1.head与postman基于索引的操作
引入概念:
集群健康:
green
所有的主分片和副本分片都正常运行。你的集群是100%可用
yellow
所有的主分片都正常运行,但不是所有的副本分片都正常运行。
red
有主分片没能正常运行。
查询es集群健康状态:
192.168.56.102:9200/_cluster/health
删除index:
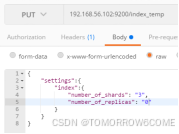
创建index:
单个查询 get /index_temp:
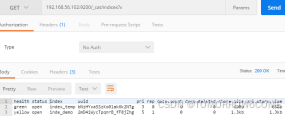
查看所有索引:get /_cat/indices?v


2.mappings自定义创建映射
设置相应的数据结构:(mapping,就是定义数据的类型)
Index:false:表示不被识别,如果存放私密信息的时候设置为FALSE
text与keyword异同:
同:都是String
异:text大的文本,需要分词;keyword:精确匹配的搜索,微信号,手机号,QQ号等无需分词
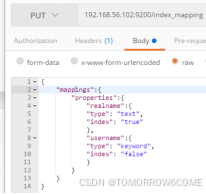
创建索引的同时创建mapping
PUT /index_str
{
"mappings": {
"properties": {
"realname": {
"type": "text",
"index": true
},
"username": {
"type": "keyword",
"index": false
}
}
}
}
为已经存在的索引创建mappings或者创建mappings
POST /index_str/_mapping
{
"properties": {
"id": {
"type": "long"
},
"age": {
"type": "integer"
},
"nickname": {
"type": "keyword"
},
"money1": {
"type": "float"
},
"money2": {
"type": "double"
},
"sex": {
"type": "byte"
},
"score": {
"type": "short"
},
"is_teenager": {
"type": "boolean"
},
"birthday": {
"type": "date"
},
"relationship": {
"type": "object"
}
}
}
注:某个属性一旦被建立,就不能修改了,但是可以新增额外属性
主要数据类型
text, keyword, string
long, integer, short, byte
double, float
boolean
date
object
数组不能混,类型一致
字符串:text:文字类需要被分词倒排序索引的内容,比如:商品名称,商品详情,商品介绍
Keyword:不会被分词,不会被倒排序索引,直接匹配搜索,比如:订单状态,qq号等
3.mappings新增数据类型与analyze
查看分词效果:
GET /index_mapping/_analyze
{
“field”: “realname”,
“text”: “food is good”
}
尝试修改
POST /index_str/_mapping
{
“properties”: {
“name”: {
“type”: “long”
}
}
}
4.文档的基本操作-添加文档与自动映射
添加文档数据:
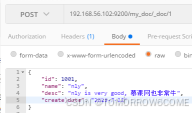
POST /my_doc/_doc/1 -> {索引名}/_doc/{索引ID}(是指索引在es中的id,而不是这条记录的id,比如记录的id从数据库来是1001,并不是这个。如果不写,则自动生成一个字符串。建议和数据id保持一致> )
{
"id": 1001,
"name": "nly-1",
"desc": "xhw is very good, 新华网非常牛!",
"create_date": "2019-12-24"
}
{
"id": 1002,
"name": "nly-2",
"desc": "xhw is fashion, 新华网非常时尚!",
"create_date": "2019-12-25"
}
{
"id": 1003,
"name": "nly-3",
"desc": "xhw is niubility, 新华网很好很强大!",
"create_date": "2019-12-26"
}
{
"id": 1004,
"name": "nly-4",
"desc": "xhw is good~!",
"create_date": "2019-12-27"
}
{
"id": 1005,
"name": "nly-5",
"desc": "新华网 is 强大!",
"create_date": "2019-12-28"
}
{
"id": 1006,
"name": "nly-6",
"desc": "新华网是一个强大网站!",
"create_date": "2019-12-29"
}
{
"id": 1007,
"name": "nly-7",
"desc": "新华网是很牛网站!",
"create_date": "2019-12-30"
}
{
"id": 1008,
"name": "nly-8",
"desc": "新华网是很好看!",
"create_date": "2019-12-31"
}
{
"id": 1009,
"name": "nly-9",
"desc": "在新华网学习很久!",
"create_date": "2020-01-01"
}
使用_doc创建时无法创建mapping。
如何增加数据:
_doc:表示如何创建文档;1表示文档名称
创建数据:对应数据库中创建一条完成的数据
区别_id与id,id一般是数据来源,可能是数据库中的id,_id就是文档的id,索引库的主键

