前言
向量对于机器学习非常重要,大量的算法都需要基于向量来完成。对于机器来说,字符是没有含义的,只是有区别。只使用字符无法去刻画字与字、词与词、文本与文本之间的关系,文本转化为向量可以更好地刻画文本之间的关系,向量化后,可以启用大量的机器学习算法,具有很高的价值。文本是由词和字组成的,想将文本转化为向量,首先要能够把词和字转化为向量。所有向量应该有同一维度n,我们可以称这个n维空间是一个语义空间。
我 [ 0.780290020.770109740.074791240.4106988 ] 爱 [ 0.140921940.636909710.737747120.42768218 ] 北京 [ 0.957805680.519037890.766158550.6399924 ] 天安门 [ 0.738613830.496943730.132135380.41237077 ] \begin{align}我 [0.78029002 0.77010974 0.07479124 0.4106988 ]\\ 爱 [0.14092194 0.63690971 0.73774712 0.42768218]\\ 北京 [0.95780568 0.51903789 0.76615855 0.6399924 ]\\ 天安门 [0.73861383 0.49694373 0.13213538 0.41237077]\end{align} 我[0.780290020.770109740.074791240.4106988]爱[0.140921940.636909710.737747120.42768218]北京[0.957805680.519037890.766158550.6399924]天安门[0.738613830.496943730.132135380.41237077]
One-hot编码
首先统计一个字表或词表,选出n个字或词:
今天 [ 1 , 0 , 0 , 0 , 0 ] 天气 [ 0 , 1 , 0 , 0 , 0 ] 真 [ 0 , 0 , 1 , 0 , 0 ] 不错 [ 0 , 0 , 0 , 1 , 0 ] 。 [ 0 , 0 , 0 , 0 , 1 ] \begin{align}今天 [1, 0, 0, 0, 0] \\ 天气 [0, 1, 0, 0, 0]\\ 真 [0, 0, 1, 0, 0]\\ 不错 [0, 0, 0, 1, 0]\\ 。 [0, 0, 0, 0, 1]\end{align} 今天[1,0,0,0,0]天气[0,1,0,0,0]真[0,0,1,0,0]不错[0,0,0,1,0]。[0,0,0,0,1]
将向量相加,组成句子:
今天不错 [ 1 , 0 , 0 , 1 , 0 ] 今天真不错 [ 1 , 0 , 1 , 1 , 0 ] \begin{align}今天 不错 [1, 0, 0, 1, 0] \\ 今天 真 不错 [1, 0, 1, 1, 0]\end{align} 今天不错[1,0,0,1,0]今天真不错[1,0,1,1,0]
在对文本向量化时,也可以考虑词频:
不错 [ 0 , 0 , 0 , 1 , 0 ] 不错不错 [ 0 , 0 , 0 , 2 , 0 ] \begin{align}不错 [0, 0, 0, 1, 0]\\ 不错 不错 [0, 0, 0, 2, 0]\end{align} 不错[0,0,0,1,0]不错不错[0,0,0,2,0]
有时也可以不事先准备词表,临时构建,如做文本比对任务,成对输入,把相同字的所在列设置为1,此时维度可随时变化:
例 1 : 你好吗心情 A : 你好吗 [ 1 , 1 , 1 , 0 , 0 ] B : 你心情好吗 [ 1 , 1 , 1 , 1 , 1 ] 例 2 :我不知道谁呀 A : 我不知道 [ 1 , 1 , 1 , 1 , 0 , 0 ] B : 谁知道呀 [ 0 , 0 , 1 , 1 , 1 , 1 ] \begin{align}例1:你好吗心情\\ A: 你好吗 [1, 1, 1, 0, 0]\\ B: 你心情好吗 [1, 1, 1, 1, 1]\\ 例2: 我不知道谁呀\\ A:我不知道 [1, 1, 1, 1, 0, 0]\\ B:谁知道呀 [0, 0, 1, 1, 1, 1]\end{align} 例1:你好吗心情A:你好吗[1,1,1,0,0]B:你心情好吗[1,1,1,1,1]例2:我不知道谁呀A:我不知道[1,1,1,1,0,0]B:谁知道呀[0,0,1,1,1,1]
one-hot编码-缺点
