前言
本次数据继续沿用上一次主题的【组队学习——支持向量机-CSDN博客】

数据处理部分延续【组队学习——支持向量机】主题的处理办法对应划分训练集和验证集
模型选择
本次贝叶斯分类器模型的较多,常用的为高斯朴素贝叶斯分类器、多项式朴素贝叶斯分类器、伯努利朴素贝叶斯分类器、补充朴素贝叶斯分类器、分类朴素贝叶斯分类器
【参考文献:常见机器学习模型(一)—— 贝叶斯分类器_贝叶斯模型-CSDN博客】
1、理解正向概率、逆向概率的定义
2、理解逆向概率引申出来的先验概率、经验概率、条件概率的定义
正向概率:上帝视角,即了解了事情的全貌再做判断
逆向概率:事先不知道,通过经验或者后验结果或者相应条件才了解事件的全貌
借用博主【知了爱啃代码】的贝叶死病的例子帮助大家更好理解什么是贝叶斯公式,如下所示:
常见机器学习模型(一)—— 贝叶斯分类器_贝叶斯模型-CSDN博客https://blog.csdn.net/rongsenmeng2835/article/details/107778187理解原理后再了解一下对应贝叶斯分类器的类别
- 高斯朴素贝叶斯适用于连续数据。
- 多项式和伯努利朴素贝叶斯更适用于离散和二元数据。
- 补充朴素贝叶斯是多项式朴素贝叶斯的改进版本,适用于类别不平衡的问题。
- 分类朴素贝叶斯适用于分类特征的数据。
步骤1:先理解上述四种贝叶斯分类器的原理,判断本数据适用于哪种分类器的要求
步骤2:对比以上四种贝叶斯分类器,用代码计算出哪一类分类器的准确率最高
代码如下:
# 高斯朴素贝叶斯
gaussian_model = GaussianNB()
gaussian_model.fit(X_train, Y_train)
Y_pred = gaussian_model.predict(X_valid)
print(f"Gaussian Naive Bayes Accuracy: {accuracy_score(Y_valid, Y_pred)}")
# 多项式朴素贝叶斯
multinomial_model = MultinomialNB()
multinomial_model.fit(X_train, Y_train)
Y_pred = multinomial_model.predict(X_valid)
print(f"Multinomial Naive Bayes Accuracy: {accuracy_score(Y_valid, Y_pred)}")
# 伯努利朴素贝叶斯
bernoulli_model = BernoulliNB()
bernoulli_model.fit(X_train, Y_train)
Y_pred = bernoulli_model.predict(X_valid)
print(f"Bernoulli Naive Bayes Accuracy: {accuracy_score(Y_valid, Y_pred)}")
# 补充朴素贝叶斯
complement_model = ComplementNB()
complement_model.fit(X_train, Y_train)
Y_pred = complement_model.predict(X_valid)
print(f"Complement Naive Bayes Accuracy: {accuracy_score(Y_valid, Y_pred)}")拓展学习
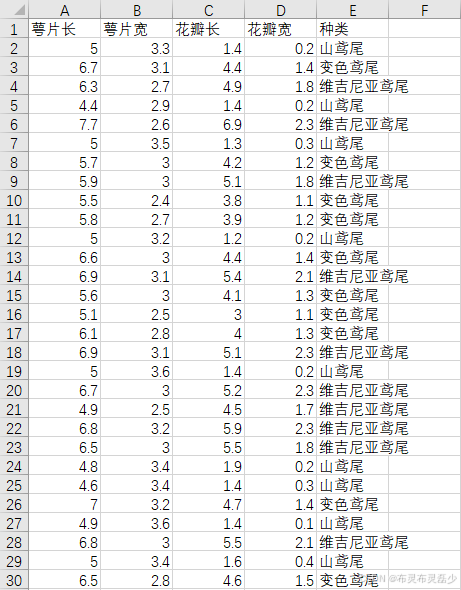
要求对鸢尾花数据集进行分类,如何进行数据预处理(提示:将分类数据转换成定量数据)
第2——145行数据为训练集和验证集数据
第146——151行数据为测试集数据
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 组队学习——贝叶斯分类器

发表评论 取消回复