大数据开发之Hadoop
大数据的核心工作、软件生态
| 大数据的核心工作 | 解释 | 大数据软件生态 |
|---|---|---|
| 存储 | 妥善保存海量待处理数据 | Apache Hadoop HDFS、Apache HBase、Apache Kudu、云平台 |
| 计算 | 完成海量数据的价值挖掘 | Apache Hadoop MapReduce、Apache Spark、Apache Flink |
| 传输 | 协助各个环节的数据传输 | fApache Kafka、Apache Pulsar、Apache Flume、Apache Sqoop |
Hadoop的发展
Hadoop创始人:Doug Cutting
Hadoop起源于Apache Lucene子项目:Nutch:Nutch的设计目标是构建一个大型的全网搜索引擎。遇到瓶颈:如何解决数十亿网页的存储和索引问题
Google三篇论文:
-
《The Google file system》:谷歌分布式文件系统GFS
-
《MapReduce: Simplified Data Processing on Large Clusters》:谷歌分布式计算框架MapReduce
-
《Bigtable: A Distributed Storage System for Structured Data》:谷歌结构化数据存储系统
Hadoop商业发行版本:
- CDH(Cloudera’s Distribution, including Apache Hadoop) Cloudera公司出品,目前使用最多的商业版
- HDP(Hortonworks Data Platform),Hortonworks公司出品,目前被Cloudera收购
- 星环,国产商业版,星环公司出品,在国内政企使用较多
Hadoop的三个功能组件
- HDFS组件:HDFS是Hadoop内的分布式存储组件。可以构建分布式文件系统用于数据存储
- MapReduce组件:MapReduce是Hadoop内分布式计算组件。提供编程接口供用户开发分布式计算程序
- YARN组件:YARN是Hadoop内分布式资源调度组件。可供用户整体调度大规模集群的资源使用。
一、HDFS 分布式文件系统
HDFS全称:Hadoop Distributed File System
是Hadoop三大组件(HDFS、MapReduce、YARN)之一
可在多台服务器上构建集群,提供分布式数据存储能力文件系统协议
file://表示Linux本地文件hdfs://namenode_server:port/表示HDFS文件系统
比如当前集群表示为:hdfs://node1:8020/。一般可以省略file://和hdfs://协议头,不用写
1、HDFS的基础架构
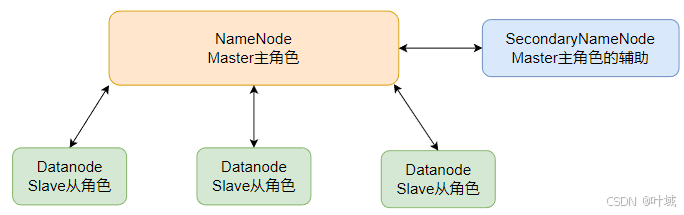
NameNode:主角色,负责管理HDFS整个文件系统 和 DataNode
Datanode:从角色,主要负责数据的存储,即存入数据和取出数据
SecondaryNameNode: 辅助角色,主要帮助NameNode完成元数据整理工作(打杂)
2、HDFS基础操作命令
HDFS同Linux系统一样,均是以/作为根目录的组织形式
官方文档:Apache Hadoop 3.3.4 – Overview
hdfs dfs [generic options]
# 创建文件夹
hdfs dfs -mkdir [-p] <path> ... # -p选项的行为与Linux mkdir -p一致,它会沿着路径创建父目录。
# 查看指定目录下内容
hdfs dfs -ls [-h] [-R] [<path> ...] # -h 人性化显示文件size、-R 递归查看指定目录及其子目录
# 上传文件到HDFS指定目录下
hdfs dfs -put [-f] [-p] <localsrc> ... <dst>
# 查看HDFS文件内容
hdfs dfs -cat <src> ...
