一、背景与效果
ICBU的核心沟通场景有了10年的“积累”,核心场景的界面响应耗时被拉的越来越长,也让性能优化工作提上了日程,先说结论,经过这一波前后端齐心协力的优化努力,两个核心界面90分位的数据,FCP平均由2.6s下降到1.9s,LCP平均由2.8s下降到2s。
本文主要着眼于服务端在此次性能优化过程中做的工作,供大家参考讨论。
二、措施一:流式分块传输(核心)
2.1. HTTP分块传输介绍
分块传输编码(Chunked Transfer Encoding)是一种HTTP/1.1协议中的数据传输机制,它允许服务器在不知道整个内容大小的情况下,就开始传输动态生成的内容。这种机制特别适用于生成大量数据或者由于某种原因数据大小未知的情况。
在分块传输编码中,数据被分为一系列的“块”(chunk)。每一个块都包括一个长度标识(以十六进制格式表示)和紧随其后的数据本身,然后是一个CRLF(即"\r\n",代表回车和换行)来结束这个块。块的长度标识会告诉接收方这个块的数据部分有多长,使得接收方可以知道何时结束这一块并准备好读取下一块。
当所有数据都发送完毕时,服务器会发送一个长度为零的块,表明数据已经全部发送完毕。零长度块后面可能会跟随一些附加的头部信息(尾部头部),然后再用一个CRLF来结束整个消息体。
我们可以借助分块传输协议完成对切分好的vm进行分块推送,从而达到整体HTML界面流式渲染的效果,在实现时,只需要对HTTP的header进行改造即可:
public void chunked(HttpServletRequest request, HttpServletResponse response) {try (PrintWriter writer = response.getWriter()) {// 设置响应类型和编码oriResponse.setContentType(MediaType.TEXT_HTML_VALUE + ";charset=UTF-8");oriResponse.setHeader("Transfer-Encoding", "chunked");oriResponse.addHeader("X-Accel-Buffering", "no");// 第一段Context modelMain = getmessengerMainContext(request, response, aliId);flushVm("/velocity/layout/Main.vm", modelMain, writer);// 第二段Context modelSec = getmessengerSecondContext(request, response, aliId, user);flushVm("/velocity/layout/Second.vm", modelSec, writer);// 第三段Context modelThird = getmessengerThirdContext(request, response, user);flushVm("/velocity/layout/Third.vm", modelThird, writer);} catch (Exception e) {// logger}}private void flushVm(String templateName, Context model, PrintWriter writer) throws Exception {StringWriter tmpWri = new StringWriter();// vm渲染engine.mergeTemplate(templateName, "UTF-8", model, tmpWri);// 数据写出writer.write(tmpWri.toString());writer.flush();}
2.2. 页面流式分块传输优化方案
我们现在的大部分应用都是springmvc架构,浏览器发起请求,后端服务器进行数据准备与vm渲染,之后返回html给浏览器。
从请求到达服务端开始计算,一次HTML请求到页面加载完全要经过网络请求、网络传输与前端资源渲染三个阶段:
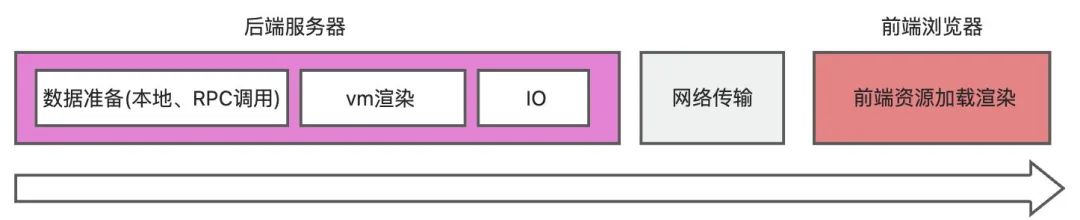
HTML流式输出,思路是对HTML界面进行拆分,之后由服务器分批进行推送,这样做有两个好处:
-
服务端分批进行数据准备,可以减少首次需要准备的数据量,极大缩短准备时间。
-
浏览器分批接收数据,当接收到第一部分的数据时,可以立刻进行js渲染,提升其利用率。
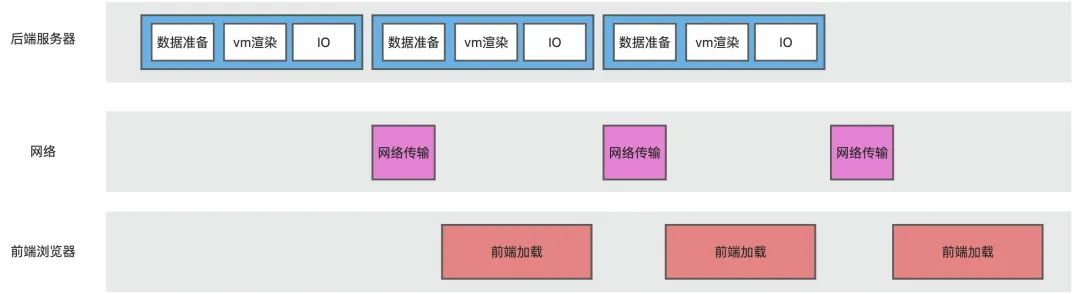
这个思路对需要加载资源较多的页面有很明显的效果,在我们此次的界面优化中,页面的FCP与LCP均有300ms-400ms的性能提升,在进行vm界面的数据拆分时,有以下几个技巧:
-
注意界面资源加载的依赖关系,前序界面不能依赖后序界面的变量。
-
将偏静态与核心的资源前置,后端服务器可以快速完成数据准备并返回第一段html供前端加载。
2.3. 注意事项
此次优化的应用与界面本身历史包袱很重,在进行流式改造的过程中,我们遇到了不少的阻力与挑战,在解决问题的过程也学到了很多东西,这部分主要对遇到的问题进行整理。
-
二方包或自定义的HTTP请求 filter 会改写 response 的 header,导致分块传输失效。如果应用中有这种情况,我们在进行流式推送时,可以获取到最原始的response,防止被其他filter影响:
/*** 防止filter或者其他代理包装了response并开启缓存* 这里获取到真实的response** @param response* @return*/private static HttpServletResponse getResponse(HttpServletResponse response) {ServletResponse resp = response;while (resp instanceof ServletResponseWrapper) {ServletResponseWrapper responseWrapper = (ServletResponseWrapper) resp;resp = responseWrapper.getResponse();}return (HttpServletResponse) resp;}
-
谷歌浏览器禁止跨域名写入cookie,我们的应用界面会以iframe的形式嵌入其他界面,谷歌浏览器正在逐步禁止跨域名写cookie,如下所示:

为了确保cookie能正常写入,需要指定cookie的SameSite=None。
-
VelocityEngine模板引擎的自定义tool。
我们的项目中使用的模板引擎为VelocityEngine,在流式分块传输时,需要手动渲染vm:
private void flushVm(String templateName, Context model, PrintWriter writer) throws Exception {StringWriter tmpWri = new StringWriter();// vm渲染engine.mergeTemplate(templateName, "UTF-8", model, tmpWri);// 数据写出writer.write(tmpWri.toString());writer.flush();}
需要注意的是VelocityEngine模板引擎支持自定义tool,在vm文件中是如下的形式,当vm引擎渲染到对应位置时,会调用配置好的方法进行解析:
<title>$tool.do("xx", "$!{arg}")</title>如果用注解的形式进行vm渲染,框架本身会帮我们自动做tools的初始化。但如果我们想手动渲染vm,那么需要将这些tools初始化到context中:
/*** 初始化 toolbox.xml 中的工具*/private Context initContext(HttpServletRequest request, HttpServletResponse response) {ViewToolContext viewToolContext = null;try {ServletContext servletContext = request.getServletContext();viewToolContext = new ViewToolContext(engine, request, response, servletContext);VelocityToolsRepository velocityToolsRepository = VelocityToolsRepository.get(servletContext);if (velocityToolsRepository != null) {viewToolContext.putAll(velocityToolsRepository.getTools());}} catch (Exception e) {LOGGER.error("createVelocityContext error", e);return null;}}
对于比较古老的应用,VelocityToolsRepository需要将二方包版本进行升级,而且需要注意,velocity-spring-boot-starter升级后可能存在tool.xml文件失效的问题,建议可以采用注解的形式实现tool,并且注意tool对应java类的路径。
@DefaultKey("assetsVersion")public class AssertsVersionTool extends SafeConfig {public String get(String key) {return AssetsVersionUtil.get(key);}}
-
Nginx 的 location 配置
server {location ~ ^/chunked {add_header X-Accel-Buffering no;proxy_http_version 1.1;proxy_cache off; # 关闭缓存proxy_buffering off; # 关闭代理缓冲chunked_transfer_encoding on; # 开启分块传输编码proxy_pass http://backends;}}
-
ngnix配置本身可能存在对流式输出的不兼容,这个问题是很难枚举的,我们遇到的问题是如下配置,需要将SC_Enabled关闭。
