今天是24天,学习了LSTM+CRF序列标注。
LSTM + CRF 序列标注
LSTM(Long Short-Term Memory)是一种特殊类型的循环神经网络(RNN),能够处理长序列数据中的长期依赖关系。
CRF(Conditional Random Field)是一种概率图模型,常用于序列标注任务,如命名实体识别、词性标注等。
将 LSTM 与 CRF 结合用于序列标注具有以下优势:
- 处理长序列:LSTM 能够有效地捕捉长距离的上下文信息,避免了传统 RNN 中的梯度消失或梯度爆炸问题。
- 学习序列特征:LSTM 可以自动学习输入序列中的特征表示。
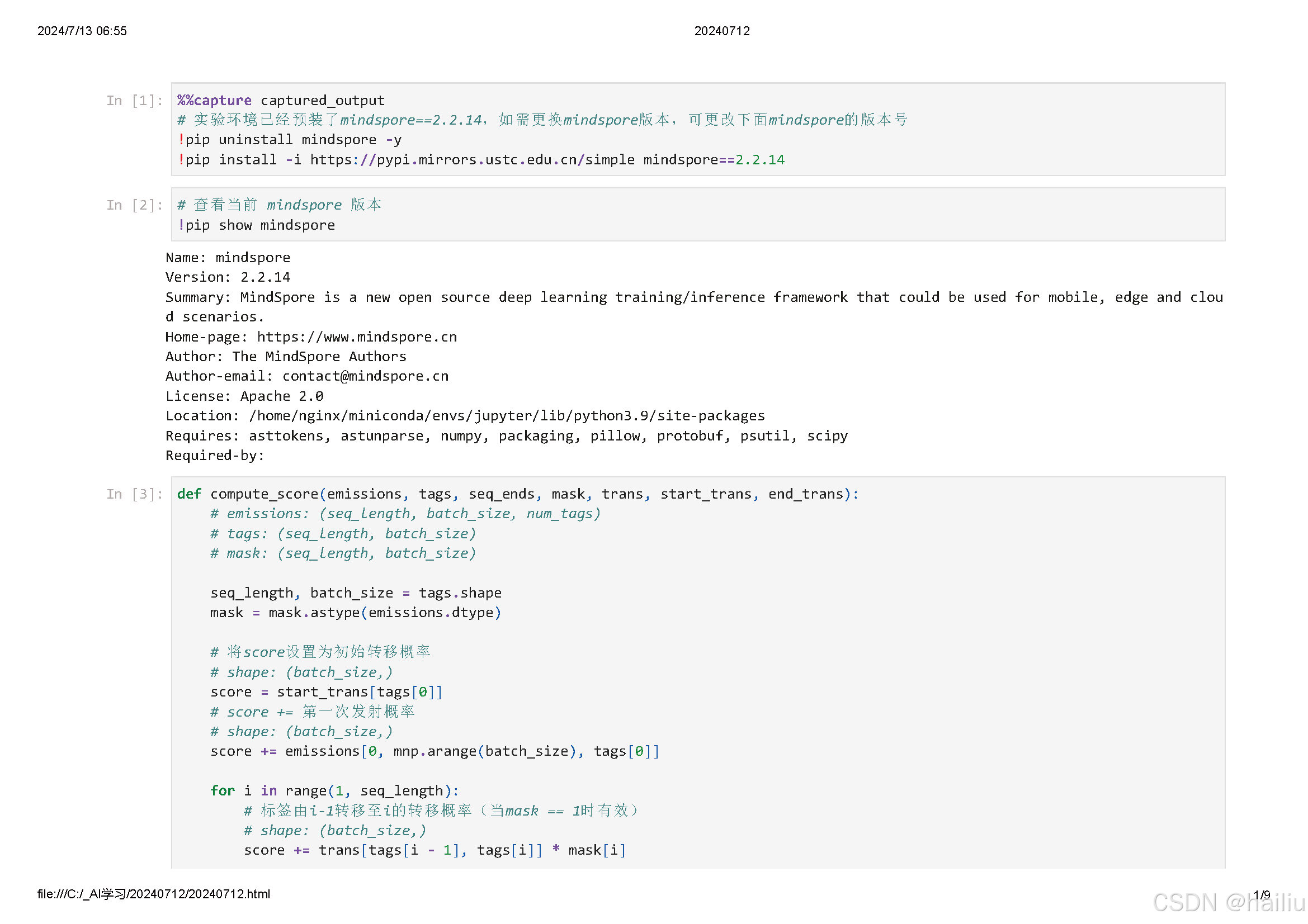
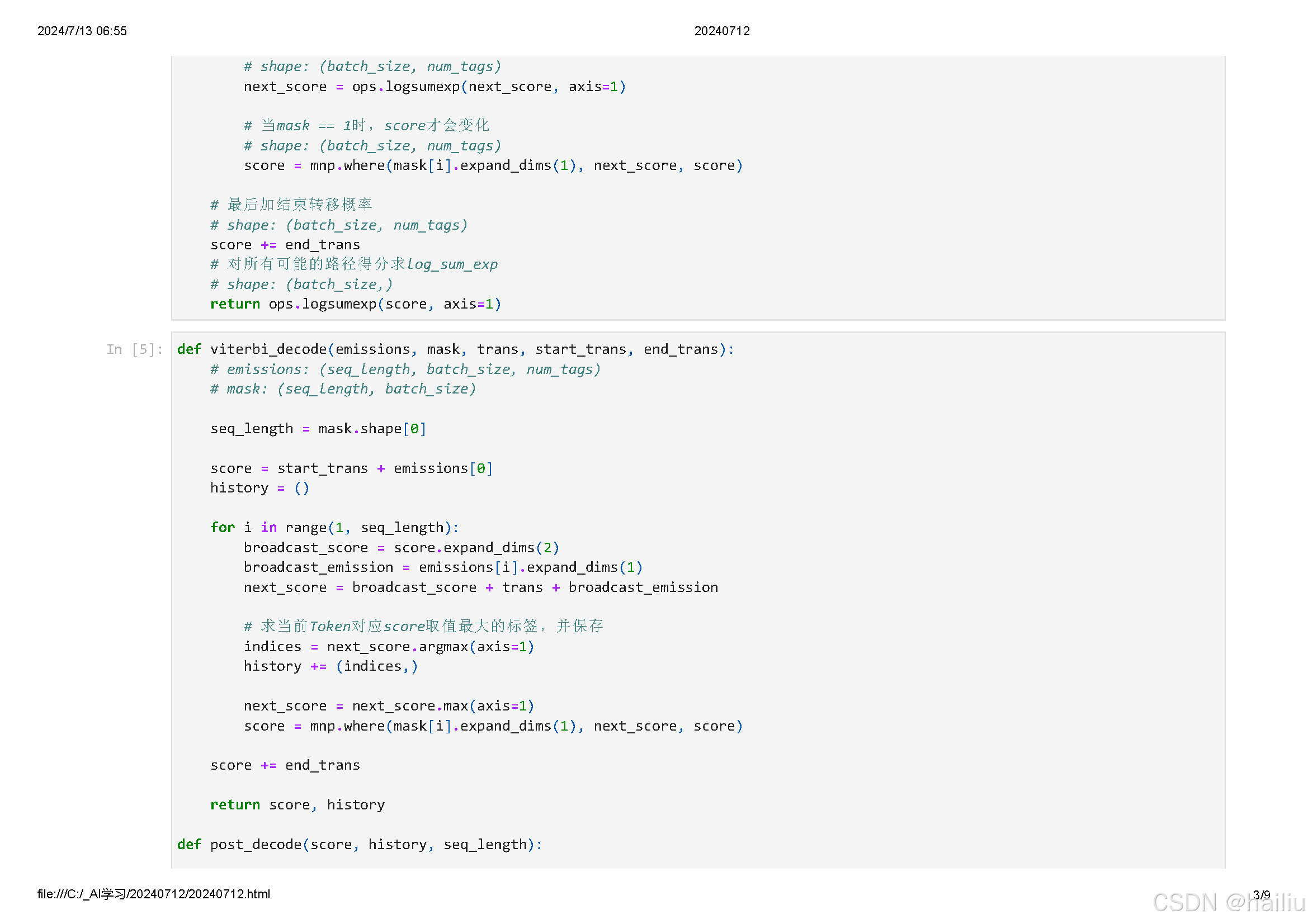
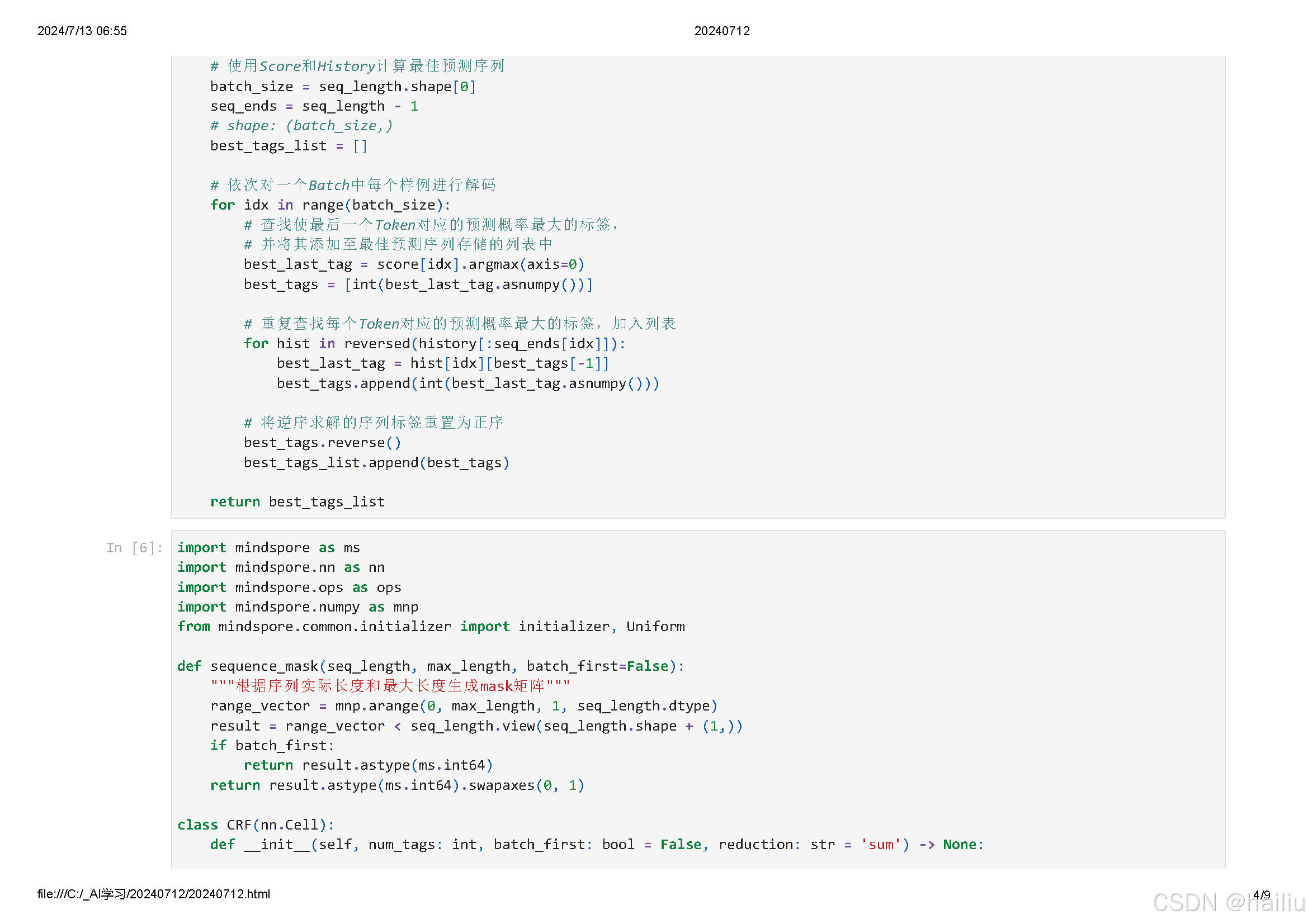
