一、解决方案
1、在数据采集的时候,就将小文件或小批数据合成大文件再上传HDFS(数据源头)
2、Hadoop Archive(存储方向)
是一个高效的将小文件放入HDFS块中的文件存档工具,能够将多个小文件打包成一个HAR文件,从而达到减少NameNode的内存使用
3、CombineTextInputFormat(计算方向)
CombineTextInputFormat用于将多个小文件在切片过程中生成一个单独的切片或者少量的切片
4、开启uber模式,实现JVM重用(计算方向)
默认情况下,每个Task任务都需要启动一个JVM来运行,如果Task任务计算的数据量很小,我们可以让同一个Job的多个Task运行在一个JVM中,不必为每个Task都开启一个JVM。也就是JVM重用。
二、案例
1、未开启uber模式
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input/hello.txt /output1
2、观察控制台
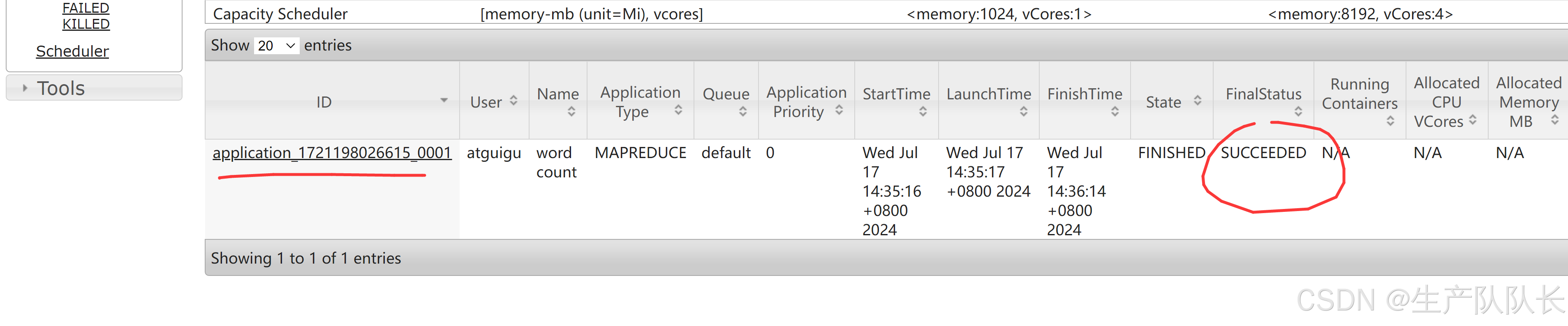
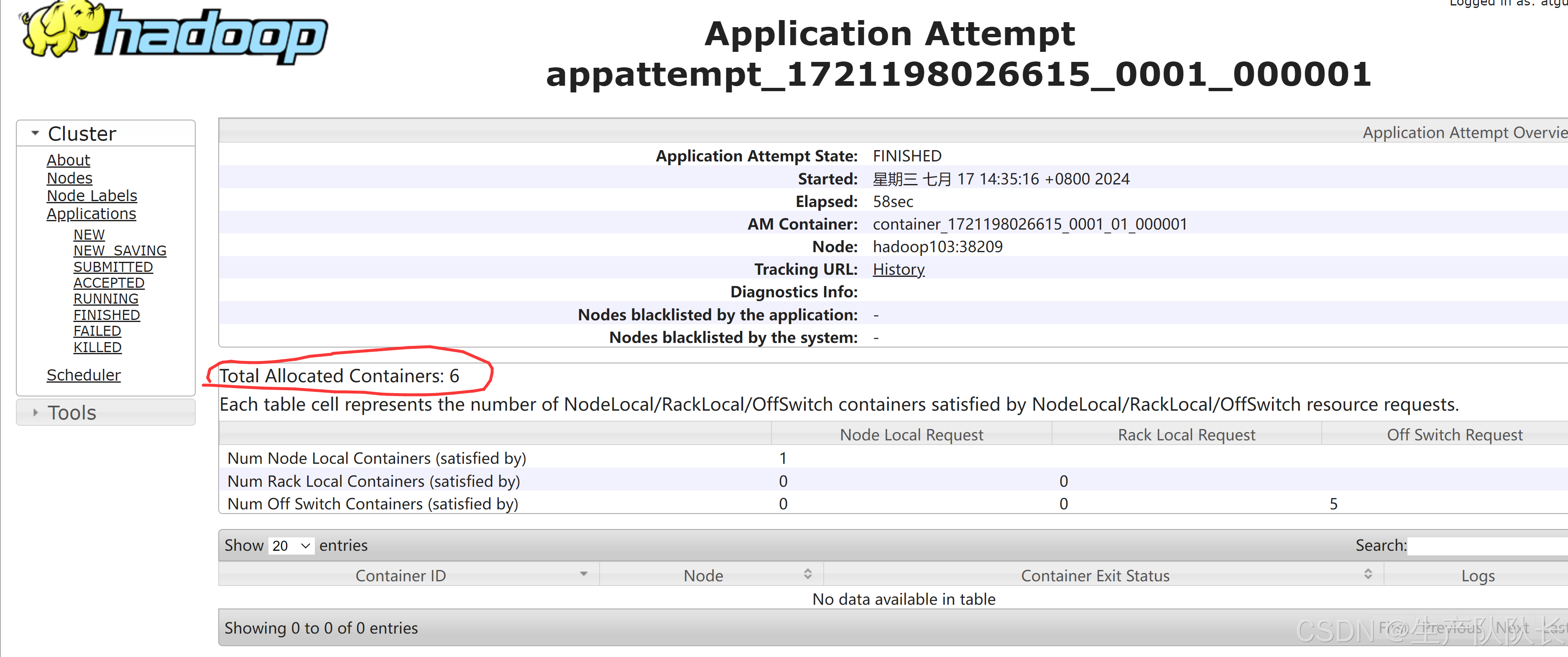
3、查看页面任务
发现这个任务,启用了6个Container容器,也就意味着开启了6个JVM。
4、开启uber模式mapred-site.xml

<!-- 开启uber模式,默认关闭 -->
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<!-- uber模式中最大的mapTask数量,可向下修改 -->
<property>
<name>mapreduce.job.ubertask.maxmaps</name>
<value>9</value>
</property>
<!-- uber模式中最大的reduce数量,可向下修改 -->
<property>
<name>mapreduce.job.ubertask.maxreduces</name>
