LivePortrait 本地部署教程,强大且开源的可控人像AI视频生成
1,准备工作,本地下载代码并准备环境,运行命令前需安装git
以下操作不要安装在C盘和容量较小的硬盘,可以找个大点的硬盘装哟
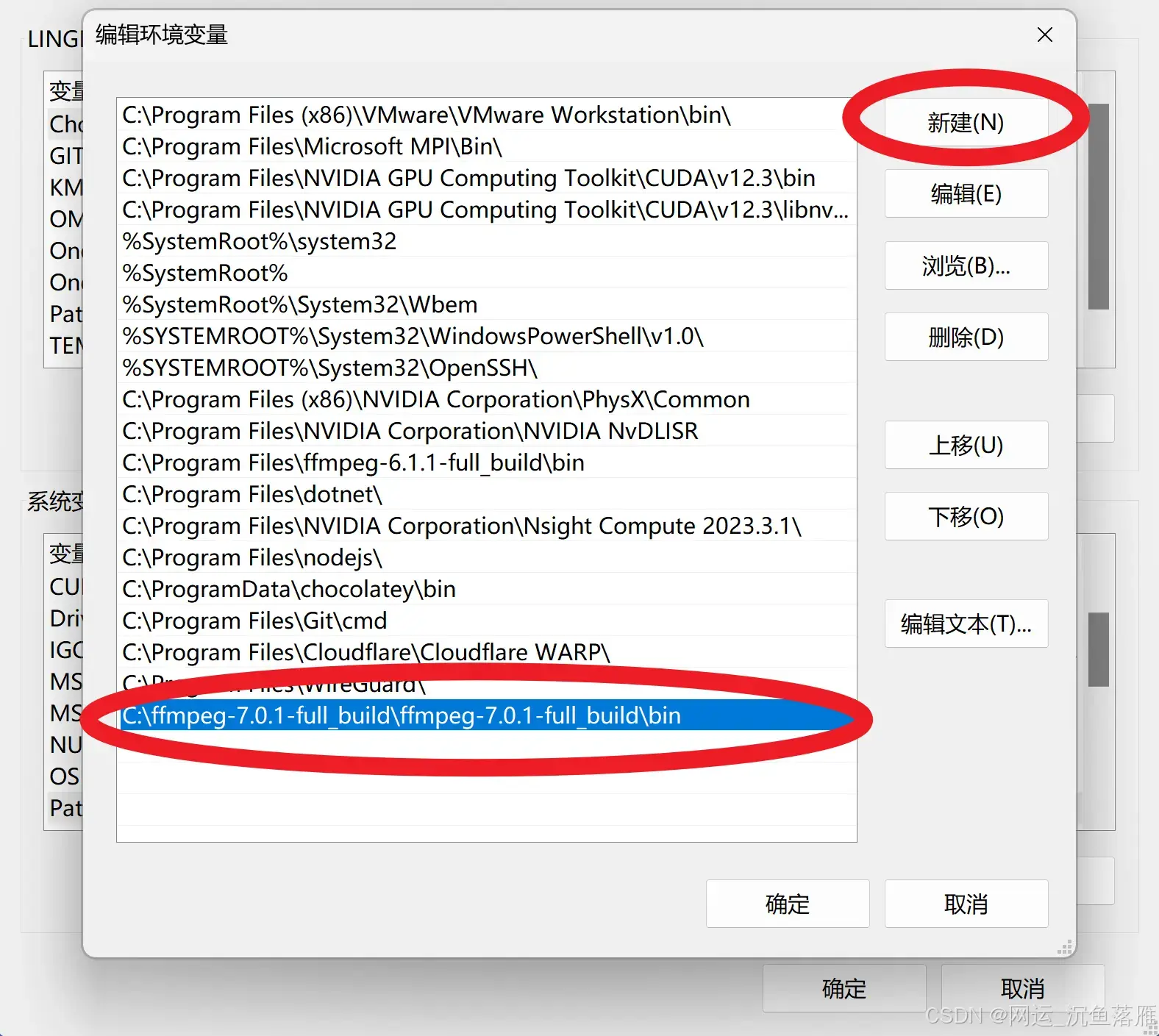
2,需要安装FFmpeg

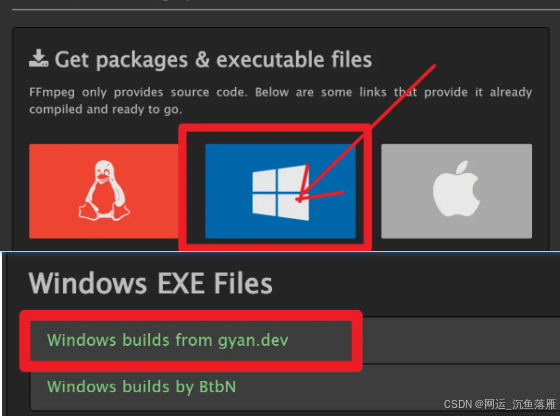
进去以后,选择左边的 release builds ,右边出现如下内容
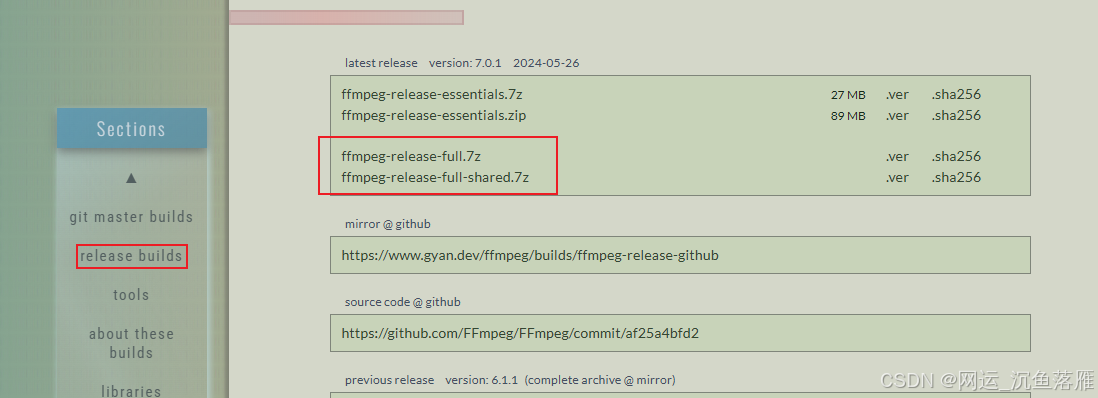
选择带 shared 的还是不带 shared 的版本,其实都是可以的。功能是完全一样的。
只不过带 shared 的里面,多了 include、lib 目录。把 FFmpeg 依赖的模块包单独的放在的 lib 目录中。ffmpeg.exe,ffplay.exe,ffprobe.exe 作为可执行文件的入口,文件体积很小,他们在运行的时候,如果需要,会到 lib 中调用相应的功能。
不带 shared 的里面,bin 目录中有 ffmpeg.exe,ffplay.exe,ffprobe.exe 三个可执行文件,每个 exe 的体积都稍大一点,因为它已经把相关的需要用的模块包编译到exe里面去了。
