就是包含了模型权重的字典。之后,你可以通过model.load_state_dict(state_dict)来将这些权重加载到你的模型中,前提是你模型的结构与预训练模型的结构相匹配,或者你已经适当地处理了任何不匹配的情况。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » CV08_深度学习模块之间的缝合教学(3)--加载预训练权重

发表评论 取消回复