目录
决策树C4.5算法概述
决策树C4.5算法简介
C4.5算法是由Ross Quinlan开发的用于产生决策树的算法。该算法是对Ross Quinlan之前开发的ID3算法的一个扩展。C4.5算法产生的决策树可以被用作分类目的,因此该算法也可以用于统计分类。 C4.5算法与ID3算法一样使用了信息熵的概念,并和ID3一样通过学习数据来建立决策树
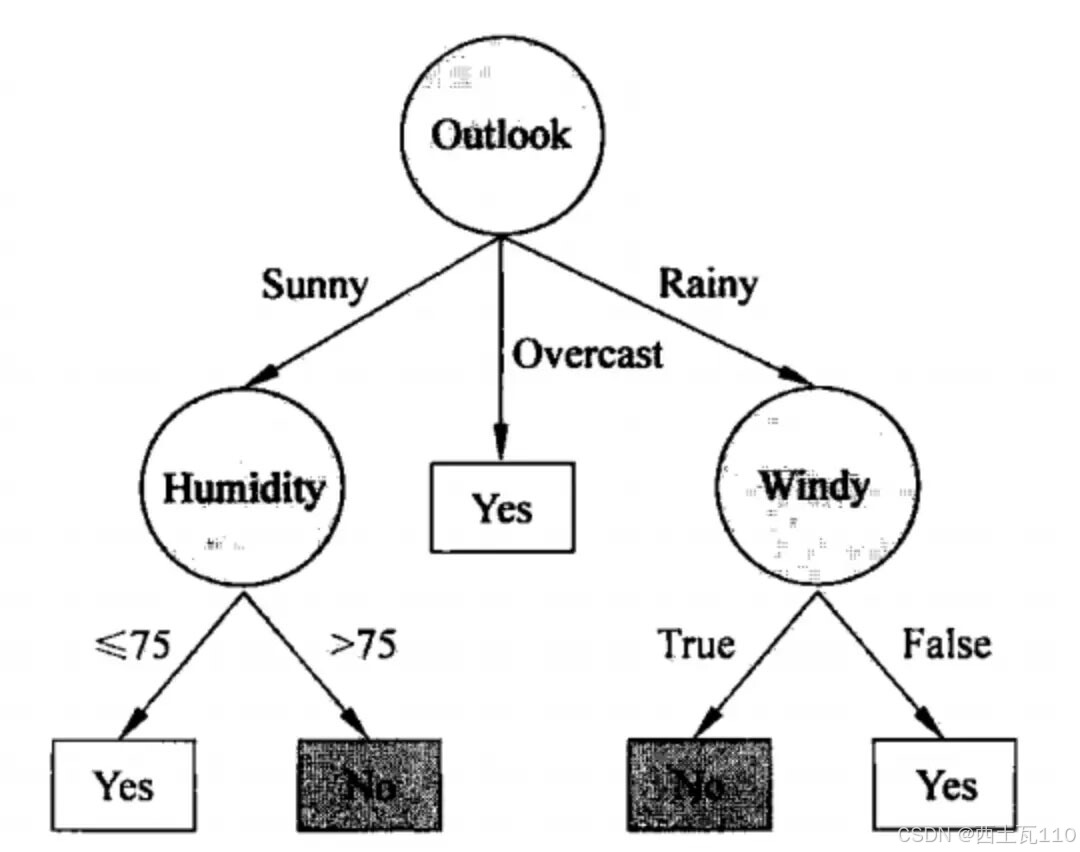
C4.5算法是数据挖掘十大算法之一,它是对ID3算法的改进,相对于ID3算法主要有以下几个改进
- 用信息增益比来选择属性
- 在决策树的构造过程中对树进行剪枝
- 对非离散数据也能处理
- 能够对不完整数据进行处理
决策树C4.5算法发展历史
最早的决策树算法是由Hunt等人于1966年提出的CLS。当前最有影响的决策树算法是由Quinlan于1986年提出的ID3和1993年提出的C4.5.其他早期算法还包括CART,FACT,CHAID算法。后期的算法主要有SLIQ, SPRINT, PUBLIC等。
传统的决策树分类算法主要是针对小数据集的,大都要求训练集常驻内存,这使得在处理数据挖掘任务时,传统决策树算法在可伸展性,精度和效率方面受到了很大的限制。而在实际的数据挖掘应用中我们面临的数据集往往是容量巨大的数据库或者数据仓库,在构造决策树时需要将庞大的数据在主存和缓存中不停地导入导出,使得运算效率大大降低。针对以上问题,许多学者提出了处理大型数据集的决策树算法。
| A | B | C | |
| 1 | 年份 | 事件 | 相关论文 |
| 2 | 1993 | Ross Quinlan对ID3算法扩展,发明了C4.5算法 | C4.5: Programs for Machine Learning. Morgan Kaufmann Publishers.ISBN1-55860-238-0 |
| 3 | 2002 | 讲解了离散类数据挖掘的标杆属性选择技术,其中讲解了C4.5在大数据挖掘的应用。 | Hall M A, Holmes G. Benchmarking Attribute Selection Techniques for Discrete Class Data Mining[J]. IEEE Transactions on Knowledge & Data Engineering, 2002, 15(6):1437-1447. |
决策树C4.5算法原理
在深入了解C4.5算法之前,有必要明确几个核心概念和度量指标。本节将重点介绍信息熵、信息增益、以及信息增益比,这些都是C4.5算法决策树构建中的关键因素。
信息熵(Information Entropy)
信息熵是用来度量一组数据的不确定性或混乱程度的。它是基于概率论的一个概念,通常用以下数学公式来定义:
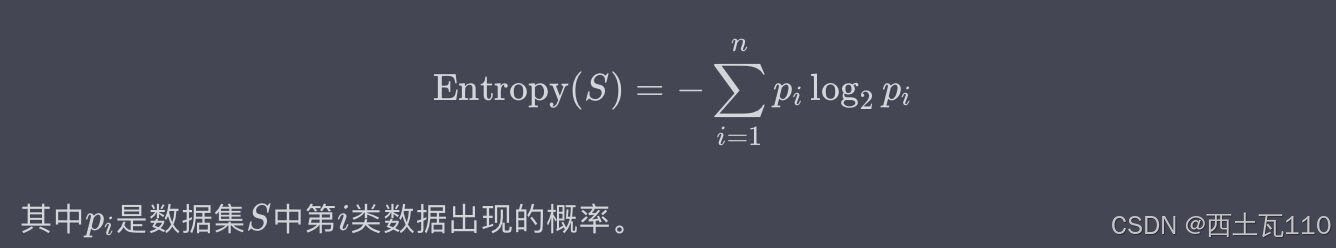
信息增益(Information Gain)
信息增益表示通过某个特征进行分裂后,数据集不确定性(即信息熵)下降的程度。信息增益通常用以下数学公式来定义:

信息增益比(Gain Ratio)
信息增益比是信息增益与该特征导致的数据集分裂复杂度(Split Information)的比值。用数学公式表示为:

决策树C4.5算法改进
在ID3中:
信息增益
按属性A划分数据集S的信息增益Gain(S,A)为样本集S的熵减去按属性A划分S后的样本子集的熵,即
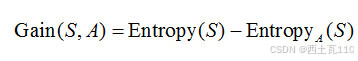
在此基础上,C4.5计算如下:
分裂信息
利用引入属性的分裂信息来调节信息增益
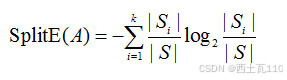
信息增益率
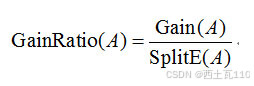
信息增益率将分裂信息作为分母,属性取值数目越大,分裂信息值越大,从而部分抵消了属性取值数目所带来的影响。
相比ID3直接使用信息熵的增益选取最佳属性,避免因某属性有较多分类取值因而有较大的信息熵,从而更容易被选中作为划分属性的情况。
决策树C4.5算法流程
在这一部分中,我们将深入探讨C4.5算法的核心流程。流程通常可以分为几个主要步骤,从数据预处理到决策树的生成,以及后续的决策树剪枝。下面是更详细的解释:
步骤1:数据准备
在决策树的构建过程中,首先需要准备一个训练数据集。这个数据集应该包含多个特征(或属性)和一个目标变量(或标签)。数据准备阶段也可能包括数据清洗和转换。
步骤2:计算信息熵
