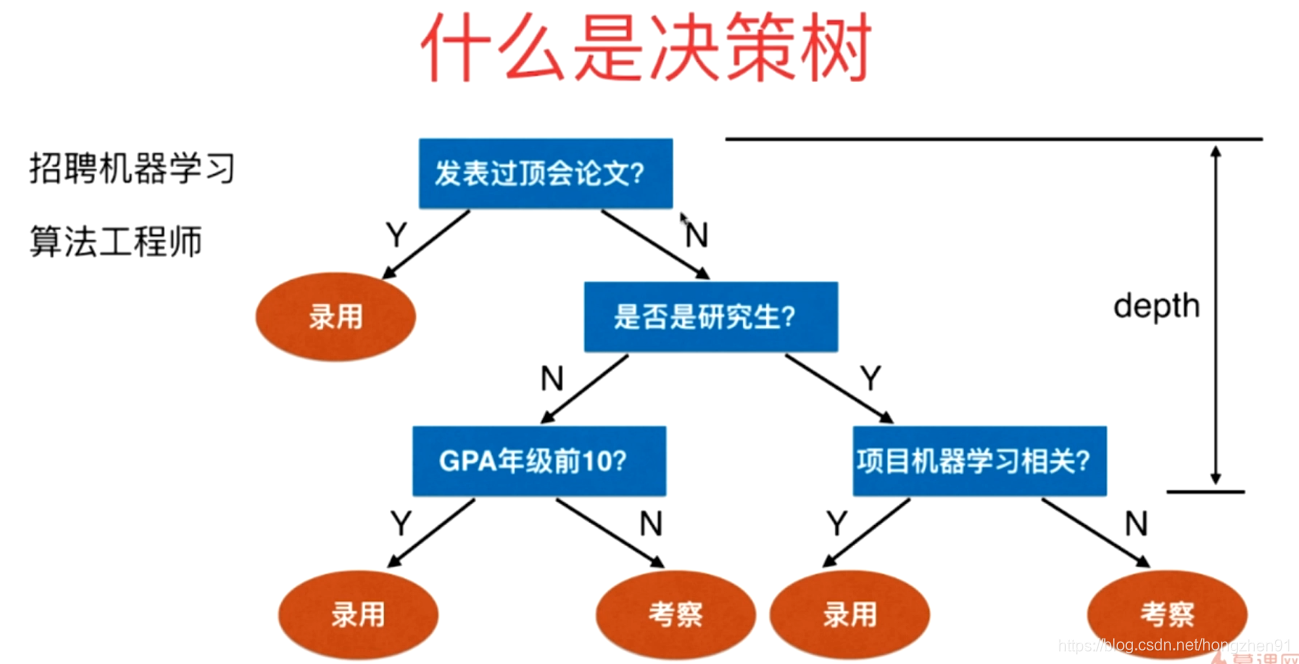
决策树是非参数学习算法,可以解决分类问题,天然可以解决多分类问题(不同于逻辑回归或者SVM,需要通过OVR,OVO的方法),也可以解决回归问题,甚至是多输出任务,并且决策树有非常好的可解释性。决策树功能强大,能够拟合复杂的数据集。
在线dot转换png
https://onlineconvertfree.com/zh/