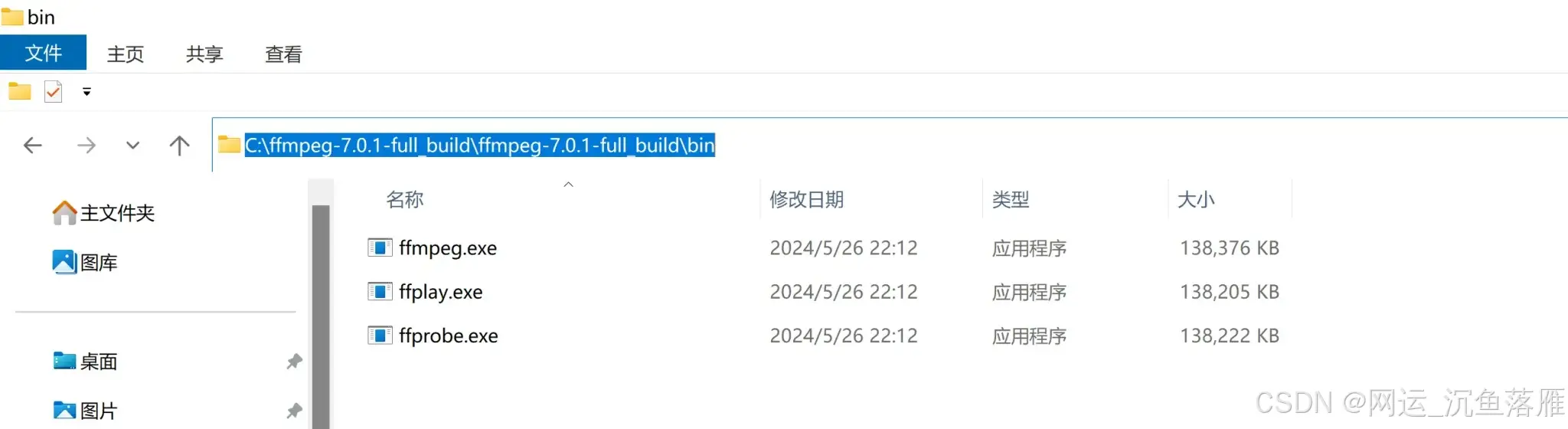
验证是否安装成功
在CMD命令终端下,输入: ffmpeg -version,有类似如下版本信息输出,就说明配置成功了!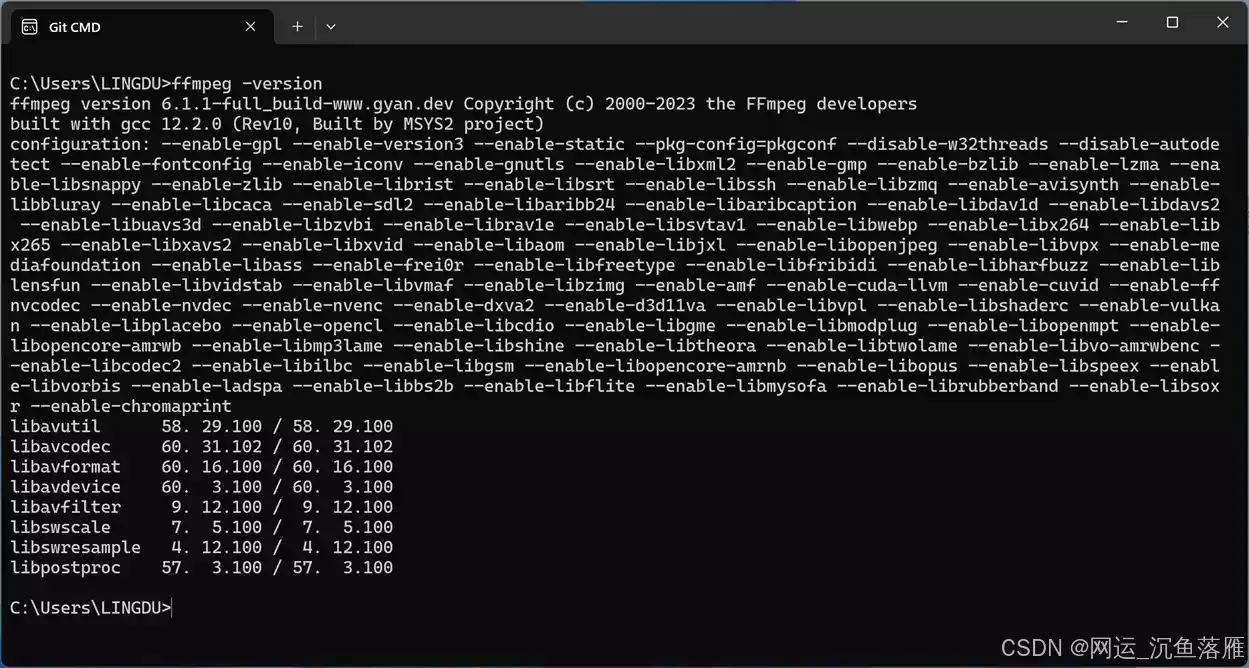
3,LivePortrait 本地安装
WIN+R---CMD全部复制粘贴下面两行自动下载(这里要关闭机场,可能不成功,这个加载成功后再开启稳定的机场)
git clone https://github.com/KwaiVGI/LivePortrait
cd LivePortrait
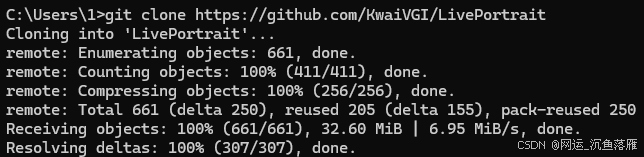
下载成功如下图
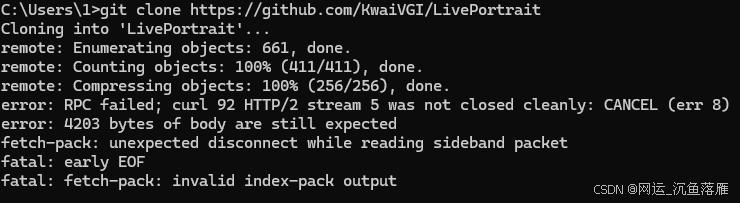
下载失败如下图(要关掉机场)
回车进入目录
复制粘贴下面命令进入
conda create -n LivePortrait python=3.9
如果出现错误

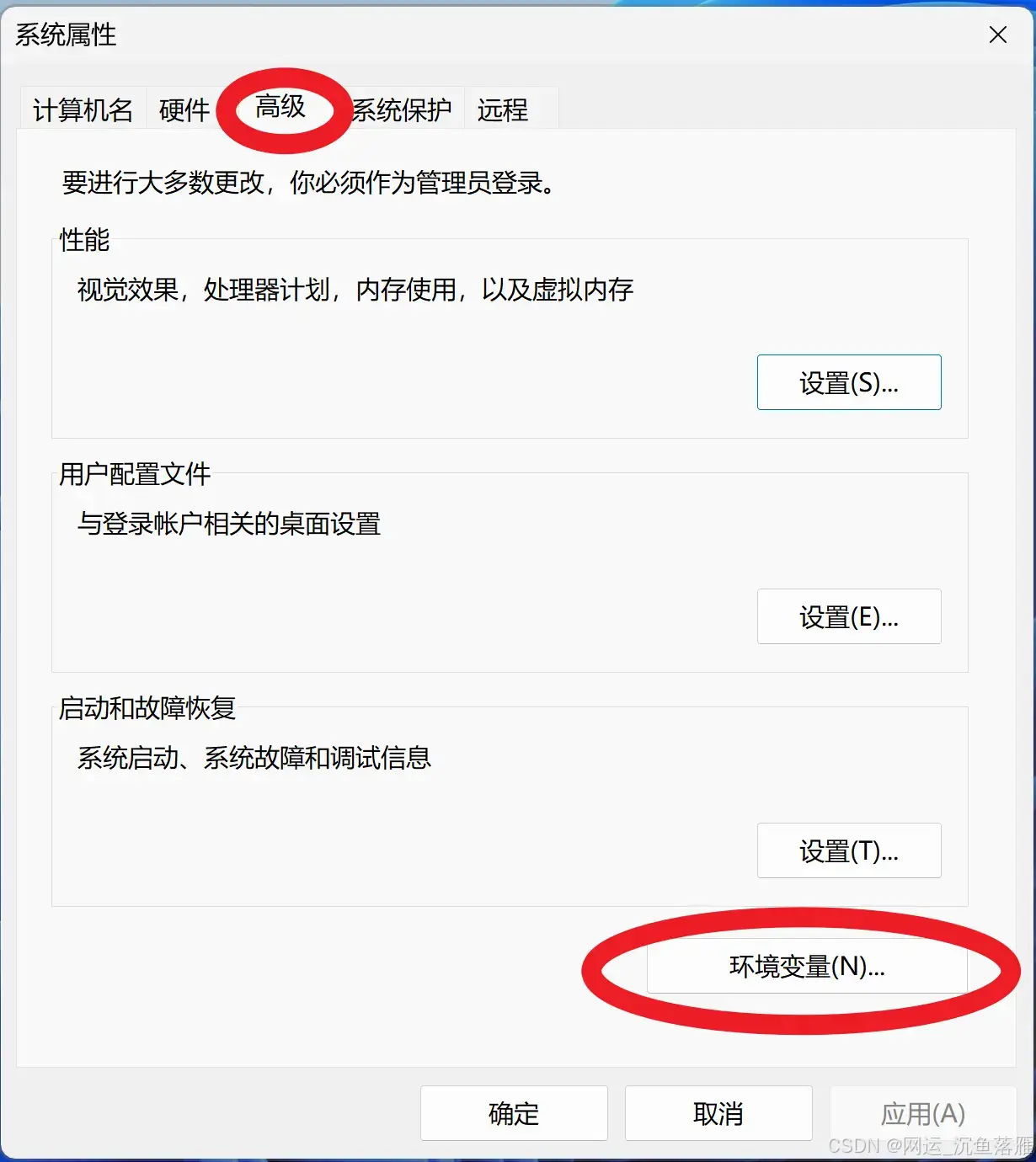
因为没有Conda在系统或者环境PATH,
解决方法:Conda下载
如果 Anaconda/Miniconda 已经安装,你可能需要将 conda 添加到系统的环境变量中。
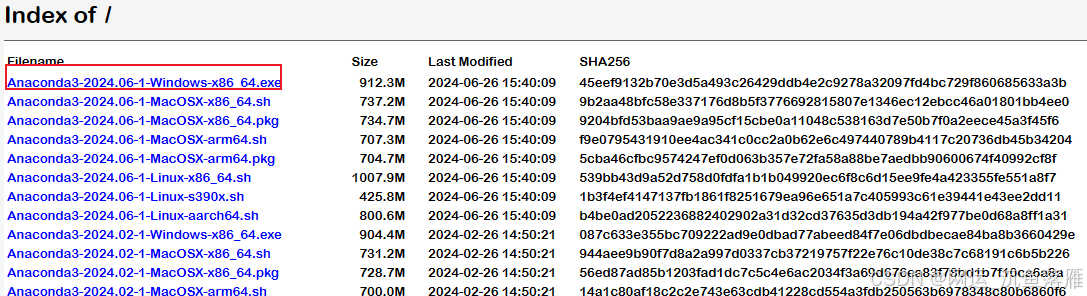
