本文详细记录了数据库中使用到的索引的定义及其原理,以下内容为结合各大平台的知识点加自己的理解进行的总结,希望大家在读完以后能对索引有个全新的认识~~
1. 什么是索引?索引的底层数据结构
- 索引是帮助MySQL高效获取数据的数据结构(有序)
- 索引是表的目录,在查找内容之前可以先在目录中查找索引位置,以此快速定位查询数据。对于索引,会保存在额外的文件中。
- 通过索引列对数据进行排序,降低数据排序的成本,降低了CPU的消耗。
2. 索引类型分类
原文链接:https://github.com/Snailclimb/JavaGuide/blob/main/docs/database/mysql/mysql-index.md
按照数据结构维度划分:
- B+索引:MySQL 里默认和最常用的索引类型。只有叶子节点存储 value,非叶子节点只有指针和 key。存储引擎 MyISAM 和 InnoDB 实现 BTree 索引都是使用 B+Tree。
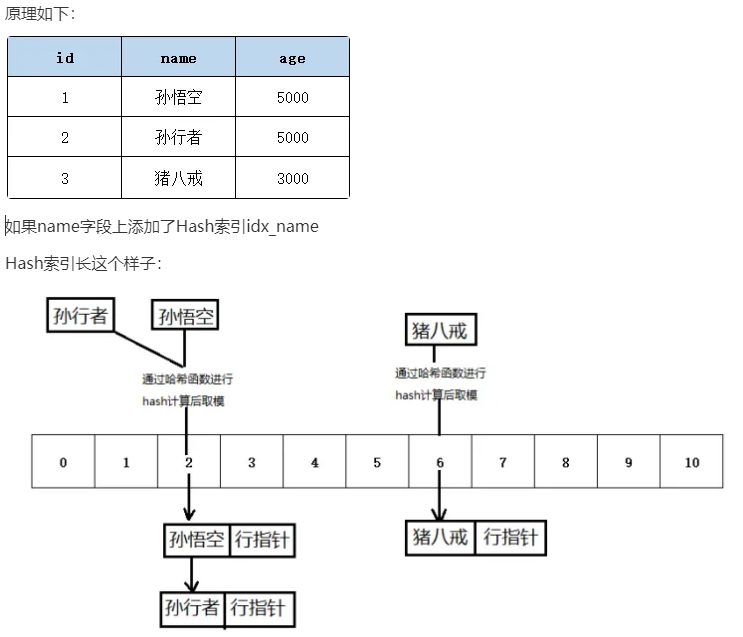