- 如果有很多词,编码向量维度会很高,而且向量十分稀疏(大部分位置都是零),计算负担很大(维度灾难)。
- 编码向量不能反映字词之间的语义相似性,只能做到区分。
word2vec-词向量
我们希望得到一种词向量有以下性质
- 向量关系能反映语义关系,比如:cos(你好, 您好) > cos(你好,天气),即词义的相似性反映在向量的相似性。
- 向量可以通过数值运算反映词之间的关系,国王 - 男人 = 皇后 -女人。
- 同时,不管有多少词,向量维度应当是固定的。
word2vec-词向量,本质上是一样的,都是以向量代表字符,一般说Word Embedding是指随机初始化的词向量或字向量Word2Vec一般指一种训练Word Embedding的方法,使得其向量具有一定的性质(向量相似度反映语义相似度)。
基于语言模型的训练方式
这是Bengio et al在《A Neural Probabilistic Language Model》提出的训练方式,做出假设:每段文本中的某一个词,由它前面n个词决定。例如:
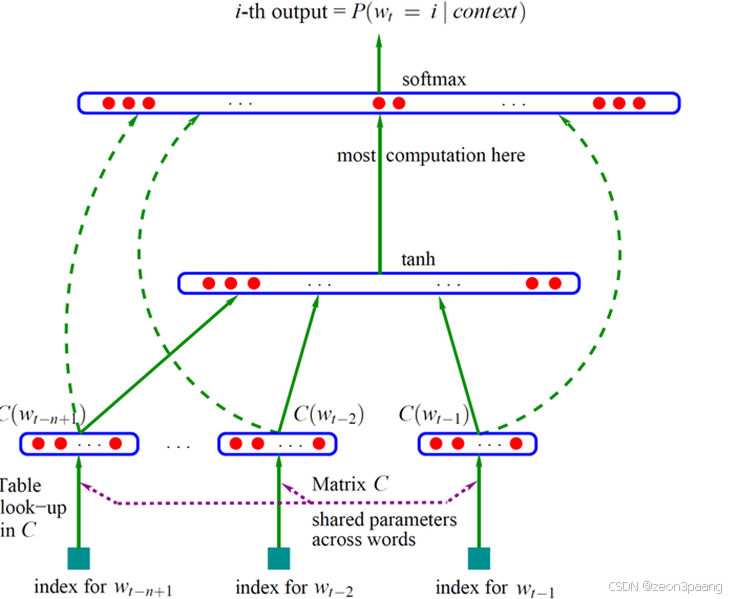
今天 天气 不错 我们 出去 玩
今天 -> 天气
今天 天气 -> 不错
今天 天气 不错 -> 我们
今天 天气 不错 我们 -> 出去
论文中的网络层的公式为: y = b + W ∗ x + U ∗ t a n h ( d + H x ) y=b+W*x+U*tanh(d+Hx) y=b+W∗x+U∗tanh(d+Hx)
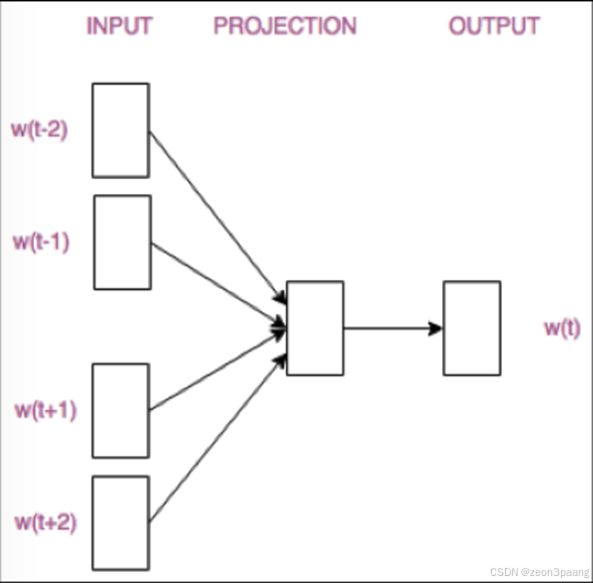
基于窗口——CBOW
做出假设:如果两个词在文本中出现时,它的前后出现的词相似,则这两个词语义相似。如:
基于前述思想,我们尝试用窗口中的词(或者说周围词)来表示(预测)中间词,这个称为CBOW模型。如:

窗口:你 想 明白 了 吗
输入:你 想 了 吗
输出:明白
对于CBOW的网络层有如下的计算方式:
class CBOW(nn.Module):
def __init__(self, vocab_size, embedding_size, window_length):
super(CBOW, self).__init__()
self.word_vectors = nn.Embedding(vocab_size, embedding_size)
self.pooling = nn.AvgPool1d(window_length)
self.projection_layer = nn.Linear(embedding_size, vocab_size)
def forward(self, context):
context_embedding = self.word_vectors(context) #batch_size * max_length * embedding size 1*4*4
#transpose: batch_size * embedding size * max_length -> pool: batch_size * embedding_size * 1 -> squeeze:batch_size * embeddig_size
context_embedding = self.pooling(context_embedding.transpose(1, 2)).squeeze()
#batch_size * embeddig_size -> batch_size * vocab_size
pred = self.projection_layer(context_embedding)
return pred
由embedding层和pooling层,最后经过线性层实现的,所以相比语言模型,CBOW的训练的参数相对较少,训练速度更快,而且CBOW更依赖Embedding层,所以训练出来的词向量更好一点。
基于窗口——SkipGram
或用中间词来表示周围词,这个称为SkipGram模型,窗口:你想明白了吗
(输入,输出): (明白 , 你) (明白 , 想) (明白 , 了) (明白 , 吗) \begin{align}(明白,你)\\ (明白,想)\\ (明白,了)\\ (明白,吗)\end{align} (明白,你)(明白,想)(明白,了)(明白,吗)
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » NLP之词的向量化

发表评论 取消回复