如果索引没有手动建立mappings,那么当插入文档数据的时候,会根据文档类型自动设置属性类型。这个就是es的动态映射,帮我们在index索引库中去建立数据结构的相关配置信息。
“fields”: {“type”: “keyword”}
对一个字段设置多种索引模式,使用text类型做全文检索,也可使用keyword类型做聚合和排序
“ignore_above” : 256
设置字段索引和存储的长度最大值,超过则被忽略
5.文档的基本操作-删除与修改
文档的删除不是立即删除,文档还是保存在磁盘上,索引增长越来越多,才会把那些曾经标识过删除的,进行清理,从磁盘上移出去。
删除:删除文档中的一条数据
DELETE /my_doc/_doc/1
修改:修改某一条数据中的一部分(不添加update也可以实现)
POST /my_doc/_doc/1/_update
{
“doc”: {
“name”: “慕课”
}
}
全量替换:替换一条完整的文档(数据)
PUT /my_doc/_doc/1
{
“id”: 1001,
“name”: “imooc-1”,
“desc”: “imooc is very good, 慕课网非常牛!”,
“create_date”: “2019-12-24”
}
注意:每次修改后,version会更改
6.文档的基本操作-查询
常规查询:
查询某条特定的数据:(1表示对应的_id是1)
GET /index_demo/_doc/1
查询索引中的全部数据
GET /index_demo/_doc/_search
元数据
_index:文档数据所属那个索引,理解为数据库的某张表即可。
_type:文档数据属于哪个类型,新版本使用_doc。
_id:文档数据的唯一标识,类似数据库中某张表的主键。可以自动生成或者手动指定。
_score:查询相关度,是否契合用户匹配,分数越高用户的搜索体验越高。
_version:版本号。
_source:文档数据,json格式。
定制结果集:查询想要的参数
GET /index_demo/_doc/1?_source=id,name
GET /index_demo/_doc/_search ?_source=id,name
判断文档是否存在:
HEAD /index_demo/_doc/1
使用此种方式的好处是:规范;方便,快捷(只需要code码就可)
7.文档乐观锁控制if_seq_no与if_primary_term
乐观锁(version字段实现,删除或者被修改后它的version是累加的):
当一个共用数据,同时被几个用户或者线程并发的进行操作,
它会和它的版本号进行对比。版本号匹配更新,否则不更新
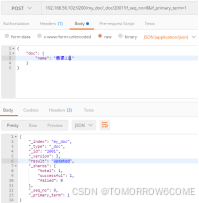
老版更新方式:
post:192.168.56.102:9200/my_doc/_doc/2001?version=2
{
“doc”: {
“name”: “慕课111”
}
}
查询对应的数值:
使用if_seq_no与if_primary_term进行更新的时候,同时会将下次的
if_seq_no(累加)与if_primary_term(不变)数值返回出来
当下版本的乐观锁控制需要使用if_seq_no与if_primary_term,使用在请求体中
字段中的“_seq_no”与“_primary_term”代表的是新的版本号
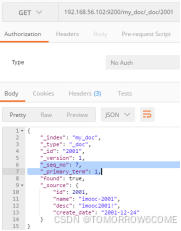
版本元数据
_seq_no:文档版本号,作用同_version(相当于学生编号,每个班级的班主任为学生分配编号,效率要比学校教务处分配来的更加高效,管理起来更方便)
_primary_term:文档所在位置(相当于班级)
8.分词与内置分词器
分词中文不识别。
全局分析:展现的是对于text文本内容的分词
POST /_analyze
{
“analyzer”: “standard”,
“text”: “text文本”
}
使用现有索引库:
POST /my_doc/_analyze
{
“analyzer”: “standard”,
“field”: “name”,
“text”: “text文本”
}
上面两种结果在简单的测试中,看起来没有多大区别;
es内置分词器
standard:默认分词,单词会被拆分,大小会转换为小写。
simple:按照非字母分词。大写转为小写。
whitespace:按照空格分词。忽略大小写。
stop:去除无意义单词,比如the/a/an/is…
keyword:不做分词。把整个文本作为一个单独的关键词。
非字母分词表示:不是字母会将其去除。
{
“analyzer”: “standard”,
“text”: “My name is Peter Parker,I am a Super Hero. I don’t like the Criminals.”
}
9建立IK中文分词器
安装IK分词器:(问题:遇到了-bash: unzip: 未找到命令的问题,重新定义安装就可)
Yum -y install unzip zip:安装unzip
unzip elasticsearch-analysis-ik-7.4.2.zip -d /usr/local/elasticsearch-7.4.2/plugins/ik
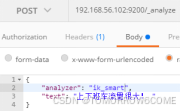
POST /_analyze
{
“analyzer”: “ik_max_word”,
“text”: “上下班车流量很大”
}

10.自定义中文词库
建立自定义词汇
在es/plugins/ik/config
vim custom.dic
添加内容:
新华网
骚年
配置自定义词典:
custom.dic
重启测试:
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 分布式搜索引擎ES-Elasticsearch进阶

发表评论 取消回复