今天我们来聊聊一个上了热搜的问题,这个问题看似简单,却让不少 AI 大模型“翻车”的问题:9.11 和 9.9,哪个大?
问题的由来
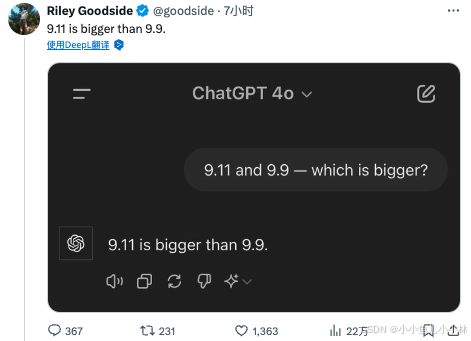
这个问题最初是由一位名叫 Riley Goodside 的工程师提出的。Riley 是一家 AI 数据标注公司的“大牛”,专门负责设计那些能引导 AI 模型回答问题的提示(prompt)。他发现了一个有趣的现象:当他用“9.11 and 9.9 - which is bigger?”(9.11 和 9.9,哪个大?)这个问题去问一些 AI 大模型时,结果让人大跌眼镜。
国外大模型的表现

国外一些知名的 AI 大模型是怎么回答这个问题的。
- ChatGPT 4o:它毫不犹豫地说,9.11 大于 9.9。
- Gemini Advanced:同样给出了 9.11 大于 9.9 的答案。
- Claude 3.5 Sonnet:虽然一开始解释得头头是道,但最后还是说 9.11 大于 9.9。
这些答案显然都是错误的,因为 9.9 明显比 9.11 大。但为什么这些 AI 大模型会犯这样的错误呢?我在文末会给出答案
国产大模型的表现
国内的 AI 大模型是怎么表现的。
- 阿里的通义千问:不仅给出了正确的答案,还详细解释了为什么 9.9 大于 9.11。
- 百度文心一言:同样正确地指出 9.9 大于 9.11。
- 腾讯元宝、昆仑万维的天工、科大讯飞的星火大模型、360 智脑和百川智能:这些模型也都给出了正确的答案。
看来在这个问题上,国产大模型表现得相当不错。
错误原因分析
