我是买了一本书自己看书去学python的,然后学到了一个章节就是讲的用python去某网络小说网址爬取小说保存到本地,结果我看的这本书比较古老,它举例的这个被爬取的网站已经不存在了,所以,我另外找了一个网站,比着摸索着打代码,中间出现过好多不理解的地方,还有好多地方走了弯路,在此重新整理一下这个代码,尽量说详细一些,给后来的学习者们提供一点灵感吧。
一、要实现的效果
就是我们现在在某网络小说网站看到了一篇长篇小说——《渣男文里的攻略女》,它好多个章节,我想要把这部小说里所有的章节内容保存到本地电脑,每个章节保存成一个txt文件。
网页分析,这个小说页包含一个总的目录页,还有各个章节的具体内容页。
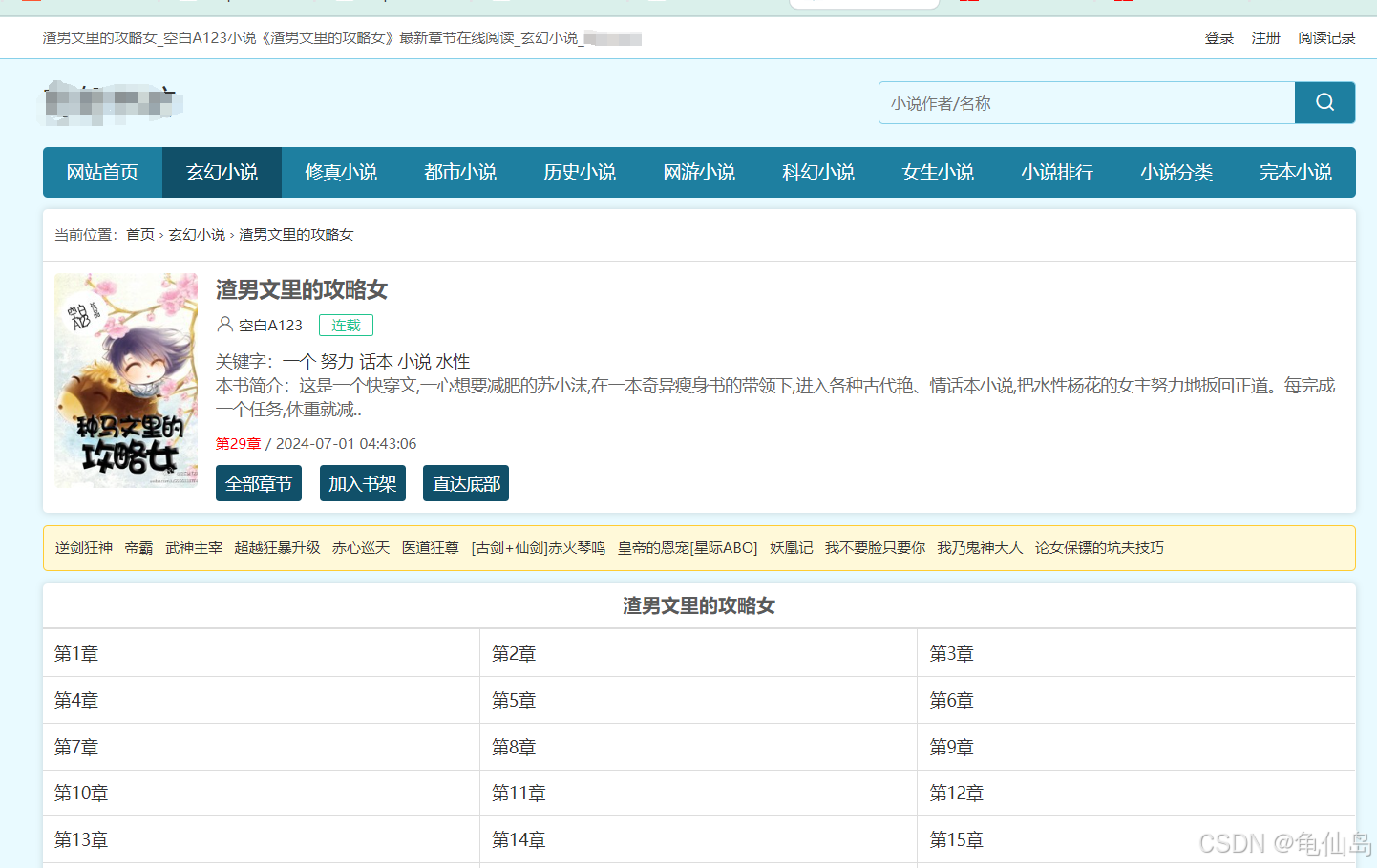
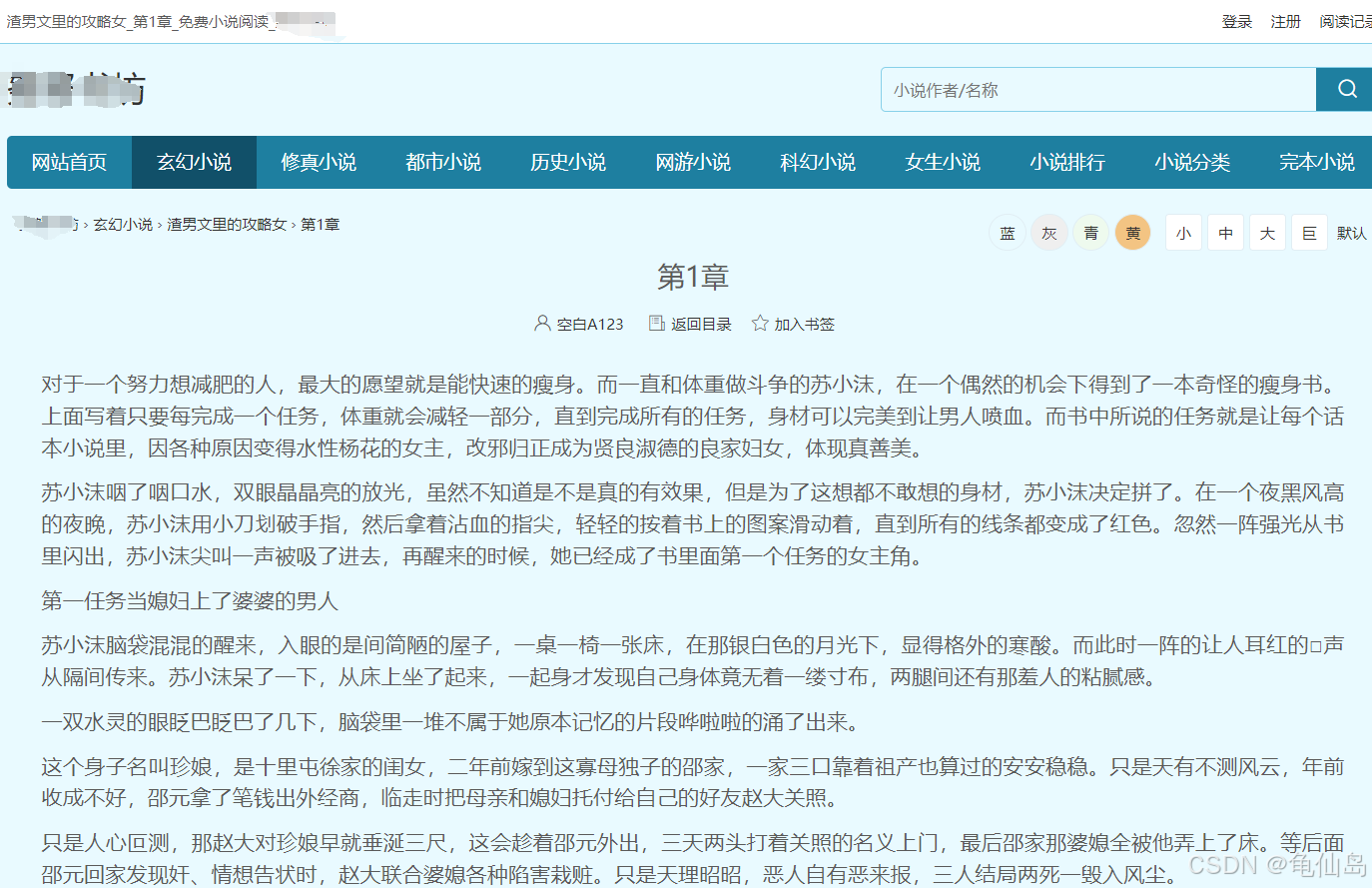
二、爬取思路分析
1、涉及的知识点如下。
(1
)使用
requests获取网页源代码。
(
2)使用正则表达式获取内容。
(
3)文件操作,在本地新建文件夹,新建txt文件,写入内容。
上面三个知识点不熟悉的先百度一下吧。
2、代码设计思路
- 导入用到的模块,
- 从网站的目录页的源代码里通过正则表达式爬取所有章节的链接保存到列表
- 从具体的章节内容页爬取章节名和每一章节的具体内容
- 在本地新建一个文件夹,用章节名命名txt文件,写入爬取到的具体内容
3、写代码
1、第一段代码,先把用到的库导入进来,用到以下四个库,其中requests是需要另外安装的,其它三个是python自带的。
import re
import requests
impor本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 用python去爬取小说网址的小说保存到本地全过程

发表评论 取消回复