问题介绍
机器学习中的监督学习主要分为回归问题和分类问题,我们之前已经讲过回归问题了,它希望预测的结果是连续的,那么分类问题所预测的结果就是离散的类别。这时输入变量可以是离散的,也可以是连续的,而监督学习从数据中学习一个分类模型或者分类决策函数,它被称为分类器(classifier)。分类器对新的输入进行输出预测,这个过程即称为分类(classification)。例如,判断邮件是否为垃圾邮件,医生判断病人是否生病,或者预测明天天气是否下雨等。同时分类问题中包括有二分类和多分类问题我们下面先讲一下最著名的二分类算法---Logistic回归。首先从Logistic 回归的起源说起。
Logistic起源
Logistic 起源于对人口数量增长情况的研究,后来又被应用到了对于微生物生长情况的研究,以及解决经济学相关的问题,现在作为回归分析的一个分支来处理分类问题,先从 Logistic 分布人手,再由 Logistic 分布推出 Logistic 回归。
Logistic分布
设 X 是连续的随机变量,服从 Logistic 分布是指 X 的积累分布函数和密度函数如下:
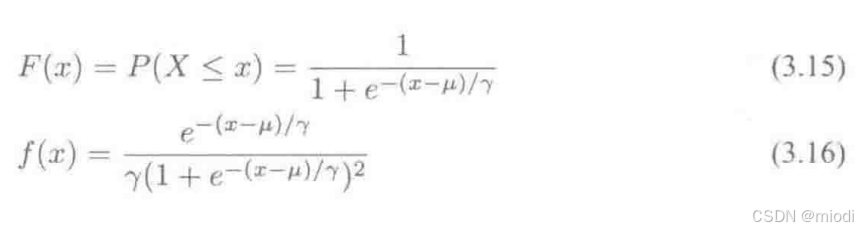
其中 μ 影响中心对称点的位置,γ 越小中心点附近的增长速度越快。下一节会讲到在深度学习中常用的一个非线性变换 Sigmoid 函数是 Logistic 分布函数中 γ=1,μ=0 的特殊形式。
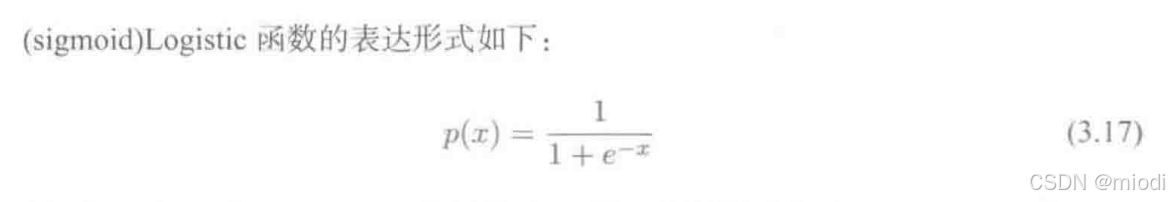
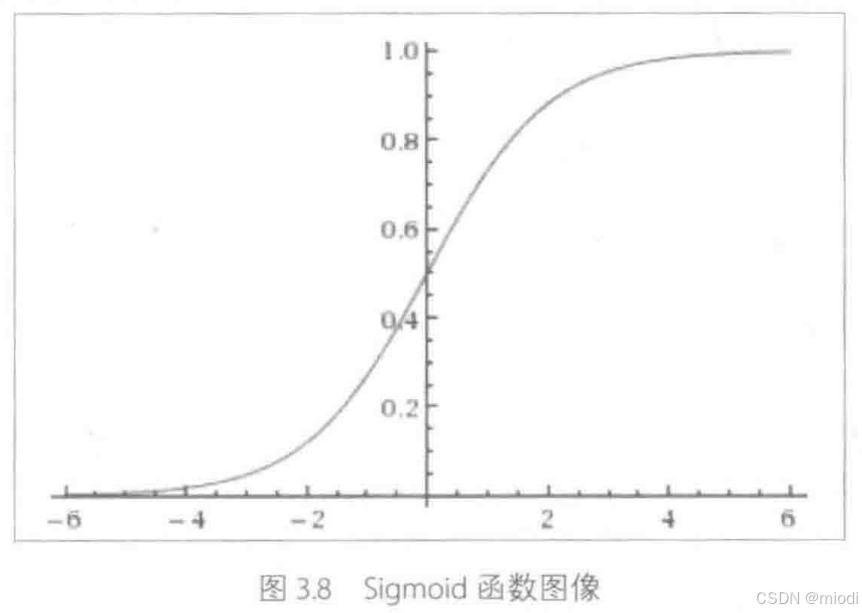
其函数图像如图 3.8 所示,由于函数很像“S”形,所以该函数又叫 Sigmoid 函数。
二分类的 Logistic 回归
Logistic 回归不仅可以解决二分类问题,也可以解决多分类问题,但是二分类问题最为常见同时也具有良好的解释性。对于二分类问题,Logistic 回归的目标是希望找到一个区分度足够好的决策边界,能够将两类很好地分开。
假设输入的数据的特征向量
;假设存在一个样本点使得
,那么可以判定它的类别是1;如果
,那么可以判定其类别是0。这个过程其实是一个感知机的过程,通过决策函数的符号来判断其属于哪一类。而 Logistic 回归要更进一步,通过找到分类概率 P(Y=1) 与输入变量x的直接关系,然后通过比较概率值来判断类别,简单来说就是通过计算下面两个概率分布:
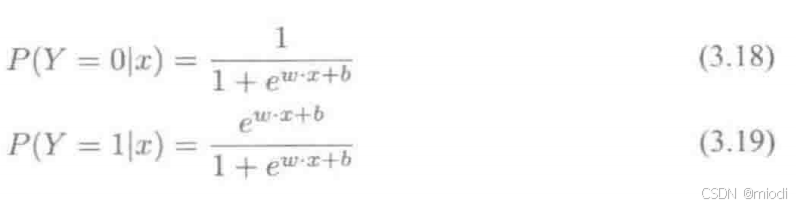
其中w是权重、b是偏置。现在介绍 Logistic 模型的特点,先引入一个概念:一个事件发生的几率(odds)是指该事件发生的概率与不发生的概率的比值,比如一个事件发生的概率是p,那么该事件发生的几率是

对于 Logistic 回归而言,我们由式 (3.16) 和式 (3.17) 可以得到:
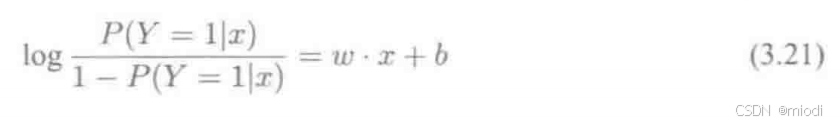
这也就是说在 Logistic 回归模型中,输出 Y=1 的对数几率是输入 x 的线性函数,这也就是 Logistic 回归名称的原因。如果观察式(3.17),则可以得到另外一种 Logistic 回归的定义,即线性函数的值越接近正无穷,概率值就越接近1;线性函数的值越接近负无穷,概率值越接近0。因此 Logistic 回归的思路是先拟合决策边界(这里的决策边界不局限于线性,还可以是多项式),在建立这个边界和分类概率的关系,从而得到二分类情况下的概率。
