Python新闻语料分析系统开题报告
一、项目背景与意义
随着互联网的迅猛发展,新闻数据呈现出爆炸式增长的趋势。新闻语料中蕴含着丰富的信息,包括社会热点、公众情绪、事件趋势等,这些信息对于政府决策、企业市场调研、学术研究以及个人兴趣追踪等方面都具有重要价值。然而,如何从海量的新闻数据中高效、准确地提取有用信息,成为了一个亟待解决的问题。因此,开发一套基于Python的新闻语料分析系统,对于提升信息处理效率、挖掘新闻价值具有重要意义。
二、项目目标
本项目旨在设计并实现一个基于Python的新闻语料分析系统,该系统应能够完成以下主要功能:
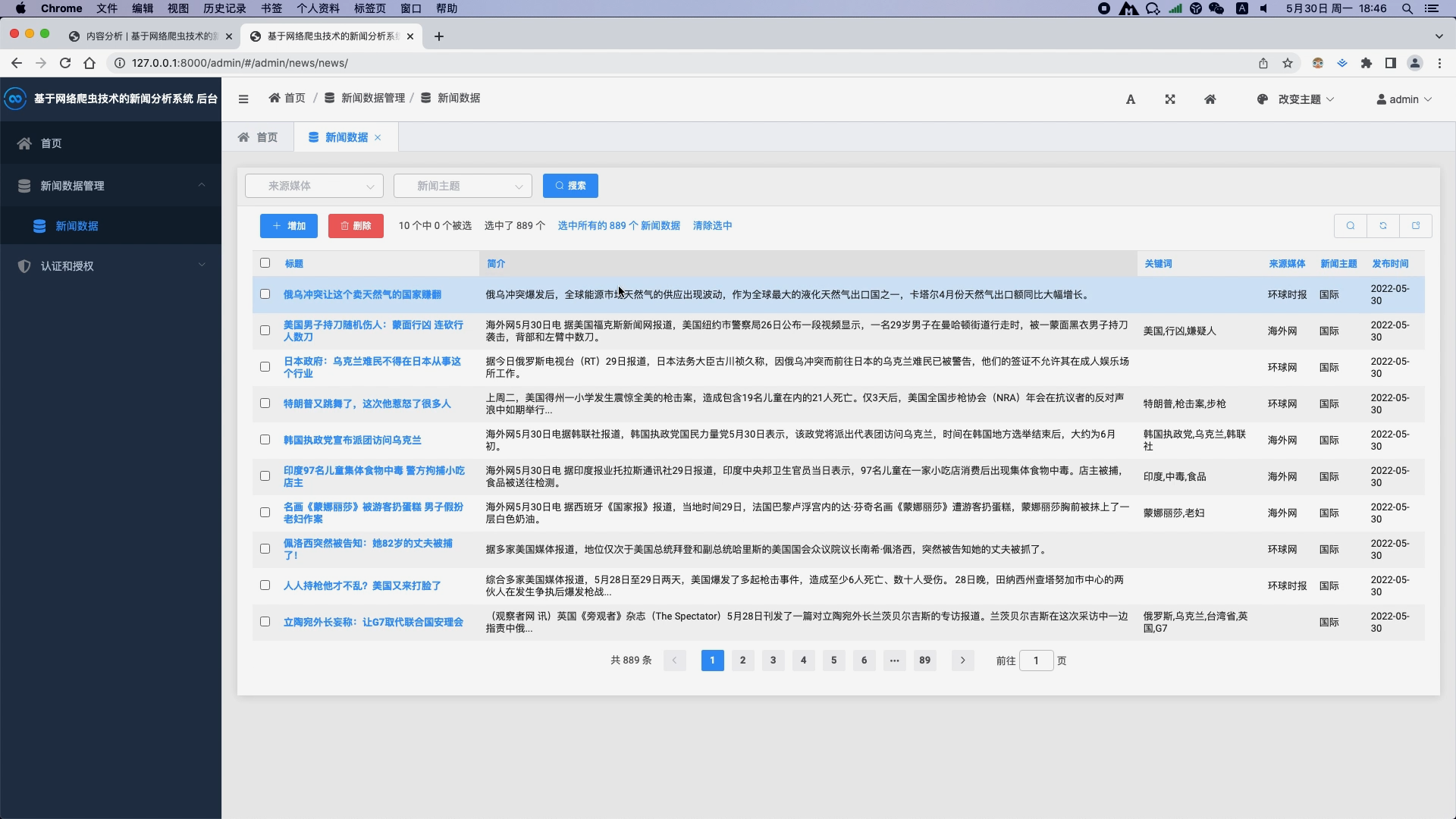
