上课内容
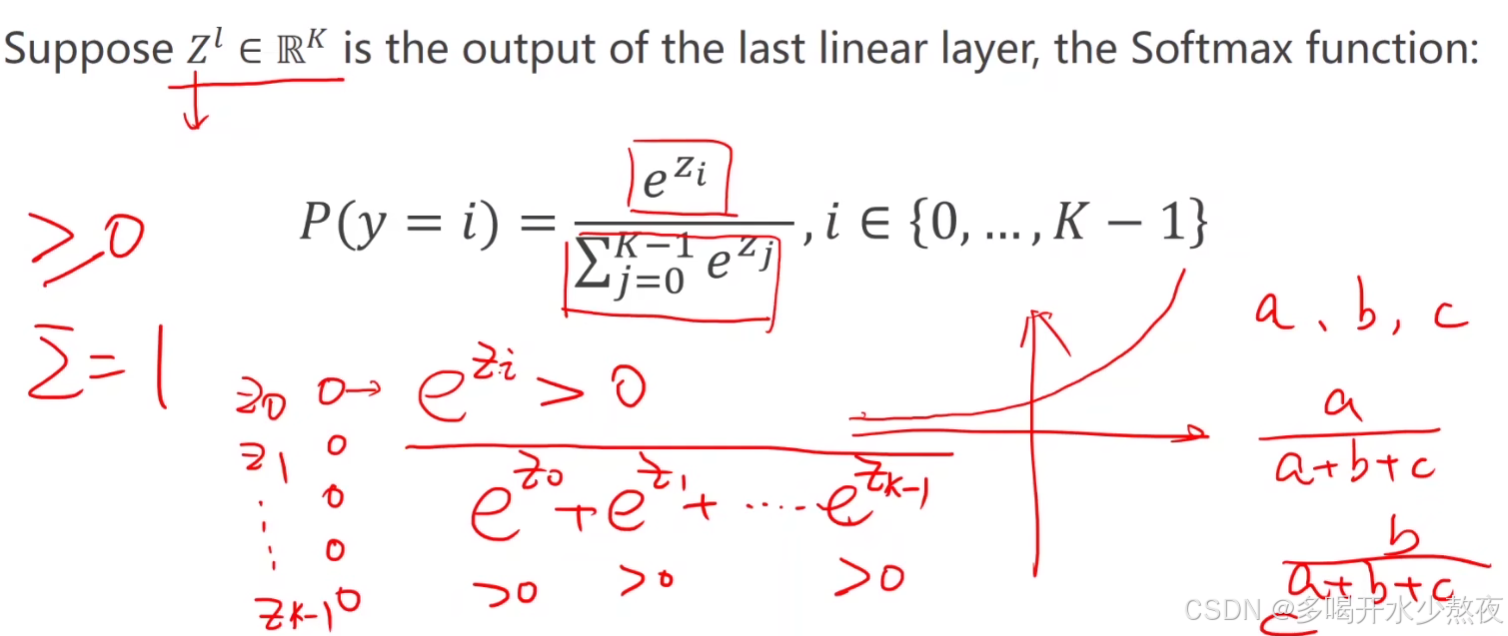
softmax能输出一个分布:每一个输出值>=0,且和=1
说明: 1、softmax的输入不需要再做非线性变换,也就是说softmax之前不再需要激活函数(relu)。softmax两个作用,如果在进行softmax前的input有负数,通过指数变换,得到正数。所有类的概率求和为1。
2、y的标签编码方式是one-hot。我对one-hot的理解是只有一位是1,其他位为0。(但是标签的one-hot编码是算法完成的,算法的输入仍为原始标签)
3、多分类问题,标签y的类型是LongTensor。比如说0-9分类问题,如果y = torch.LongTensor([3]),对应的one-hot是[0,0,0,1,0,0,0,0,0,0].(这里要注意,如果使用了one-hot,标签y的类型是LongTensor,糖尿病数据集中的target的类型是FloatTensor)
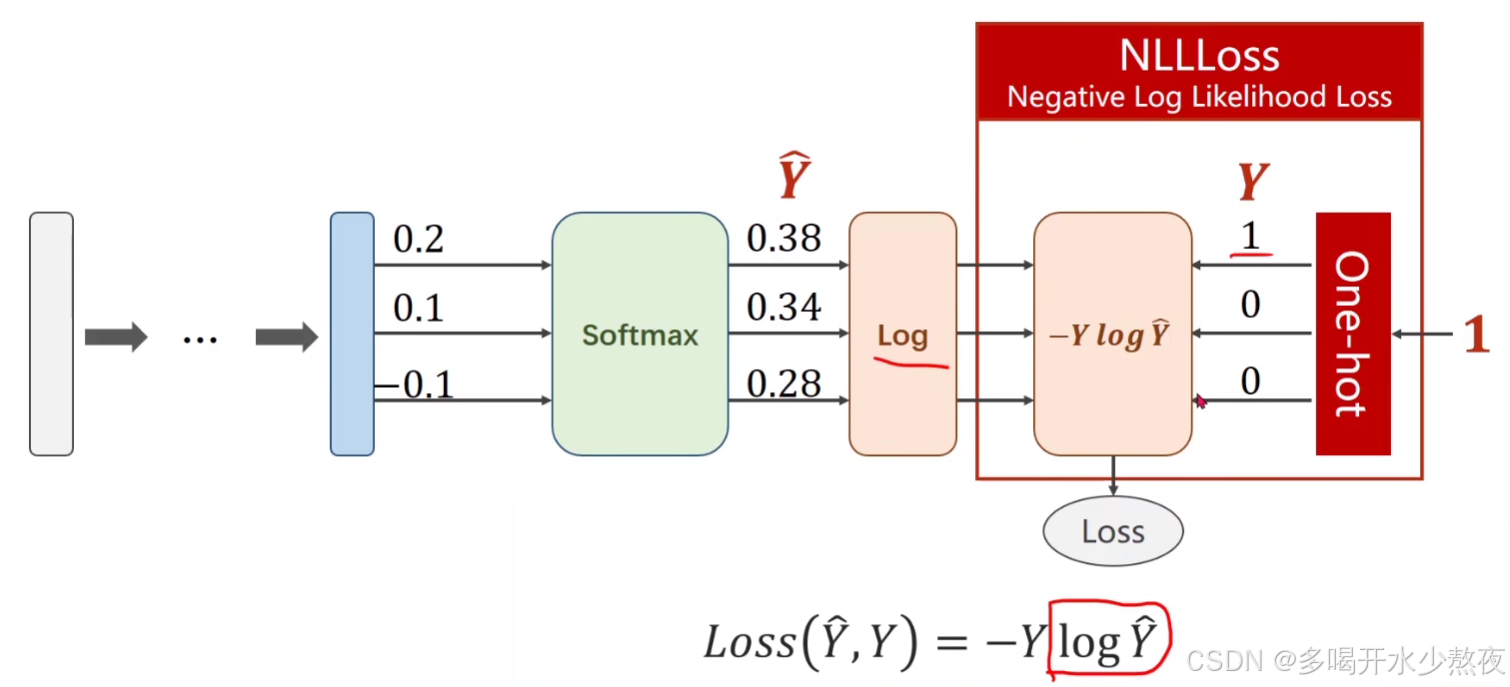
4、CrossEntropyLoss <==> LogSoftmax + NLLLoss。也就是说使用CrossEntropyLoss最后一层(线性层)是不需要做其他变化的;使用NLLLoss之前,需要对最后一层(线性层)先进行SoftMax处理,再进行log操作。
Y是经过独热编码后的值,只有一个概率最大的为1,计算损失只要计算Y为1的Y_hat的损失
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
import torch
y = torch.LongTensor([0])
z = torch.Tensor([0.2, 0.1, -0.1])
criterion = torch.nn.CrossEntropyLoss()
loss = criterion(z, y)
print(loss)
代码流程:
1.prepare dataset 2.design model using class 3.construct loss and optimizer 4.training cycle + test
import torch
from torchvision import transforms #用来处理图像
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F #用relu()函数
import torch.optim as optim
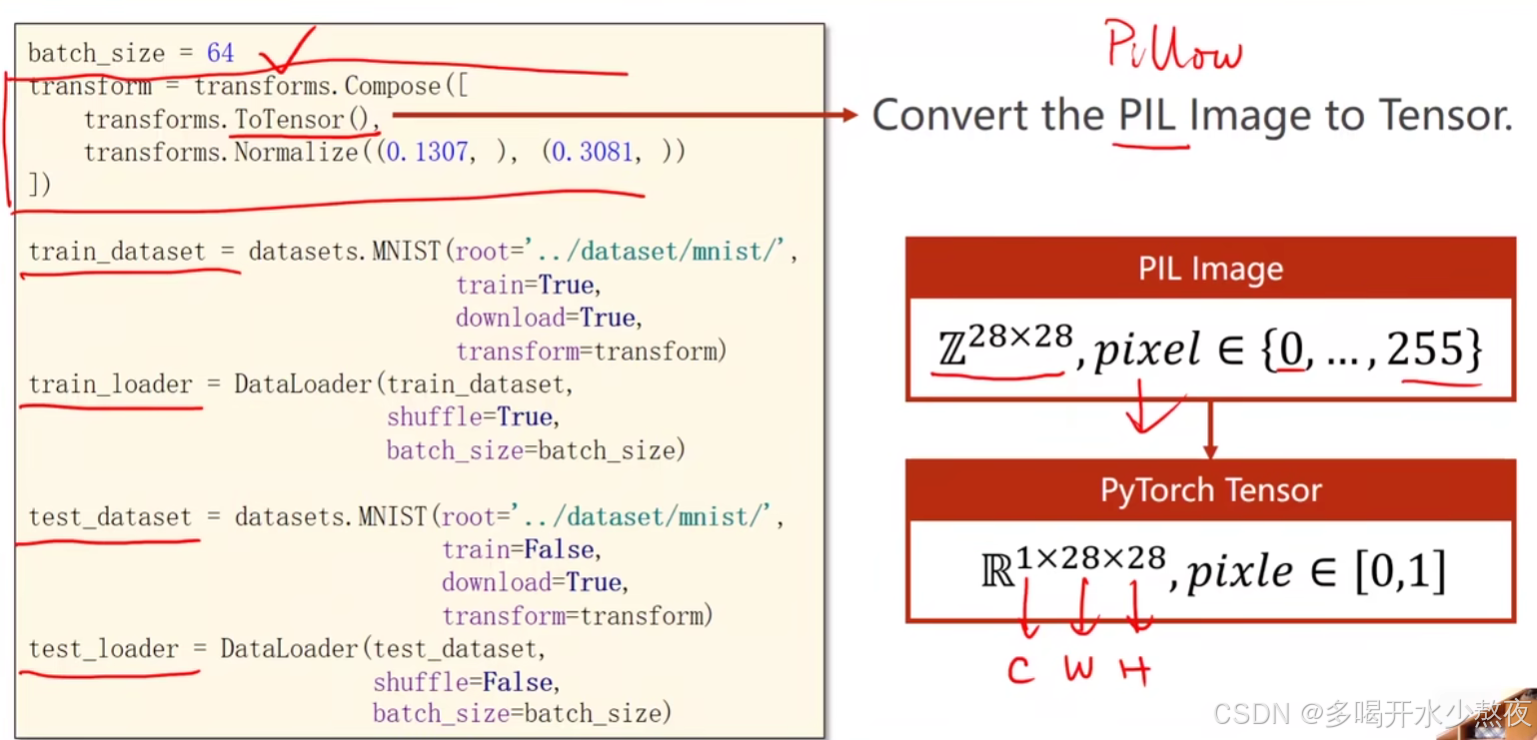
transform = transforms.Compose([transforms.ToTensor(), #把输入的图像转变为pytorch张量:c*w*h,将px映射到[0,1]
transforms.Normalize((0.1307,), (0.3081,))]) # 归一化,均值和方差,基于经验
标准化之后让数据变成标准分布,从而可以解决一些问题比如,多层传递之后梯度爆炸的问题

关于x,view(-1, 784)的说明
在PyTorch中,x.view(-1, 784)是一个非常常见的操作,用于重塑(reshape)张量(tensor)x的形状。这里的view方法不会改变张量的数据,而是返回一个新的张量,这个新张量的数据与原始张量共享内存空间,但具有不同的形状。
具体来说,x.view(-1, 784)的作用是将张量x重塑为一个新的二维张量,其中这个新张量的第二维(列数)是784,而第一维(行数)是自动计算的,以确保重塑后的张量总元素数与原始张量x相同。这里的-1是一个特殊的值,它告诉PyTorch自动计算该维度的大小,以保持元素总数不变。
