从今天起,我们不再单独介绍推荐算法的原理,而是开始进入一个新的模块-工程篇。
在工程实践的部分中,我首先介绍的内容是当今最热门的信息流架构。
信息流是推荐系统应用中的热门,它表现形式有很多:社交网络的动态信息流、新闻阅读的图文信息流、短视频信息流等等。
如果要搭建一个自己的信息流系统,它应该怎么样呢?今天,我就来带你一探信息流架构的究竟。
整体框架
信息流,通常也叫做feed,这个英文也很有意思,就是喂给用户的意思。
传统的信息流产品,知识简单按照时间排序,而被推荐系统接管后的信息流逐渐成为主流,按照兴趣排序,也叫作“兴趣feed” 。
所以我们通常提到信息流,或者兴趣feed,其实都是在说同一个话题。搜索 fedd相关的技术文章,应该用Activity Stream作为关键词去搜。
要实现一个信息流,整体逻辑上是比较清楚的。可以划分为两个子问题。
1.如何实现一个按照时间顺序排序的信息流体系?
2.如何给信息流内容按照兴趣重排序?
我这里先给出一个整体的框架,然后再分别详谈。
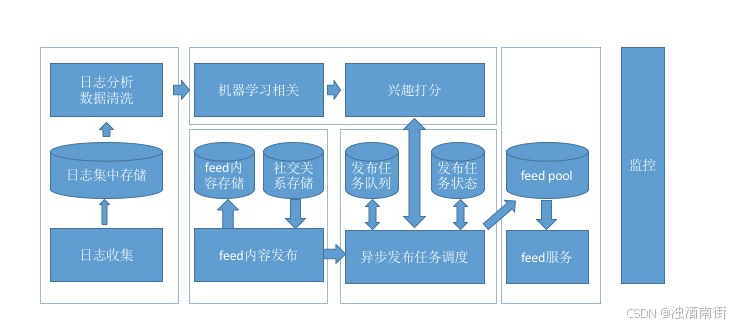
这张架构图划分为几个大的模块:日志收集、内容发布、机器学习、信息流服务、监控。这里分别介绍一下:
1.日志收集,是所有排序训练的数据来源,要收集的最核心数据就是用户在信息流上产生的行为,用于机器学习更新排序模型;
2.内容发布,就是用推或拉的模式把信息流的内容从源头发布到受众端;
3.机器学习,从收集到用户行为日志中训练模型,然后为每一个用户即将收到的信息流内容提供打分服务;
4.信息流服务,为信息流的展示前端提供Rest API;
5.监控,这是系统的运维标准,保证系统的安全和稳定等;
数据模型
信息流的基本数据有三个:用户(User)、内容(Activity)和关系(Connection)
用户自不用说,即不同用户的身份ID,我来说一说其他两种。
1.内容即Activity
用于表达Activity的元素有相应的规范,叫作Atom,根据Atom的定义,一条Activity包含的元素有:Time,Actor,Verb,Object,Target,Title,Summary;下面详细解释一下这些元素。
1.Time :即Activity发生的时间
2.Actor:即Activity由谁发出的。通常Actor就是用户id,也可以拓展到拟人化的物体上,如关注的一个店铺,收藏的一部电影,或者用户喜欢的一个标签或者分类。
3.Verb:动词,就是连接的名字,比如“follow”“like”等,也可以是隐含的连接,如挖掘出的用户兴趣词和用户之间的这种潜规则。
4.Object:即动作作用到最主要的对象,只能有一个,比如一个人赞过一张照片,店铺上新了一件商品,一个分类下一篇新的文章。
5.Target:动作的最终目标,与verb有关,可能没有。它对应英语中介词to后接的事物,比如“john saved a movie to his wishlist”(john保存了一部电影到清单里),
这里电影就是object,而清单就是target.