- 新闻数据采集:从多个新闻源(如门户网站、社交媒体、RSS订阅等)自动抓取新闻数据,包括标题、正文、发布时间等。
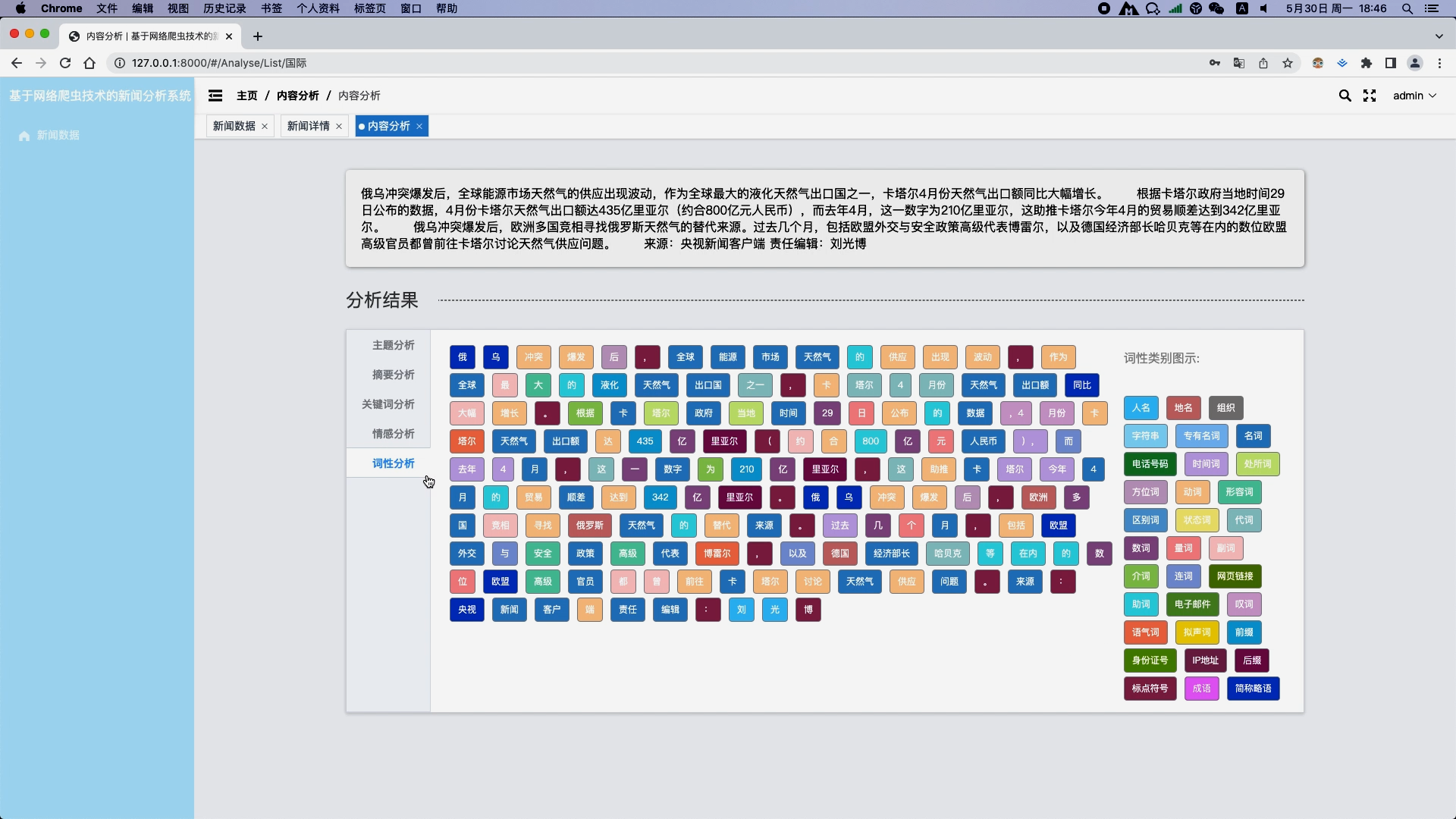
- 新闻预处理:对采集到的新闻数据进行清洗(去除HTML标签、特殊字符等)、分词、去停用词等预处理操作,为后续分析做准备。
- 新闻分类:利用机器学习或深度学习算法对新闻进行分类,如政治、经济、科技、娱乐等类别。
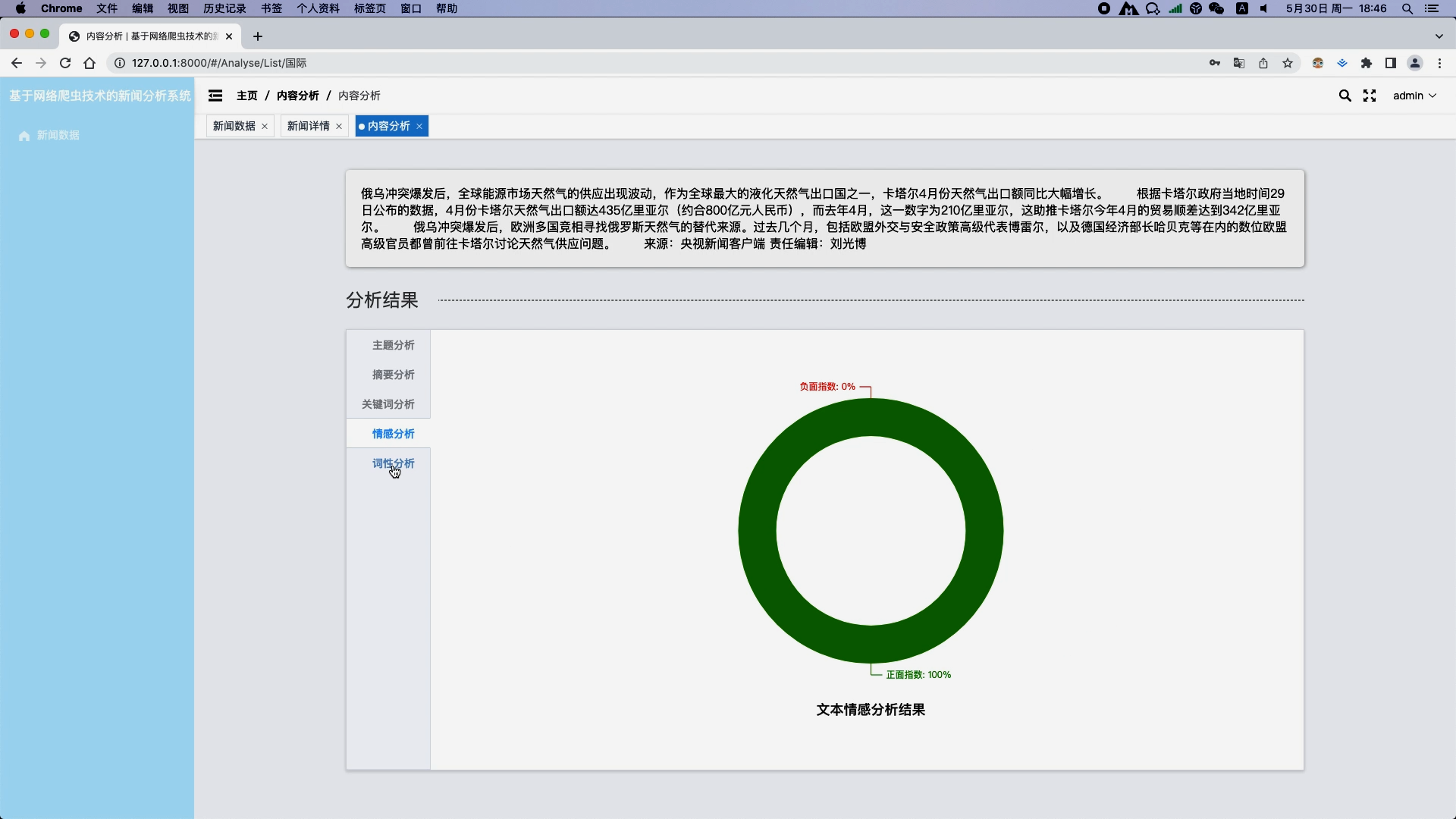
- 情感分析:对新闻文本进行情感倾向判断,识别出正面、负面或中性的情感。
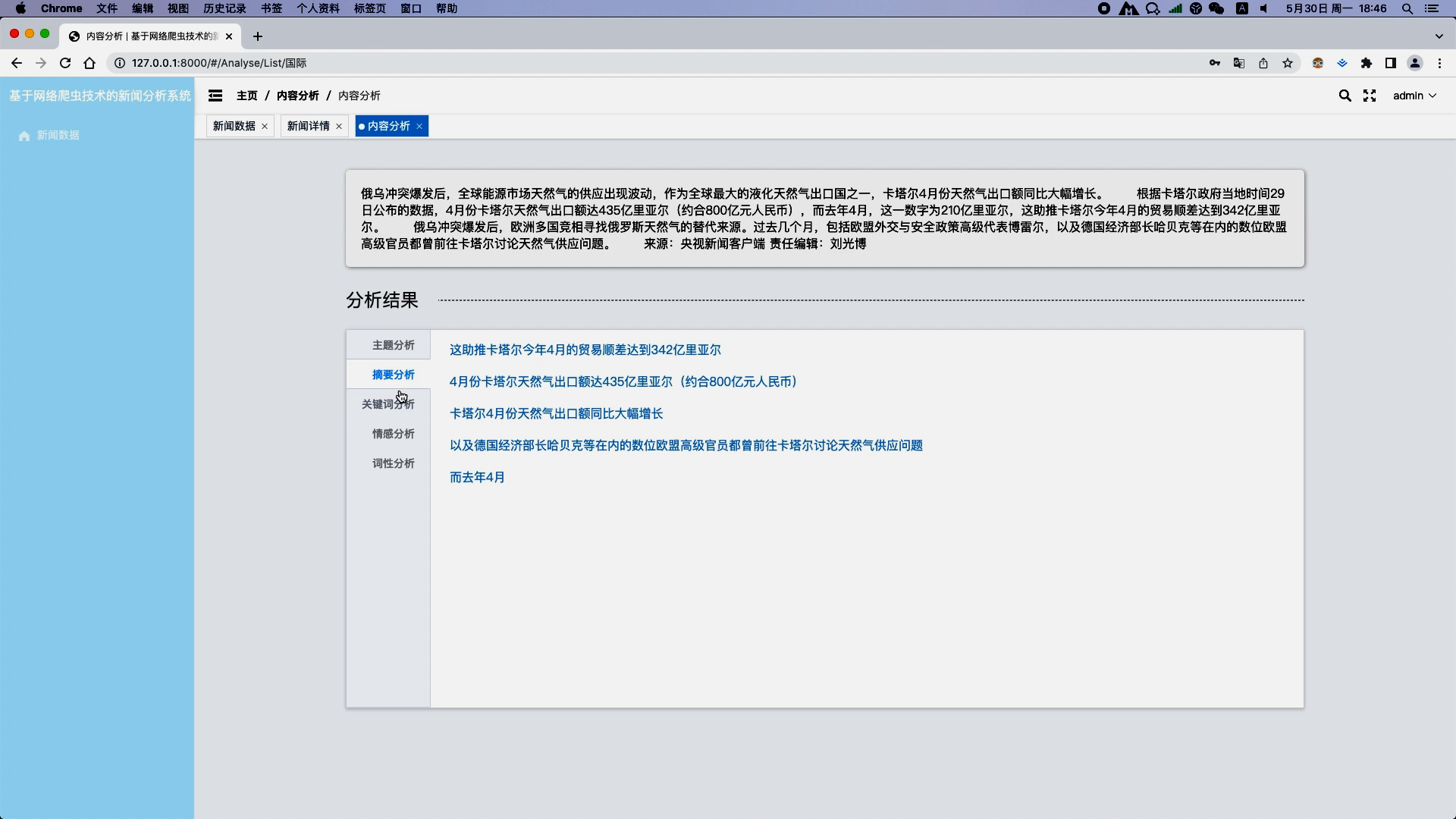
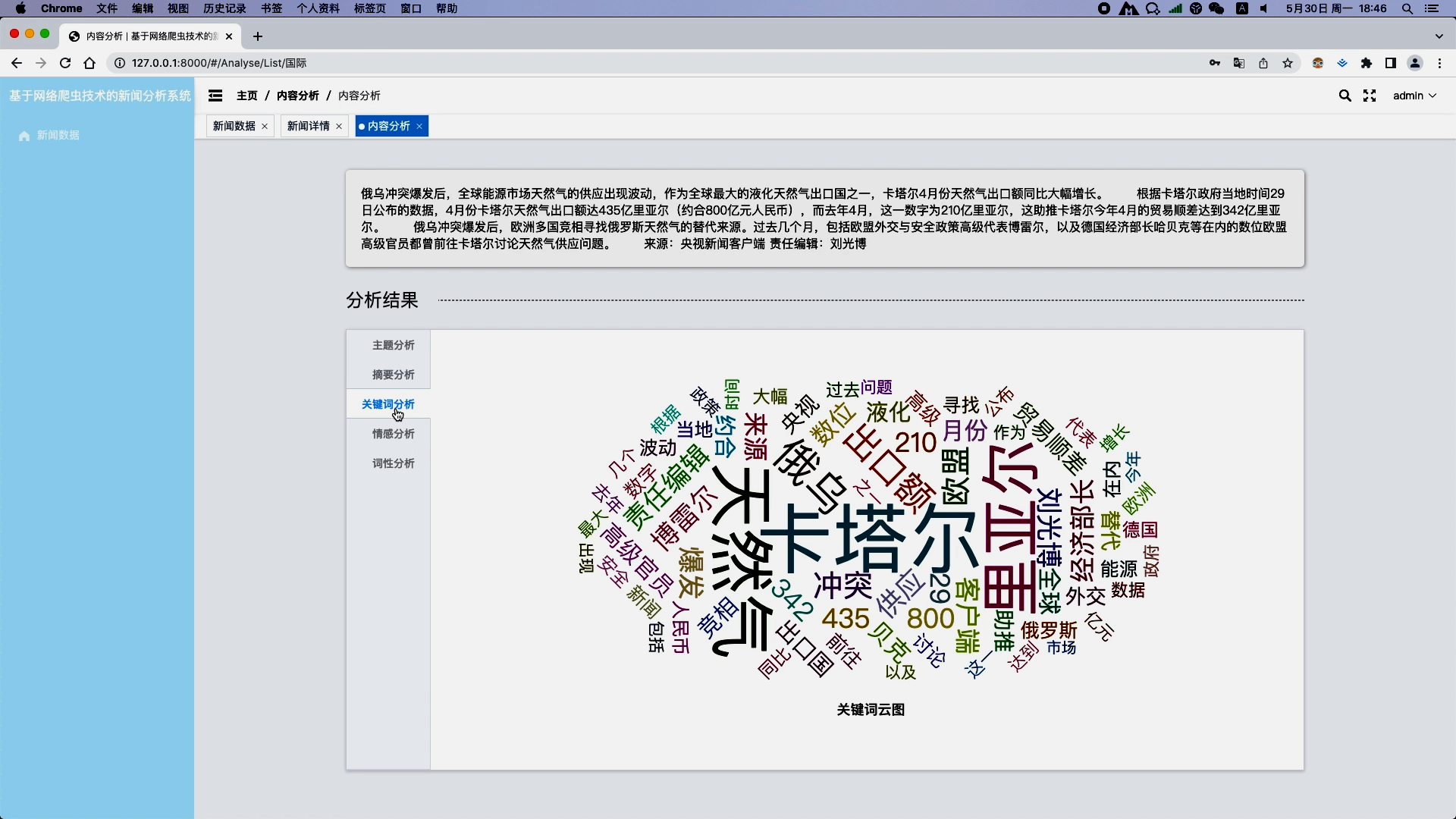
