1. shuffle并行度:
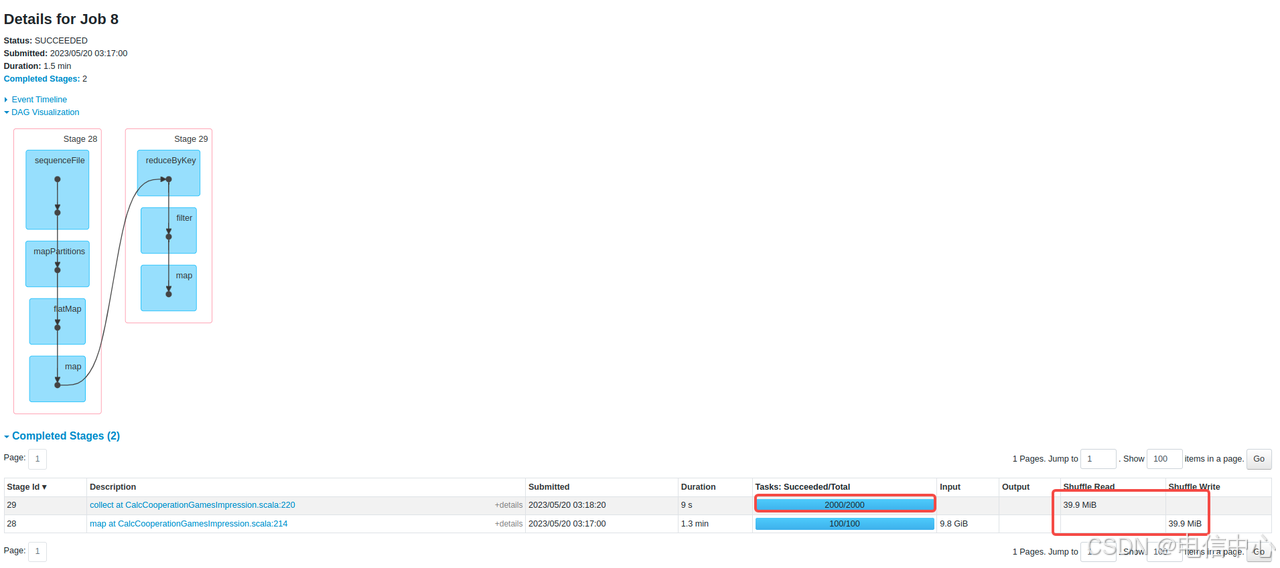
例如,如下图所示,作业中可能不止一个Job,shuffle数据只有几十mb,但是并行度设置了2000:
但是设置2000可能只是为了让作业中的一个Job的瓶颈更小:
这种可能是一种使用上的常态,其实不太合理:
如果这种情况下,怎么使用更加合理呢:
rdd程序其实控制能力极强的,常见的瓶颈算子都可以直接单独设置并行度的
例如上述图中的算子可以由 rdd.reduceByKey(keyName) 改为 rdd.reduceByKey(keyName,3000)
2.读取数据的并行度:
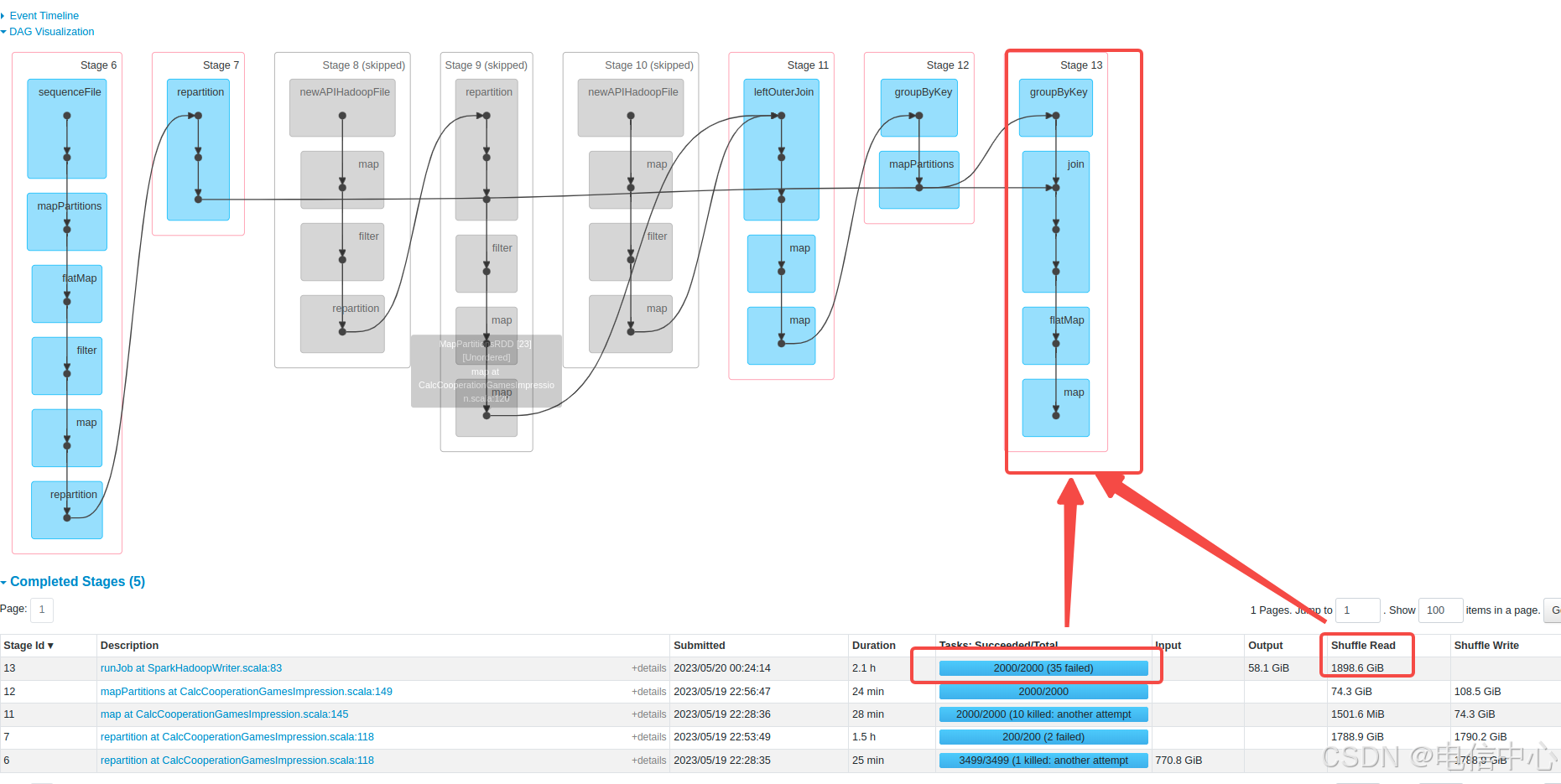
什么时候需要调整呢?有一种典型的情况,就是从hadoop输入的数据在后续的stage计算可能出现了内存瓶颈(gc时间比较长)等
-
DataSource读法,特指使用SparkSession.read这种,默认128:
spark.files.maxPartitionBytes=268435456 -
使用rdd直接读的,例如HDFSIO.thriftSequence、直接使用rdd hadoop api等,默认256(注意这个没有合并小文件功能):
spark.hadoop.mapred.max.split.size=268435456
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Spark 优化技巧-并行度设置

发表评论 取消回复