这种操作在处理图像数据时特别有用,特别是在处理MNIST数据集时。MNIST数据集中的每个图像是一个28x28的灰度图像,总共784个像素点。如果你有一个包含多个图像的一维张量(比如,每个图像都被展平成了一个784维的向量,并存储在一个一维张量中),你可能想要将这些图像重塑回它们原始的28x28二维形状以便于处理。但是,如果你只是想将这些图像作为特征向量输入到神经网络中,你可能会选择保持它们为784维的向量,并通过x.view(-1, 784)将它们组织成一个二维张量,其中每一行都是一个图像的特征向量。
举个例子,假设你有一个包含60000个MNIST图像的一维张量x,每个图像都被展平成了一个784维的向量。那么x的形状将是[60000, 784](如果它已经是二维的,那么你就不需要重塑它)。但是,如果x是一个一维张量,形状为[46800000](因为60000 * 784 = 46800000),那么你可以通过x.view(-1, 784)将其重塑为形状[60000, 784]的二维张量,这样每一行就代表了一个图像的特征向量。
同理,如果想要784行列自动计算则用:x,view(784, -1)
知识点:SoftMax激活函数,多分类交叉熵CrossEntropyLoss,图像transform预处理,训练测试单独封装,torchvision库
问题描述:dataset中MINIST数据集读取方式为PIL不能直接输入网络,同时多分类问题输出需要为一个分布
主要思路:利用transform进行预处理,将图片拉直后进入线性网络,利用多分类交叉熵CrossEntropyLoss计算损失值(线性层传入即可,CrossEntropyLoss = SoftMax + NLLLoss)
代码实现
数据处理:transforms构建Compose时用ToTensor转为张量,用Normalize进行标准化(涉及到的函数都来自于torchvision.transforms)
利用dataset中MINIST数据集指定下载、路径、是否为训练集、transform
利用Dataloader整理成分批数据集
由于用线性网络实现,前向传播时先利用view将图像拉直过线性层(注意最后一层不用过激活函数),采用CrossEntropyLoss损失函数
训练:内层循环单独拿出来(传入epoch)记录batch数,进行输出(loss存的是item(),同时输出后记得置零)
测试:
不用计算梯度,利用with torch.no_grad():
利用正确数除以总数记录精确度
总数:累加每个batch的size(0)
正确数:利用``torch.max找到最大概率值,获取其索引于真实值进行比较,利用sum()`汇总数据
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
# prepare dataset
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) # 归一化,均值和方差
train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
# design model using class
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 784) # -1其实就是自动获取mini_batch
# print("x_view ", x.shape)#x_view torch.Size([64, 784])
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x) # 最后一层不做激活,不进行非线性变换 softmax+NLLloss等于Cross Entropy softmax在后面使用的损失函数里面包含了,后面会定义自带的crossEntropy交叉熵函数,里面会计算
model = Net()
# construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)#冲量(动量)会累加梯度,从而回收上一次计算影响,形象称呼会惯性
# training cycle forward, backward, update
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