# 读取大文件可以使用管道符配合more
hdfs dfs -cat <src> | more
# 下载HDFS文件
hdfs dfs -get [-f] [-p] <src> ... <localdst>
# 下载文件到本地文件系统指定目录,localdst必须是目录
# 拷贝HDFS文件
hdfs dfs -cp [-f] <src> ... <dst>
# 追加数据到HDFS文件中
hdfs dfs -appendToFile <localsrc> ... <dst> # 如果<localSrc>为-,则输入为从标准输入中读取、 dst如果文件不存在,将创建该文件。
# HDFS数据移动操作
hdfs dfs -mv <src> ... <dst>
# HDFS数据删除操作
hdfs dfs -rm -r [-skipTrash] URI [URI ...] # -skipTrash 跳过回收站,直接删除
-
path为待创建的目录 -
-f覆盖目标文件(已存在下) -
-p保留访问和修改时间,所有权和权限。 -
localsrc本地文件系统(客户端所在机器) -
dst目标文件系统(HDFS)
3、HDFS WEB浏览:
http://node1:9870
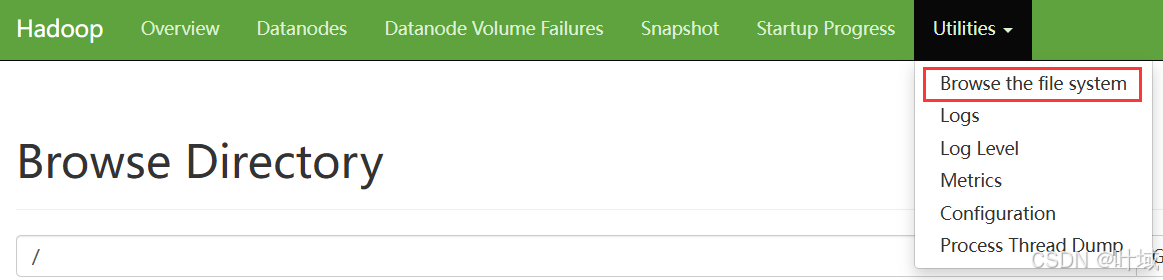
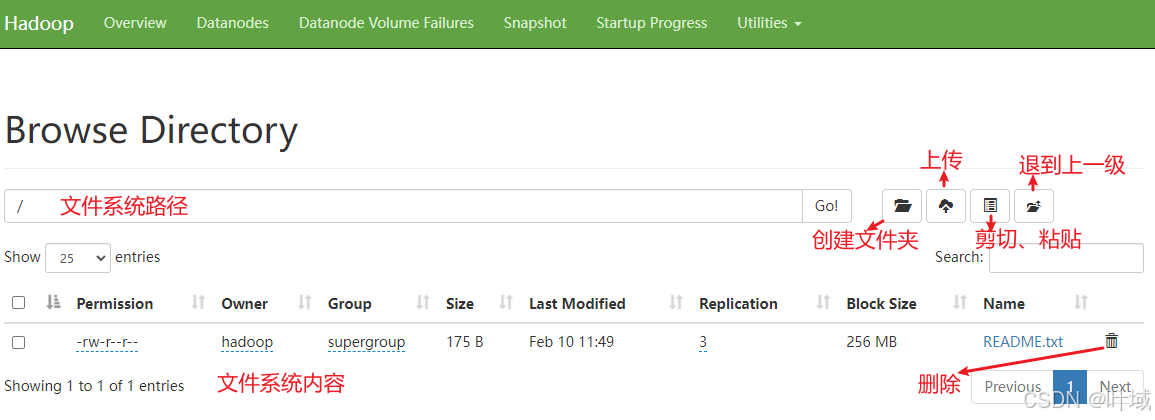
使用WEB浏览操作文件系统,一般会遇到权限问题

这是因为WEB浏览器中是以匿名用户(dr.who)登陆的,其只有只读权限,多数操作是做不了的。如果需要以特权用户在浏览器中进行操作,需要配置如下内容到core-site.xml并重启集群
<property>
<name>hadoop.http.staticuser.user</name>
<value>username</value>
</property>
不推荐这样做。HDFS WEBUI,只读权限挺好的,简单浏览即可,如果给与高权限,会有很大的安全问题,造成数据泄露或丢失
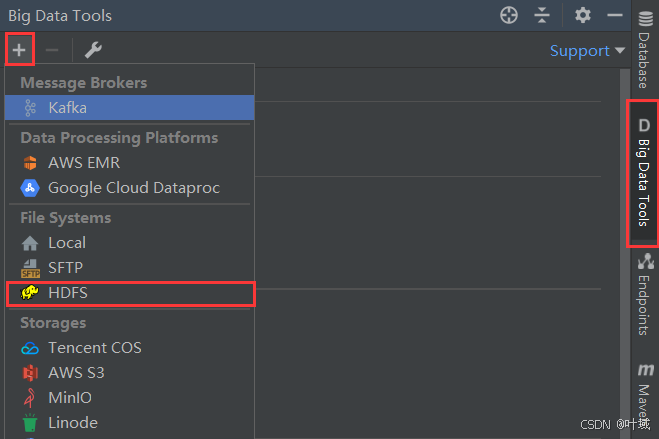
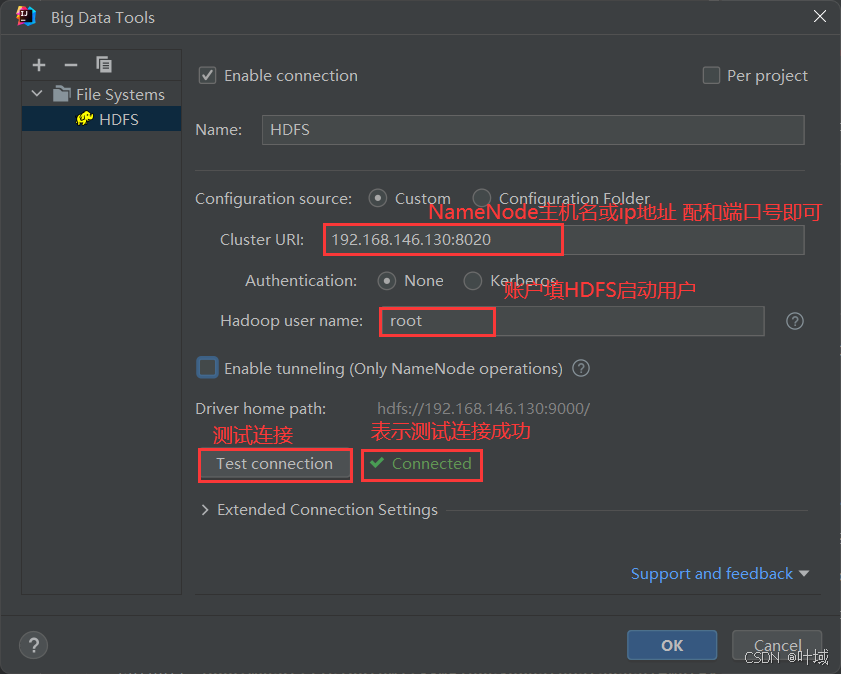
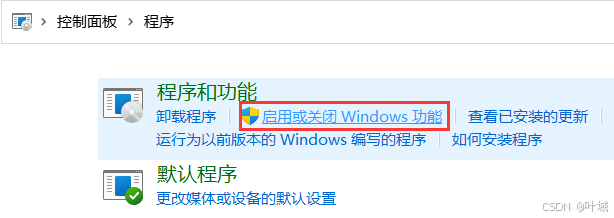
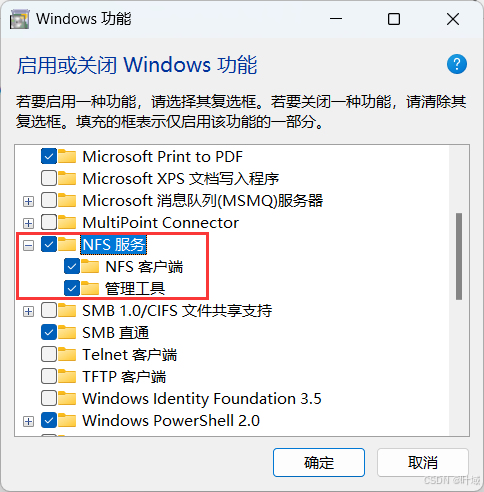