SC_Enabled on;SC_AppName gangesweb;SC_OldDomains //b.alicdn.com;SC_NewDomains //b.alicdn.com;SC_OldDomains //bg.alicdn.com;SC_NewDomains //bg.alicdn.com;SC_FilterCntType text/html;SC_AsyncVariableNames asyncResource;SC_MaxUrlLen 1024;
详见:https://github.com/dinic/styleCombine3
-
ngnix缓冲区大小,在我们优化的过程中,某个应用并没有指定缓冲区大小,取的默认值,我们的改造导致http请求的header变大了,导致报错upstream sent too big header while reading response header from upstream
proxy_buffers 128 32k;proxy_buffer_size 64k;proxy_busy_buffers_size 128k;client_header_buffer_size 32k;large_client_header_buffers 4 16k;
如果页面在浏览器上有问题时,可以通过curl命令在服务器上直接访问,排查是否为ngnix的问题:
curl --trace - 'http://127.0.0.1:7001/chunked' \-H 'cookie: xxx'
-
ThreadLocal与StreamingResponseBody
在开始,我们使用StreamingResponseBody来实现的分块传输:
@GetMapping("/chunked")public ResponseEntity<StreamingResponseBody> streamChunkedData() {StreamingResponseBody stream = outputStream -> {// 第一段Context modelMain = getmessengerMainContext(request, response, aliId);flushVm("/velocity/layout/Main.vm", modelMain, writer);// 第二段Context modelSec = getmessengerSecondContext(request, response, aliId, user);flushVm("/velocity/layout/Second.vm", modelSec, writer);// 第三段Context modelThird = getmessengerThirdContext(request, response, user);flushVm("/velocity/layout/Third.vm", modelThird, writer);}};return ResponseEntity.ok().contentType(MediaType.TEXT_HTML).body(stream);}}
但是我们在运行时发现vm的部分变量会渲染失败,卡点了不少时间,后面在排查过程中发现应用在处理http请求时会在ThreadLocal中进行用户数据、request数据与部分上下文的存储,而后续vm数据准备时,有一部分数据是直接从中读取或者间接依赖的,而StreamingResponseBody本身是异步的(可以看如下的代码注释),这就导致新开辟的线程读不到原线程ThreadLocal的数据,进而渲染错误:
/*** A controller method return value type for asynchronous request processing* where the application can write directly to the response {@code OutputStream}* without holding up the Servlet container thread.** <p><strong>Note:</strong> when using this option it is highly recommended to* configure explicitly the TaskExecutor used in Spring MVC for executing* asynchronous requests. Both the MVC Java config and the MVC namespaces provide* options to configure asynchronous handling. If not using those, an application* can set the {@code taskExecutor} property of* {@link org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter* RequestMappingHandlerAdapter}.** @author Rossen Stoyanchev* @since 4.2*/@FunctionalInterfacepublic interface StreamingResponseBody {/*** A callback for writing to the response body.* @param outputStream the stream for the response body* @throws IOException an exception while writing*/void writeTo(OutputStream outputStream) throws IOException;}