- 哈希索引:类似键值对的形式,一次即可定位。
- 全文索引:对文本的内容进行分词,进行搜索。目前只有
CHAR、VARCHAR,TEXT列上可以创建全文索引。一般不会使用,效率较低,通常使用搜索引擎如 ElasticSearch 代替。
按照底层存储方式角度划分:
- 聚簇索引:索引值和数据一起存放的索引,InnoDB 中的主键索引就属于聚簇索引。
- 非聚簇索引(非聚集索引):索引值和数据分开存放的索引,二级索引(辅助索引)就属于非聚簇索引。MySQL 的 MyISAM 引擎,不管主键还是非主键,使用的都是非聚簇索引。
按照应用维度划分:
- 主键索引:加速查询 + 列值唯一(不可以有 NULL)+ 表中只有一个。
- 普通索引:仅加速查询。
- 唯一索引:加速查询 + 列值唯一(可以有 NULL)。
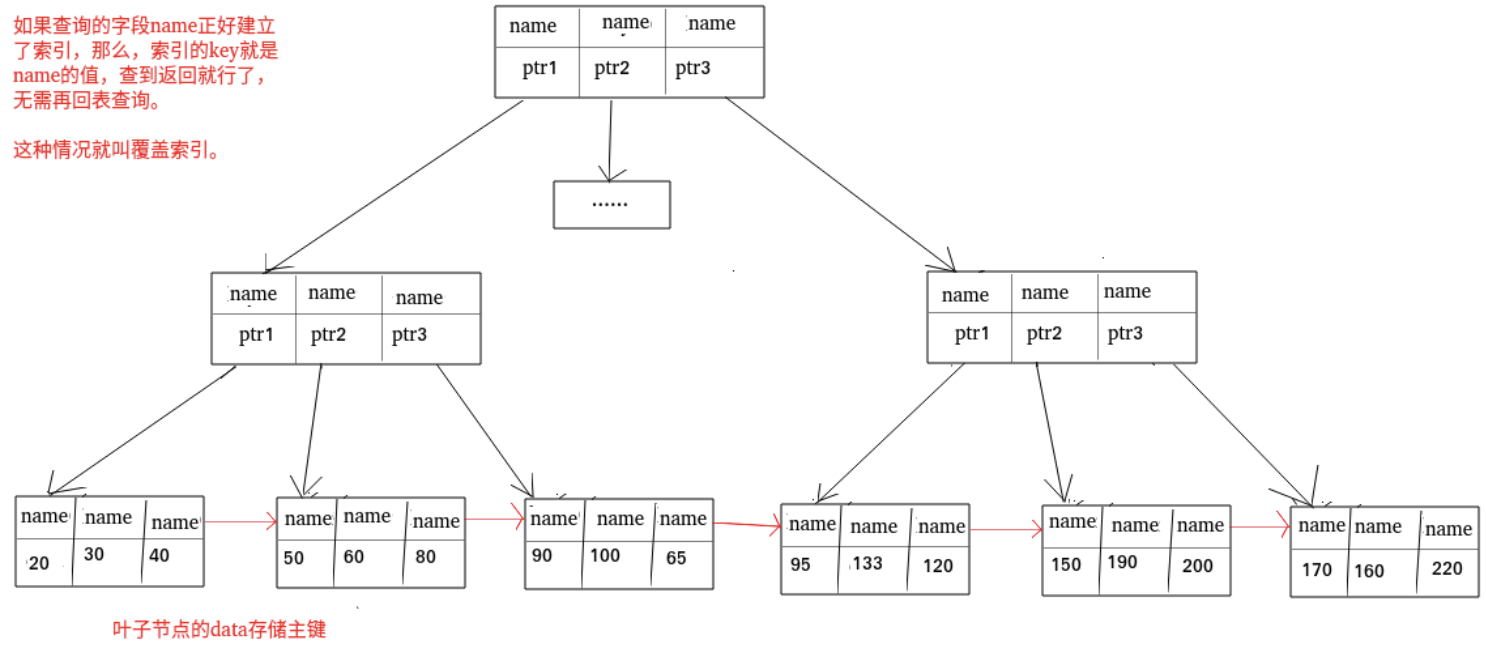
- 覆盖索引:一个索引包含(或者说覆盖)所有需要查询的字段的值。
- 联合索引:多列值组成一个索引,专门用于组合搜索,其效率大于索引合并。