4、Big Data Tools插件
在Jetbrains的产品中,均可以安装插件,其中:Big Data Tools插件可以帮助我们方便的操作HDFS
-
下载插件
在设置->Plugins(插件)-> Marketplace(市场),搜索Big Data Tools,点击Install安装即可
-
需要对Windows系统做一些基础设置,配合插件使用
- 解压Hadoop安装包到Windows系统,如解压到:E:\hadoop-3.3.4
- 设置$HADOOP_HOME环境变量指向:E:\hadoop-3.3.4
- 下载 hadoop.dll winutils.exe
- 将hadoop.dll和winutils.exe放入E:\hadoop-3.3.4/bin中
- 重启IDEA
-
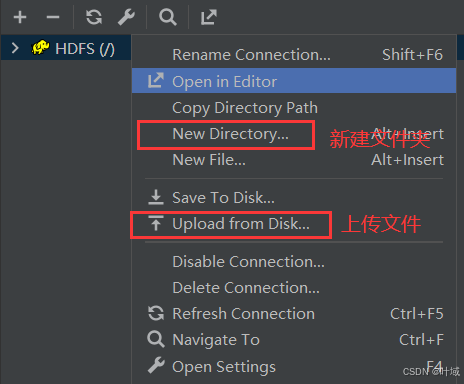
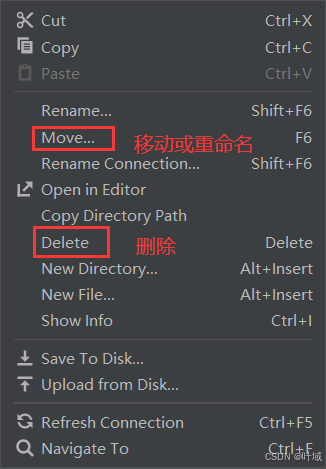
插件使用
还可以插看和在修改文件内容
5、使用NFS网关功能将HDFS挂载到本地系统
HDFS提供了基于NFS(Network File System)的插件,可以对外提供NFS网关,供其它系统挂载使用。
NFS 网关支持 NFSv3,并允许将 HDFS 作为客户机本地文件系统的一部分挂载,现在支持:上传、下载、删除、追加内容
如下图,将HDFS挂载为Windows文件管理器的网络位置,(NFS功能需要windows专业版)
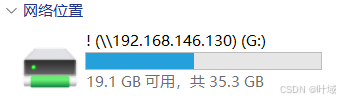
-
在
core-site.xml内新增如下两项<!-- 允许hadoop用户代理任何其它用户组 --> <property> <name>hadoop.proxyuser.[username].groups</name> <value>*</value> </property> <!-- 允许代理任意服务器的请求 --> <property> <name>hadoop.proxyuser.[username].hosts</name> <value>*</value> </property> -
在