6.Title ;这个是Activity的标题,用自然语言描述,用于展示给用户。
7.Summary:通常是一小段HTML代码,是对这个Activity的描述,还可能包含类似缩略图这样的可视化元素,可以理解为Activity的视图,不是必须的。
除了上面的字段外,还有一个隐藏的id,用于唯一标识一个Activity。社交电商Etsy在介绍他们的信息流系统时,还创造性地给Activity增加了Owner属性,
同一个Activity可以属于不同的用户,相当于考虑了方向。
2.关系即连接
互联网产品里处处有连接,有强有弱,好友关系、关注关系等社交是较强的连接,还有点赞、收藏,评论,浏览这些动作都可以认为是用户和另一对象之间建立了连接。有了连接,就有信息流的传递和发布。
定义一个连接的元素有下面几种:
1.From:连接的发起方
2.To:被连接方
3.Type/Name:就是Atom模型中的verb,即连接的类型:关注、加好友,点赞、浏览、评论等等
4.Affinity:连接的强弱。
如果把建立一个连接视为一个Activity的话,From就对应Activity中的Actor,To就对应Activity中的Object。
Connection和Activity是相互加强的,有了Activity,就会产生Connnection,有了connection,就可以喂(feed)给你更多的Activity.
在数据存储上可以选择的工具有下面的几种:
1.Activity存储可以采用Mysql、Redis、Cassandra等;
2.connection存储可以采用Mysql;
3.User存储可以采用Mysql;
动态发布
用户登录或者刷新后,信息流是怎么产生的呢?我们把动态内容出现在受众的信息流中这个过程称为Fan-out,直觉上是这样实现的:
1.获取用户所有的连接的终点(如好友、关注对象、兴趣标签);
2.获取这些连接终点(关注对象)产生的新内容(Activity);
3.按照某个指标排序后输出。
上面这个步骤别看简单,在一个小型的社交网络上,通常很有效,而且Twitter早期也是这么做的。这就是江湖行话说的“拉”模式(Fan-out-on-load),即:信息流是在用户登录或者刷新后实时产生的。
这里有一个示意图:
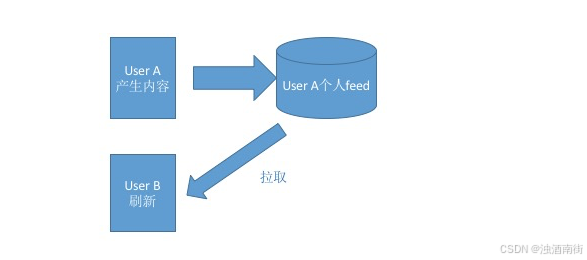
拉模式就是当用户访问时,信息流服务才会去相应的发布源拉取内容到自己的feed区来,这是一个阻塞同步的过程。“拉”模式的好处也显而易见,主要有下面两种:
1.实现简单直接
2.实时:内容产生了,受众只要刷新就能看见。
不足:
1.随着连接数的增加,这个操作的复杂度指数级增加;
2.内容中要保留每个人产生的内容
3.服务很难做到高可用。
与拉模式相应,还有一个推模式(Fan -out-on-write).如下图:
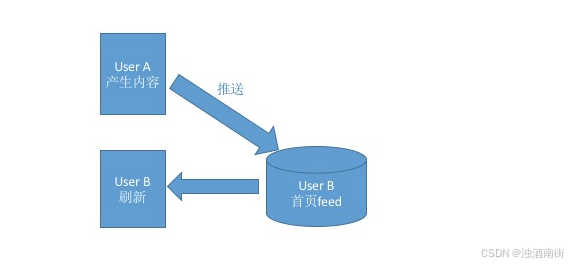
当一个Actor产生了一条Activity后,不管受众在不在线,刷没刷新,都会立即将这条内容推送给相应的用户(即和这个Actor建立了连接的人),系统为每一个用户单独开辟一个信息流存储区域,用于接收 推送的内容。如此一来,当用户登录后,系统只需读取他自己的信息流即可。
推的模式好处显而易见:在用户访问自己的信息流时,几乎没有任何复杂的查询操作,所以服务可用性较高。
不足:
1.大量的写操作:每一个粉丝都要写一次。
2.大量冗余存储:每一条内容都要存储N份(受众数量)。
3.非实时:一条内容产生后,有一定的延迟才会到达受众信息流中。
4.无法解决新用户的信息流产生问题。
既然两者各有优劣,那么实际上就应该将两者结合起来,一种简单的结合方案是全局的:
1.对于活跃度高的用户,使用推模式,每次他们刷新时不用等待太久,而且内容页相对多一些;
2.对于活跃度没那么高的用户,使用拉模式,当他们登录是才拉取最近的内容;
3.对于热门的内容产生者,缓存其最新的N条内容,用于不同场景下的拉取。