<value>1</value>
</property>
<!-- uber模式中最大的输入数据量,默认使用dfs.blocksize 的值,可向下修改 -->
<property>
<name>mapreduce.job.ubertask.maxbytes</name>
<value></value>
</property>
分发配置,无需重启。
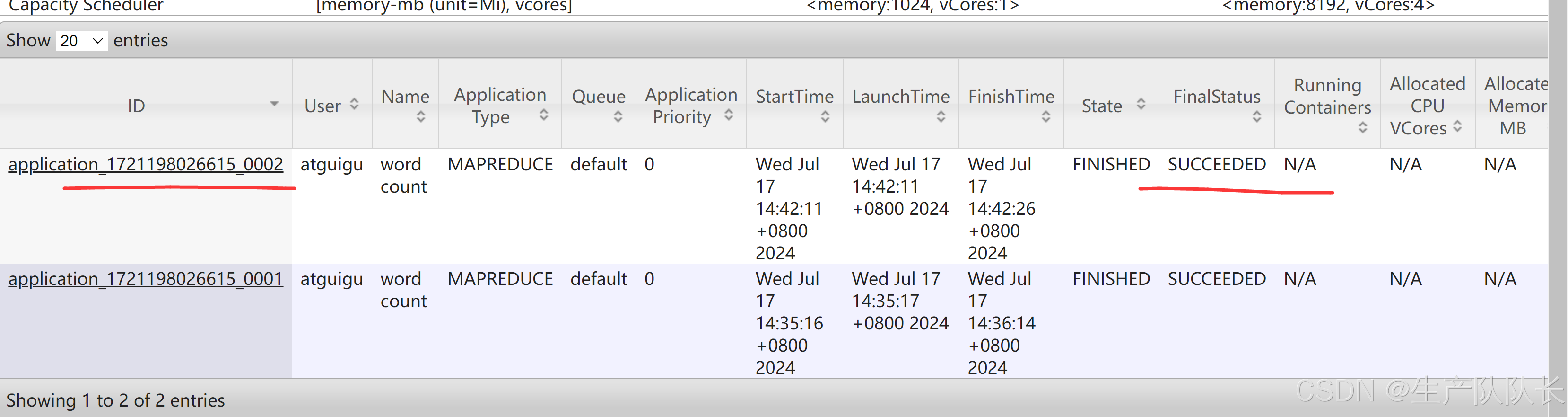
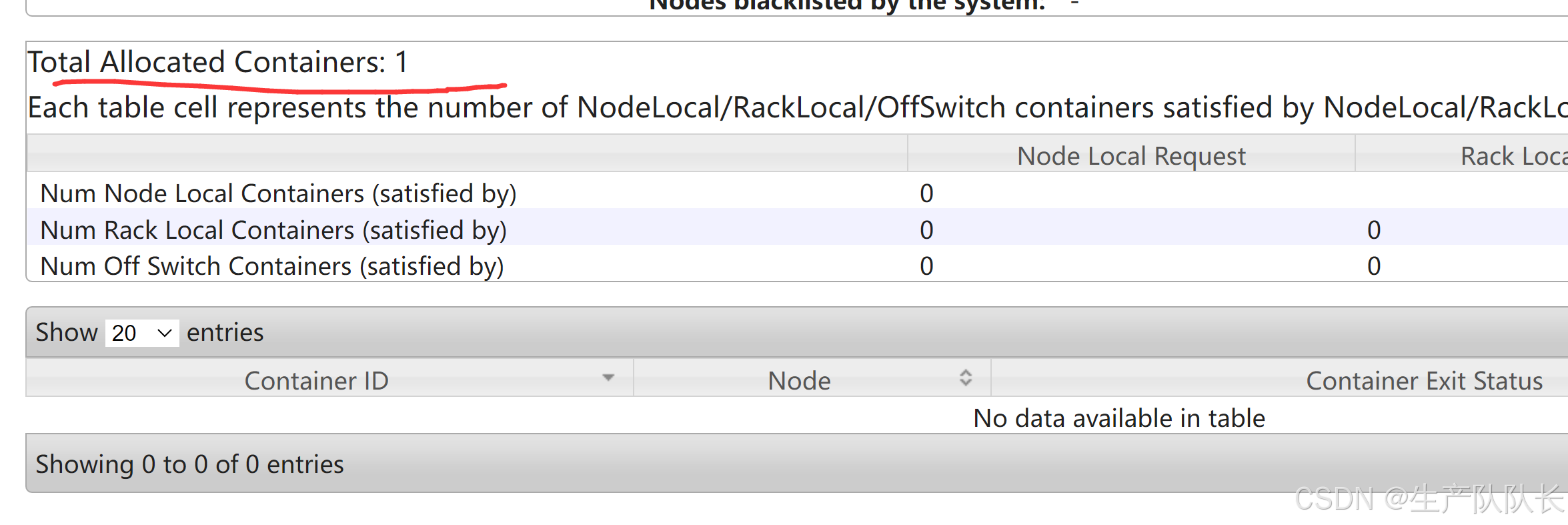
5、再次执行任务
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input/hello.txt /output1
发现,只启用了一个容器。

本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Hadoop3:MR程序处理小文件的优化办法(uber模式)

发表评论 取消回复