hdfs-site.xml中新增如下项<!-- NFS操作HDFS系统,所使用的超级用户(hdfs的启动用户为超级用户) --> <property> <name>nfs.superuser</name> <value>[username]</value> </property> <!-- NFS接收数据上传时使用的临时目录 --> <property> <name>nfs.dump.dir</name> <value>/tmp/.hdfs-nfs</value> </property> <!-- NFS允许连接的客户端IP和权限,rw表示读写,IP整体或部分可以以*代替 --> <!-- 192.168.88.1这个IP是电脑虚拟网卡VMnet8的IP,连接虚拟机就走这个网卡 --> <property> <name>nfs.exports.allowed.hosts</name> <value>192.168.88.1 rw</value> </property> -
将配置好的
core-site.xml和hdfs-site.xml分发到其他节点、重启Hadoop HDFS集群(先stop-dfs.sh,后start-dfs.sh) -
停止系统的NFS相关进程
systemctl stop nfs systemctl disable nfs # 关闭系统nfs并关闭其开机自启 yum remove -y rpcbind # 卸载系统自带rpcbind -
启动portmap(HDFS自带的rpcbind功能)(必须以root执行)
hdfs --daemon start portmap -
启动nfs(HDFS自带的nfs功能)(必须以hadoop用户执行)
hdfs --daemon start nfs3 -
开启Windows的NFS功能
此功能需要专业版,如果是家庭版Windows需要升级为专业版
-
在Windows命令提示符(CMD)内输入
net use G: \\192.168.88.101\!192.168.88.101为 NameNode主机IP地址G:盘符名称(任意,与已有不重复即可) -
完成后即可在文件管理器中看到盘符为G的网络位置(见上图)
至此,就将HDFS挂载到Windows文件管理器内了可以进行上传、下载、改名、删除、追加文本等操作。
- 点击右键客户断开连接
6、HDFS数据存储
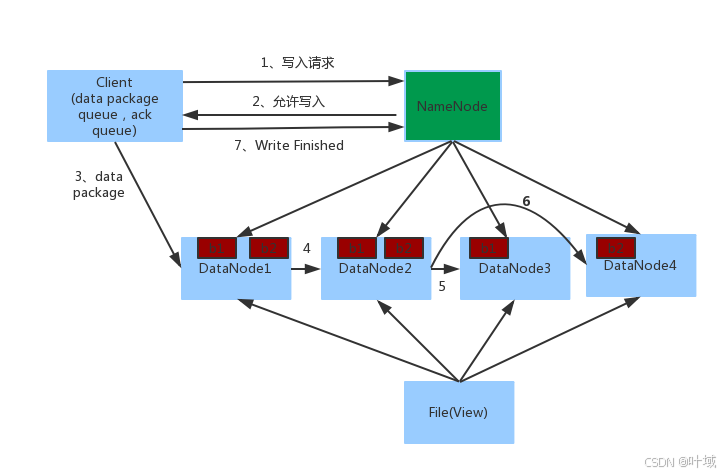
当客户端向 HDFS 写入文件时:
客户端向 NameNode 请求写操作。
NameNode审核权限、剩余空间后,满足条件允许写入,并告知客户端写入的DataNode地址