- 全文索引:对文本的内容进行分词,进行搜索。目前只有
CHAR、VARCHAR,TEXT列上可以创建全文索引。一般不会使用,效率较低,通常使用搜索引擎如 ElasticSearch 代替。
创建索引的sql语句:
-- 创建唯一索引: 创建唯一索引的列的值不能重复
-- create unique index <index_name> on 表名(列名);
create unique index index_test1 on tb_testindex(tid);查看索引:
-- 查询数据表的索引
show indexes from tb_testindex;
-- 查询索引
show keys from tb_testindex;3. 聚簇索引与非聚簇索引
聚族索引:
聚簇索引指的是一类将索引值和数据存放在一起的索引,并不是一种单独的索引类型。
InnoDB 中的主键索引就属于聚簇索引。
非聚族索引:
非聚簇索引指的是索引值和数据分开存放的索引,并不是一种单独的索引类型。二级索引(辅助索引)就属于非聚簇索引。
MySQL 的 MyISAM 引擎,不管主键还是非主键,使用的都是非聚簇索引。
InnoDB的物理存储方式:当创建一张表t_user,并使用InnoDB存储引擎时,会在硬盘上生成这样一个文件:
- t_user.ibd (InnoDB data表索引 + 数据)
- t_user.frm (存储表结构信息)
MyISAM的物理存储方式:当创建一张表t_user,并使用MyISAM存储引擎时,会在硬盘上生成这样一个文件:
- t_user.MYD (表数据)
- t_user.MYI (表索引)
- t_user.frm (表结构)
注意:从MySQL8.0开始,不再生成frm文件了,引入了数据字典,用数据字典来统一存储表结构信息,例如:
- information_schema.TABLES (表包含了数据库中所有表的信息,例如表名、数据库名、引擎类型等)
- information_schema.COLUMNS(表包含了数据库中所有表的列信息,例如列名、数据类型、默认值等)
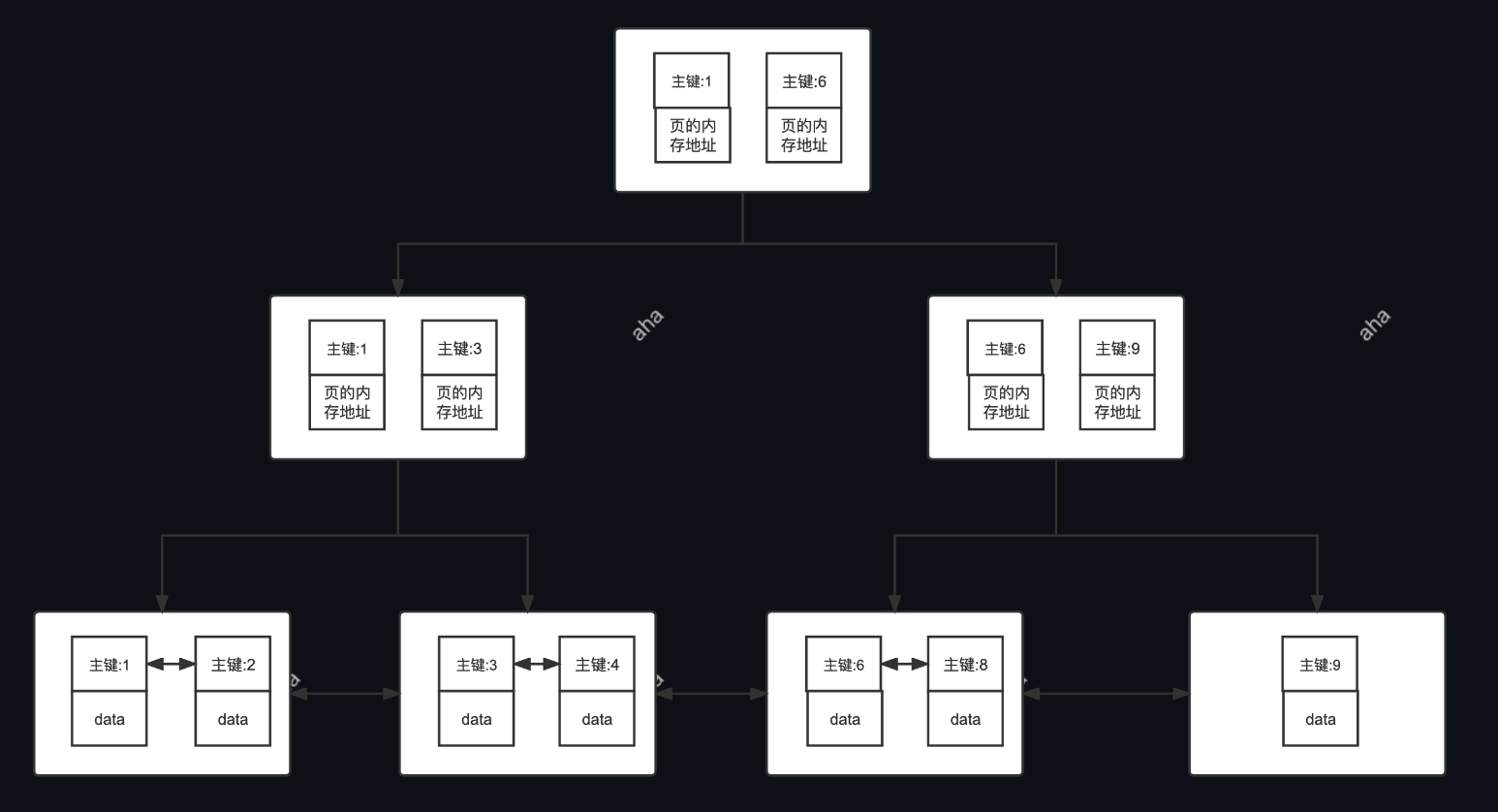