信息熵是一个用于衡量数据不确定性的度量。在C4.5算法中,使用信息熵来评估如何分割数据。
步骤3:选择最优特征
在决策树的每一个节点,算法需要选择一个特征来分割数据。选择哪个特征取决于哪个特征会导致信息熵最大的下降(或信息增益最大)。
步骤4:递归构建决策树
一旦选择了最优特征并根据该特征分割了数据,算法将在每个分割后的子集上递归地执行同样的过程,直到满足某个停止条件(如,所有数据都属于同一类别或达到预设的最大深度等)。
步骤5:决策树剪枝(可选)
决策树剪枝是一种优化手段,用于去除决策树中不必要的节点,以防止过拟合。
决策树C4.5算法代码实现
import numpy as np
class Node:
def __init__(self, gini, num_samples, num_samples_per_class, predicted_class):
self.gini = gini
self.num_samples = num_samples
self.num_samples_per_class = num_samples_per_class
self.predicted_class = predicted_class
self.feature_index = 0
self.threshold = 0
self.left = None
self.right = None
def split(nodeX, nodeY, nodeX_col, split_index, split_value):
left_indices = nodeX[:, nodeX_col] < split_value
right_indices = nodeX[:, nodeX_col] >= split_value
nodeY_left = nodeY[left_indices]
nodeX_left = nodeX[left_indices]
nodeY_right = nodeY[right_indices]
nodeX_right = nodeX[right_indices]
return nodeX_left, nodeY_left, nodeX_right, nodeY_right
def calculate_gini(groups, classes):
gini = 0.0
n_instances = float(sum([len(group) for group in groups]))
for group in groups:
size = float(len(group))
if size == 0:
continue
score = 0.0
group_classes = [row[-1] for row in group]
for class_val in classes:
p = group_classes.count(class_val) / size
score += p * p
gini += (1.0 - score) * (size / n_instances)
return gini
def get_split(dataset, labels):
class_values = list(set(labels))
b_index, b_value, b_score, b_groups = 999, 999, 999, None
for index in range(len(dataset[0])-1):
for row in dataset:
groups = [row[index] < value for value in row[index]]
score = calculate_gini(groups, class_values)
if score < b_score:
b_index, b_value, b_score, b_groups = index, row[index], score, groups
return {'index': b_index, 'value': b_value, 'groups': b_groups}
def to_terminal(group):
outcomes = [row[-1] for row in group]
return outcomes.index(max(set(outcomes), key=outcomes.count))
def split_dataset(dataset, labels, index, value):
left, right = list(), list()
for row, label in zip(dataset, labels):