还有一种结合方案是分用户的,这是Etsy的设计方案:
1.如果受众用户和内容产生用户之间的亲密度高,则优先推送,因为更可能被这个受众所感兴趣;
2.如果受众用户与内容产生用户之间的亲密度低,则推迟推送或者不推送;
3.也不是完全遵循亲密度顺序,而是采用与之相关的概率。
在中小型的社交网络上,小样纯推模式就够用了,结合的方案可以等业务发展到一定规模后再考虑。
对于信息流的产生和存储可以选择的工具有:
1.用户信息流的存储可以采用Redis等KV数据库,使用uid作为key
2.信息流推送的任务队列可以采用Celery等成熟架构。
信息流排序
信息流排序要避免两个误区:1.没有目标;2.人工量化
第一个误区“没有目标”意思是说,设计排序算法之前,一定要弄清楚为什么要对时间序列重排?希望达到什么目标?只有先确定目标,才能检验和优化算法。
第二个误区是“人工量化”,也就是我们常见到的产品同学或者运营同学要求对某个因素加权或者降权。这样做很不明智,主要是不能很好地持续优化。
目前信息流采用机器学习排序,以提升类似互动率,停留时长等指标,这已经成为共识。比如说提高互动率则需要下面几个内容。
1.首先,定义好互动行为包括哪些,比如点赞。转发。评论。查看详情等;
2.其次,区分好正向互动和负向互动,比如隐藏某条内容、点击不感兴趣等是负向的互动。
基本上到这里可以设计成一个典型的二分类监督学习问题了,对一条信息流的内容,在展示给用户之前,预测其获得用户正向互动的概率,概率就可以作为兴趣排序分数输出。
能产生概率输出的二分类算法有贝叶斯,最大熵,逻辑回归等。互联网常用的是逻辑回归(Logistic Regression),也有Facebook等大厂采用了逻辑回归加梯度提升树模型(又称GBDT)来对
信息流排序,效果显著。
如今很多大厂已经转向深度学习了,但我还是建议小厂或者刚起步的信息流线采用线性模型。
对于线性模型,一个重要的工作就是特征工程。信息流的特征有三类;
1.用户特征,包括用户人口统计学属性,用户兴趣标签、活跃程度等;
2.内容特征,一条内容本身可以根据其属性提取文本、图像、音频等特征,并且可以利用主题模型提取更抽象的特征。
3.其他特征,比如刷新时间,所处页面等。
排序模型在实际使用时,通常做成RPC服务,以供发布信息流时调用。
数据管道
信息流是一个数据驱动的系统,既要通过历史数据来寻找算法的最优参数,又要通过新的数据验证排序效果,所以搭建一个数据流管道就是大家翘首期盼的。
这个管道中要使用的相关数据可能有:
1.互动行为数据,用于记录每一个用户在信息流上的反馈行为;
2.曝光内容,每一条曝光要有唯一的ID,曝光的内容仅记录ID即可;
3.互动行为与曝光的映射关系,每条互动数据要对应到一条曝光数据;
4.用户画像内容,即用户画像,提供用户特征
5.信息流的内容分析数据,提供内容特征,即物品画像。
对于一个从零开始的信息流,没必要做到在线实时更新排序算法的参数,所以数据的管道可以分为三块:
1.生成训练模型,可离线
2.排序模型训练,可离线;
3.模型服务化,实时服务;
在离线训练优化模型时,关注模型的AUC是否有提升,线上AB测试时关注具体的产品目标是否有提升,比如互动率等,同时还要根据产品具体形态关注一些辅助指标。
另外,互动数据相比全部曝光数据,数据量会小得多,所以在生成训练数据时需要对负样本进行采样,采样比例也是一个可以优化的参数。
固定算法和特征后,在0.1-0.9之间遍历对比实验,选择最佳的正负比例即可。经验比例在2:3左右,即负样本略大于正样本。
总结
今天我逐一梳理了实现一个通用信息流的关键模块,及其已有的轮子,从而能最大限度地降低开发成本。这些对于一个中小型的社交网路来说已经足够,当你面临更大的社交网络,会有更多复杂的情况出现,尤其是系统上的,请时刻观察系统的监控、日志的规模。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 推荐系统三十六式学习笔记:工程篇.常见架构24|典型的信息流架构是什么样的

发表评论 取消回复