聚集索引的原理图:(B+树,叶子节点上存储了索引值 + 数据)
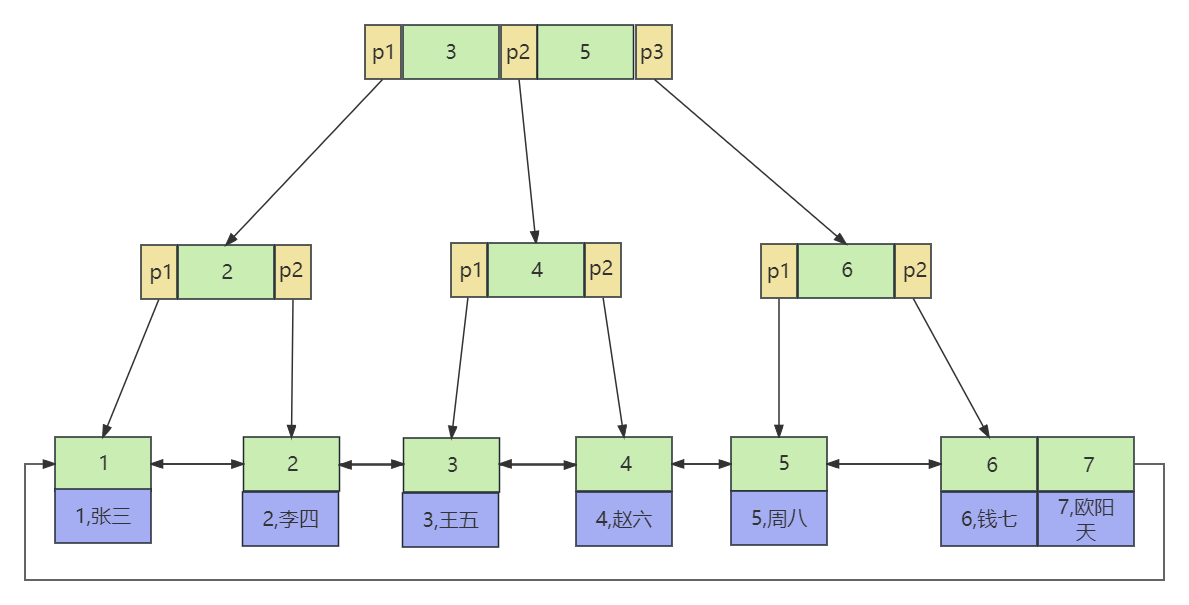
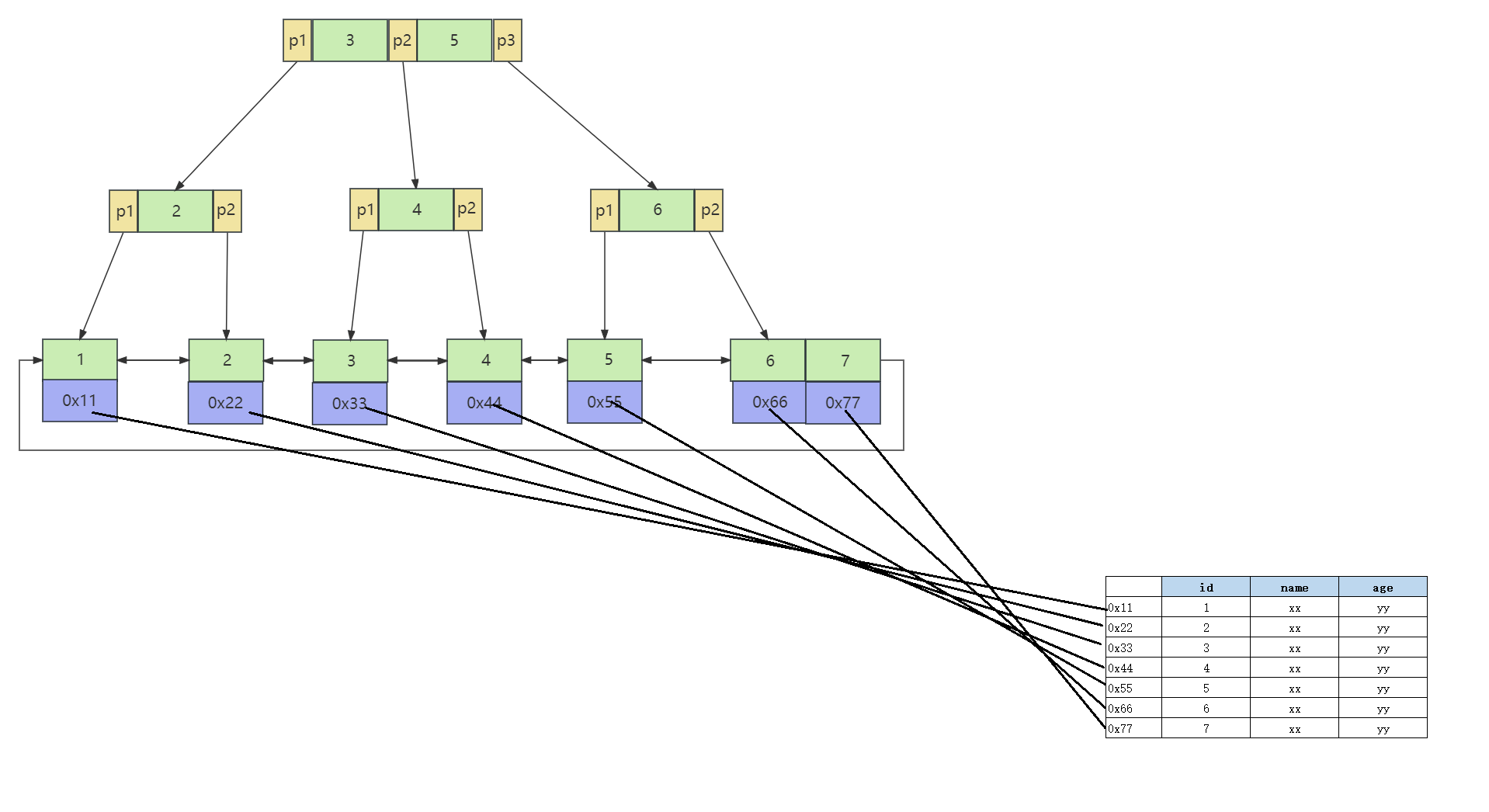
非聚集索引的原理图:(B+树,叶子节点上存储了索引值 + 行指针)
聚集索引的优点和缺点:
- 优点:聚集索引将数据存储在索引树的叶子节点上。可以减少一次查询,因为查询索引树的同时可以获取数据。
- 缺点:更新代价大,对数据进行修改或删除时需要更新索引树,会增加系统的开销。
4. 主键索引(Primary Key)
数据表的主键列使用的就是主键索引
一张数据表有只能有一个主键,并且主键不能为 null,不能重复。
在 MySQL 的 InnoDB 的表中,当没有显示的指定表的主键时,InnoDB 会自动先检查表中是否有唯一索引且不允许存在 null 值的字段,如果有,则选择该字段为默认的主键,如果没有 InnoDB 将会自动创建一个 6Byte 的自增主键。
5 二级索引
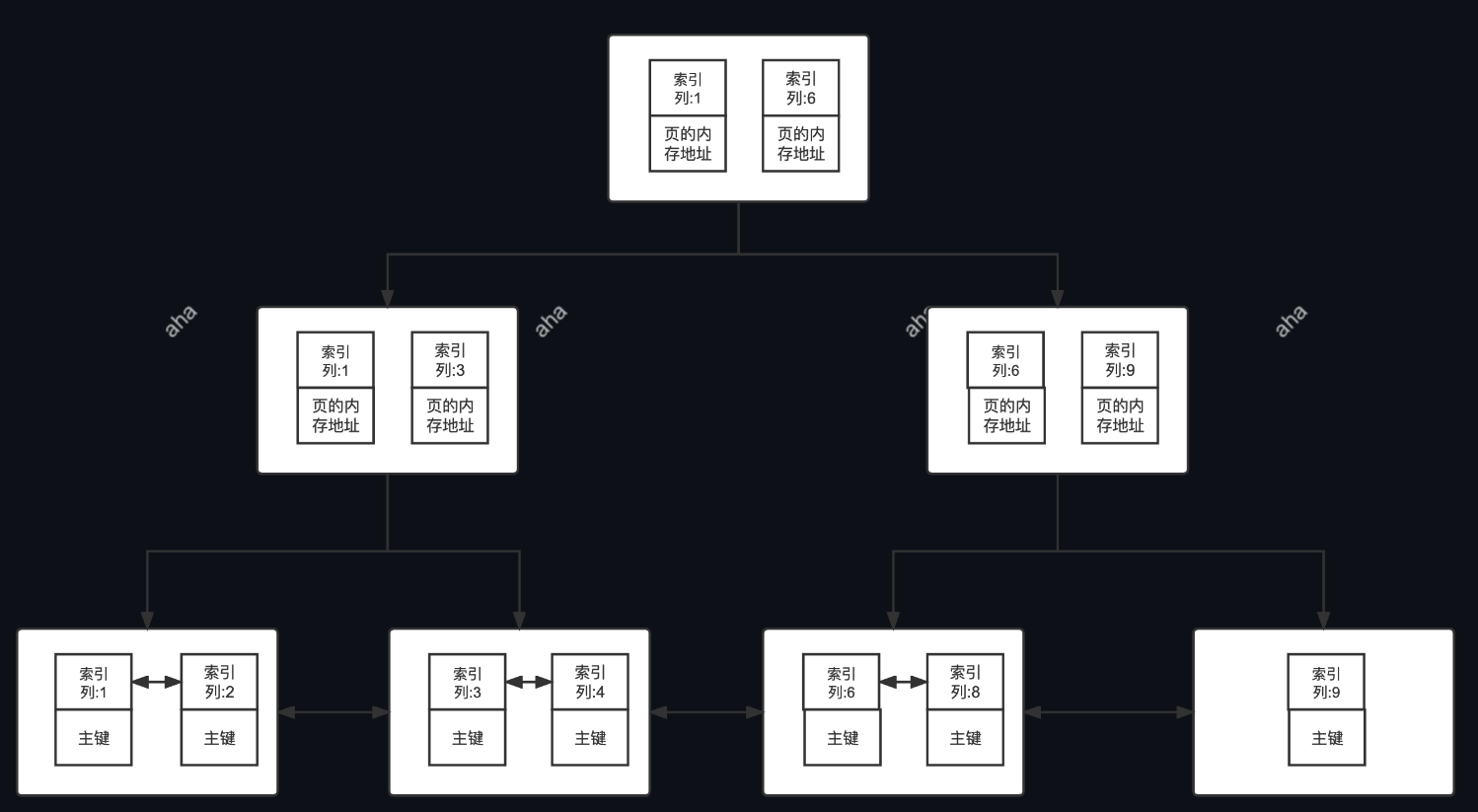