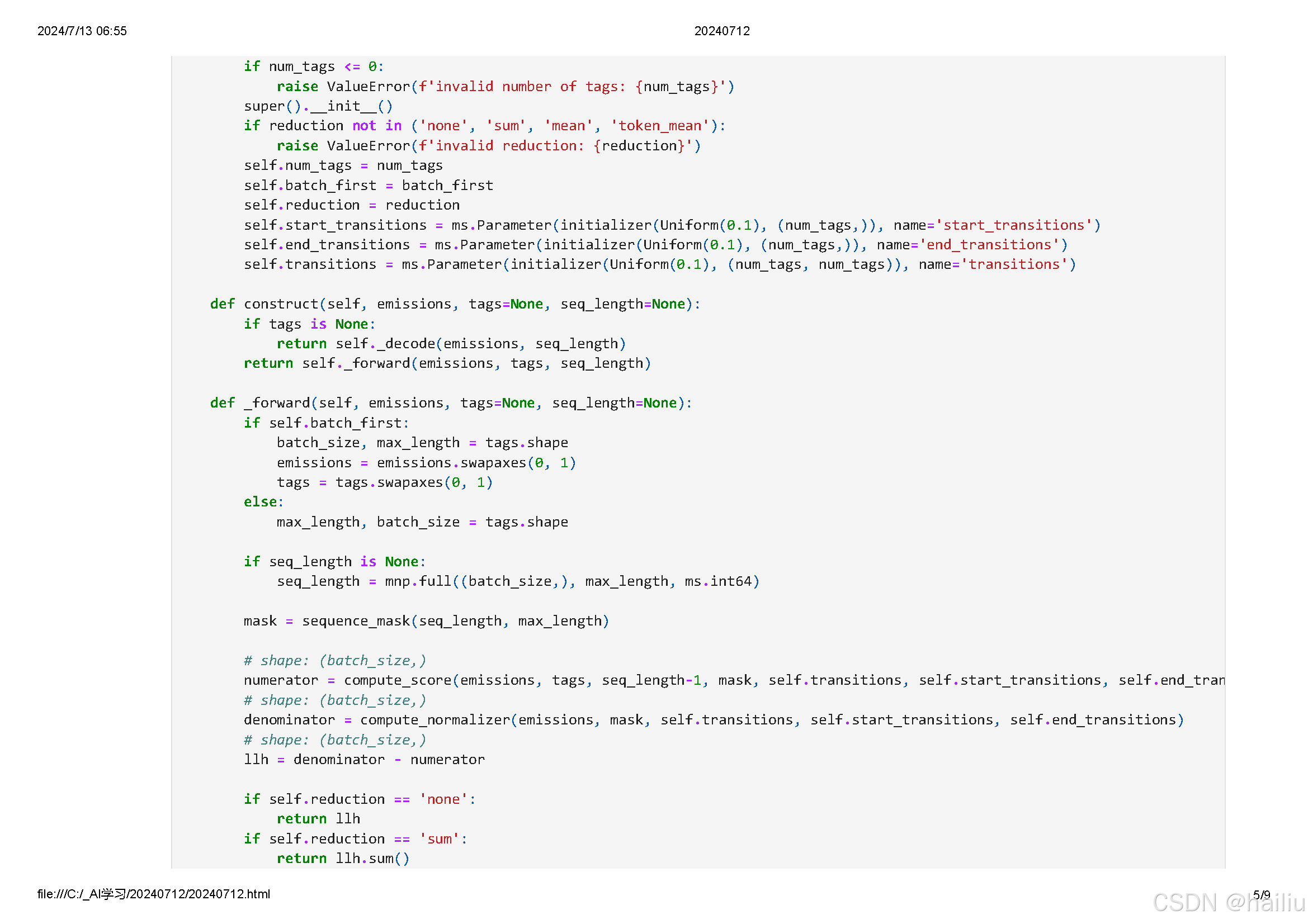
- 利用全局约束:CRF 考虑了整个序列的标签之间的约束关系,例如,在命名实体识别中,“B-PER”(人名开始)后面不太可能直接跟着 “O”(非实体),CRF 可以利用这些约束来优化最终的预测结果,提高标注的准确性。
例如,在情感分析任务中,输入的文本序列经过 LSTM 学习到特征后,CRF 可以根据情感标签之间的逻辑关系(如积极情感之后更可能是积极情感)来优化最终的标签预测。
在词性标注中,LSTM 学习单词的上下文特征,CRF 则确保标注结果符合语法规则和常见的词性序列模式。
LSTM + CRF 这种组合在序列标注任务中表现出色,能够提高模型的性能和标注的准确性。
LSTM + CRF 序列标注与传统方法相比的优势
传统的序列标注方法,如基于规则的方法和简单的统计模型,存在一些局限性。
相比之下,LSTM + CRF 具有以下显著优势:
1. 更强的特征学习能力:
- 传统方法通常依赖于人工设计的特征,这些特征可能无法充分捕捉复杂的语义和上下文信息。而 LSTM 能够自动从输入序列中学习到深层次的特征表示,从而更好地理解数据的内在模式。
- 例如,对于文本序列,LSTM 可以学习到单词之间的依赖关系和长距离的语义关联。
2. 处理长序列数据:
- 传统方法在处理长序列时可能会遇到梯度消失或梯度爆炸的问题,导致无法有效地捕捉远距离的依赖关系。LSTM 则通过其特殊的门控机制有效地解决了这个问题,能够处理较长的序列数据,并保持对早期信息的记忆。
- 比如在分析一篇较长的文章进行词性标注时,LSTM + CRF 能够更好地考虑到整篇文章的上下文信息。
3. 考虑全局最优:
- CRF 层可以引入全局的约束条件,使得预测的标签序列在整个序列上是最优的,而不仅仅是局部最优。这在传统方法中往往难以实现。
- 以命名实体识别为例,传统方法可能会出现实体边界标注不一致的情况,而 LSTM + CRF 能够更好地保证实体标注的完整性和一致性。
4. 适应性和泛化能力:
- LSTM + CRF 可以通过大量的数据进行训练,从而适应不同领域和任务的序列标注需求,具有更强的泛化能力。
- 无论是在自然语言处理中的不同语言,还是在生物信息学中的序列标注,LSTM + CRF 都可以通过调整训练数据来适应新的任务。
5. 端到端的学习:
- 这种组合方法可以实现端到端的学习,无需像传统方法那样进行多个步骤的特征工程和模型训练,简化了流程并提高了效率。
LSTM + CRF 序列标注在特征学习、长序列处理、全局优化、适应性和端到端学习等方面表现出明显的优势,从而在各种序列标注任务中取得了更好的性能。


本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 昇思25天学习打卡营第24天 | LSTM+CRF序列标注

发表评论 取消回复