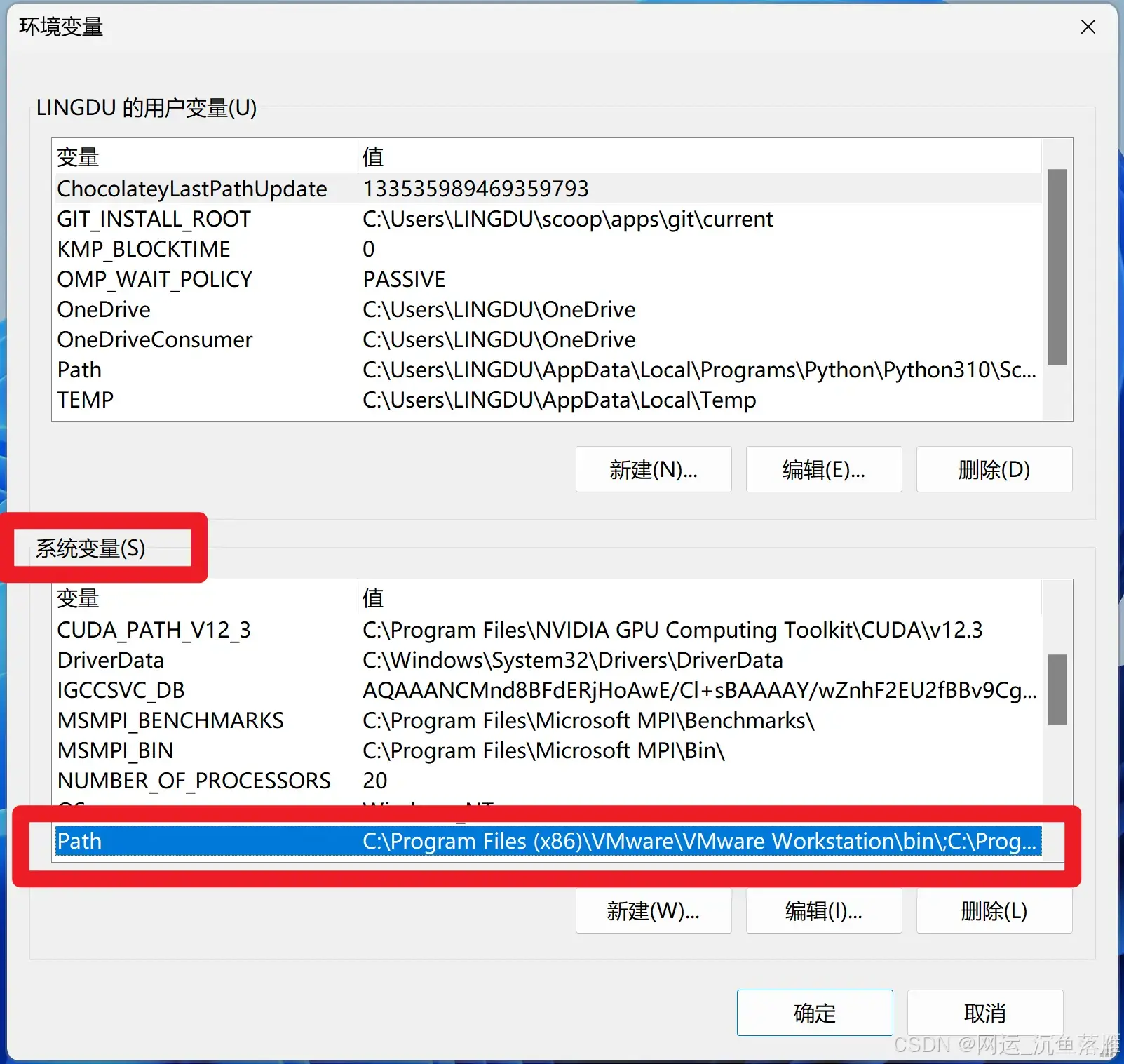
安装成功后,环境PATH变量(我在E盘,你们随便)
E:\anaconda3E:\anaconda3\ScriptsE:\anaconda3\Library\bin验证:conda --version
重新复制命令
conda create -n LivePortrait python=3.9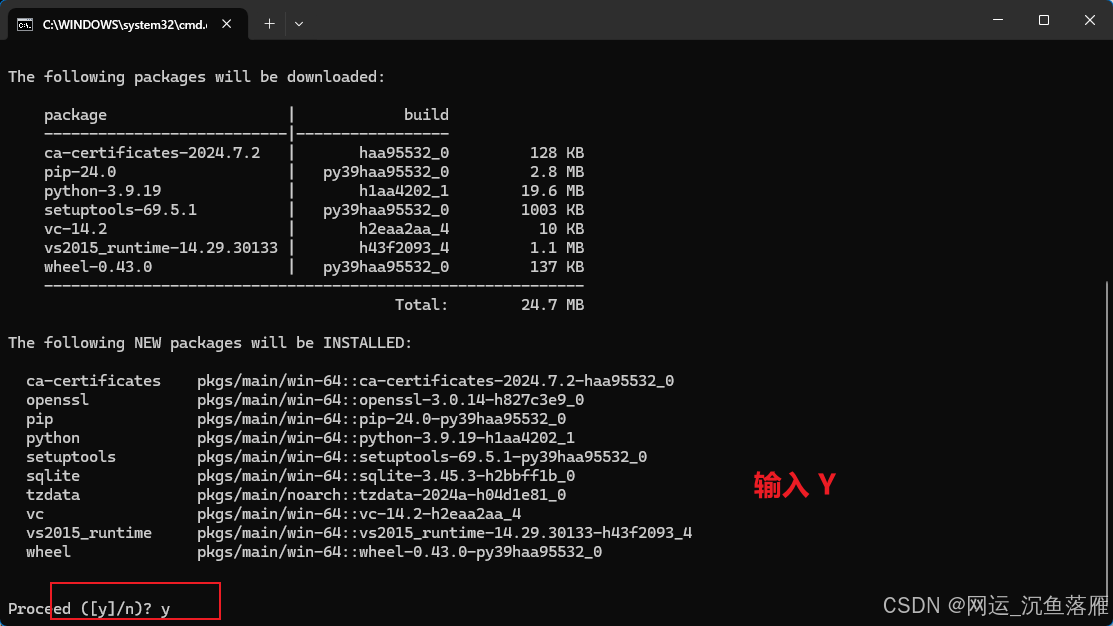


继续复制粘贴
conda activate LivePortrait进入下面以后我们要注意 有两个选项
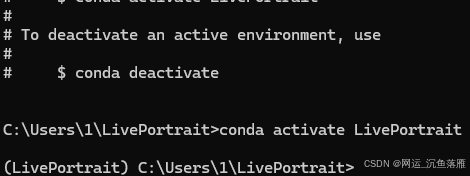
如果你是win系统或者Linux系统就用
pip install -r requirements.txt如果你是mac系统就用
pip install -r requirements_macOS.txt我是Windows,所以粘贴win系统的,回车开始下载所需的安装环境,可能需要点时间(我用了1个多点)

成功如下图
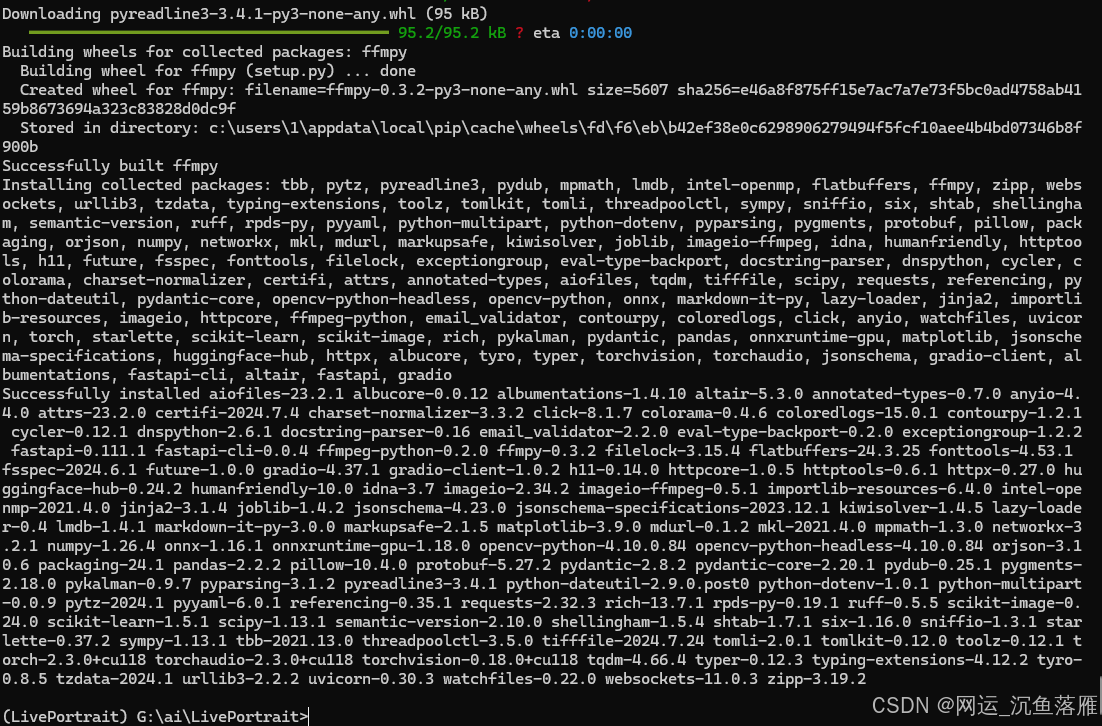 4,下载预训练权重
4,下载预训练权重
下载预训练权重的最简单方法是从 HuggingFace 下载:直接copy