二级索引(Secondary Index)的叶子节点存储的数据是主键的值,也就是说,通过二级索引可以定位主键的位置,二级索引又称为辅助索引/非主键索引。
唯一索引,普通索引,前缀索引等索引都属于二级索引,二级索也属于非聚簇索引。
MySQL 的 MyISAM 引擎,不管主键还是非主键,使用的都是非聚簇索引。
- 唯一索引(Unique Key):唯一索引也是一种约束。唯一索引的属性列不能出现重复的数据,但是允许数据为 NULL,一张表允许创建多个唯一索引。 建立唯一索引的目的大部分时候都是为了该属性列的数据的唯一性,而不是为了查询效率。
- 普通索引(Index):普通索引的唯一作用就是为了快速查询数据,一张表允许创建多个普通索引,并允许数据重复和 NULL。
- 前缀索引(Prefix):前缀索引只适用于字符串类型的数据。前缀索引是对文本的前几个字符创建索引,相比普通索引建立的数据更小,因为只取前几个字符。
- 全文索引(Full Text):全文索引主要是为了检索大文本数据中的关键字的信息,是目前搜索引擎数据库使用的一种技术。Mysql5.6 之前只有 MYISAM 引擎支持全文索引,5.6 之后 InnoDB 也支持了全文索引。
6. 覆盖索引和联合索引
如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为覆盖索引
在 InnoDB 存储引擎中,非主键索引的叶子节点包含的是主键的值。这意味着,当使用非主键索引进行查询时,数据库会先找到对应的主键值,然后再通过主键索引来定位和检索完整的行数据。这个过程被称为"回表"。
覆盖索引即需要查询的字段正好是索引的字段,那么直接根据该索引,就可以查到数据了,而无需回表查询。
如主键索引,如果一条 SQL 需要查询主键,那么正好根据主键索引就可以查到主键。再如普通索引,如果一条 SQL 需要查询 name,name 字段正好有索引, 那么直接根据这个索引就可以查到数据,也无需回表。
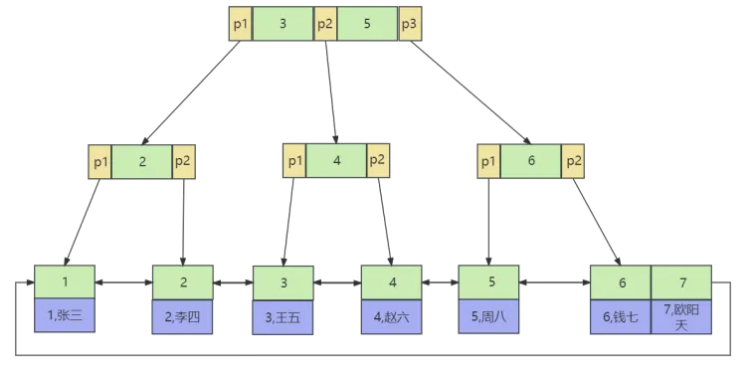
7. 什么是B树和B+树,为什么 MySQL 的索引使用B+树(16阶)而不是B树?
