实现线性不可分logistic逻辑回归
我们目前所学的都是线性回归,例如
y
=
w
1
x
1
+
w
2
x
2
+
b
y = w_1x_1+w_2x_2+b
y=w1x1+w2x2+b
用肉眼来看数据集的话不难发现,线性回归没有用了,那么根据课程所学,我们是不是可以增加
x
3
=
x
1
x
x
,
x
4
=
x
1
2
,
x
5
=
x
2
2
x_3=x_1x_x,x_4=x_1^2,x_5=x_2^2
x3=x1xx,x4=x12,x5=x22呢?那么逻辑回归就可以变成
y
=
w
1
x
1
+
w
2
x
2
+
w
3
x
3
+
w
4
x
4
+
w
5
x
5
+
b
y=w_1x_1+w_2x_2+w_3x_3+w_4x_4+w_5x_5+b
y=w1x1+w2x2+w3x3+w4x4+w5x5+b
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
def sigmoid(x):
return 1/(1+np.exp(-x))
def compute_loss(X, y, w, b, lambada):
m = X.shape[0]
cost = 0.
cost_gradient = 0.
for i in range(m):
z_i = sigmoid((np.dot(X[i], w) + b))
cost += -y[i] * np.log(z_i) - (1 - y[i]) * np.log(1 - z_i)
cost_gradient += w[i] ** 2
return cost / m + lambada * cost_gradient / (2 * m)
def compute_gradient_logistic(X, y, w, b, eta, lambada):
m, n = X.shape
db_w = np.zeros(n)
db_b = 0
for i in range(m):
z_i = sigmoid((np.dot(X[i], w) + b))
err_i = z_i - y[i]
for j in range(n):
db_w[j] += err_i * X[i][j]
db_b += err_i
return db_w / m, db_b / m
def gradient_descent(X, y, w, b, eta, lambada, iterator):
m, n = X.shape
for i in range(iterator):
w_tmp = np.copy(w)
b_tmp = b
db_w, db_b = compute_gradient_logistic(X, y, w_tmp, b, eta, lambada)
db_w += lambada * w / m
w = w - eta * db_w
b = b - eta * db_b
return w, b
if __name__ == '__main__':
data = pd.read_csv(r'D:\BaiduNetdiskDownload\data_sets\ex2data2.txt')
X_train = data.iloc[:, 0:-1].to_numpy()
y_train = data.iloc[:, -1].to_numpy()
x1 = (X_train[:, 0] * X_train[:, 1]).reshape(-1, 1)
x2 = (X_train[:, 0] ** 2).reshape(-1, 1)
x3 = (X_train[:, 1] ** 2).reshape(-1, 1)
X_train = np.hstack((X_train, x1, x2, x3))
w_tmp = np.zeros_like(X_train[0])
b_tmp = 0.
alph = 0.1
lambada = 0.01
iters = 10000
w_out, b_out = gradient_descent(X_train, y_train, w_tmp, b_tmp, alph, lambada, iters)
count = 0
for i in range(X_train.shape[0]):
ans = sigmoid(np.dot(X_train[i], w_out) + b_out)
prediction = 1 if ans > 0.5 else 0
if y_train[i] == prediction:
count += 1
print('Accuracy = {}'.format(count/X_train.shape[0]))
print(w_out, b_out)
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train)
# 绘制决策边界
x_min, x_max = X_train[:, 0].min() - 0.1, X_train[:, 0].max() + 0.1
y_min, y_max = X_train[:, 1].min() - 0.1, X_train[:, 1].max() + 0.1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01),
np.arange(y_min, y_max, 0.01))
# 创建与网格形状匹配的特征
grid = np.c_[xx.ravel(), yy.ravel()]
print('grid_shape : {}'.format(grid.shape))
grid_x1 = (grid[:, 0] * grid[:, 1]).reshape(-1, 1)
grid_x2 = (grid[:, 0] ** 2).reshape(-1, 1)
grid_x3 = (grid[:, 1] ** 2).reshape(-1, 1)
grid_features = np.hstack((grid, grid_x1, grid_x2, grid_x3))
# 计算网格点的预测值
Z = sigmoid(np.dot(grid_features, w_out) + b_out)
Z = Z.reshape(xx.shape)
# 绘制决策边界
plt.contour(xx, yy, Z, levels=[0.5], colors='g')
# 显示图形
plt.xlabel('x1')
plt.ylabel('x2')
plt.title('Decision Boundary')
plt.show()
一些图
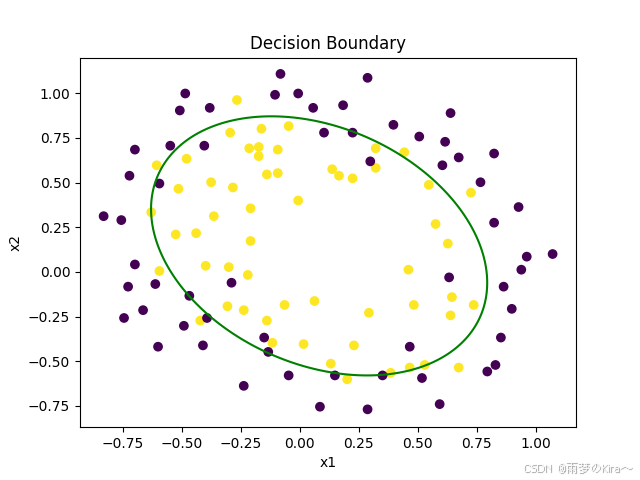
Accuracy = 0.8376068376068376
然后就是各个参数w1,w2,w3,w4,b
[ 2.12915132 2.82388529 -4.83135528 -8.64819153 -8.31828602] 3.7305124000753627
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【机器学习】Exam4

发表评论 取消回复