# 获得一个批次的数据和标签
inputs, target = data
optimizer.zero_grad()
# 获得模型预测结果(64, 10)
outputs = model(inputs)
# 交叉熵代价函数outputs(64,10),target(64)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss/300))
running_loss = 0.0
#test里面不需要进行反向传播
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1) # dim = 1 列从上到下是第0个维度,行从左到右是第1个维度,取值最大的下标正好就是输出的0-9的最大可能
total += labels.size(0)
correct += (predicted == labels).sum().item() # 张量之间的比较运算
print('accuracy on test set: %d %% ' % (100*correct/total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()

处理图像时更关注一些比较高抽象级别的特征,上面用的是非常原始的特征,所以如果用某些特征提取做分类训练可能效果会更好一点,考虑图像自动提取特征:CNN
作业实现
import pandas as pd
import torch
from torch.utils.data import DataLoader, Dataset
import torch.nn.functional as F
import torch.optim as optim
# 自定义数据集
class OttoDataset(Dataset):
def __init__(self, data, targets=None, transform=None):
self.data = data
self.targets = targets
self.transform = transform
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
x = self.data[idx]
if self.targets is not None:
y = self.targets[idx]
return torch.tensor(x, dtype=torch.float32), torch.tensor(y, dtype=torch.long)
else:
return torch.tensor(x, dtype=torch.float32)
# 加载数据
train_df = pd.read_csv('./dataset/otto_train.csv')
test_df = pd.read_csv('./dataset/otto_test.csv')
# 提取特征和标签
X_train = train_df.drop(['id', 'target'], axis=1).values
y_train = train_df['target'].map(lambda x: int(x.split('_')[1]) - 1).values # target 转换为 0-8
X_test = test_df.drop(['id'], axis=1).values
test_ids = test_df['id'].values
# 转换为数据集
train_dataset = OttoDataset(X_train, y_train)
test_dataset = OttoDataset(X_test)
batch_size = 64
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