Logistic 回归的代码实现
首先我们打开txt文件,可以看到数据存放的方式,如图3.9所示

每个数据点是一行,每一行中前面两个数据表示 x 坐标和 y 坐标,最后一个数据表示其类别。
我们先从 data.txt 文件中读取数据,使用非常简单的 python 读取 txt 的方法就能够实现。
with open('data.txt', 'r') as f:
data_list = f.readlines()
data_list = [i.split('\n')[0] for i in data_list]
data_list = [i.split(',') for i in data_list]
data = [(float(i[0]), float(i[1]), float(i[2])) for i in data_list]然后通过matplotlib 能够简单地将数据画出来。
x0 = list(filter(lambda x: x[-1] == 0.0, data))
x1 = list(filter(lambda x: x[-1] == 1.0, data))
plot_x0_0 = [i[0] for i in x0]
plot_x0_1 = [i[1] for i in x0]
plot_x1_0 = [i[0] for i in x1]
plot_xl_1 = [i[1] for i in x1]
plt.plot(plot_x0_0, plot_x0_1, 'ro', label='x_0')
plt.plot(plot_x1_0, plot_xl_1, 'bo', label='x_1')
plt.legend(loc='best')
# plt.show()首先将两个类别分开,然后将所有的数据点画出就能够得到图3.10。
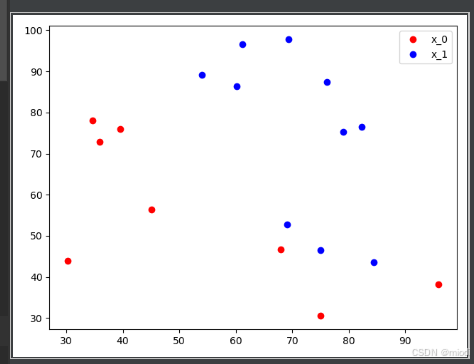
从图3.10中我们可以明显看出这些数据点被分为两个类:一类用红色的点,一类用蓝色的点,我们希望通过 Logistic 回归将它们分开。
接下来定义 Logistic 回归的模型,以及二分类问题的损失函数和优化方法。
class LogisticRegression(nn.Module):
def __init__(self):
super(LogisticRegression, self).__init__()
self.lr = nn.Linear(2, 1)
self.sm = nn.Sigmoid()
def forward(self, x):
x = self.lr(x)
x = self.sm(x)
return x
logistic_model = LogisticRegression()
if torch.cuda.is_available():
logistic_model.cuda()
criterion = nn.BCELoss()
optimizer = torch.optim.SGD(logistic_model.parameters(), lr=1e-3, momentum=0.9)
这里 nn.BCELoss 是二分类的损失函数,torch.optim.SGD 是随机梯度下降优化函数。
然后训练模型,并且间隔一定的迭代次数输出结果。
x_data = [(float(i[0]), float(i[1])) for i in data_list]
y_data = [int(i[2]) for i in data_list] # Convert labels to binary (0 or 1)
