1、非关系型数据库、快、高并发、功能强大
2、为什么快?内存+单线程 非阻塞的IO多路复用+有效的数据类型/结构
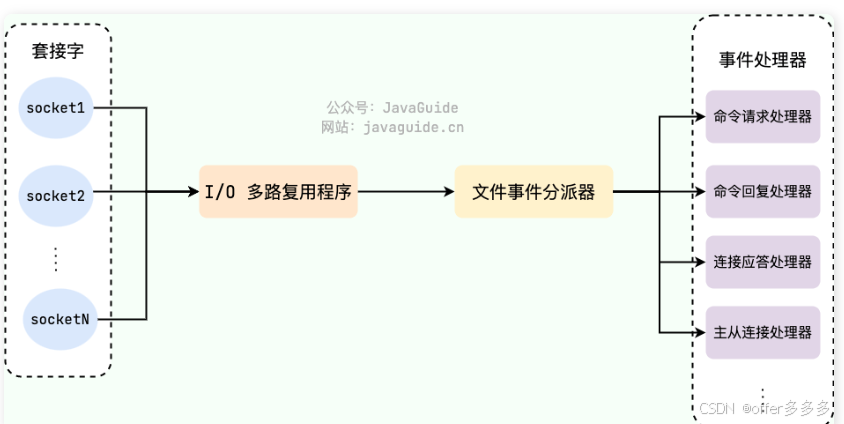
3、应用:支持缓存、支持事务、持久化、发布订阅模型、Lua脚本
4、数据类型:
- 5 种基础数据类型:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
- 3 种特殊数据类型:HyperLogLog(基数统计)、Bitmap (位图)、Geospatial (地理位置)。
string 底层是SDS,简单动态字符串 二进制安全的数据类型 缓存token、图片的base64编码、简单计数
list 双向链表 应用: 信息流展示 最新文章、最新动态

hash hashmap 应用:对象数据存储场景
set hashset 应用:需要存放的数据不能重复的场景,比如点赞数 ;需要获取多个数据源交集、并集和差集的场景,共同好友 ;需要随机获取数据源中的元素的场景 ,如抽奖系统、随机点名
Sorted Set 跳表 增加了一个权重参数 score,使得集合中的元素能够按 score 进行有序排列,还可以通过 score 的范围来获取元素的列表。 应用:需要随机获取数据源中的元素根据某个权重进行排序的场景;
5、redis内存管理:
过期时间 string类型通过setex设置 其他类型通过expire设置
过期时间有利于缓解内存的消耗
删除策略:定期删除:随机抽取若干个设置了过期时间的key,看是否过期
定期删除的频率 HZ 10hz 就是说。每秒钟进行10词尝试来查找并删除过期的key
惰性/懒汉式删除

为了避免key集中过期,在设置键的过期时间时尽量随机一点
内存碎片:Redis 存储数据的时候向操作系统申请的内存空间可能会大于数据实际需要的存储空间。频繁修改 Redis 中的数据也会产生内存碎片。
如何保证redis存的都是热点数据呢?
内存淘汰策略 默认是no-eviction 禁止驱逐数据
6、redis事务
不支持原子性,不支持持久化
改进——lua脚本,确保写入的命令的正确性,就可以保证执行的正常性,否则错误的语句会报错,但是之前已经执行的却不能回滚
7、redis性能优化
- 使用批量操作减少网络传输,即减少RTT,往返时间;减少socket I/O成本 pipline
- 客户端超时阻塞,网络阻塞、工作线程阻塞 可以采用分割bigkey,采用合适的数据结构来处理
- hotkey 处理 hotkey 会占用大量的 CPU 和带宽 如果突然访问 hotkey 的请求超出了 Redis 的处理能力,Redis 就会直接宕机。这种情况下,大量请求将落到后面的数据库上,可能会导致数据库崩溃。 使用 Redis 自带的
--hotkeys参数来查找。 - 解决hotkey 读写分离,使用redis cluster 二级缓存
- 慢查询命令