客户端将数据分成块,并将每个块写入到第一个 DataNode。
第一个 DataNode 将块复制到第二个 DataNode,第二个 DataNode 再复制到第三个 DataNode,依此类推,直到达到副本因子。
每个 DataNode 在成功存储块后,向 NameNode 发送报告。
当客户端从 HDFS 读取文件时:
客户端向 NameNode 请求读取操作。
NameNode判断客户端权限等细节后,允许读取,并返回此文件的block列表
客户端拿到block列表后自行寻找DataNode读取即可
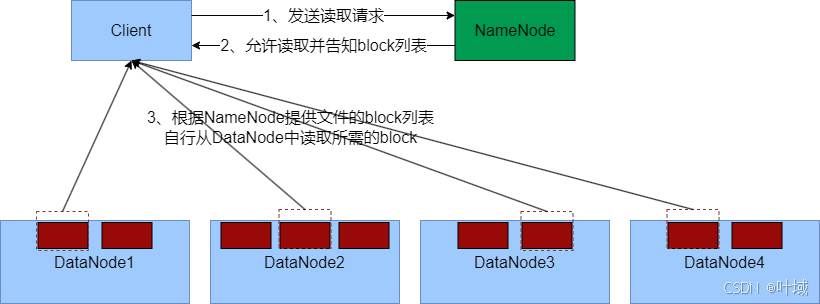
数据存储
HDFS 将文件拆分成多个块(默认块大小为 128MB),每个块被存储在不同的 DataNode 上:
- 块(Block):文件被分割成大小相等的数据块。块大小可以在 HDFS 配置中设置(通常为 128MB 或 256MB)。
- 副本(Replication):每个数据块会被复制到多个 DataNode 上(默认副本数为 3)。这种数据冗余提供了容错性和高可用性。
副本(Replication)
<!-- hdfs-site.xml中配置 设置默认文件上传到HDFS中拥有的副本数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
# 可以在上传文件的时候,临时决定被上传文件以多少个副本存储
hdfs dfs -D dfs.replication=2 -put test.txt /tmp/
# 对于已经存在HDFS的文件,修改dfs.replication属性不会生效, 如果要修改已存在文件可以通过命令
# 如下命令,指定path的内容将会被修改为2个副本存储
hdfs dfs -setrep [-R] 2 path # -R选项可选,使用-R表示对子目录也生效
# 使用hdfs提供的fsck命令来检查文件的副本数
hdfs fsck path [-files [-blocks [-locations]]]
-files可以列出路径内的文件状态-files -blocks输出文件块报告(有几个块,多少副本)-files -blocks -locations输出每一个block的详情
块(Block)
对于块(block),hdfs默认设置为256MB一个,也就是1GB文件会被划分为4个block存储。