# first, ensure git-lfs is installed, see: https://docs.github.com/en/repositories/working-with-files/managing-large-files/installing-git-large-file-storage
git lfs install
# clone and move the weights
git clone https://huggingface.co/KwaiVGI/LivePortrait temp_pretrained_weights
mv temp_pretrained_weights/* pretrained_weights/
rm -rf temp_pretrained_weights
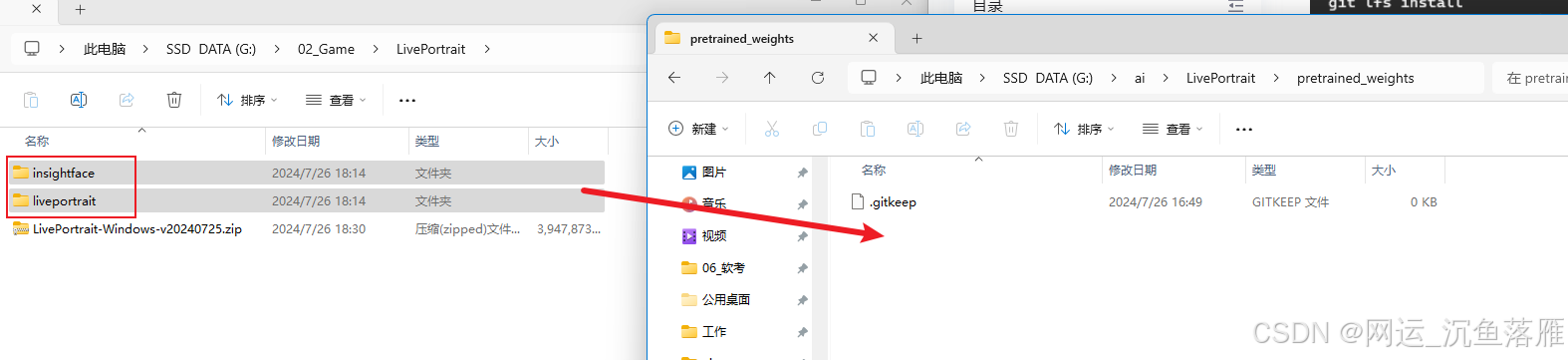
第二种方法,如果没有机场就用下载好的解压到 ./pretrained_weights 目录下
通过百度网盘分享的文件:LivePortrait
链接:https://pan.baidu.com/s/1sUrcg2WmaBkZZ2FEzJMQ5g?pwd=ib5p
提取码:ib5p
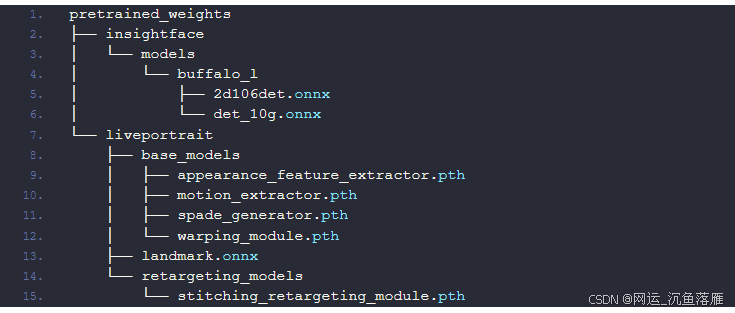