对于二分类:
H
=
−
p
⋅
l
o
g
(
p
)
−
(
1
−
p
)
⋅
l
o
g
(
1
−
p
)
H = -p \cdot log(p) - (1-p) \cdot log(1-p)
H=−p⋅log(p)−(1−p)⋅log(1−p)
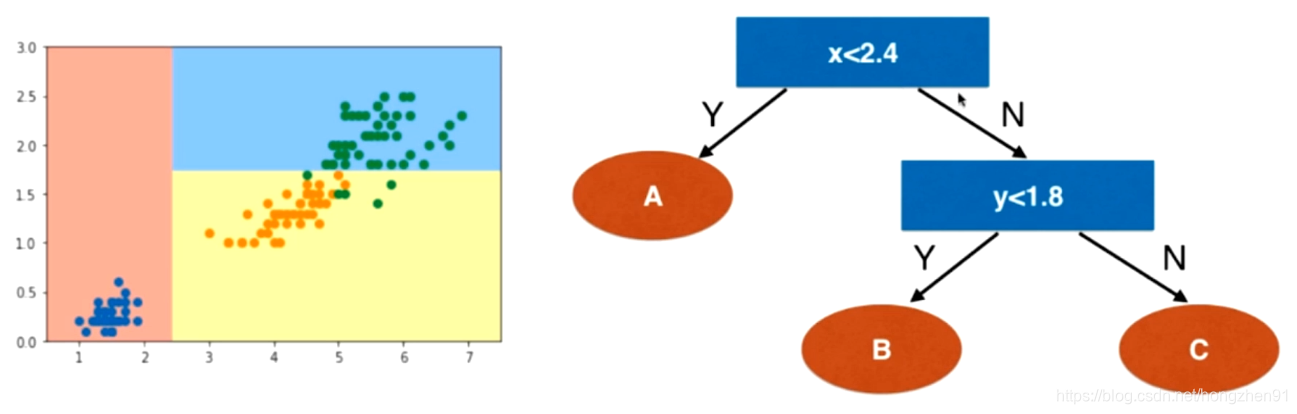
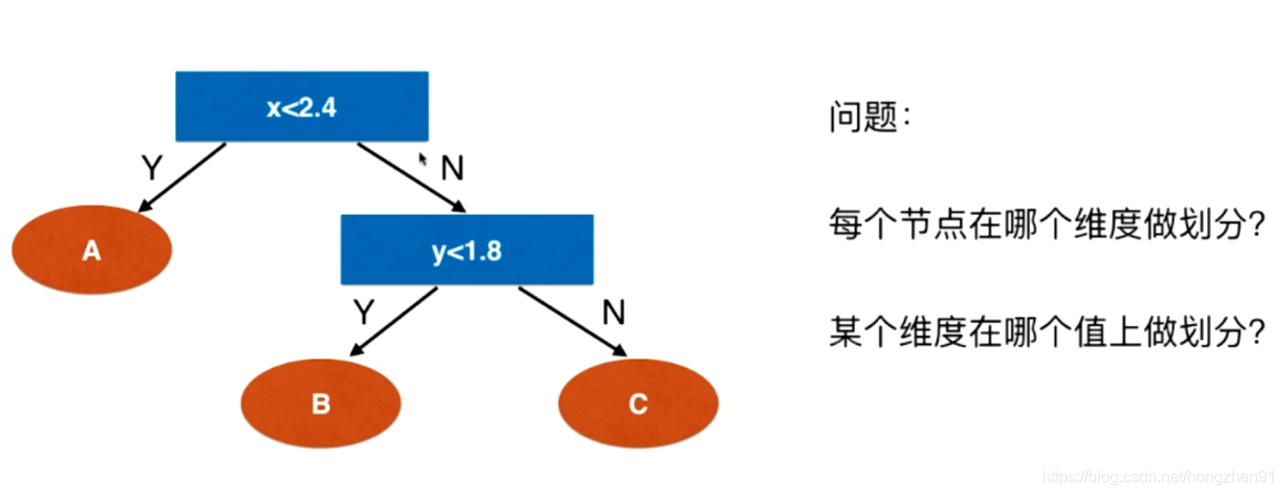
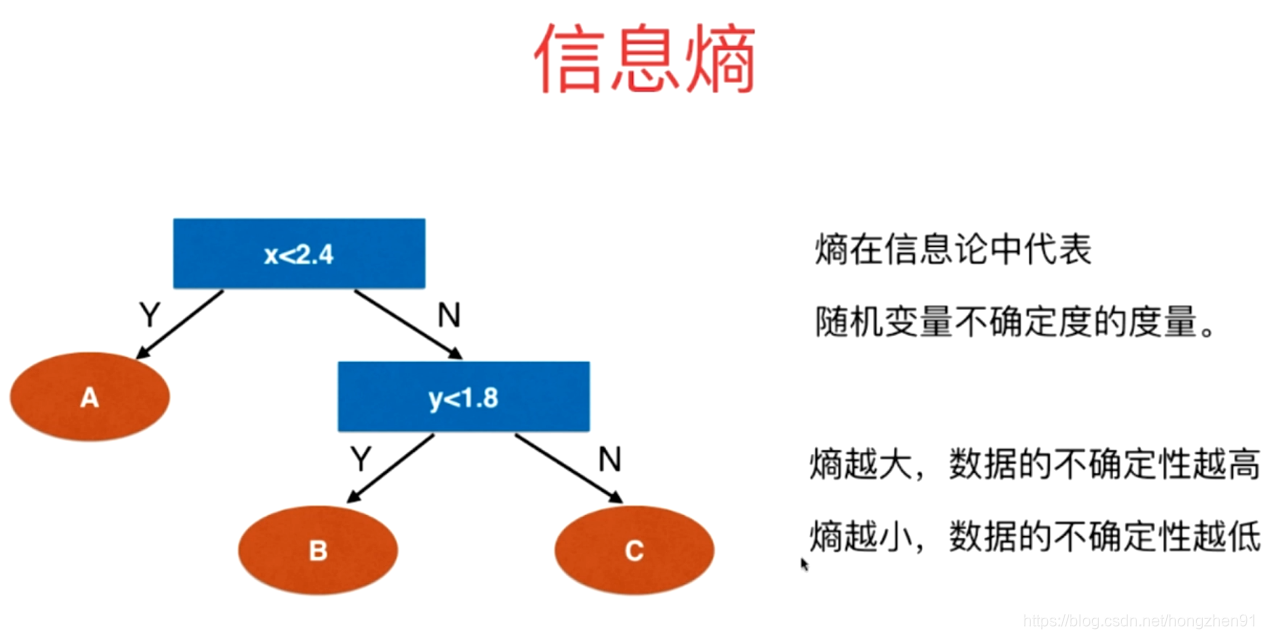
通过信息熵可以看到当前数据的不确定度。对于决策树,在根节点上要找到一个维度和一个阈值,对根节点进行划分,划分之后希望整体信息熵减小,进而对于划分出来的两个子节点重复递归划分的方法,逐步减小整体的信息熵。
对于二分类:
G
=
1
−
p
2
−
(
1
−
p
)
2
=
1
−
p
2
−
1
+
2
p
−
p
2
=
−
2
p
2
+
2
p
\begin{aligned} G &= 1 - p^2 - (1-p)^2 \\ &= 1 - p^2 -1 + 2p - p^2 \\ &= -2p^2 + 2p \end{aligned}
G=1−p2−(1−p)2=1−p2−1+2p−p2=−2p2+2p