- 热点追踪:基于新闻关键词统计和趋势分析,追踪社会热点话题及其发展变化。
- 可视化展示:将分析结果以图表、热力图等形式直观展示,便于用户理解和使用。
三、技术路线与方案
1. 数据采集
- 工具选择:使用Python的
requests库发送HTTP请求,BeautifulSoup或lxml库解析HTML页面,feedparser库处理RSS订阅。 - 策略设计:制定定时任务,定期从指定新闻源抓取数据,并存储到数据库中。
2. 数据预处理
- 分词:采用
jieba分词工具进行中文分词。 - 去停用词:基于自定义或现有的停用词表去除无意义的词汇。
- 清洗:去除HTML标签、特殊字符等。
3. 新闻分类与情感分析
- 算法选择:使用机器学习算法(如朴素贝叶斯、SVM、随机森林)或深度学习模型(如TextCNN、BERT)进行新闻分类和情感分析。
- 模型训练:利用标注好的新闻数据集进行模型训练,并调整参数以优化性能。
- 评估与调优:通过交叉验证、混淆矩阵、准确率、召回率等指标评估模型性能,并进行必要的调优。
4. 热点追踪
- 关键词提取:利用TF-IDF、TextRank等方法提取新闻关键词。
- 趋势分析:统计关键词在一段时间内的出现频率,绘制趋势图,识别热点话题。
5. 可视化展示
- 工具选择:使用
matplotlib、seaborn、plotly等Python库进行图表绘制。 - 展示内容:包括新闻分类结果、情感分布、热点话题趋势图等。
四、预期成果与贡献
- 系统实现:完成新闻语料分析系统的开发,实现新闻数据采集、预处理、分类、情感分析、热点追踪及可视化展示等功能。