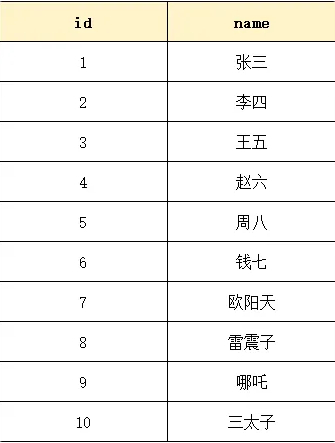
B树存储结构示意图:
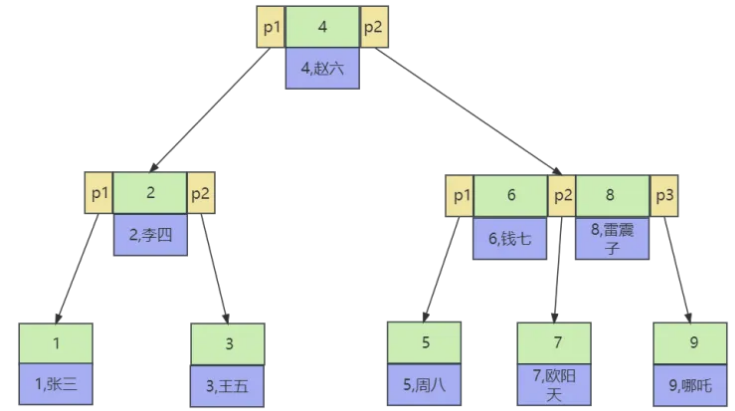
B+树存储结构示意图:
B-tree:因为B树不管叶子节点还是非叶子节点,都会保存数据,在单个节点存储容量有限的情况下,这样导致在非叶子节点中能保存的指针数量变少(有些资料也称为扇出),指针少的情况下要保存大量数据,只能增加树的高度,导致IO操作变多,查询性能变低;
B+树:B+树和B树的区别在于非叶子节点不再存储数据,数据只存储在同一层的叶子节点上,且叶节点之间增加了链表,便于查询。
Hash:虽然可以快速定位,但是没有顺序,IO复杂度高。
二叉树:树的高度不均匀,不能自平衡,查找效率跟数据有关(树的高度),并且IO代价高。
红黑树:树的高度随着数据量增加而增加,IO代价高。
为什么 MySQL 没有使用其作为索引的数据结构呢? 主要是因为 Hash 索引不支持顺序和范围查询。假如我们要对表中的数据进行排序或者进行范围查询,那 Hash 索引可就不行了。并且,每次 IO 只能取一个。
经典面试题:mysql为什么选择B+树作为索引的数据结构,而不是B树?
- 非叶子节点上可以存储更多的键值,阶数可以更大,更矮更胖,磁盘IO次数少,数据查询效率高。
- 所有数据都是有序存储在叶子节点上,让范围查找,分组查找效率更高。
- 数据页之间、数据记录之间采用链表链接,让升序降序更加方便操作。
经典面试题:如果一张表没有主键索引,那还会创建B+树吗?当一张表没有主键索引时,默认会使用一个隐藏的内置的聚集索引(clustered index)。这个聚集索引是基于表的物理存储顺序构建的,通常是使用B+树来实现的。
8. B树和B+树的区别
- B树叶子节点和非叶子节点都存储数据,B+树非叶子节点不存储数据,数据只存储在同一层的叶子节点上。
- B树的查询效率比B+树低,因为B树的内部节点存储了部分数据,在单个节点存储容量有限的情况下,会导致内部节点的大小较大,使树的高度增加,从而提高了查询效率;B+树的内部节点只存储键值对的索引信息,大小较小,在单个节点存储容量有限的情况下可以容纳更多的索引信息,从而减少了树的高度,提高了查询效率。
- B+树的叶子节点使用双向链表进行连接,可以通过遍历叶子节点来实现范围查询,而B树需要在内部节点和叶子节点之间进行额外的搜索,效率较低。同时B+树支持范围查询,因此不需要回溯内部节点。
10. InnoDB和MyISAM存储引擎的区别
- 事务支持
- InnoDB存储引擎支持事务处理,具有ACID(原子性、一致性、隔离性、持久性)特性,可以保证数据的完整性和可靠性。
- MyISAM存储引擎不支持事务,所有的操作都是原子的,不具备事务的ACID特性。
- 索引支持
- InnoDB支持聚族索引和非聚族索引,MyISAM无论是主键索引还是非主键索引都只支持非聚族索引。
- 锁级别
- InnoDB使用行级锁定,这使得在并发访问时可以提高处理能力和数据完整性。
- MyISAM使用表级锁定,这意味着在并发访问时对同一表的操作可能会导致性能瓶颈和锁定问题。
- 适用场景
- InnoDB适合需要事务支持、并发性能要求高、有复杂查询和更新操作、数据完整性要求较高的应用场景,如在线事务处理(OLTP)系统。
- MyISAM适合对事务支持要求不高、读频率远高于写频率、对数据完整性要求不严格的应用场景,如数据仓库和读密集型应用。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 数据库索引原理及其分类详解

发表评论 取消回复