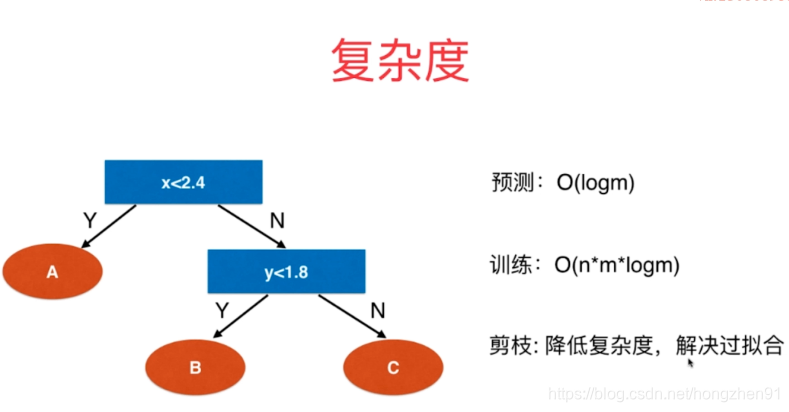
每次都是对半划分,决策树高度:logm
维度:n,样本:m ,遍历:n*m

如使用 CART 的方式,在每个叶子节点都包含若干个数据,如果这些数据的输出值是类别的话,则可以在叶子结点中让数据进行投票,归为多的一类的数据的类别。
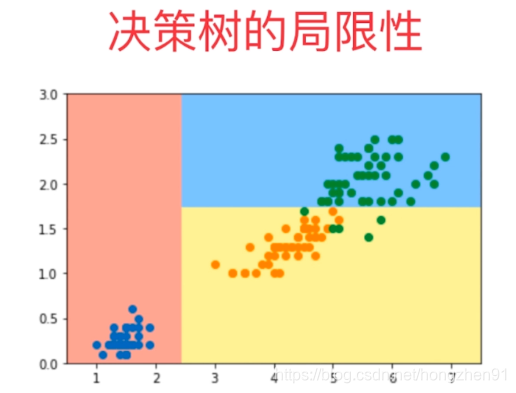
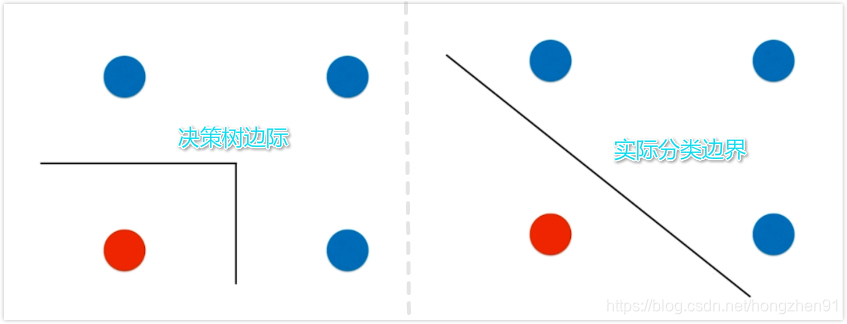
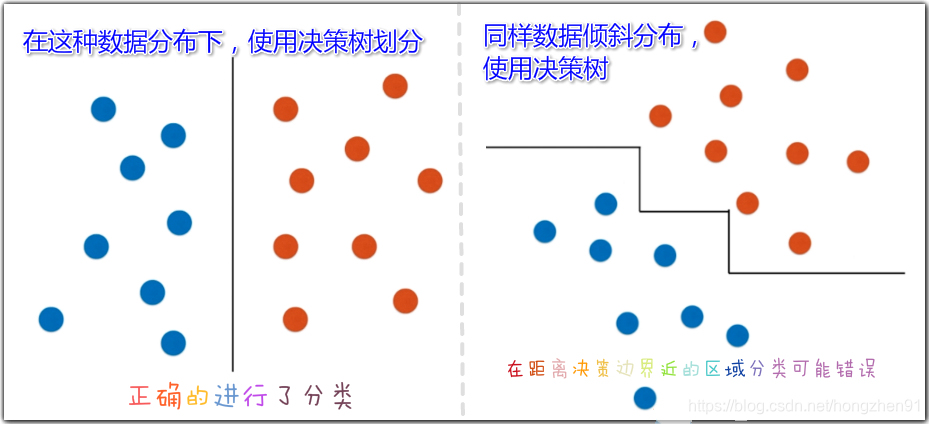
决策树的局限性
1、
2、
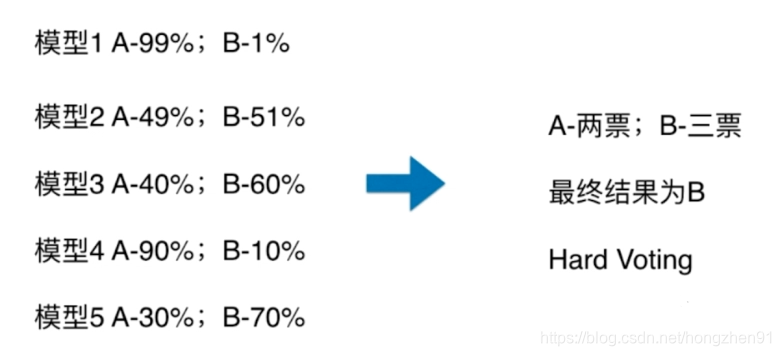
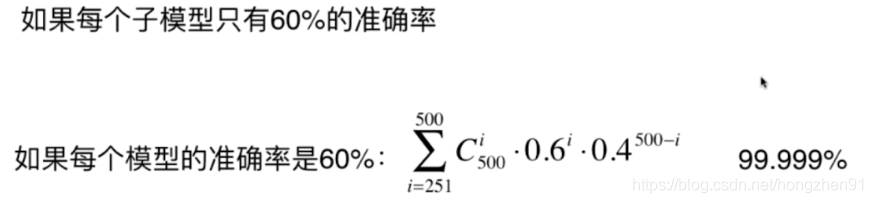
集成学习