if row[index] < value:
left.append(row)
else:
right.append(row)
return left, right
def grow_tree(dataset, labels, depth=0):
labels = [label[-1] for label in labels]
dataset, labels = shuffle(dataset, labels)
best问答, groups = get_split(dataset, labels)
left, right = split_dataset(dataset, labels, best问答['index'], best问答['value'])
del (best问答['groups'])
# 判断是否终止
if not left or not right:
return to_terminal(dataset)
# 递归生成子树
node = Node(gini=best问答['score'], num_samples=len(dataset), num_samples_per_class=[len(l) for l in labels], predicted_class=best问答['value'])
if len(left) > 0:
node.left = grow_tree(left, labels, depth+1)
if len(right) > 0:
node.right = grow_tree(right, labels, depth+1)
return node
def print_tree(node, depth=0):
if isinstance(node, tuple):
print("\n" + depth*" " + str(node))
else:
print("L:" + str(node.feature_index) + " <= " + str(node.threshold))
print("\n" + depth*" " + "Predict: " + str(node.predicted_class))
if node.left:
print_tree(node.left, depth+1)
if node.right:
print("L:" + str(node.feature_index) + " > " + str(node.threshold))
print("\n" + depth*" " + "Predict: " + str(node.predicted_class))
print_tree(node.right, depth+1)
def predict(node, row):
if row[node.feature_index] <= node.threshold:
if node.left:
return predict(node.left, row)
return node.predicted_class
else:
if node.right:
return predict(node.right, row)
return node.predicted_class
def shuffle(dataset, labels):
combined = list(zip(dataset, labels))
np.random.shuffle(combined)
dataset, labels = zip(*combined)
return list(dataset), list(labels)
def decision_tree_classifier(train_file_path):
train_data = np.loadtxt(train_file_path, delimiter=',')
train_data = np.array(train_data, dtype=np.float)
train_dataset = train_data[:, :-1]
train_labels = train_data[:, -1]
tree = grow_tree(train_dataset, train_labels)
print_tree(tree)
test_data = np.loadtxt("test_data.txt", delimiter=',')
test_dataset = test_data[:, :-1]
test_labels = test_data[:, -1]
predictions = list()