# 设计模型
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(93, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 9) # 输出9类
def forward(self, x):
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x)
model = Net()
# 构造损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# 训练循环
def train(epoch):
running_loss = 0.0
for batch_idx, (inputs, target) in enumerate(train_loader, 0):
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
# 生成测试集结果并保存为CSV
def generate_test_results():
model.eval()
results = []
with torch.no_grad():
for data in test_loader:
inputs = data
outputs = model(inputs)
probabilities = F.softmax(outputs, dim=1)
results.extend(probabilities.cpu().numpy())
# 将结果转换为 DataFrame
results_df = pd.DataFrame(results, columns=[f'Class_{i+1}' for i in range(9)])
results_df.insert(0, 'id', test_ids)
# 保存为 CSV 文件
results_df.to_csv('otto_predictions.csv', index=False, float_format='%.1f')
# 主函数
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
generate_test_results()
gpt改进版本:
import pandas as pd
import torch
from torch.utils.data import DataLoader, Dataset
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
# 自定义数据集
class OttoDataset(Dataset):
def __init__(self, data, ids, targets=None):
self.data = data
self.ids = ids
self.targets = targets
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
x = self.data[idx]
id = self.ids[idx]
if self.targets is not None:
y = self.targets[idx]
return torch.tensor(x, dtype=torch.float32), torch.tensor(y, dtype=torch.long), id
else:
return torch.tensor(x, dtype=torch.float32), id
# 加载数据
train_df = pd.read_csv('./dataset/otto_train.csv')
test_df = pd.read_csv('./dataset/otto_test.csv')
# 提取特征和标签
X_train = train_df.drop(['id', 'target'], axis=1).values