这是目录结构
5,推理使用
还是一样,你是win或者Linux系统
python inference.pymac系统
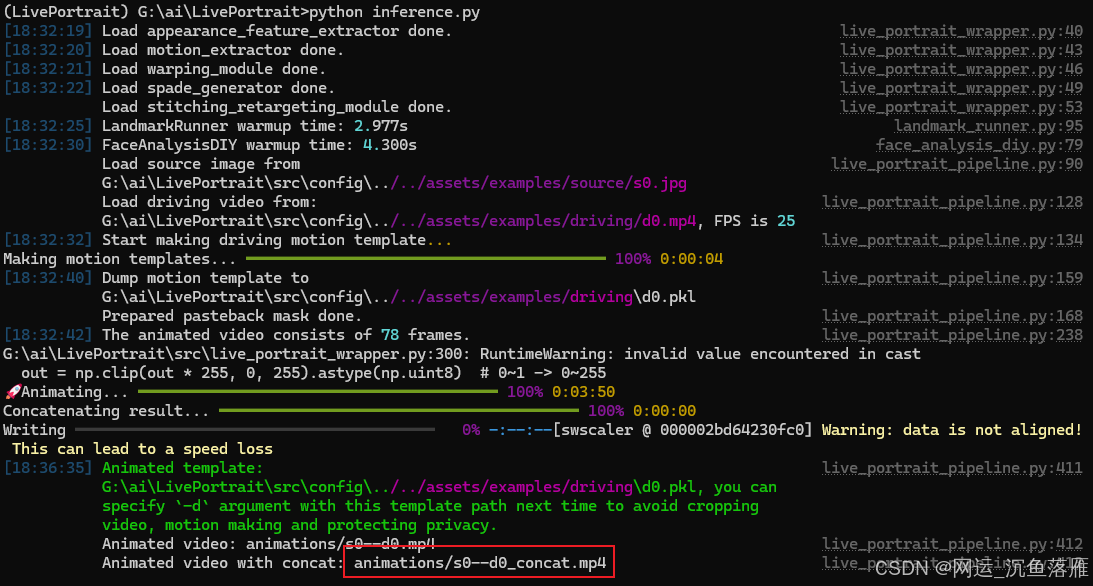
PYTORCH_ENABLE_MPS_FALLBACK=1 python inference.py我还是win,我们GO一下
复制命令框中,等待一会生成.MP4视频,会给你个生成地址目录,此时还是看网络质量了。
或者您可以通过指定-s和参数-d来更改输入
# 图片转视频
python inference.py -s assets/examples/source/s9.jpg -d assets/examples/driving/d0.mp4
# 视频转视频
python inference.py -s assets/examples/source/s13.mp4 -d assets/examples/driving/d0.mp4
python inference.py -hG:\ai\LivePortrait\assets\examples\source,把你需要的照片放进去也可以上传图片或者视频,自行打开观察
添加的图片后要修改上面命令的格式(图片转视频,视频转视频一样的)
修改前:
python inference.py -s assets/examples/source/s9.jpg -d assets/examples/driving/d0.mp4
修改后:前者是照片,后者是视频
python inference.py -s assets/examples/source/1.jpg -d assets/examples/driving/d20.mp4
然后放在命令框中运行即可生成

如果还是不行,可以百度网盘里制作好的文件
通过百度网盘分享的文件:LivePortrait
链接:https://pan.baidu.com/s/1sUrcg2WmaBkZZ2FEzJMQ5g?pwd=ib5p
提取码:ib5p
5,要使用您自己的参照视频,我们建议:⬇️
- 将其裁剪为1:1 的宽高比(例如 512×512 或 256×256 像素),或通过 启用自动裁剪
--flag_crop_driving_video。 - 重点关注头部区域,与示例视频类似。
- 尽量减少肩部运动。
- 确保参照视频的第一帧是正面且表情中性。
- 以下是自动裁剪的案例
--flag_crop_driving_video: -
python inference.py -s assets/examples/source/s9.jpg -d assets/examples/driving/d13.mp4 --flag_crop_driving_video如果觉得自动裁剪的效果不好,您可以修改
--scale_crop_driving_video、--vy_ratio_crop_driving_video选项来调整比例和偏移量,或者手动进行调整。
动作模板制作
您还可以使用自动生成的以 结尾的运动模板文件来.pkl加速推理,并保护隐私,例如:
python inference.py -s assets/examples/source/s9.jpg -d assets/examples/driving/d5.pkl # portrait animation
python inference.py -s assets/examples/source/s13.mp4 -d assets/examples/driving/d5.pkl # portrait video editing6,Gradio 可视化界面操作
在Gradio的可视化界面下可以获得更好的体验,适合新手使用,只需运行下面安装代码即可:
老样子,win或者Linux
python app.py
mac
PYTORCH_ENABLE_MPS_FALLBACK=1 python app.py您可以指定--server_port、、--share参数--server_name来满足您的需求!
它们还提供了加速选项--flag_do_torch_compile。首次推理会触发优化过程(约一分钟),使后续推理速度提高 20-30%。性能提升可能因 CUDA 版本的不同而有所差异。
python app.py --flag_do_torch_compile注意:Windows 和 macOS 不支持此方法。或者,在HuggingFace上轻松尝试一下
7,推理速度评估
下方提供了一个脚本来评估每个模块的推理速度:
python speed.py以下是使用原生 PyTorch 框架在 RTX 4090 GPU 上推断一帧的结果torch.compile:
| 模型 | 参数(米) | 模型大小(MB) | 推理(毫秒) |
|---|---|---|---|
| 外观特征提取器 | 0.84 | 3.3 | 0.82 |
| 运动提取器 | 28.12 | 108 | 0.84 |
| 铲形发电机 | 55.37 | 212 | 7.59 |
| 变形模块 | 45.53 | 174 | 5.21 |
| 拼接和重定向模块 | 0.23 | 2.3 | 0.31 |
注意:拼接和重定向模块的值代表三个连续 MLP 网络的组合参数数量和总推理时间。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 最新爆火的开源AI项目 | LivePortrait 本地安装教程

发表评论 取消回复