<!-- hdfs-site.xml中配置 块大小可以通过参数 -->
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
<description>设置HDFS块大小,单位是b</description>
</property>
7、NameNode 元数据
NameNode基于edits和FSImage的配合,完成整个文件系统文件的管理。
- 每次对HDFS的操作,均被edits文件记录
- edits达到大小上线后,开启新的edits记录
- 定期进行edits的合并操作
如当前没有fsimage文件, 将全部edits合并为第一个fsimage
如当前已存在fsimage文件,将全部edits和已存在的fsimage进行合并,形成新的fsimage
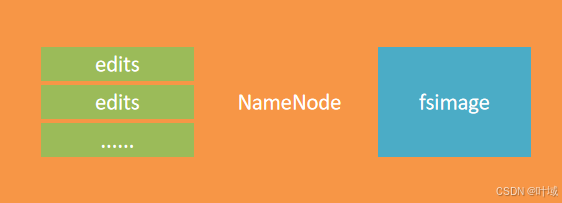
<!-- hdfs-site.xml中配置 元数据位置如下/data/nn/current -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/nn</value>
</property>
元数据合并控制参数
对于元数据的合并,是一个定时过程,基于:
dfs.namenode.checkpoint.period,默认3600(秒)即1小时dfs.namenode.checkpoint.txns,默认1000000,即100W次事务
即每1小时或发生100W次事务合并(有一个达到条件就执行)
检查是否达到条件,默认60秒检查一次,基于:
dfs.namenode.checkpoint.check.period,默认60(秒),来决定
8、SecondaryNameNode的作用
NameNode的元数据并不是有NameNode本身完成,NameNode不负责数据写入,只负责元数据记录和权限审批
SecondaryNameNode会通过http从NameNode拉取数据(edits和fsimage)
然后合并完成后提供给NameNode使用。
二、MapReduce 分布式计算
1、大数据体系内的计算, 举例:
销售额统计、区域销售占比、季度销售占比
利润率走势、客单价走势、成本走势
品类分析、消费者分析、店铺分析
数据太大,一台计算机无法独立处理、靠数量来取胜
计算:对数据进行处理,使用统计分析等手段得到需要的结果