for row in test_dataset:
prediction = predict(tree, row)
predictions.append(prediction)
accuracy = sum([predictions[i] == test_labels[i] for i in range(len(test_labels))]) / float(len(test_labels))
print("Accuracy: " + str(accuracy))
if __name__ == "__main__":
decision_tree_classifier("train_data.txt")这段代码实现了C4.5算法的基本功能,包括数据的读取、决策树的生成、预测和准确率计算。你可以将训练数据和测试数据分别保存在train_data.txt和test_data.txt文件中,然后运行代码进行训练和测试。
决策树C4.5算法的优缺点
优点
- 易于理解和解释:决策树是白盒模型,每个节点的决策逻辑清晰,易于理解和解释。例如,银行可以轻易地解释给客户为什么他们的贷款申请被拒绝 。
- 能够处理非线性关系:C4.5算法能很好地处理特征与目标变量之间的非线性关系。例如,在电子商务网站中,用户年龄和购买意愿之间可能存在非线性关系,C4.5算法能捕捉到这种关系 。
- 对缺失值有较好的容忍性:C4.5算法可以容忍输入数据的缺失值,使其在医疗诊断等场景中仍然有效 。
- 处理连续属性:C5算法能够处理连续属性,通过单点离散化的方法选择最优的划分属性 。
- 剪枝优化:C4.5算法通过引入剪枝技术,能够有效地提升模型的泛化能力,减少过拟合的风险 。
缺点
- 容易过拟合:C4.5算法非常容易产生过拟合,尤其是当决策树很深的时候。例如,如果一个决策树模型在股票市场预测问题上表现得异常好,那很可能是该模型已经过拟合了 。
- 对噪声和异常值敏感:由于决策树模型在构建时对数据分布的微小变化非常敏感,因此噪声和异常值可能会极大地影响模型性能。例如,在识别垃圾邮件的应用中,如果训练数据包含由于标注错误而导致的噪声,C4.5算法可能会误将合法邮件分类为垃圾邮件 。
- 计算复杂度较高:C4.5算法在特征维度非常高时可能会有较高的计算成本。例如,在基因表达数据集上,由于特征数可能达到数千或更多,使用C4.5算法可能会导致计算成本增加 。
- 时间耗费大:C5算法在处理连续值时,需要计算所有可能的切分点,这使得算法的时间复杂度较高 。
- 未解决回归问题:C4.5算法主要用于分类问题,并未解决回归问题 。
决策树C4.5算法的应用场景
金融领域
- 信用评分:C4.5算法可以用于评估客户的信用风险,帮助银行和金融机构决定是否批准贷款或信用卡申请。通过构建决策树模型,可以对客户进行分类,从而为贷款审批提供依据。
- 风险评估:在金融风控中,C4.5算法可以分析客户的财务状况、信用评分等特征,评估贷款违约风险。
医疗领域
- 疾病诊断:C4.5算法可以用于辅助医生进行疾病诊断。通过对病人的特征进行分类,可以辅助医生做出更准确的诊断和治疗方案。
- 治疗方案选择:在医疗领域,C4.5算法还可以用于选择最佳的治疗方案,通过对病人的病情和治疗反应进行分析,提供个性化的治疗建议。
电商领域
- 商品推荐:在电商领域,C4.5算法可以分析用户的购买历史和行为特征,构建决策树模型,为用户推荐合适的商品。
- 用户细分:通过分析用户的行为数据,C4.5算法可以帮助电商平台进行用户细分,提供个性化的服务和营销策略。
数据挖掘
- 数据分类:C4.5算法在数据挖掘中用于将数据集分类,通过递归地将数据集划分成更小的子集,形成树状结构,以便进行决策。
- 特征选择:C4.5算法通过信息增益比(Gain Ratio)来选择最优的划分属性,构建决策树,从而在数据挖掘中实现高效的特征选择。
机器学习研究
- 算法比较:C4.5算法常与其他决策树算法(如ID3、CART和Random Forests)进行比较,研究其在不同应用场景下的适用性和性能表现。
- 模型优化:在机器学习研究中,C4.5算法的剪枝策略和对连续属性的处理机制被广泛研究,以提高模型的泛化能力和计算效率。
教育领域
- 学生评估:C4.5算法可以用于教育领域,通过分析学生的学习表现、行为特征等,预测学生的学业成绩或学习习惯。
环境监测
- 污染预测:在环境科学中,C4.5算法可以用于预测空气质量或水污染情况,通过对环境数据的分析,提供污染控制的建议。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » AI算法24-决策树C4.5算法

发表评论 取消回复