y_train = train_df['target'].map(lambda x: int(x.split('_')[1]) - 1).values # target 转换为 0-8
X_test = test_df.drop(['id'], axis=1).values
test_ids = test_df['id'].values
# 数据标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 转换为数据集
train_dataset = OttoDataset(X_train, ids=np.arange(len(X_train)), targets=y_train)
test_dataset = OttoDataset(X_test, ids=test_ids)
batch_size = 64
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
# 设计模型
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(93, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 9) # 输出9类
self.dropout = torch.nn.Dropout(0.5) # Dropout
def forward(self, x):
x = F.relu(self.l1(x))
x = self.dropout(F.relu(self.l2(x)))
x = self.dropout(F.relu(self.l3(x)))
x = F.relu(self.l4(x))
return self.l5(x)
model = Net()
# 构造损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 学习率调度器
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)
# 训练循环
def train(epoch):
model.train()
running_loss = 0.0
for batch_idx, (inputs, target, _) in enumerate(train_loader, 0):
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
# 测试函数并生成csv
def test():
model.eval()
results = []
with torch.no_grad():
for data, ids in test_loader:
outputs = model(data)
probabilities = F.softmax(outputs, dim=1).numpy()
for id, probs in zip(ids, probabilities):
results.append([id.item()] + probs.tolist())
# 生成csv文件
columns = ['id'] + [f'Class_{i+1}' for i in range(9)]
df = pd.DataFrame(results, columns=columns)
df.to_csv('otto_predictions2.csv', index=False, float_format='%.1f')
# 主函数
if __name__ == '__main__':
for epoch in range(30):
train(epoch)
scheduler.step()
test()
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » PyTorch 深度学习实践-基于SoftMax的多分类

发表评论 取消回复