虽然分为 A 类只有两票,但是认为是 A 类的概率非常高,而分为 B 类的票数虽然是三票,都是得到的确定性都不太大。


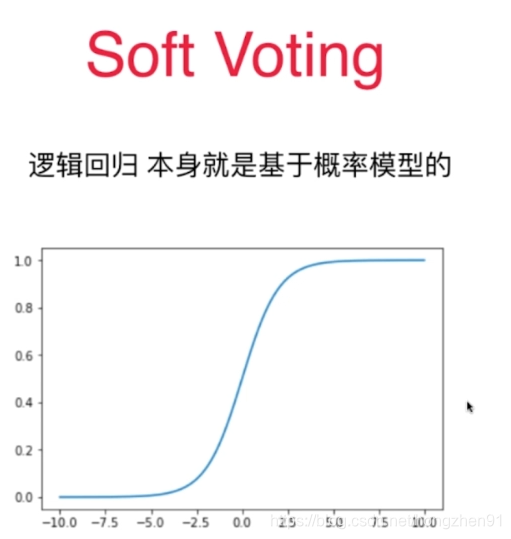
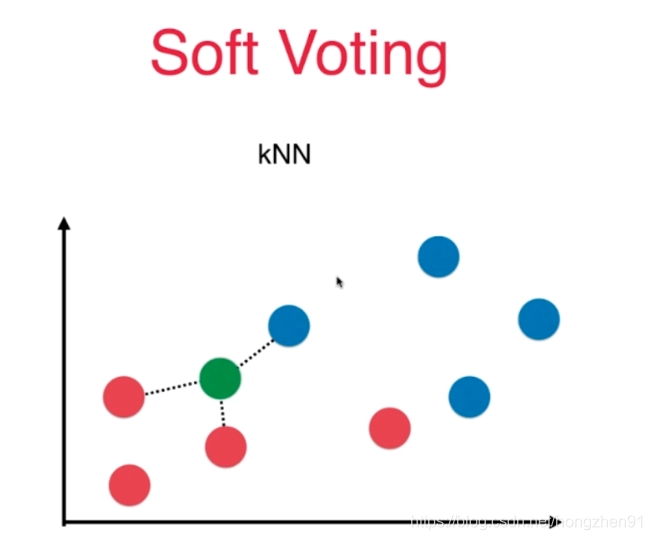
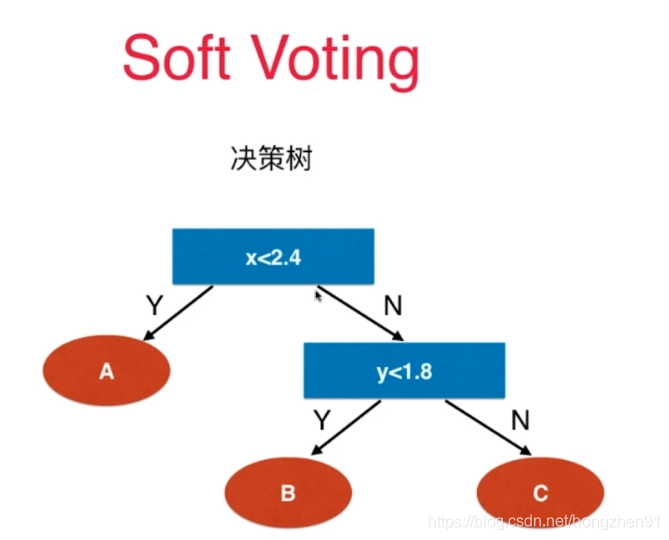

每个子模型可以用同一个算法,这样子模型之间的数据不同,是存在有一定的差异性。





和集成学习的不同,不需要使用多种算法,使用一种算法就可以创建差异性
Bagging:使用随机取样的方式,包括在特征空间中随机取特征,创建诸多的子模型,把它们集成在一起。



通过 n_jobs 参数控制并行运行的核数



在Bagging中,使用的集成学习的方式(基础分类器)是决策树,集成了很多决策树的集成学习,由于采用了随机取样的方式,具有随机性,所以叫做随机森林。

Extra-Trees:极其随机的随机森林,极其随机的特性表现在决策树节点的划分上。



本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 决策树 和 集成学习、随机森林

发表评论 取消回复