首先,来看一下Transformer架构图:
我们知道,Bert设计时主要采用的是Transformer编码器部分,要论述Bert为啥是双向的,我想从编码器和解码器的注意力机制来阐述。
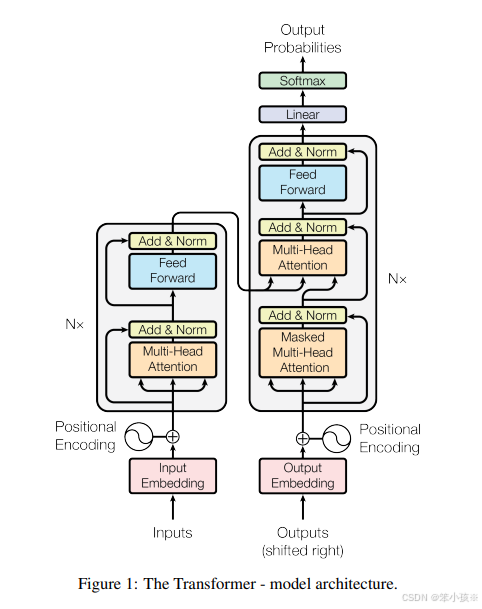
在看这篇博客前,需要对Transformer有一定的了解,在这里推荐博客翻译: 详细图解Transformer
我们知道,编码器部分的注意力机制采用多头注意力机制,而为什么要用MultiHead Attention,Transformer给出的解释为:Multi-head attention允许模型共同关注来自不同位置的不同表示子空间的信息;
而解码器部分采用的是Masked Attention,mask的目的是为了防止网络看到不该看到的内容。
二者区别一个是双向,一个是单向,这也就是我如何理解的Bert采用的是双向编码器了。
关于MultiHead Attention和Masked Attention机制,这篇博客及其推荐:MultiHead-Attention和Masked-Attention的机制和原理
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【NLP自然语言处理】为什么说BERT是bidirectional

发表评论 取消回复