- 性能优化:通过算法调优和系统优化,提高新闻处理的准确性和效率。
- 应用推广:将系统应用于实际场景,为政府、企业、研究机构等提供有价值的新闻分析服务。
- 学术贡献:通过项目实践,探索新闻语料分析的新方法和技术,为相关领域的研究提供参考。
五、项目计划与进度安排
- 需求分析与系统设计(第1-2周):明确项目需求,设计系统架构和功能模块。
- 数据采集与预处理模块开发(第3-5周):实现新闻数据采集和预处理功能。
- 新闻分类与情感分析模块开发(第6-9周):选择合适的算法,进行模型训练和调优,实现新闻分类和情感分析功能。
- 热点追踪与可视化展示模块开发(第10-12周):开发热点追踪算法,实现可视化展示功能。
- 系统集成与测试(第13-14周):将各模块集成,进行系统测试,确保系统稳定运行。
- 项目总结与报告撰写(第15周):整理项目文档,撰写开题报告、结题报告等。
六、结论
本项目旨在通过开发一个基于Python的新闻语料分析系统,实现对新闻数据的全面分析和深度挖掘。该系统不仅有助于提升新闻信息处理的效率和质量,还能为政府决策、企业市场调研等领域提供有力支持。通过本项目的实施,我们期待
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 计算机毕业设计Python新闻语料分析 新闻情感分析 新闻关键词提取 新闻摘要抽取 机器学习 深度学习 爬虫 可视化 大数据毕业设计 Hadoop Spark

发表评论 取消回复