分布式计算:多台服务器协同工作,共同完成一个计算任务
2、分布式(数据)计算 的两种模式
分散->汇总模式:(MapReduce就是这种模式)
-
将数据分片,多台服务器各自负责一部分数据处理
-
然后将各自的结果,进行汇总处理
-
最终得到想要的计算结果
中心调度->步骤执行模式:(大数据体系的Spark、Flink等是这种模式)
-
由一个节点作为中心调度管理者
-
将任务划分为几个具体步骤
-
管理者安排每个机器执行任务
-
最终得到结果数据
3、分布式计算框架 - MapReduce
MapReduce是“分散->汇总”模式的分布式计算框架,可供开发人员开发相关程序进行分布式数据计算。
提供了2个编程接口:Map 和 Reduce
- Map功能接口提供了“分散”的功能, 由服务器分布式对数据进行处理
- Reduce功能接口提供了“汇总(聚合)”的功能,将分布式的处理结果汇总统计
MapReduce执行原理 (单词统计样例)
假定有4台服务器用以执行MapReduce任务可以3台服务器执行Map,1台服务器执行Reduce
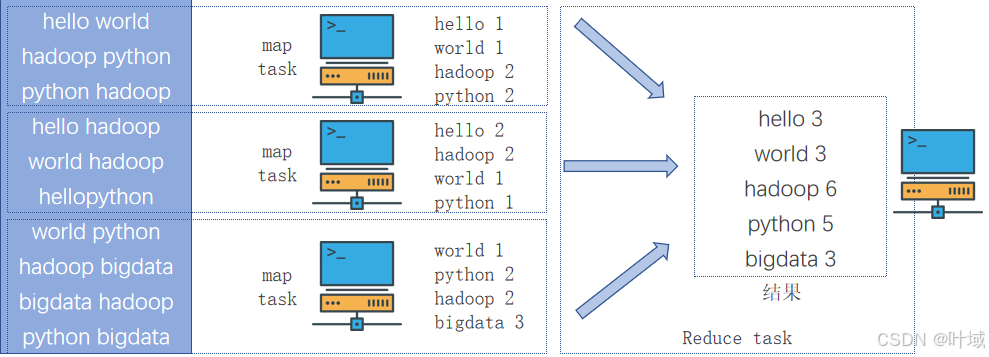
文件 将任务分解为:3个Map(分散) Task(任务) 1个Reduce(汇总) Task
三、Yarn 分布式资源调度
1、资源调度
- 资源:服务器硬件资源,如:CPU、内存、硬盘、网络等
- 资源调度:管控服务器硬件资源,提供更好的利用率
- 分布式资源调度:管控整个分布式服务器集群的全部资源,整合进行统一调度
对于资源的利用,有规划、有管理的调度资源使用,是效率最高的方式
YARN 管控整个集群的资源进行调度, 那么应用程序在运行时,就是在YARN的监管(管理)下去运行的。
这就像:全部资源都是公司(YARN)的,由公司分配给个人(具体的程序)去使用。
YARN用来调度资源给MapReduce分配和管理运行资源,所以,MapReduce需要YARN才能执行(普遍情况)
2、Yarn核心架构
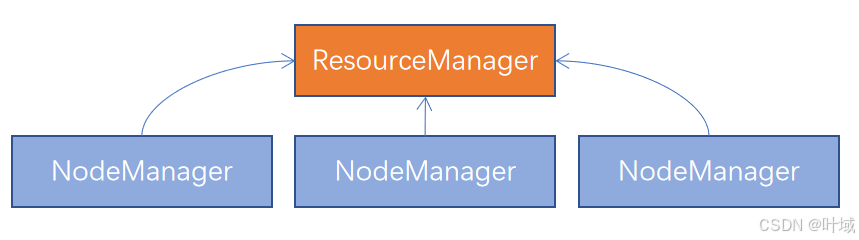
主(Master)角色:ResourceManager:整个集群的资源调度者, 负责协调调度各个程序所需的资源。
从(Slave)角色:NodeManager:单个服务器的资源调度者,负责调度单个服务器上的资源提供给应用程序使用。
3、Yarn容器
如何实现服务器上精准分配如下的硬件资源呢?