三、措施二:非流量中间件优化
在性能优化过程中,我们发现在流量高峰期,某个服务接口的平均耗时会显著升高,结合arths分析发现,是由于在流量高峰期,对于配置中心的调用被限流了。原因是配置中心的使用不规范,每次都是调用getConfig方法从配置中心服务端拉取的数据。
在读取配置中心的配置时,更标准的使用方法是由配置中心主动推送变更,客户端监听配置信息缓存到本地,这样,每次读取配置其实读取的是机器的本地缓存,可以参考如下的方式:
public static void registerDynamicConfig(final String dataIdKey, final String groupName) {IOException initError = null;try {String e = Diamond.getConfig(dataIdKey, groupName, DEFAULT_TIME_OUT);if(e != null) {getGroup(groupName).put(dataIdKey, e);}logger.info("Diamond config init: dataId=" + dataIdKey + ", groupName=" + groupName + "; initValue=" + e);} catch (IOException e) {logger.error("Diamond config init error: dataId=" + dataIdKey, e);initError = e;}Diamond.addListener(dataIdKey, groupName, new ManagerListener() {@Overridepublic Executor getExecutor() {return null;}@Overridepublic void receiveConfigInfo(String s) {String oldValue = (String)DynamicConfig.getGroup(groupName).get(dataIdKey);DynamicConfig.getGroup(groupName).put(dataIdKey, s);DynamicConfig.logger.warn("Receive config update: dataId=" + dataIdKey + ", newValue=" + s + ", oldValue=" + oldValue);}});if(initError != null) {throw new RuntimeException("Diamond config init error: dataId=" + dataIdKey, initError);}}
四、措施三:数据直出
-
静态图片直出,页面上有静态的loge图片,原本为cdn地址,在浏览器渲染时,需要建联并会抢占线程,对于这类不会发生发生变化的图片,可以直接替换为base64的形式,js可以直接加载。
-
加载数据直出,这部分需要根据具体业务来分析,部分业务数据是浏览器运行js脚本在本地二次请求加载的,由于低端机以及本地浏览器的能力限制,如果需要加载的数据很多,就很导致js线程的挤占,拖慢整体的时间,因此,可以考虑在服务器将部分数据预先加载好,随http请求一起给浏览器,减少这部分的卡点。
数据直出有利有弊,对于页面的加载性能有正向影响的同时,也会同时导致HTTP的response增大以及服务端RT的升高。数据直出与流式分块传输相结合的效果可能会更好,当服务端分块响应HTTP请求时,本身的response就被切割成多块,单次大小得到了控制,流式分块传输下,服务端分批执行数据准备的策略也能很好的缓冲RT增长的问题。
五、措施四:本地缓存
以我们遇到的一个问题为例,我们的云盘文件列表需要在后端准备好文件所属人的昵称,这是在后端服务器由用户id调用会员的rpc接口实时查询的。分析这个场景,我们不难发现,同一时间,IM场景下的文件所属人往往是其中归属在聊天的几个人名下的,因此,可以利用HashMap作为缓存rpc查询到的会员昵称,避免重复的查询与调用。
六、措施五:下线历史债务
针对有历史包袱的应用,历史债务导致的额外耗时往往很大,这些历史代码可能包括以下几类:
-
未下线的实验或者分流接口调用;
-
-
时间线拉长,这部分的代码残骸在所难免,而且积少成多,累计起来往往有几十上百毫秒的资源浪费,再加上业务开发时,大家往往没有额外资源去评估这部分的很多代码是否可以下线,因此可以借助性能优化的契机进行治理。
-
-
已经废弃的vm变量与重复变量治理。
-
-
对vm变量的盘点过程中发现有很多之前在使用但现在已经废弃的变量。当然,这部分变量的需要前后端同学共同梳理,防止下线线上依旧依赖的变量。
-
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 科普文:后端性能优化的实战小结

发表评论 取消回复