题目链接:**. - 力扣(LeetCode)**
题目描述:
给定两个字符串 s 和 p,找到 s 中所有 p 的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。
异位词 指由相同字母重排列形成的字符串(包括相同的字符串)。
示例 1:
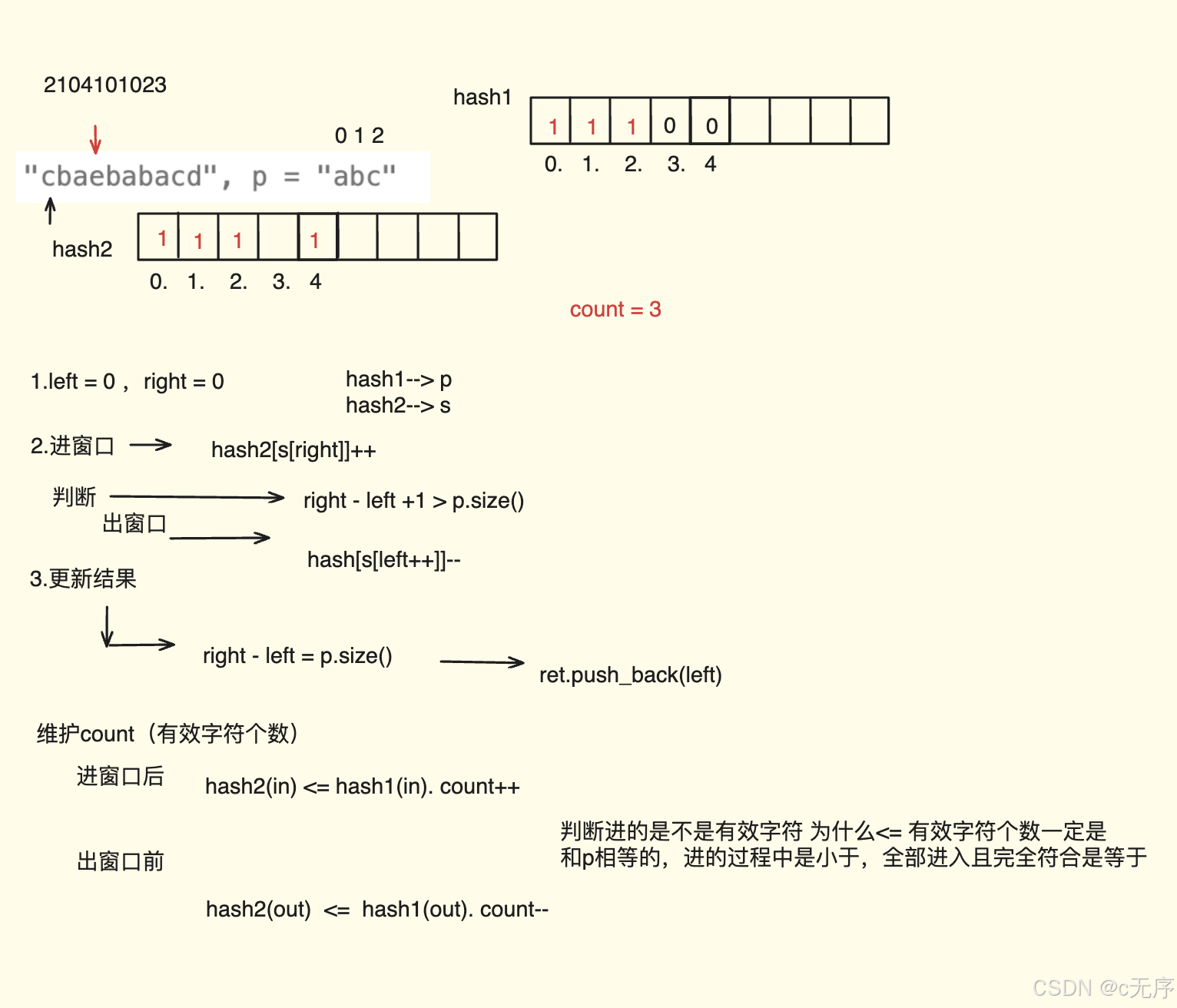
输入: s = "cbaebabacd", p = "abc" 输出: [0,6] 解释: 起始索引等于 0 的子串是 "cba", 它是 "abc" 的异位词。 起始索引等于 6 的子串是 "bac", 它是 "abc" 的异位词。
示例 2:
输入: s = "abab", p = "ab" 输出: [0,1,2] 解释: 起始索引等于 0 的子串是 "ab", 它是 "ab" 的异位词。 起始索引等于 1 的子串是 "ba", 它是 "ab" 的异位词。 起始索引等于 2 的子串是 "ab", 它是 "ab" 的异位词。
提示:
-
1 <= s.length, p.length <= 3 * 104 -
s和p仅包含小写字母
解法(滑动窗口+哈希表):
算法思路:
-
因为字符串
p的异位词的长度一定与字符串p的长度相同,所以我们可以在字符串s中构造一个长度为与字符串p的长度相同的滑动窗口,并在滑动中维护窗口中每种字母的数量; -
当窗口中每种字母的数量与字符串
p中每种字母的数量相同时,则说明当前窗口为字符串p的异位词; -
因此可以用大小为
26的数组来模拟哈希表,一个来保存s中的子串每个字符出现的个数,另一个来保存p中每一个字符出现的个数。这样就能判断两个串是否是异位词。 -
class Solution { public: vector<int> findAnagrams(string s, string p) { vector<int> ret;//存储满足条件的结果 int hash1[26] = {0};//存储p int hash2[26] = {0};//存储s for(auto ch : p) hash1[ch - 'a']++; int m = p.size(); int count = 0; for(int left = 0,right = 0; right < s.size(); right++){ //进窗口 char in = s[right]; //维护count if(++hash2[in - 'a'] <= hash1[in - 'a']) count++; //判断 if(right - left + 1 > m){ char out = s[left++]; //出窗口+维护count if(hash2[out - 'a']-- <= hash1[out - 'a']) count--; } //更新结果 if(count == m) ret.push_back(left); } return ret; } };
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 滑动窗口练习6-找到字符串中所有字母异位词

发表评论 取消回复