for epoch in range(50000):
if torch.cuda.is_available():
x = Variable(torch.Tensor(x_data)).cuda()
y = Variable(torch.Tensor(y_data)).cuda()
else:
x = Variable(torch.Tensor(x_data))
y = Variable(torch.Tensor(y_data))
# =================forward================
out = logistic_model(x)
y = y.unsqueeze(1)
loss = criterion(out, y)
print_loss = loss.item()
mask = out.ge(0.5).float()
correct = (mask == y).sum()
acc = correct.item() / x.size(0)
# =================backward===============
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch + 1) % 2000 == 0:
print('*' * 10)
print('epoch {}'.format(epoch + 1))
print('loss is {:.4f}'.format(print_loss))
print('acc is {:.4f}'.format(acc)) 其中 mask=out.ge(0.5).float() 是判断输出结果如果大于 0.5 就等于 1,小于 0.5 就等于 0,通过这个来计算模型分类的准确率。
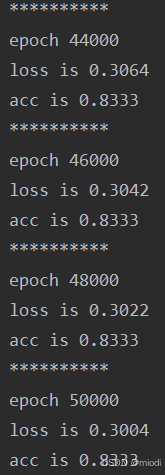
训练完成我们可以得到图3.11所示的 loss 和准确率。因为数据相对简单,同时我们使用的是也是简单的线性 Logistic 回归,loss 已经降得相对较低,同时也有 91%的准确率
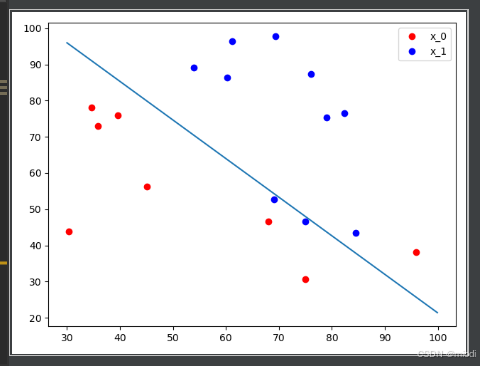
我们可以将这条直线画出来,因为模型中学习的参数 w1,w2 和 b 其实构成了一条直线 w1x+w2y+b=0,在直线上方是一类,在直线下方又是一类。我们可以通过下面的方式将模型的参数取出来,并将直线画出来,如图3.12所示
w0, w1 = logistic_model.lr.weight[0]
w0 = w0.item()
w1 = w1.item()
b = logistic_model.lr.bias.data[0].item()
plot_x = np.arange(30, 100, 0.1)
plot_y = (-w0 * plot_x - b) / w1
plt.plot(plot_x, plot_y)
plt.show()
通过图3.12我们可以看出这条直线基本上将这两类数据都分开了。
以上我们介绍了分类问题中的二分类问题和 Logistic 回归算法,一般来说,Logistic 回归也可以处理多分类问题,但最常见的还是应用在处理二分类问题上,下面我们将介绍一下使用神经网络算法来处理多分类问题。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 多层全连接神经网络(三)---分类问题

发表评论 取消回复