8、redis生产问题
缓解:Mysql不存在也会返回一个空值 布隆过滤器

- 提前预热(推荐):针对热点数据提前预热,将其存入缓存中并设置合理的过期时间比如秒杀场景下的数据在秒杀结束之前不过期。
- 加锁(看情况):在缓存失效后,通过设置互斥锁确保只有一个请求去查询数据库并更新缓存。
- 设置随机失效时间
- 提前预热(推荐):针对热点数据提前预热,将其存入缓存中并设置合理的过期时间比如秒杀场景下的数据在秒杀结束之前不过期。

如何保证缓存和数据库数据的一致性?
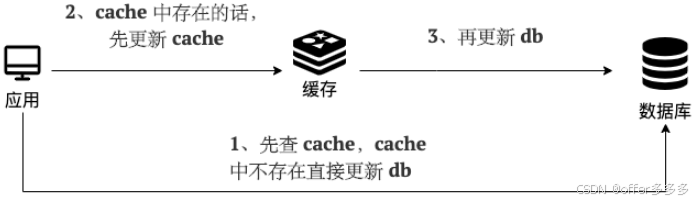
旁路缓存模式:更新数据库,删除缓存。删除缓存失败的话,重试
能否先删除缓存,再更新数据库?数据不一致
读写穿透 :
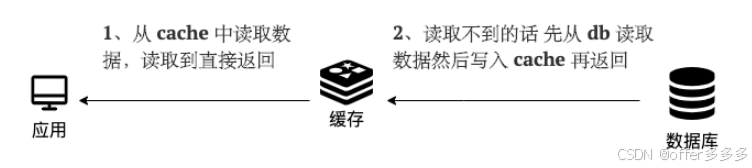
异步缓存写入:Read/Write Through 是同步更新 cache 和 db,而 Write Behind 则是只更新缓存,不直接更新 db,而是改为异步批量的方式来更新 db。
9、redis持久化
RDB持久化:通过创建快照来获得存储在内存里面的数据在 某个时间点 上的副本
bgsave: fork 出一个子进程,子进程执行,不会阻塞 Redis 主线程,默认选项。生成RDB快照文件
AOF持久化:开启 AOF 持久化后每执行一条会更改 Redis 中的数据的命令,Redis 就会将该命令写入到 AOF 缓冲区 server.aof_buf 中,然后再写入到 AOF 文件中(此时还在系统内核缓存区未同步到磁盘),最后再根据持久化方式( fsync策略)的配置来决定何时将系统内核缓存区的数据同步到硬盘中的。
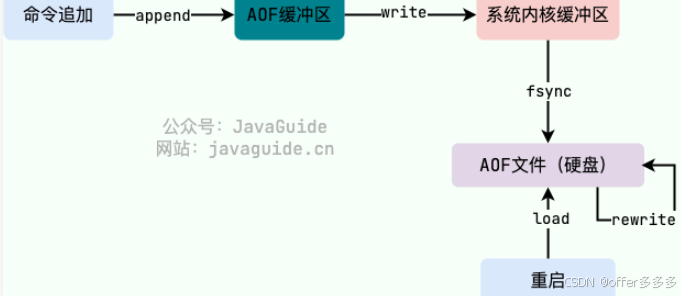
AOF重写 当 AOF 变得太大时,Redis 能够在后台自动重写 AOF 产生一个新的 AOF 文件,这个新的 AOF 文件和原有的 AOF 文件所保存的数据库状态一样,但体积更小。
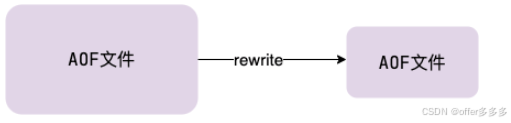
AOF校验机制:Redis 在启动时对 AOF 文件进行检查,以判断文件是否完整,是否有损坏或者丢失的数据。 校验和
- Redis 保存的数据丢失一些也没什么影响的话,可以选择使用 RDB。
- 不建议单独使用 AOF,因为时不时地创建一个 RDB 快照可以进行数据库备份、更快的重启以及解决 AOF 引擎错误。