- 容器(Container)是YARN的NodeManager在所属服务器上分配资源的手段
- 创建一个资源容器,即由NodeManager占用这部分资源
- 然后应用程序运行在NodeManager创建的这个容器内
- 应用程序无法突破容器的资源限制
4、Yarn辅助架构
YARN的架构中除了核心角色还可以搭配2个辅助角色使得YARN集群运行更加稳定
代理服务器(ProxyServer):Web Application Proxy Web应用程序代理
历史服务器(JobHistoryServer): 应用程序历史信息记录服务
1、代理服务器
-
代理服务器,即Web应用代理是 YARN 的一部分。默认情况下,它将作为资源管理器(RM)的一部分运行,但是可以配置为在独立模式下运行。使用代理的原因是为了减少通过 YARN 进行基于网络的攻击的可能性。
-
这是因为, YARN在运行时会提供一个WEB UI站点(同HDFS的WEB UI站点一样)可供用户在浏览器内查看YARN的运行信息
-
开启代理服务器,可以提高YARN在开放网络中的安全性 (但不是绝对安全只能是辅助提高一些)
-
统一收集到HDFS,由历史服务器托管为WEB UI供用户在浏览器统一查看
代理服务器默认集成在了ResourceManager中,也可以将其分离出来单独启动,
如果要分离代理服务器,在yarn-site.xml中配置 yarn.web-proxy.address参数
并通过命令启动它即可 $HADOOP_YARN_HOME/sbin/yarn-daemon.sh start proxyserver
<!-- yarn-site.xml -->
<property>
<name>yarn.web-proxy.address</name>
<value>node01:8089</value>
<description>代理服务器主机和端口</description>
</property>
2、JobHistoryServer历史服务器
- 提供WEB UI站点,供用户在浏览器上查看程序日志
- 可以保留历史数据,随时查看历史运行程序信息
运行日志,产生在多个容器中,太零散了难以查看,所以需要历史服务器
JobHistoryServer需要配置:
-
开启日志聚合,即从容器中抓取日志到HDFS集中存储
<!-- yarn-site.xml --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> <description>开启日志聚合</description> </property> <property> <name>yarn.nodemanager.remote-app-log-dir</name> <value>/tmp/logs</value> <description>程序日常HDFS的存储路径</description> </property> -
配置历史服务器端口和主机
<!-- mapred-site.xml --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>node01:19888</value> <description>配置历史服务器web端口为node0的19888端口</description> </property> <property> <name>mapreduce.jobhistory.address</name> <value>node01:10020</value> <description>历史服务器通讯端口为node01:10020</description> </property> -
启动和停止:
$HADOOP_HOME/bin/mapred --daemon start|stop historyserver
提交MapReduce程序至YARN运行
-
YARN作为资源调度管控框架,其本身提供资源供许多程序运行,常见的有:MapReduce程序、Spark程序、Flink程序
-
Hadoop官方内置了一些预置的MapReduce程序代码,无需编程,只需要通过命令即可使用,例如:
- wordcount:单词计数程序。
- pi:求圆周率 (通过蒙特卡罗算法(统计模拟法)求圆周率)
-
这些内置的示例MapReduce程序代码,都在
$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar这个文件内。 -
可以通过 hadoop jar 命令来运行它,提交MapReduce程序到YARN中。
hadoop jar 程序文件 java类名 [程序参数] ... [程序参数] # 参数1是数据输入路径 # 参数2是结果输出路径 hadoop $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /input/word.txt /output/wc可以通过 http://node01:8088 查看程序运行状态日志,历史信息
oop官方内置了一些预置的MapReduce程序代码,无需编程,只需要通过命令即可使用,例如:
- wordcount:单词计数程序。
- pi:求圆周率 (通过蒙特卡罗算法(统计模拟法)求圆周率)
-
这些内置的示例MapReduce程序代码,都在
$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar这个文件内。 -
可以通过 hadoop jar 命令来运行它,提交MapReduce程序到YARN中。
hadoop jar 程序文件 java类名 [程序参数] ... [程序参数] # 参数1是数据输入路径 # 参数2是结果输出路径 hadoop $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /input/word.txt /output/wc可以通过 http://node01:8088 查看程序运行状态日志,历史信息
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 大数据开发之Hadoop

发表评论 取消回复