1.分布式搜索引擎:luceneVS Solr VS Elasticsearch
什么是分布式搜索引擎
搜索引擎:数据源:数据库或者爬虫资源
分布式存储与搜索:多个节点组成的服务,提高扩展性(扩展成集群)
使用搜索引擎为搜索提供服务。可以从海量数据 中快速的获取到用户想要的数据,并且反馈给用户;可以提升存储量,分布式,可以部署在多个节点之上,分散存储。
luceceVS Solr VS Elasticsearch
倒排序索引:共同特点
Lucene:类库,api,本质是jar包,只能使用java整合
Solr:基于lucece,对Lucene的封装,Apache开源项目,实现集群通过zookeeper
国外互联网大厂在使用。
ES:基于lucene,提供restful类型的接口为我们提供服务。任何开发语言
2.Elasticsearch核心术语
ES->类比:数据库
索引index–》类比:表
文档(document)–>行,记录
字段fields->列
stu_index:索引
{
id: 1001,
name: jason,
age: 19
},//{}内容为文档,id,name,age都是字段
{
id: 1002,
name: tom,
age: 18
},
{
id: 1003,
name: rose,
age: 22
}
文档都是以json格式存在的。
映射mapping:类比表结构定义(int,char,长度,是不是null等)
近实时NRT:near real time一般一秒左右,近实时搜索
节点node:每一个服务器
Shard repica:数据分片和备份
age: 22
}
集群相关
分片(shard):把索引库拆分为多份,分别放在不同的节点上,比如有3个节点,3个节点的所有数据内容加在一起是一个完整的索引库。分别保存到三个节点上,目的为了水平扩展,提高吞吐量。
备份(replica):每个shard的备份。
简称
shard = primary shard(主分片)
replica = replica shard(备份节点)
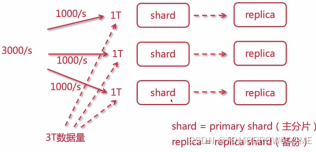
3.Elasticsearch集群架构原理
多个es节点组成集群(多个shard),平均分配,1000/s是吞吐量。当有宕机后,使用repica作为备份。分片提高性能。
4.什么是倒排索引
正排索引:
相当于文档中的一条条记录;
例子:汉语值得学习;汉语是语言;汉语学习视频;
倒排索引:起源于实际应用中需要根据属性的值来查询记录。这种索引表的每一项都包括一个属性值和包含该属性值得各个记录地址。由于不是根据记录来确定属性,而是根据属性来确定记录的位置。
可以记录文档的ids,词频跟位置
例子:汉语值得学习;汉语是语言;汉语学习视频;
| 单词 | 文档ids | 词频TF;位置POS |
|---|---|---|
| 汉 | 1,2,3 | 1:1<1>,2:1<1>,3:1<1> |
| 语 | 1,2,3 | 1:1<2>,2:2<2,4>,3:1<2> |
| 值得 | 1 | 1:1:<3> |
| 学习 | 1,3 | 1:1<4>,3:1:<3> |
| 是 | 2 | 1:1;<3> |
| 言 | 2 | 2:1:<5> |
| 视频 | 3 | 3:1:<4> |
5.安装Elasticsearch
上传后解压:
移动后的es文件:
ES 目录介绍
bin:可执行文件在里面,运行es的命令就在这个里面,包含了一些脚本文件等
config:配置文件目录
JDK:java环境
lib:依赖的jar,类库
logs:日志文件
modules:es相关的模块
plugins:可以自己开发的插件
data:这个目录没有,自己新建一下,后面要用 -> mkdir data,这个作为索引目录

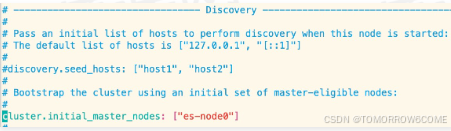
修改核心配置文件 elasticearch.yml
修改集群名称,默认是elasticsearch,虽然目前是单机,但是也会有默认的
为当前的es节点取个名称,名称随意,如果在集群环境中,都要有相应的名字
修改data数据保存地址
修改日志数据保存地址
绑定es网络ip,原理同redis
默认端口号,可以自定义修改
集群节点
修改JVM参数
默认xms和xmx都是1g,虚拟机内存没这么大,修改一下即可
添加用户
ES不允许使用root操作es,需要添加用户,操作如下:




useradd esuser
chown -R esuser:esuser /usr/local/elasticsearch-7.4.2
su esuser
whoami
whoami
启动ES
./elasticsearch
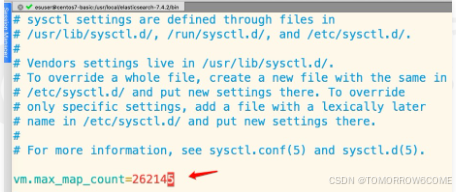
如果出现如下错误:

那么需要切换到root用户下去修改配置如下:
vim /etc/security/limits.conf
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
别忘记 sysctl -p 刷新一下
最后再次启动OK

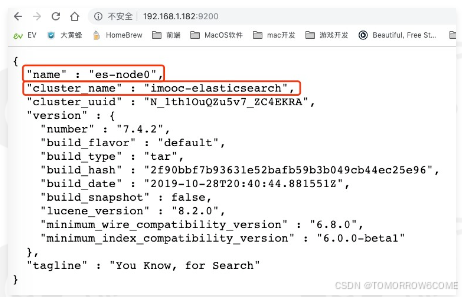
测试
访问你的虚拟机ip+端口号9200,如下则表示OK
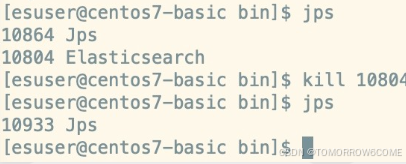
停止es
如果是前台启动,直接ctrl+c就可以停止
后台启动:
./elasticsearch -d
停止杀进程:
端口号意义
9200:Http协议,用于外部通讯
9300:Tcp协议,ES集群之间是通过9300通讯
6.安装es-header插件
由于无法访问GitHub官网,以及google应用商店,在网上找到教程通过GitClone去访问GitHub。然后在csdn找到别人别人提供的es-head的google商店扩展程序的安装包,完成es-head的一种安装方式。
扩展程序的安装地址:
GiuClone地址:https://www.gitclone.com/

安装node.js:最好结合下面两个教程:
https://blog.csdn.net/qq_39038178/article/details/125403896
https://zhuanlan.zhihu.com/p/542932711
需要在测试的后台开启跨域权限。
npm run start
总结;独立部署或者通过google扩展程序都很不错;主要有两种实现方式;
独立部署:
使用google extension:

本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 分布式搜索引擎ES-elasticsearch入门

发表评论 取消回复