- 如果保存的数据要求安全性比较高的话,建议同时开启 RDB 和 AOF 持久化或者开启 RDB 和 AOF 混合持久化
10、redis延时
- redis过期时间监听 当一个key过期之后,rendis发布一个key过期的事件到某个channel中 但是过期时间消息是在redis服务器删除key时发布的,而不是一个key过期之后就会直接发布;还可能会丢了消息;多服务实例下消息重复消费
- redisson内置的延时队列 Redisson 使用
zrangebyscore命令扫描 SortedSet 中过期的元素,然后将这些过期元素从 SortedSet 中移除,并将它们加入到就绪消息列表中。就绪消息列表是一个阻塞队列,有消息进入就会被监听到。这样做可以避免对整个 SortedSet 进行轮询,提高了执行效率
11、redis为什么要用分布式缓存
缓存服务可以部署在一台单独的服务器,即使同一个相同的服务部署在多台机器上,也是使用的同一份缓存。 并且,单独的分布式缓存服务的性能、容量和提供的功能都要更加强大。
12、Redis Sentinel:
- 实现 Redis 集群高可用,只是在主从复制实现集群的基础下,多了一个 Sentinel 角色来帮助我们监控 Redis 节点的运行状态并自动实现故障转移
- 监控,故障转移即把一台slave升级为master ;通知,即通知slave新的master连接信息,配置提供,即通知新的master连接信息给客户端
- 那么senstial是如何判断节点是否下线呢?
每秒对集群进行ping
主观:自己认为 客观:过半都认为
- 如何选择出新的master
在线的slave,根据slave的优先级,再根据复制进度,如若还是选不出来,就选用运行id小的slave
13、redis cluster
可以横向扩展缓解写压力和存储压力,支持动态扩容和缩容
具备主从复制、故障转移,senstiel集群等开箱即用的功能
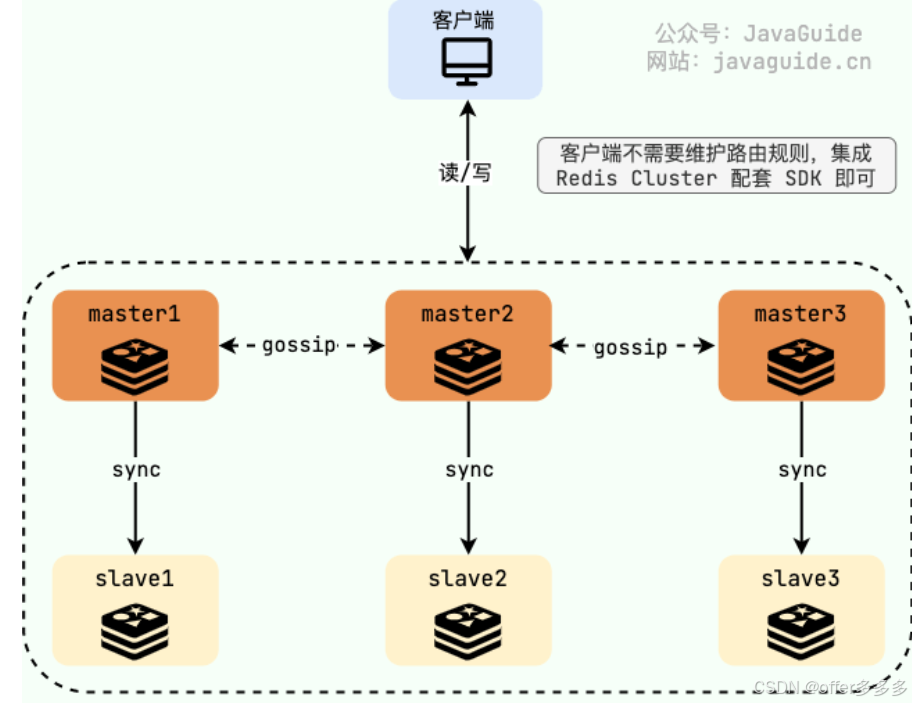
slave不对外提供读的接口,是为了保证redis cluster的高可用
redis cluster中有master出现故障,不会对其他master产生影响
redis cluster 是通过哈希槽进行分配的 解耦了数据和节点之间的关系,提升了集群的横向扩展性和容错性
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Java开发之Redis

发表评论 取消回复