那么,为什么那些国外大模型会犯这样的错误呢?因为这些模型在比较数字时,错误地将整数部分和小数部分分开比较。它们先比较整数部分(都是 9),然后错误地认为 11 大于 9,从而得出了 9.11 大于 9.9 的结论。
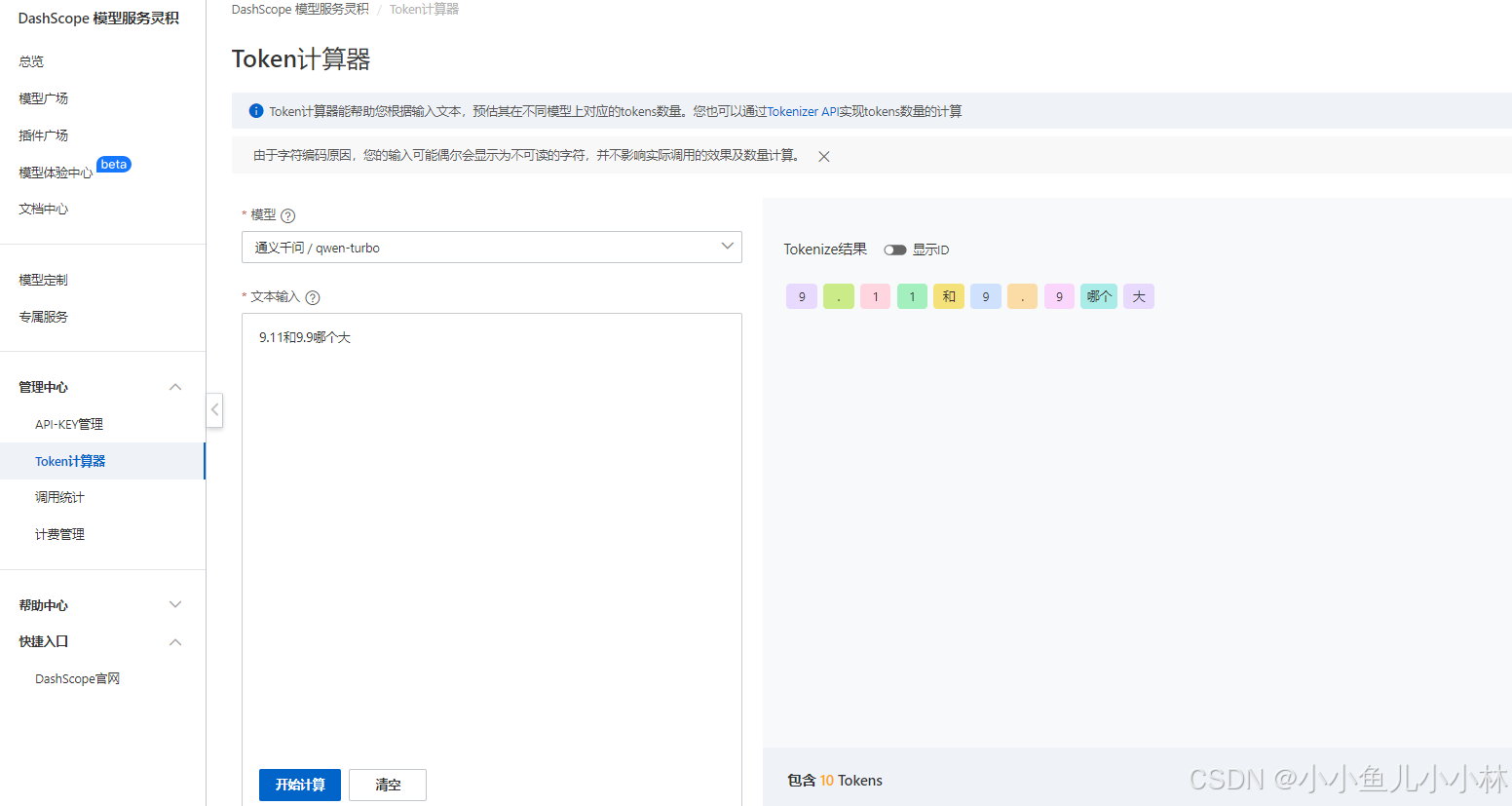
我给大家上一个图,大家就知道了
我们使用阿里通义千问 的token计算工具:
https://dashscope.console.aliyun.com/tokenizer
除了上述原因,其实还有一个原因,所以大模型语言之所以叫做大模型语言,是因为它是一个文科生,它对任何内容都是以文字内容去理解的,这时候,你要是突然来一个数学题或者推理题,它就不会了,因为它没有学过数学。不像我们人类来讲,大脑有两个区域,一个是负责记忆系统,就是传统的内容知识,顾名思义就是背诵的内容,类似红灯停绿灯行;还有一个就是思维推理系统,就是负责运算和推理的,一旦告诉你某个知识点,你要按照这个规则去运算后面类似的运算,比如告诉你加法是个位相加,十位相加,然后让你算111+222等于几的时候,你就会类比推理。但是大模型就不会这个能力了,它只能是一个记忆系统,去搜索有没有111+222的答案,如果出现过了,那就直接告诉你答案,如果没有出现过,那就只能以文字的逻辑去告诉你等于多少
那为什么国内的大模型能够正确回答呢,那是因为做过这方面的训练,简单的内容大模型就会去按照你给的推理步骤一步步去计算了,但是如果你出一点难一点的数学题,他们还是不会算对的。
正因为如此,大模型之路其实还有很长的一段路要走,我还是挺期待通用大模型的来临的
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 简单讲讲为什么大模型会回答9.11大于9.9

发表评论 取消回复